翻译水平有限,欢迎阅读原文
一、深度学习
当前,深度学习已经成为一个热门话题。随着深度学习算法和GPU技术的发展,我们已经能够解决许多领域(计算机视觉、自然语言处理和机器人学)曾经认为不可能的事情。
深度学习是建立在传统的深度神经网络之上的。最近几年的热点是大数据集和强大的GPUs的使用。神经网络本质上是一种并行算法,因此多核GPUs的使用能够明显的减少用于训练深度神经网络的时间。以下,我将会讨论如何使用MATLAB以及深度卷积神经网络和GPUs开发一个对象识别系统
二、为什么将深度学习用于计算机视觉?
机器学习技术是利用数据(图像,信号,文本)来训练机器(模型)进而用于图像分类、对象检测以及语言翻译等领域。传统的机器学习技术依然可以用于解决具有挑战性的图像分类问题。但是如果将传统的机器学习技术直接用于处理图像,那么得到的结果会比较差,因为传统的方法忽略了图像的结构和属性。目前,性能最好的机器学习技术是利用特征提取算法来提取一副图像的特征部分(interesting parts),进而构成图像的特征向量(feature vectors)。然后再将其与传统的机器学习算法结合起来作进一步处理。
走进深度学习的世界!深度卷积神经网络(CNNs)属于深度学习算法中的一种特别类型。它弥补了传统机器学习技术的不足之处,改变了我们解决问题的方法。CNNs不仅能够用于分类,而且也能够直接用于图像的提取特征,因此避免了手动提取特征的环节。在计算机视觉应用领域中,你遇到的问题不仅有图像分类,还需要用一种好的计算机视觉技术来进行对象检测,同时也需要一些专业领域的知识并且还要了解如何有效的使用GPUs.本文以下部分,我将用一个对象识别的例子来说明用MATLAB进行深度学习是一件非常容易的事情,即使你没有计算机视觉领域的知识或者不会GPU编程也没关系。
三、对象检测与识别
我们的方法包括以下两个步骤:
a、对象检测:“宠物在视频中的什么位置?”
b、对象识别:“现在我知道了它在什么位置,不过它到底是猫还是狗呢?”
图1显示了最终结果。

图1 图像检测与识别系统
1、使用预先训练过的CNN分类器
第一步是训练分类器,该分类器能够区分猫与狗的图像。我可以通过:
a、收集一些图像,在合理的训练时间范围内进行裁剪、改变大小再标出图像中的猫和狗,或者
b、使用在大量常见图像中训练过的模型来解决我的问题。
对于本例,我将用第2种方法,因为第2种方法在实际中很常见。为此,我首先从一个在数据集ImageNet上训练过的CNN分类器开始。
然后,我会用到MatConvNet。MatConvNet是一个MATLAB CNN工具包,它使用NVIDIA cuDNN库来加速训练和预测时间(想要了解更多的cuDNN信息,可以参考这里 Parallel Forall post)。MatConvNet的下载和安装指令可以在其主页找到。以前,我已经在我的电脑上安装过MatConvNet,因此现在我可以直接使用如下MATLAB代码下载预训练过的CNN分类器,然后进行预测。注意:我还使用了cnnPredict()帮助函数,具体见我的Github。
%% Download and predict using a pretrained ImageNet model
% Setup MatConvNet
run(fullfile('matconvnet-1.0-beta15','matlab','vl_setupnn.m'));
% Download ImageNet model from MatConvNet pretrained networks repository
urlwrite('http://www.vlfeat.org/matconvnet/models/imagenet-vgg-f.mat', 'imagenet-vgg-f.mat');
cnnModel.net = load('imagenet-vgg-f.mat');
% Load and display an example image
imshow('dog_example.png');
img = imread('dog_example.png');
% Predict label using ImageNet trained vgg-f CNN model
label = cnnPredict(cnnModel,img);
title(label,'FontSize',20)
预训练过的CNN分类器在对象分类中的效果超出想象。CNN模型能够告诉我们在本例所用的图像中(图像2)有一个小猎犬。尽管这是一个好的开端,但是我们的问题与此有些不同。我想要:(1)在宠物周围画一个矩形(对象检测),然后(2)准确的标出其到底是狗还是猫(分类)。接下来,让我们利用预训练过的CNN模型建立一个狗vs猫的分类器开始。
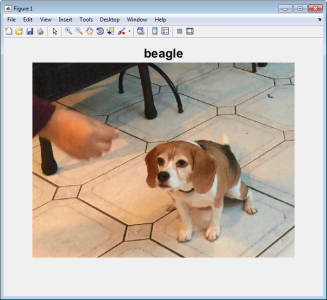
图2 预训练过的ImageNet模型将有一只狗的图像认为是“小猎犬”
2、训练狗vs猫分类器
对象识别还是比较简单的。首先要解决一个简单的分类问题——给定一幅图像,训练一个能够准确识别该图像中是否有一只狗或一只猫的分类器。只要有足够数量的猫和狗图像,然后再利用预训练过的CNN分类器,这个问题还是很容易实现的。
为了获取本例中所需要的图像,我让我的同事给我发了一些他们自己宠物的照片。然后我将其分成猫和狗两类并放在文件夹“pet_images”下的“cat”和“dog”文件夹里,这样做的好处是方便imageSet函数自动处理这些图像。随后,我用如下代码将其加入到MATLAB里。
%% Load images from folder
% Use imageSet to load images stored in pet_images folder
imset = imageSet('pet_images','recursive');
% Preallocate arrays with fixed size for prediction
imageSize = cnnModel.net.normalization.imageSize;
trainingImages = zeros([imageSize sum([imset(:).Count])],'single');
% Load and resize images for prediction
for ii = 1:numel(imset)
for jj = 1:imset(ii).Count
trainingImages(:,:,:,jj) = imresize(single(read(imset(ii),jj)),imageSize(1:2));
end
end
% Get the image labels
trainingLabels = getImageLabels(imset);
summary(trainingLabels) % Display class label distribution
3、利用CNN进行特征提取
下一步我要做到是利用上述数据和预训练过的ImageNet来提取图像特征。正如我之前提到的那样,CNNs可以从图像中提取一般的特征。然后,可以利用这些特征来训练新的分类器进而解决不同的问题,例如本例中的猫狗图像分类问题。
CNN算法是计算密集型的算法,因此其计算过程可能比较长。而鉴于CNN本质上是并行算法,因此我们可以利用GPUs来加速计算过程。下面是利用预训练过的模型来进行特征提取的代码,同时也与利用多线程CPU和利用GPU实现进行了比较。
%% Extract features using pretrained CNN
% Depending on how much memory you have on your GPU you may use a larger
% batch size. I have 400 images, so I choose 200 as my batch size
cnnModel.info.opts.batchSize = 200;
% Make prediction on a CPU
[~, cnnFeatures, timeCPU] = cnnPredict(cnnModel,trainingImages,'UseGPU',false);
% Make prediction on a GPU
[~, cnnFeatures, timeGPU] = cnnPredict(cnnModel,trainingImages,'UseGPU',true);
% Compare the performance increase
bar([sum(timeCPU),sum(timeGPU)],0.5)
title(sprintf('Approximate speedup: %2.00f x ',sum(timeCPU)/sum(timeGPU)))
set(gca,'XTickLabel',{'CPU','GPU'},'FontSize',18)
ylabel('Time(sec)'), grid on, grid minor
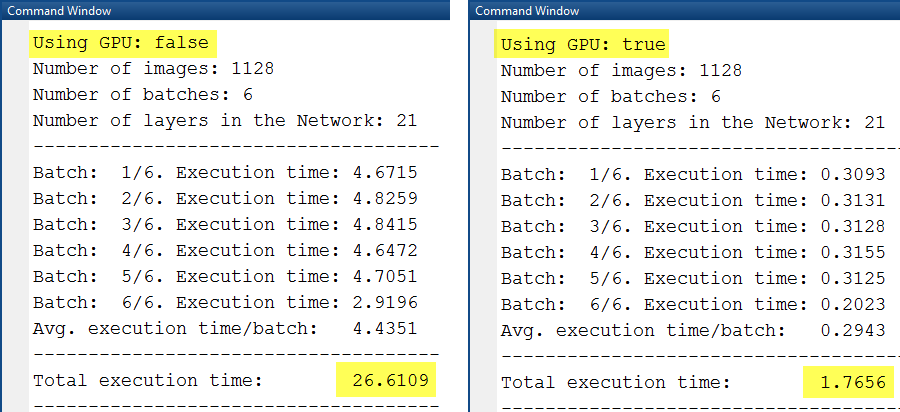
图3 利用CPU(左)和GPU(右)进行特征提取的时间对比
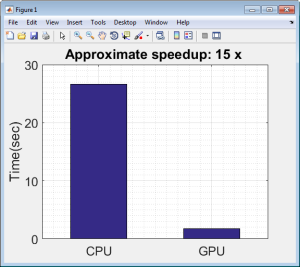
图4利用CPU和GPU从1128副图像中提取特征的时间
正如图4所示的那样,在本例中利用GPUs带来的性能提升是很明显的——大约提高了15倍左右。函数cnnPredict已经在MatConvNet里面的vl_simplenn预测函数里封装好了。如果你要用GPU来进行预测的话,只需改变图5中红色矩形部分的代码即可。并行计算工具箱中的gpuArray函数使你非常方便的将在CPU上实现的代码转换到GPU上。
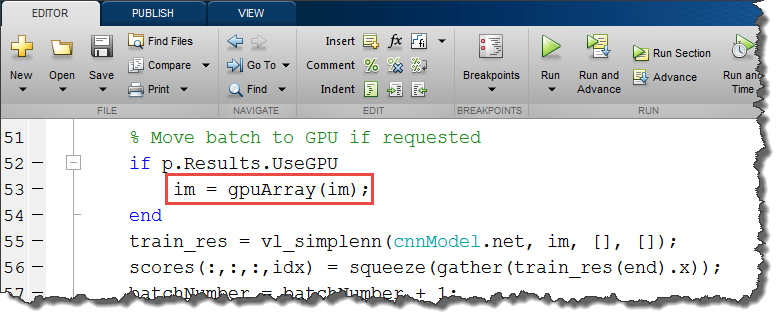
图5gpuArray和gather函数可以使你将MATLAB 工作空间中的数据转换到GPU中
4、利用CNN特征训练分类器
下一步,我首先用 fitcsvm函数提取特征,之后用cnnFeature作为输入或预测器,用trainingLabels作为输出或预测值,然后在此基础上来训练SVM分类器。当然,为了验证准确率我还会用交叉验证来测试分类器。验证得到的准确率是该分类器在实际数据上所得结果的无偏估计。
%% Train a classifier using extracted features
% Here I train a linear support vector machine (SVM) classifier.
svmmdl = fitcsvm(cnnFeatures,trainingLabels);
% Perform crossvalidation and check accuracy
cvmdl = crossval(svmmdl,'KFold',10);
fprintf('kFold CV accuracy: %2.2f\n',1-cvmdl.kfoldLoss)
svmmdl是我的分类器,该分类器可以用于区分图像中的宠物是猫还是狗。
5、对象检测
除了宠物之外,大多数图像或视频中还有许多其他的东西,有可能是树或浣熊之类的。要是这样的话,即使分类器很好(比如我上述用到的),其分类效果往往也不是很好。但是如果我们能够定位到图像中的对象(狗或者猫),然后提取该对象所在区域并将其用到分类器中,那么分类结果将明显改善。而对象定位的过程就叫做对象检测。
为了检测出所需对象,我要使用一种叫做 Optical Flow的技术。该技术的核心是对象像素在视频的连续帧中具有不同的位置。图6中显示了视频的一帧(带有运动矢量重叠)。
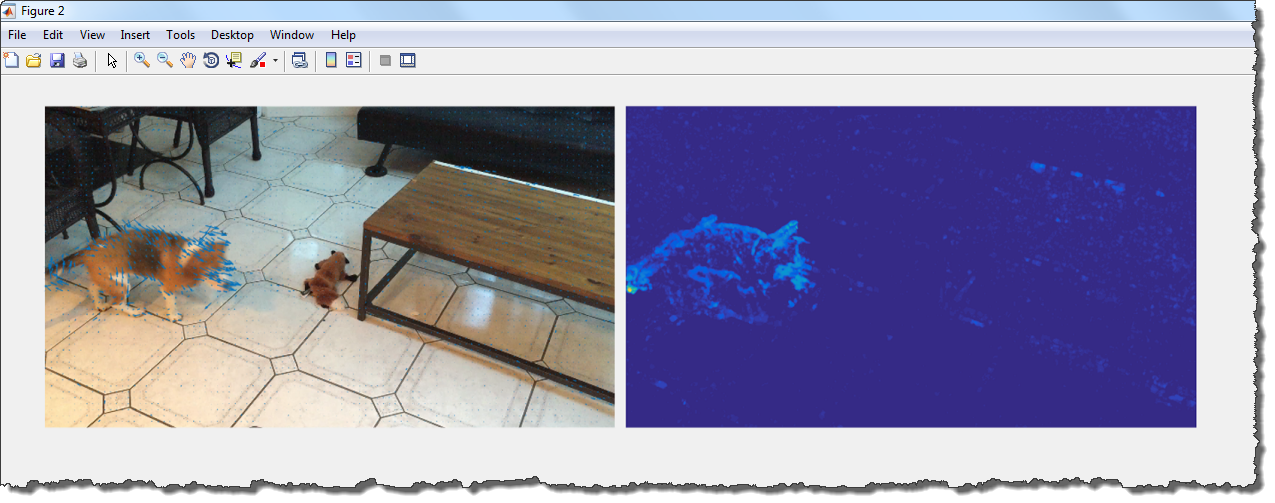
图6 视频中的一帧
对象检测的下一步是提取出运动的像素,然后使用 Image Region Analyzer app来分析二值图像中的连通部分以此来消除因相机运动而引起的噪声像素。
四、对象检测与识别步骤
目前为止,我已经有了建立一个宠物检测与识别系统所需的基本步骤,接下来我将把它们整理汇总。首先来快速回顾一下这些基本步骤:
A、 检测宠物在图像中的位置;
B、 提取宠物所在区域并用训练好的CNN来提取特征;
C、 利用SVM分类器进行(特征)分类。
宠物检测与识别
将上述基本步骤整理后,最终我可以得到如下MATLAB代码所示的完整宠物检测与识别系统。
vr = VideoReader(fullfile('PetVideos','videoExample.mov'));
vw = VideoWriter('test.avi','Motion JPEG AVI');
opticFlow = opticalFlowFarneback;
open(vw);
while hasFrame(vr)
frameNumber = frameNumber + 1;
videoFrame = readFrame(vr);
vFrame = imresize(videoFrame,0.25);
frameGray = rgb2gray(vFrame);
bboxes = findPet(frameGray,opticFlow);
if ~isempty(bboxes)
img = zeros([imageSize size(bboxes,1)]);
for ii = 1:size(bboxes,1)
img(:,:,:,ii) = imresize(imcrop(videoFrame,bboxes(ii,:)),imageSize(1:2));
end
[~, scores] = cnnPredict(cnnModel,img,'UseGPU',true,'display',false);
label = predict(svmmdl,scores);
videoFrame = insertObjectAnnotation(videoFrame,'Rectangle',bboxes,cellstr(label),'FontSize',40);
end
writeVideo(vw,videoFrame);
fprintf('Frames processed: %d of %d\n',frameNumber,ceil(vr.FrameRate*vr.Duration));
end
close(vw);
五、结论
在解决现实世界的计算机视觉问题时,往往需要根据你的应用需求(性能、准确率和方案简洁性)进行权衡。就视觉识别的准确度来说,深度学习这样的高级技术相比传统机器学习已经有了显著提高。但是对于主流的应用来说,其性能代价往往也很显著,不过GPU技术可以以数量级的加速倍数来弥补这些代价。
MATLAB使得深度学习计算机视觉工作变得更加方便。一些易于使用的应用程序与其他编程环境,开源计算机视觉库和机器学习算法以及支持CUDA的显卡等技术的结合使得MATLAB成为设计与快速实现计算机视觉问题的理想平台。
相关连接