项目场景:
最近正在学习爬虫之际,但是遇到了一个匪夷所思的问题:
在使用
etree.tostring(htmlElement,encoding='utf-8').decode('utf-8')#按字符串序列化HTML文档
按字符串序列化HTML文档的有些时候,在每一行的结尾都会出现
奇怪的字符,而且在xpath匹配时后面还不会进行截断。
问题描述
错误例子:以下代码执行结果后,输出序列化后的text,每一行后面都会出现 
from lxml import etree
text = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">第四项</a></li>
<li class="item-0"><a href="link5.html">第五项</a>
</ul>
</div>
"""
def parse_text():
htmlElement = etree.HTML(text)#利用etree.HTML,将字符串解析为HTML文件
print(type(htmlElement))#<class 'lxml.etree._Element'>
print(etree.tostring(htmlElement,encoding='utf-8').decode('utf-8'))#按字符串序列化HTML文档
def parse_file():
parser = etree.HTMLParser(encoding='utf-8')
htmlElement = etree.parse('test.html',parser=parser)
print(etree.tostring(htmlElement,encoding='utf-8').decode('utf-8'))
if __name__ == '__main__':
parse_file()
结果如下:
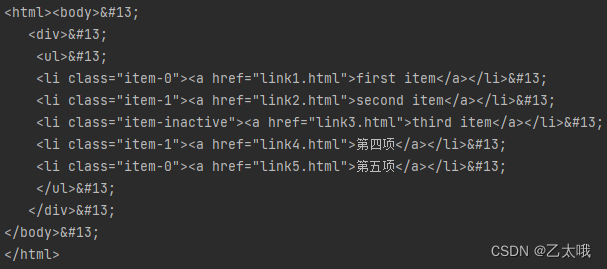
原因分析:
贴心小tips:
原因就是etree.tostring()中有一个参数method默认为xml,如果不写默认设置,此时每行的后面就会多出一些奇怪的据说是换行字
,xpath匹配后面还不会进行截断。
解决方案为:参数method值设置为等于html就行了
解决方案:
解决方案为:参数method值设置为等于html就行了
小小彩蛋
我就是在学习写这个爬虫的时候遇到的问题;现在提供源码供大家学习交流,优化完善。
网络爬虫—爬取电影链接和信息。现在还没学到文件归档整理,只写了一个简单的写入到txt
import requests
from lxml import etree
BASE_DAMAIN = 'https://dytt8.net'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39'
}
def get_datail_urls(url):
#url = "https://dytt8.net/html/gndy/dyzz/list_23_1.html"
response = requests.get(url,headers=HEADERS)
#print(response.text)#这会默认使用自己猜测的方式进行解码,然后存储到text属性上,猜错了编码方式所以乱码
text = response.content.decode('gbk')#可以先去查看页面源码查看编码方式手动解码
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class='tbspan']//a/@href")
'''def abc(url):
return BASE_DAMAIN+url
index = 0
for detail_url in detail_urls:
detail_url = abc(detail_url)
detail_urls[index] = detail_url
index += 1'''
detail_urls = map(lambda url:BASE_DAMAIN+url,detail_urls)#等价于上面操作重构url
return detail_urls
def parse_detail_page(url):
movie = {
}#创建一个空的列表准备储存电影信息
response = requests.get(url,headers=HEADERS)
text = response.content.decode('gbk')
with open('dytt8.html','w',encoding='utf-8') as fp:
fp.write(text)
html = etree.HTML(text)
title = html.xpath("//div[@class='title_all']//font[@color='#07519a']/text()")[0]
print("标题:"+title)#输出电影标题
'''for x in title:
#贴心小tips: method默认为xml,此时每行的后面就会多出一些奇怪的据说是换行字
,xpath匹配后面还不会进行截断。解决方案为:设置为html就行了。etree.tostring(x, encoding="utf-8", method='html')
print(etree.tostring(x,encoding='utf-8',method='html').decode('utf-8'))
print("="*100)'''
movie['title'] = title
zoomE = html.xpath("//div[@id='Zoom']")[0]
img = zoomE.xpath(".//img/@src")
#print("图片:"+img)#输出电影图片
cover = img[0]
movie['cover'] = cover
infos = zoomE.xpath(".//text()")
#print(infos)#返回一个具有全部详细信息的列表
def parse_info(info,rule):
return info.replace(rule,"").strip()
for index,info in enumerate(infos):
'''print(info)
print(index)
print("=="*20)'''
if info.startswith("◎年 代"):#判断如果以xxx开始,则XXXX
#info = info.replace("◎年 代","").strip()#首先替换字符串然后,去除两边空格
info = parse_info(info,"◎年 代")
movie['year']=info
elif info.startswith("◎产 地"):
info = parse_info(info,"◎产 地")
movie['country'] = info
elif info.startswith("◎类 别"):
info = parse_info(info,"◎类 别")
movie['category'] = info
elif info.startswith("◎豆瓣评分"):
info = parse_info(info,"◎豆瓣评分")
movie['douban_rating'] = info
elif info.startswith("◎片 长"):
info = parse_info(info,"◎片 长")
movie['duration'] = info
elif info.startswith("◎导 演"):
info = parse_info(info,"◎导 演")
movie["director"] = info
elif info.startswith("◎演 员"):
info = parse_info(info,"◎演 员")
actors = [info]
#有多个演员需要遍历列表
for x in range(index+1,len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
#print(actors)
movie['actors'] = actors
elif info.startswith("◎简 介"):
info = parse_info(info,"◎简 介")
#print(info)
for x in range(index+1,len(infos)):
profile = infos[x].strip()
if profile.startswith("点击下载"):
break
movie["profile"] = profile
download_url = zoomE.xpath(".//a/@href")[0]
movie['download'] = download_url
return movie
def spider():
base_url = "https://dytt8.net/html/gndy/dyzz/list_23_{}.html"
movies = []
for x in range(1,2):#第一个for循环是用来遍历页数的(改变后面的数字就可以改变页数)
print("="*30)
print(x)
print("="*30)
url = base_url.format(x)
print("页面:"+url)#输出当前页面
detail_urls = get_datail_urls(url)
for detail_url in detail_urls:#第2个for循环是用来遍历每一页的详细信息
print("详情页面:"+detail_url)#输出详情页面
movie = parse_detail_page(detail_url)
movies.append(movie)
print(movie)
print("=="*20+"\n")
with open('dytt8.txt', mode='a+',encoding='utf-8') as fp:
fp.write(str(movie))
fp.write('\n\n')
print(movies)
if __name__ == '__main__':
spider()
哈哈哈哈,这是我的CSDN第一篇文章!
鸣谢:https://ask.csdn.net/questions/7584110
如有侵权,联系删