二手车价格预测、机器学习、回归问题、数学建模[python]

- 目的:根据二手车参数特征,预测二手车价格。
- 数据:
- 35 Features
- csv 格式
- 30000条数据
- 准备:
- 监督学习
- 回归
- 评价指标MAPE
1. 准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2. 读取数据
data=pd.read_csv('data.csv',na_values=['na','--','NA','n/a','N/A',np.nan])
3. 特征工程
3.1 数据清洗
3.1.1 删除不必要的匿名变量
scl=['aF4','aF7','aF8','aF9','aF10','aF13','aF15']
data=data.drop(scl,axis=1)
3.1.2 缺失值处理
# 3-1.af1处理:用众数填充
af1x = float(data['aF1'].mode())
data['aF1'].fillna(af1x,inplace=True)
# 3-2.af11处理:用众数填充
af11x = data['aF11'].mode()[0]
data['aF11'].fillna(af11x,inplace=True)
# 3-4.country国别通过众数填充
counx = float(data['country'].mode()[0])
data['country'].fillna(counx,inplace=True)
# 3-5. maketype厂商类型通过众数填充
makex = float(data['maketype'].mode()[0])
data['maketype'].fillna(makex,inplace=True)
# 3-6. modelyear年款通过众数填充
modelx = float(data['modelyear'].mode()[0])
data['modelyear'].fillna(modelx,inplace=True)
# 3-7. gearbox变速箱通过众数填充
gearx = float(data['gearbox'].mode()[0])
data['gearbox'].fillna(gearx,inplace=True)
3.1.3 检验是否还存在缺失值
data.isnull().any()
3.1.4 规范时间特征
data['tradeTime'] = pd.to_datetime(data['tradeTime'])
data['registerDate'] = pd.to_datetime(data['registerDate'])
data['licenseDate'] = pd.to_datetime(data['licenseDate'])
3.1.5 规范长x宽x高特征
# 原数据格式 length*width*high,规范为三列分别为:长 宽 高
# 将aF2的长宽高单独按列提取出来,命名为length,width,high
ckg = data['aF12'].str.split('*', expand=True)
data['length'] = ckg[0]
data['width'] = ckg[1]
data['high'] = ckg[2]
# 并强制转换为浮点数
data['length'] = data['length'].astype(float)
data['width'] = data['width'].astype(float)
data['high'] = data['high'].astype(float)
#删除aF12这个列
del data['aF12']
3.1.6 类别特征的处理
# 将aF11下的值(是类别)改成数字标签
dict = {
'1':1,
'1+2':2,
'3+2':3,
'1+2,4+2':4,
'1,3+2':5,
'5':6}
data['aF11'] = data['aF11'].map(dict)
3.1.7 异常值的处理
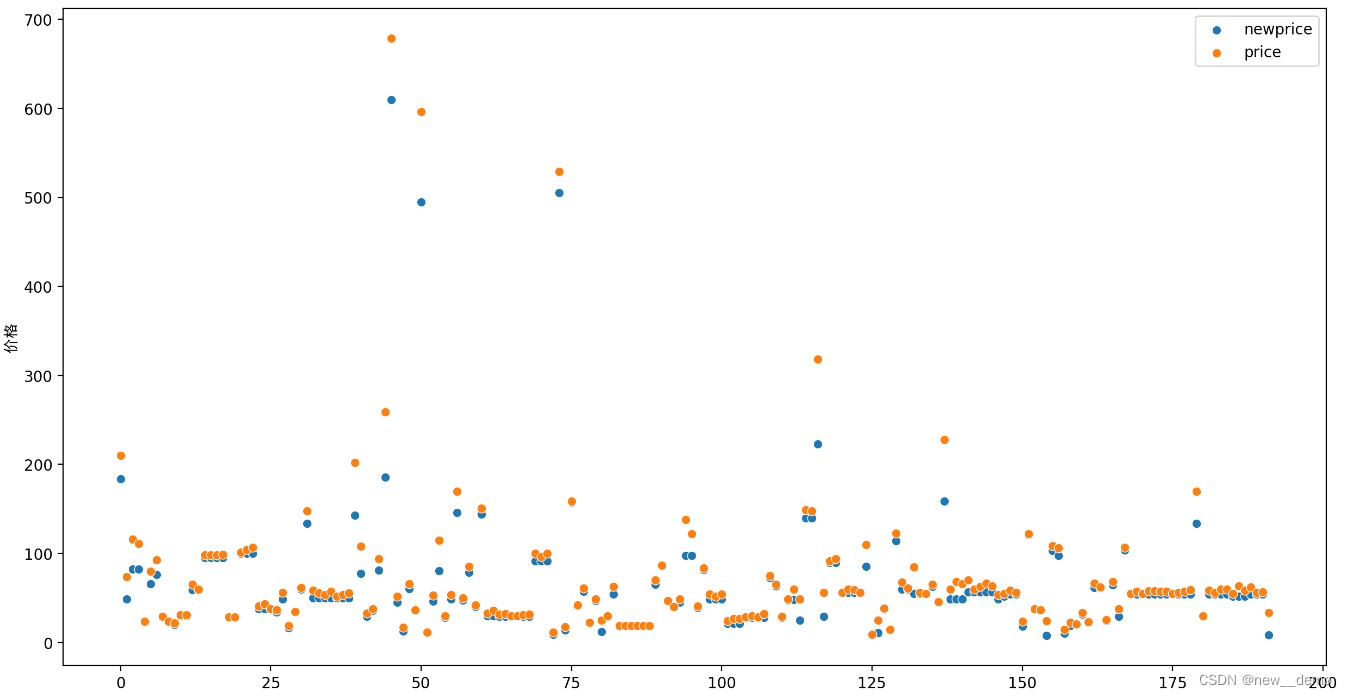
#二手远大于原价
# carid是49878和54999
# 在看了图片之后,手动更改了这两个值
new=[]
er=[]
for i in range(30000):
if data.loc[i]['newprice'] < data.loc[i]['price']:
new.append(data.loc[i]['newprice'])
er.append(data.loc[i]['price'])
plt.figure(figsize=(15, 8),dpi=200)
plt.xlabel(u'样本',fontproperties='SimHei')
plt.ylabel(u'价格',fontproperties='SimHei')
plt.legend(["train","test"])
sns.scatterplot(data=new,label='newprice')
sns.scatterplot(data=er,label='price')
plt.show()
3.1.8 导出备用
为了清晰展现机器学习流程,将各个部分分开来做。真正实践时,可以直接使用处理完成的data,不用再导出新的csv。
data.to_csv('GJdata_1.csv',index=False)
4. 准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from scipy import stats
import warnings
import math
from sklearn.preprocessing import OneHotEncoder
warnings.filterwarnings("ignore")
%matplotlib inline # jupyter里使用
5. 数据描述
5.1 读取数据
# 1.读取数据
data=pd.read_csv('GJdata_1.csv') # 上面处理完的数据
5.2 分割数据集
fea = data.drop(['price', 'carid'], axis=1)
aim = data['price']
x_train, x_test, y_train, y_test = train_test_split(fea, aim, test_size=0.2) # 8:2
train_data=pd.concat([x_train,y_train],axis=1)
test_data=pd.concat([x_test,y_test],axis=1)
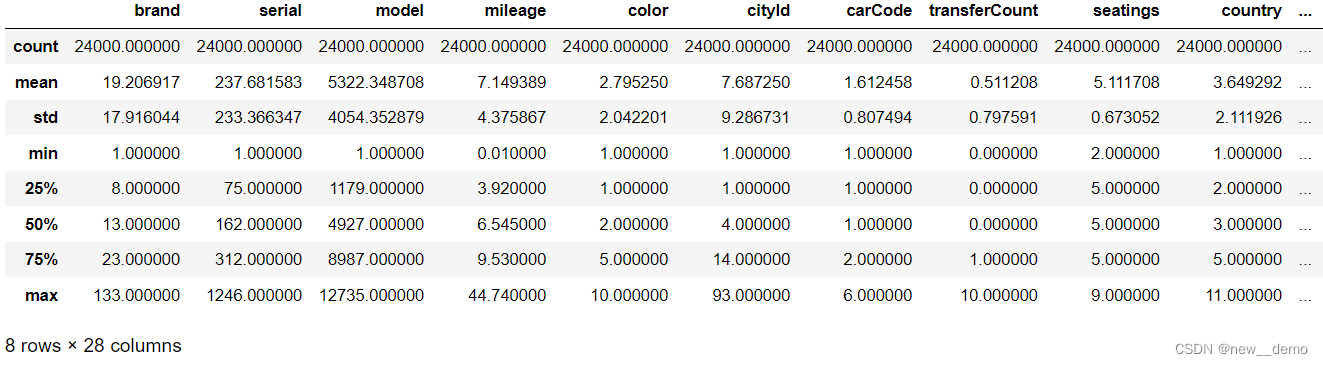
5.3 查看统计信息
train_data.describe()
5.4 连续变量
num_features_columns = ['mileage','displacement','newprice','usetime','length','width','high']
train_data_num=train_data[num_features_columns]
train_data_num['price']=train_data['price']
test_data_num=test_data[num_features_columns]
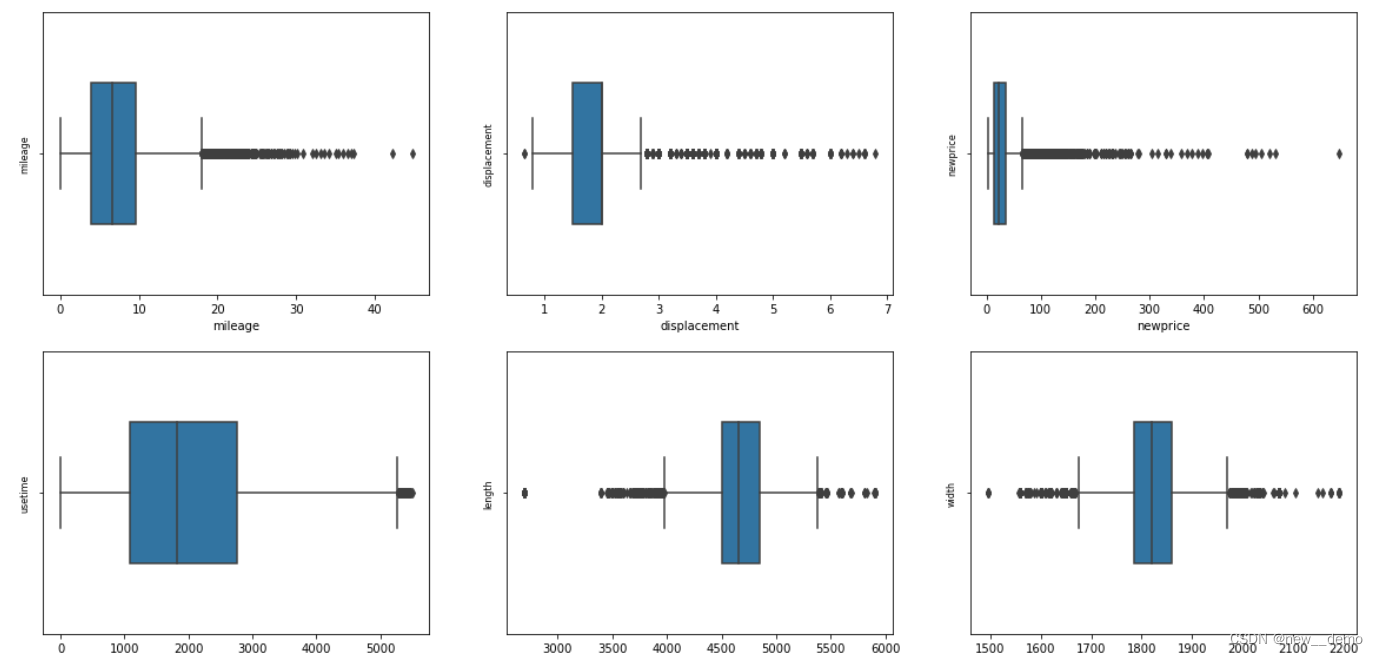
5.4.1 箱线图展示
column = train_data_num.columns.tolist()[:8]
fig = plt.figure(figsize=(20, 15))
for i in range(7):
plt.subplot(3, 3, i + 1)
sns.boxplot(train_data_num[column[i]], orient="v", width=0.5) # 箱式图
plt.ylabel(column[i], fontsize=8)
plt.show()
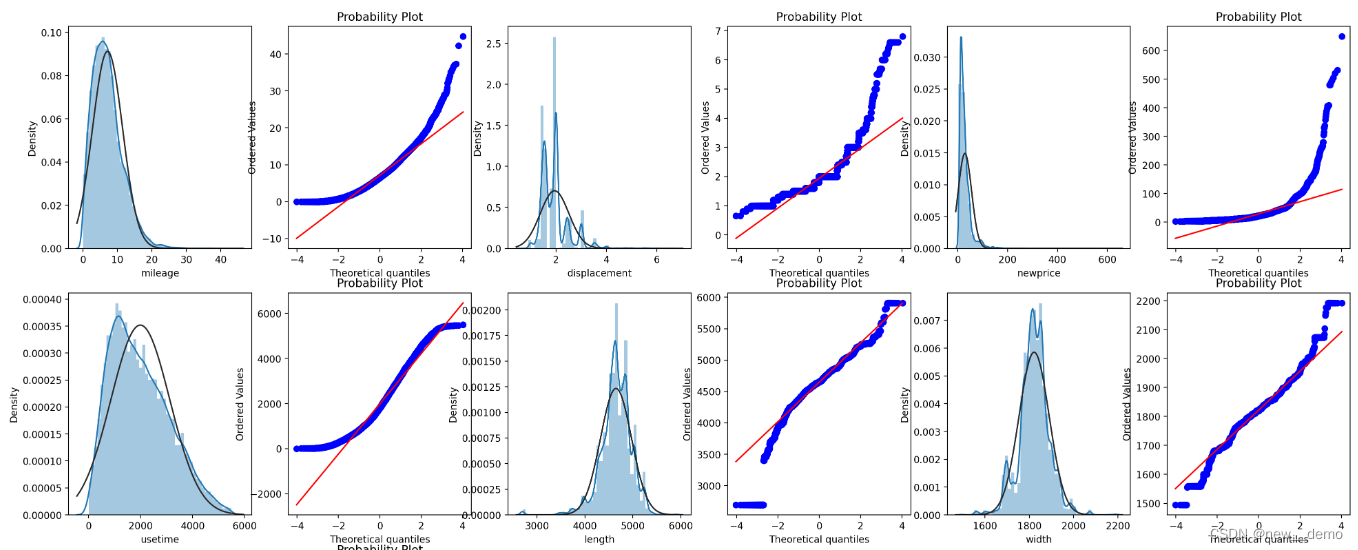
5.4.2 正态分布情况
# 红色线条表示正态分布,蓝色线条表示样本数据,蓝色越接近红色参考线,说明越符合预期分布
train_cols = 6
train_rows = len(train_data_num.columns[:7])
plt.figure(figsize=(4*train_cols,5*train_rows),dpi=200)
i=0
for col in train_data_num.columns[:7]:
i+=1
ax=plt.subplot(train_rows,train_cols,i)
sns.distplot(train_data_num[col],fit=stats.norm)
i+=1
ax=plt.subplot(train_rows,train_cols,i)
res = stats.probplot(train_data_num[col], plot=plt)
plt.show()
5.4.3 训练集和测试集的分布情况
dist_cols = 3
dist_rows = len(test_data_num.columns[:7])
plt.figure(figsize=(4*dist_cols,4*dist_rows),dpi=200)
i=1
for col in test_data_num.columns[:7]:
ax=plt.subplot(dist_rows,dist_cols,i)
ax = sns.kdeplot(train_data_num[col], color="Red", shade=True)
ax = sns.kdeplot(test_data_num[col], color="Blue", shade=True)
ax.set_xlabel(col)
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
i+=1
plt.show()

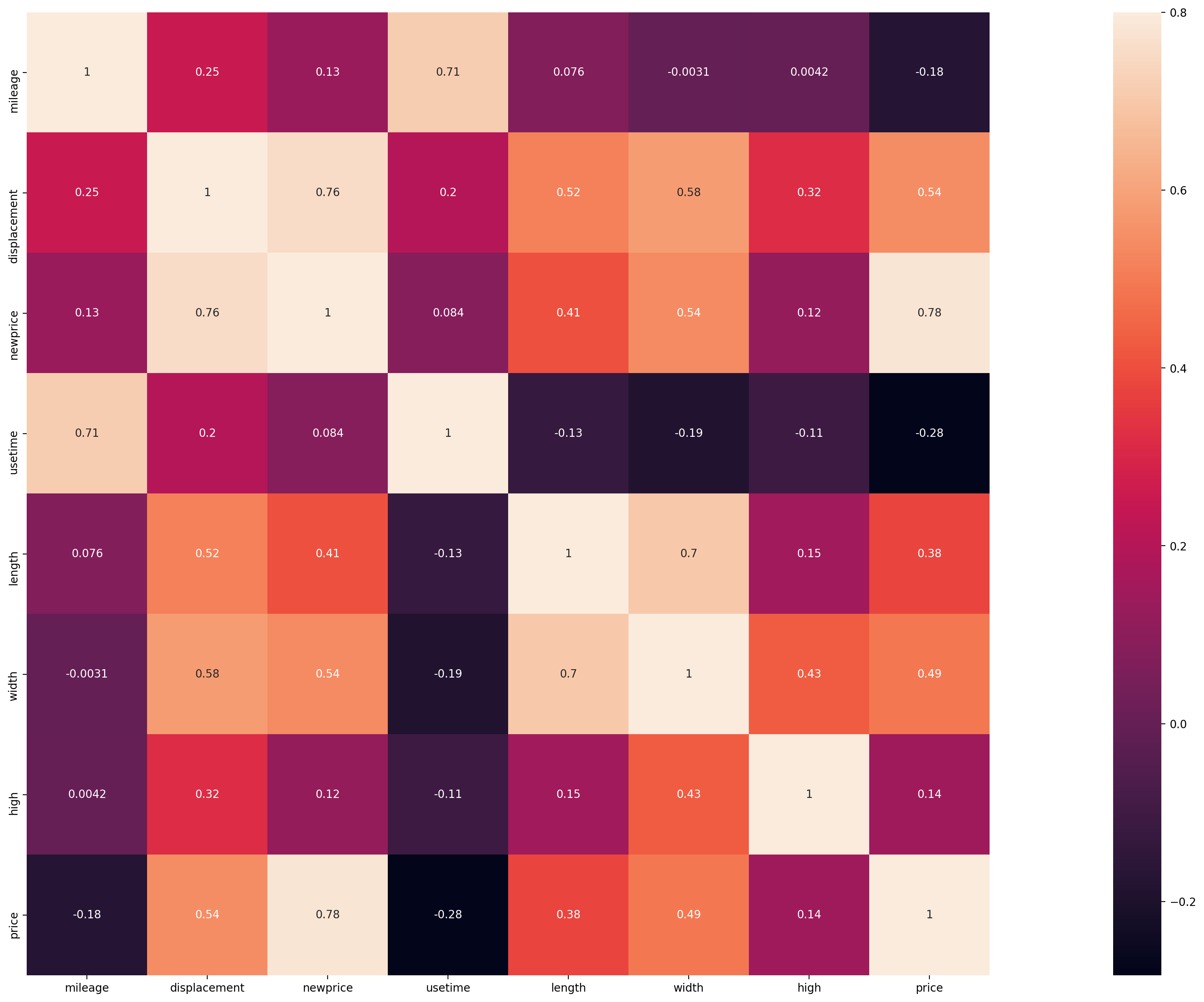
5.4.4 热力图相关性
ax = plt.subplots(figsize=(40, 16),dpi=200)
ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)
6. 准备
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
warnings.filterwarnings('ignore')
from IPython import get_ipython
get_ipython().run_line_magic('matplotlib', 'inline')
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
import lightgbm as lgb
import xgboost as xgb
from sklearn.model_selection import GridSearchCV,cross_val_score,KFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
7. 读取数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
8. 挑选特征
特征的挑选经过多次尝试不同的组合,因模型而异
column=["usetime", "color","aF1","brand", "length","mileage","model", "width",
"carCode", "newprice","aF6","serial","oiltype","registerDate_month",
"gearbox","displacement","cityId","maketype","registerDate_year",
"aF3","seatings","aF14","modelyear","transferCount","country","aF5",]
x_train_features=train[column]
y_train_labels=np.log1p(train['price'])
x_test_features=test[column]
9. 预测回归
9.1 数据量
print('X train shape:',x_train_features.shape)
print('X test shape:',x_test_features.shape)
9.2 评价指标
def Accuracy(y_true, y_pred):
"""
参数:
y_true -- 测试集目标真实值
y_pred -- 测试集目标预测值
返回:
mape -- MAPE 评价指标
"""
n = len(y_true)
mape = sum(np.abs((y_true - y_pred)/y_true))/n
Apexiaoyu005 = pd.DataFrame(abs(y_true - y_pred)/y_true)
Accuracy = (Apexiaoyu005[Apexiaoyu005 <= 0.05].count() /
Apexiaoyu005.count())*0.8+0.2*(1-mape)
print('mape',round(mape, 5))
return Accuracy
9.3 k5 + XGB
xgr = xgb.XGBRegressor(n_estimators=150, learning_rate=0.25, gamma=0, subsample=0.8,colsample_bytree=0.5, max_depth=15)
#,objective ='reg:squarederror'
scores_train = []
scores = []
val_pred = np.zeros(len(x_train_features))
val_true = np.zeros(len(x_train_features))
preds = np.zeros(len(x_test_features))
#5折交叉验证方式
sk=KFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(x_train_features,y_train_labels):
train_x=x_train_features.iloc[train_ind].values
train_y=y_train_labels.iloc[train_ind]
val_x=x_train_features.iloc[val_ind].values
val_y=y_train_labels.iloc[val_ind]
xgr.fit(train_x,train_y)
pred_train_xgb=xgr.predict(train_x)
pred_xgb=xgr.predict(val_x)
val_pred[val_ind] += xgr.predict(val_x)
val_true[val_ind] += val_y
score_train = mean_absolute_error(train_y,pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y,pred_xgb)
scores.append(score)
print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
###
Train mae: 0.0009382915641912427
Val mae 0.07728068307003066
9.4 LightGBM
def build_model_lgb(x_train,y_train):
model = lgb.LGBMRegressor(num_leaves=30,learning_rate=0.24, subsample=0.8,colsample_bytree=0.5, max_depth=15,
min_child_samples= 50,min_child_weight=0.02)
model.fit(x_train, y_train)
return model
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
###
MAE of val with lgb: 0.08174606290663007
~
~
~
~
~
~
~
~
~
~
该文仅仅是回归问题的一个一般化流程解决方案,还有很多不足,主要提供一个参考,有需要的模块可以直接cv。同时特征工程是使用传统机器学习算法的基础,个人认为比调参时带来的效果更明显。其他模型还有很多,例如决策树、岭回归等都可以在自己的数据集上进行尝试,同时也可以利用模型融合、调参来进一步提升准确度。