计算机系统漫游
信息就是位+上下文
我们先来看下面的代码:
hello.c
/* $begin hello */
#include <stdio.h>
int main()
{
printf("hello, world/n");
return 0;
}
/* $end hello */
hello程序的生命周期是从一个源程序(或者说源文件)开始的,即hello.c。源程序实际上是由值0和1组成的位(又称为比特)序列,8个位被组织称一组,称为字节。每个字节表示程序中的某些文本字符。大部分的现代计算机系统都是使用ASCII标准来表示文本字符,这种方式实际上就是用一个唯一的单字节大小的整数值来表示每个字符。比如图1-1中给出的hello.c程序的ASCII码表示:
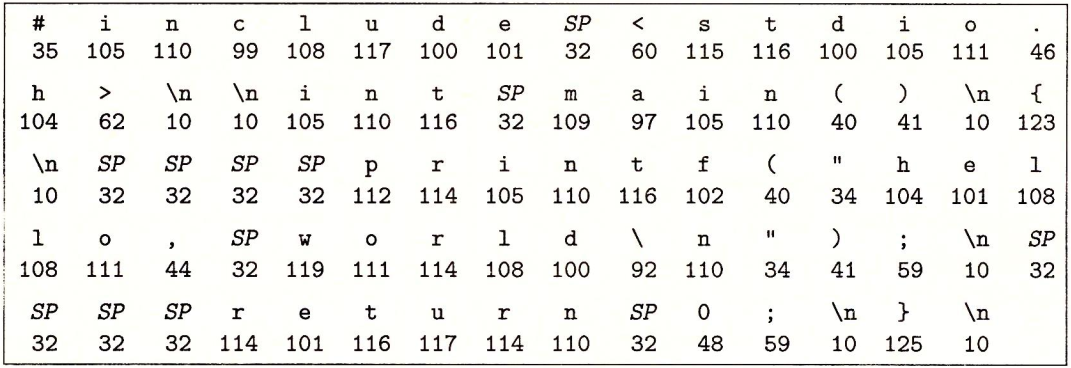
图1-1 hello.c的ASCII文本表示
hello.c程序是以字节序列的方式存储在文件中,每个字节都有一个整数值,对应于某些字符。例如第一个字节的整数值是35,它对应的字符为'#';第二个字节的整数值为105,它对应的字符为'i',以此类推。每个文本行都是以一个看不见的换行符'/n'来结束的,它所对应的整数值为10。像hello.c这样的只由ASCII字符构成的文件称为文本文件,所有其他文件都称为二进制文件。
hello.c的表示方法说明:系统中所有的信息——包括磁盘文件、内存中的程序、内存中存放的用户数据以及网络上传送的数据,都是由一串比特表示的。区分不同数据对象的唯一方法是我们读到这些数据对象时的上下文。比如,在不同的上下文中,一个同样的字节序列可能表示一个整数、浮点数、字符串或者机器指令。
程序被其他程序翻译成不同的格式
hello程序的生命周期是从一个高级C语言程序开始的,因为这种形式能够被人读懂。然而,为了在系统上运行hello.c程序,每条C语句都必须被其他程序转化为低级机器语言指令。然后这些指令按照一种称为可执行目标程序的格式打包好,并以二进制磁盘文件的形式存放起来。目标程序也可称为可执行目标文件。
现在,让我们用编译器驱动程序将之前的hello.c文件编译为目标文件:
[root]# gcc -o hello hello.c
GCC编译器驱动程序去读源程序文件hello.c,并把它翻译成一个可执行的目标文件hello。这个翻译过程可分为四个阶段完成,如图1-2所示。执行者四个阶段程序(预处理器、编译器、汇编器和链接器)一起构成了编译系统。

图1-2 编译系统
- 预处理阶段:预处理器(cpp) 根据以字符#开头的命令,修改原始的C程序。比如#include <stdio.h>告诉预处理器读取系统头文件stdio.h的内容,并把它直接插入程序文本中。结果得到了另一个C程序,通常以.i作为文件扩展名。
- 编译阶段:编译器(cc1)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。该程序包含函数main的定义如下:
main: subq $8, %rsp movl $.LCO, %edi call puts movl $0, %eax addq $8, %rsp ret
定义中2~7行的每条语句都以一种文本格式描述了一条低级机器语言指令,汇编语言是非常有用的,因为它为不同高级语言的不同编译器提供了通用的输出语言。例如,C编译器和Fortran编译器产生的输出文件用的都是一样的汇编语言。
- 汇编阶段:汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成可重定位目标程序(relocatable object program)的格式,并将结果保存在目标文件hello.o中。hello.o是一个二进制文件,它包含的17个字节是函数main的指令编码。如果我们在文本编辑器中打开hello.o文件,看到的将是一堆乱码。
- 链接连接:hello程序调用了printf函数,它是每个C编译器都提供的标准C库中的一个函数。printf函数存在于一个名为print.o的单独的预编译好的目标文件中,而这个文件必须以某种方式合并到我们的hello.o程序中。链接器(ld)就负责处理这种合并。结果就得到了hello文件,它是一个可执行目标文件(或称为可执行文件),它可以被加载到内存中,由系统执行。
处理器读并解释存储在内存中的指令
hello.c源程序经编译系统翻译成为可执行目标文件hello,并存放在磁盘上。我们可以按照下面的方式执行hello文件:
[root]# ./hello hello, world [root]#
为了理解运行hello程序时发生了什么,我们需要了解一个典型系统的硬件组织,如图1-3所示:
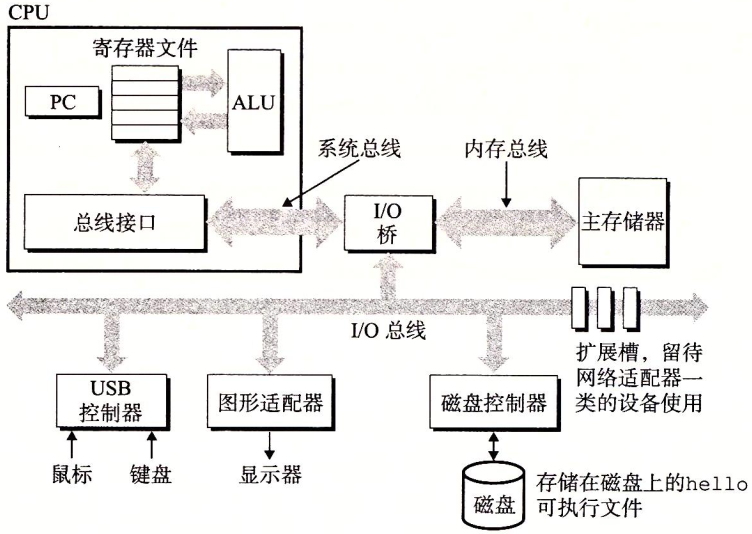
图1-3 一个典型系统的硬件组成
CPU:中央处理单元;ALU:算数/逻辑单元;PC:程序计数器;USB:通用串行总线
总线
贯穿整个系统的是一组电子管道,称为总线,它携带信息字节并负责在各个部件间传递。通常总线被设计成传送定长的字节块,也就是(字)。字中的字节数(即字长)是一个基本的系统参数,各个系统不尽相同。大多数机器字长是4个字节(32位)或8个字节(64位)。
I/O设备
I/O(输入/输出)设备是系统与外部世界的联系通道。我们的示例系统包括四个I/O设备:键盘、鼠标、显示器、以及用于长期存储数据和程序的磁盘(或称磁盘驱动器)。最开始,可执行程序hello就存放在磁盘上。
每个I/O设备都通过一个控制器或适配器与I/O总线相连。控制器与适配器之间的区别主要在于它们的封装方式。控制器是I/O设备本身或主印制电路板(通常称为主板)上的芯片组。而适配器则是一块插在主板插槽上的卡。但它们的功能都是在I/O总线和I/O设备之间传递信息。
主存
主存是一个临时存储的设备,在处理器执行程序时,用来存放程序和程序处理的数据。从物理上来说,主存是由一组动态随机存取存储器(DRAM)芯片组成。从逻辑上来说,存储器是一个线性的字节数组,每个字节都有其唯一的地址(数组索引),这些地址是从0开始的。
处理器
中央处理单元(CPU),简称处理器,是解释或执行存储再主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。在任何时刻,PC都指向主存中的某条机器语言指令(即含有该条指令的地址)。从系统开始通电到断电,处理器不断地在执行程序计数器指向的指令,再更新程序计数器,使其指向下一条指令。处理器看上去是按照一个非常简单的指令执行模型来操作的,这个模型是由指令集架构决定的。
在这个模型中,指令按照严格的顺序执行,而执行一条指令包含执行一系列的步骤。处理器从程序计数器指向的内存读取指令,解释指令中的位,执行该指令指示的简单操作,然后再更新PC,使其指向下一条指令,而这条指令并不一定和在内存中刚刚执行的指令相邻。
这样的操作并不多,它们围绕着主存、寄存器文件和算术/逻辑单元进行。寄存器文件是一个小的存储设备,由一些单个字长的寄存器组成,每个寄存器都有唯一的名字,ALU计算新的数据和地址值。CPU在指令的要求下可能会执行如下操作:
- 加载:从主存复制一个字节或一个字到寄存器,以覆盖寄存器原来的内容。
- 存储:从寄存器复制一个字节或一个字到主存的某个位置,以覆盖这个位置上原来的内容。
- 操作:把两个寄存器的内容复制到ALU,ALU对这两个字做算术运算,将结果存放到一个寄存器中,以覆盖原来寄存器中的内容。
- 跳转:从指令本身中抽取一个字,并将这个字复制到程序计数器(PC)中,以覆盖PC中原来的值。
运行hello程序
当我们在键盘上敲入"./hello"后,shell程序将字符逐一读入寄存器,再把它放到内存中,如图1-4:
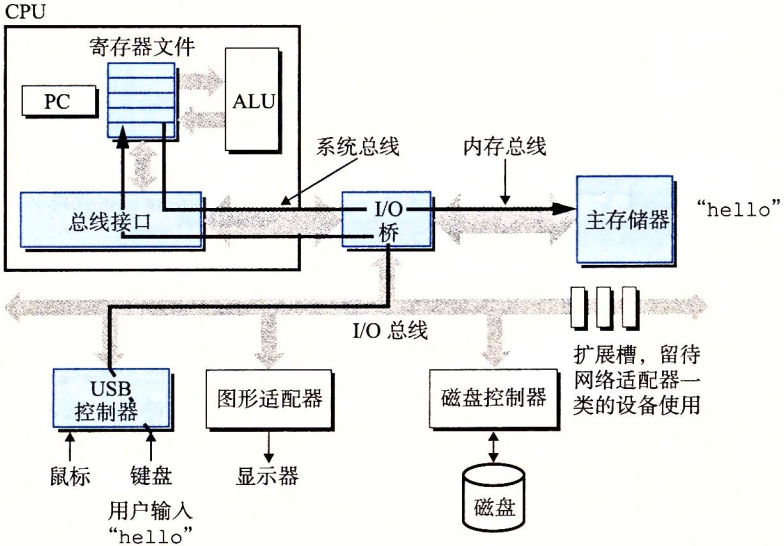
图1-4 从键盘上读取hello命令
当我们敲入回车键时,shell程序就知道我们已经结束了命令的输入。然后shell执行一系列指令来加在可执行的hello文件,这些指令将hello目标文件中的代码和数据从磁盘复制到主存。数据包括最终会被输出的字符串"hello, world/n"。
利用直接存储器存取(DMA)技术,数据可以不通过处理器而直接从磁盘到达主存,如1-5所示:
图1-5 从磁盘加在可执行文件到主存
一旦目标文件hello中的代码和数据被加载到主存,处理器就开始执行hello程序的main程序中的机器语言指令。这些指令将"hello, world/n"字符串中的字符从主存复制到寄存器文件,再从寄存器文件复制到显示设备,最终显示在屏幕上。这些步骤如1-6所示:

图1-6 将输出字符串从存储器写到显示器
高速缓存至关重要
hello程序的机器指令最初是放在磁盘上,当程序加载时它们被复制到主存;当处理器运行程序时,指令又从主存复制到处理器。相似的,数据串"hello, world/n"开始是放在磁盘上,然后被复制到主存,最后从主存复制到显示设备。从程序员的角度来看,这些复制就是开销,减慢了程序“真正”的工作。因此,系统的设计者的一个主要目标就是使得这些复制操作尽快完成。
根据机械原理,较大的存储设备比较小的存储设备运行得慢,而快速设备的造价远高于同类的低速设备。比如说,一个典型系统上的磁盘驱动器可能比主存大1000倍,但对处理器而言,从磁盘驱动器上读取一个字的时间开销要比从主存中读取的开销大1000万倍。
类似地,一个典型的寄存器文件只存储几百字节的信息,而主存里可存放几十亿字节。然而,处理器从寄存器文件中读数据比从主存中读取几乎要快100倍。并且随着这些年半导体技术的进步,这种处理器与主存之间的差距还在持续增大。加快处理器的运行速度比加快主存的运行速度要容易和便宜得多。
针对这种处理器与主存之间的差异,系统设计者采用了更小更快的存储设备,称为高速缓存存储器(cache memory,简称为cache或高速缓存),作为暂时的集结区域,存放处理器近期可能会需要的信息。
图1-7展示了一个典型系统中的高速缓存存储器。位于处理器芯片上的L1高速缓存的容量可以达到数万字节,访问速度几乎和访问寄存器文件一样快。一个容量为数十万到数百万字节的更大的L2高速缓存通过一条特殊的总线连接到处理器。进程访问L2高速缓存的时间要比访问L1高速缓存的时间长5倍,但是这仍然比访问主存的时间快5~10倍。L1和L2高速缓存是用一种叫做静态随机访问存储器(SRAM)的硬件技术实现的。

图1-7 高速缓存存储器
比较新的、处理能力更强大的系统甚至有三级高速缓存:L1、L2和L3。系统可以获得一个很大的存储器,同时访问速度也很快,原因是利用了高速缓存的局部性原理,即程序具有访问局部区域里的数据和代码的趋势。通过让高速缓存里存放可能经常访问的数据,大部分的内存操作都能在快速的高速缓存中完成。