1 循环的语法结构
在Python中,循环是一种控制结构,用于重复执行一段代码,直到满足特定条件。Python中有两种循环结构:for循环和while循环。
for循环:for循环用于遍历可迭代对象(如列表、元组、字典、集合等)中的元素。它的语法结构如下:
for 变量 in 可迭代对象:
循环体(要重复执行的代码)
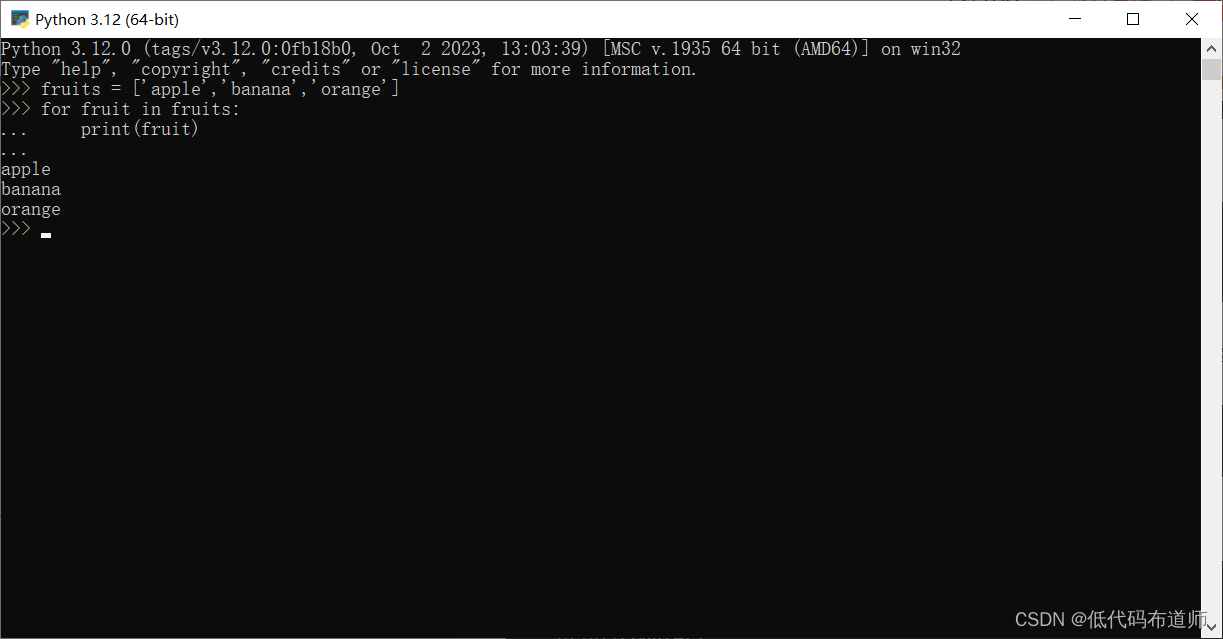
例如,遍历一个列表并打印每个元素:
fruits = ['apple', 'banana', 'orange']
for fruit in fruits:
print(fruit)
while循环:while循环在给定条件为真时重复执行一段代码。它的语法结构如下:
while 条件:
循环体(要重复执行的代码)
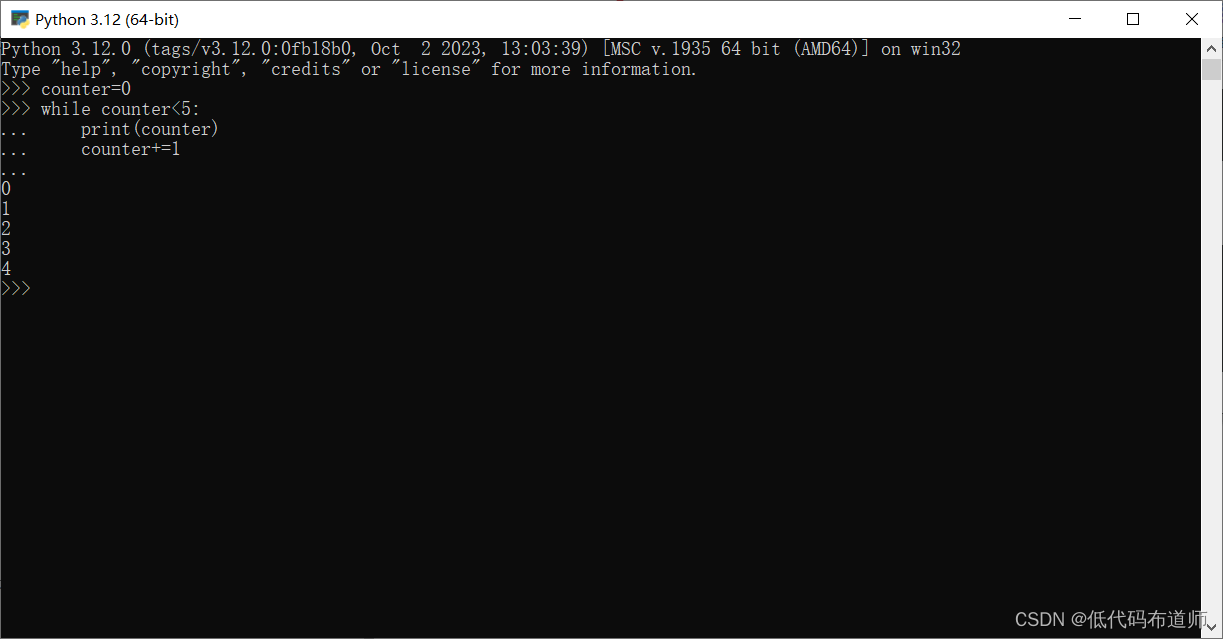
例如,计数器从0开始,每次循环加1,直到计数器达到5:
counter = 0
while counter < 5:
print(counter)
counter += 1
for循环和while循环都可以与break和continue语句一起使用,以更好地控制循环的执行。break语句用于提前终止循环,而continue语句用于跳过当前迭代并进入下一次循环。
2 break和continue的示例
break 和 continue 是 Python 中用于控制循环流程的关键字。下面分别给出它们的示例:
-
break:用于跳出当前循环,不再执行循环体中的剩余代码。for i in range(10): if i == 5: break print(i)
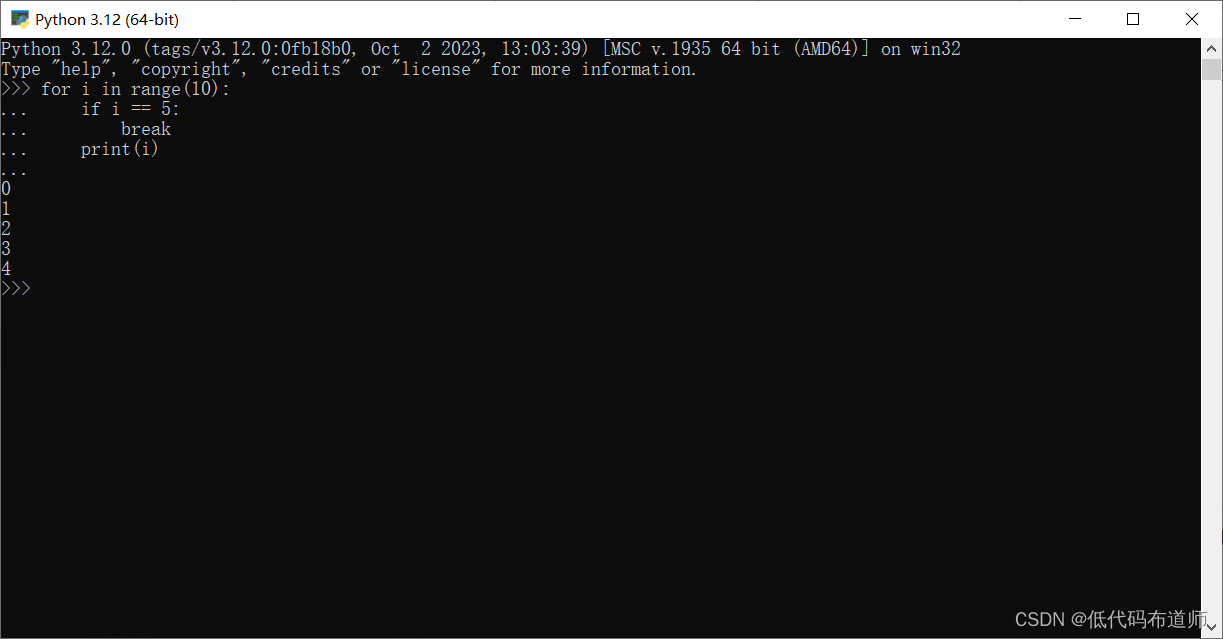
在这个示例中,循环会遍历 0 到 9 的整数。当 i 等于 5 时,break 语句会被执行,跳出循环,不再打印 i 的值。因此,这个循环只会打印 0 到 4 的整数。
-
continue:用于跳过当前循环的剩余代码,直接进入下一次循环。for i in range(10): if i % 2 == 0: continue print(i)
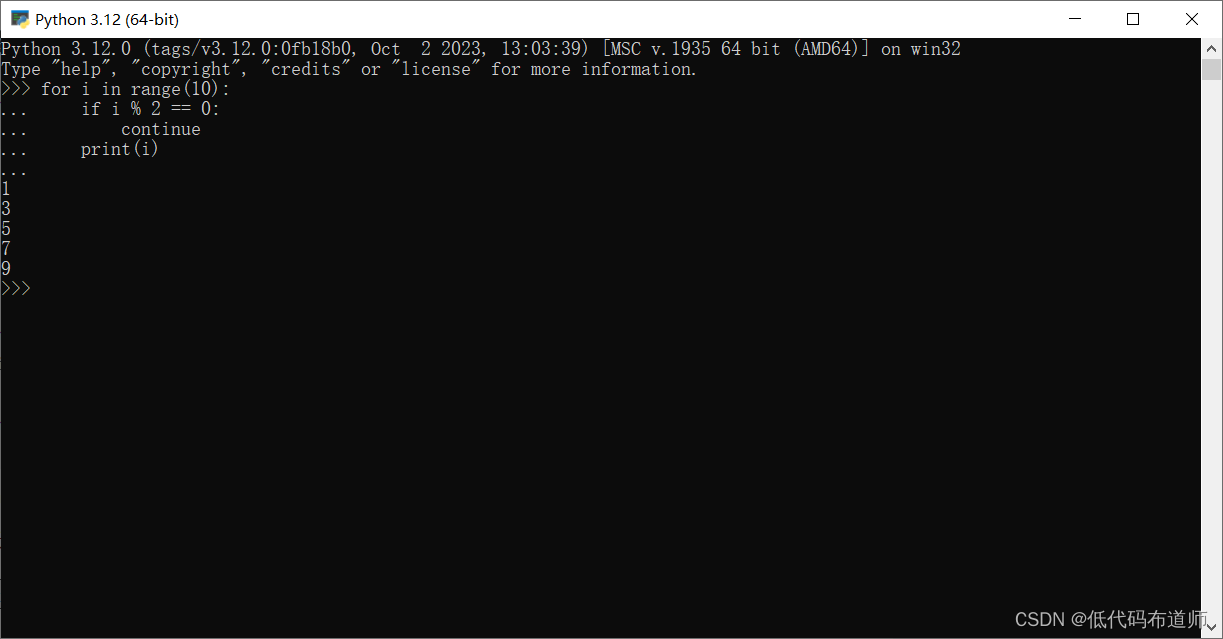
在这个示例中,循环会遍历 0 到 9 的整数。当 i 是偶数时,continue 语句会被执行,跳过当前循环的剩余代码,直接进入下一次循环。因此,这个循环只会打印 1 到 9 的奇数。
通过使用 break 和 continue,我们可以更灵活地控制循环的执行流程,以满足不同的需求。
3 可迭代对象
在Python中,可迭代对象(Iterable)是指包含__iter__()方法或__getitem__()方法的对象。这意味着可以对这些对象进行迭代操作,如在for循环中遍历它们的元素。
以下是一些常见的可迭代对象:
- 列表(List):例如
[1, 2, 3, 4, 5]。 - 元组(Tuple):例如
(1, 2, 3, 4, 5)。 - 字符串(String):例如
'hello, world'。 - 集合(Set):例如
{1, 2, 3, 4, 5}。 - 字典(Dictionary):例如
{'a': 1, 'b': 2, 'c': 3}。 - 生成器(Generator):例如
(x**2 for x in range(5))。
可迭代对象允许我们在for循环中轻松地遍历它们的元素,而无需关心底层的实现细节。这使得Python代码更简洁、易读。
4 列表
列表(List)是Python中的一种数据结构,它是一个有序的元素集合,可以包含任意数量的元素。列表中的元素可以是不同类型的数据,如整数、浮点数、字符串、布尔值等。列表是可变的,这意味着我们可以修改列表中的元素,添加或删除元素。
列表使用方括号[]表示,并用逗号,分隔其中的元素。例如:
my_list = [1, 2, 3, 4, 5]
列表具有以下常用操作:
-
获取元素:通过索引访问列表中的元素。索引从0开始,负数索引表示从末尾开始计数。例如:
first_element = my_list[0] # 获取第一个元素 last_element = my_list[-1] # 获取最后一个元素 -
添加元素:在列表末尾添加一个元素。例如:
my_list.append(6) # 在列表末尾添加元素6 -
插入元素:在指定索引处插入一个元素。例如:
my_list.insert(1, 7) # 在索引1处插入元素7 -
删除元素:从列表中删除指定索引处的元素。例如:
my_list.pop(1) # 删除索引1处的元素 -
修改元素:通过索引修改列表中的元素。例如:
my_list[0] = 0 # 将索引0处的元素修改为0 -
列表推导式:使用简洁的语法快速创建新列表。例如:
squares = [x**2 for x in range(1, 6)] # 创建一个包含1到5的平方数的新列表 -
列表排序:对列表的元素进行排序。例如:
my_list.sort() # 对列表的元素进行升序排序 -
列表切片:获取列表的一部分。例如:
sublist = my_list[1:4] # 获取索引1到3的元素组成的新列表 -
列表长度:获取列表中元素的数量。例如:
length = len(my_list) # 获取列表的长度 -
列表遍历:使用
for循环遍历列表中的每个元素。例如:for element in my_list: print(element)
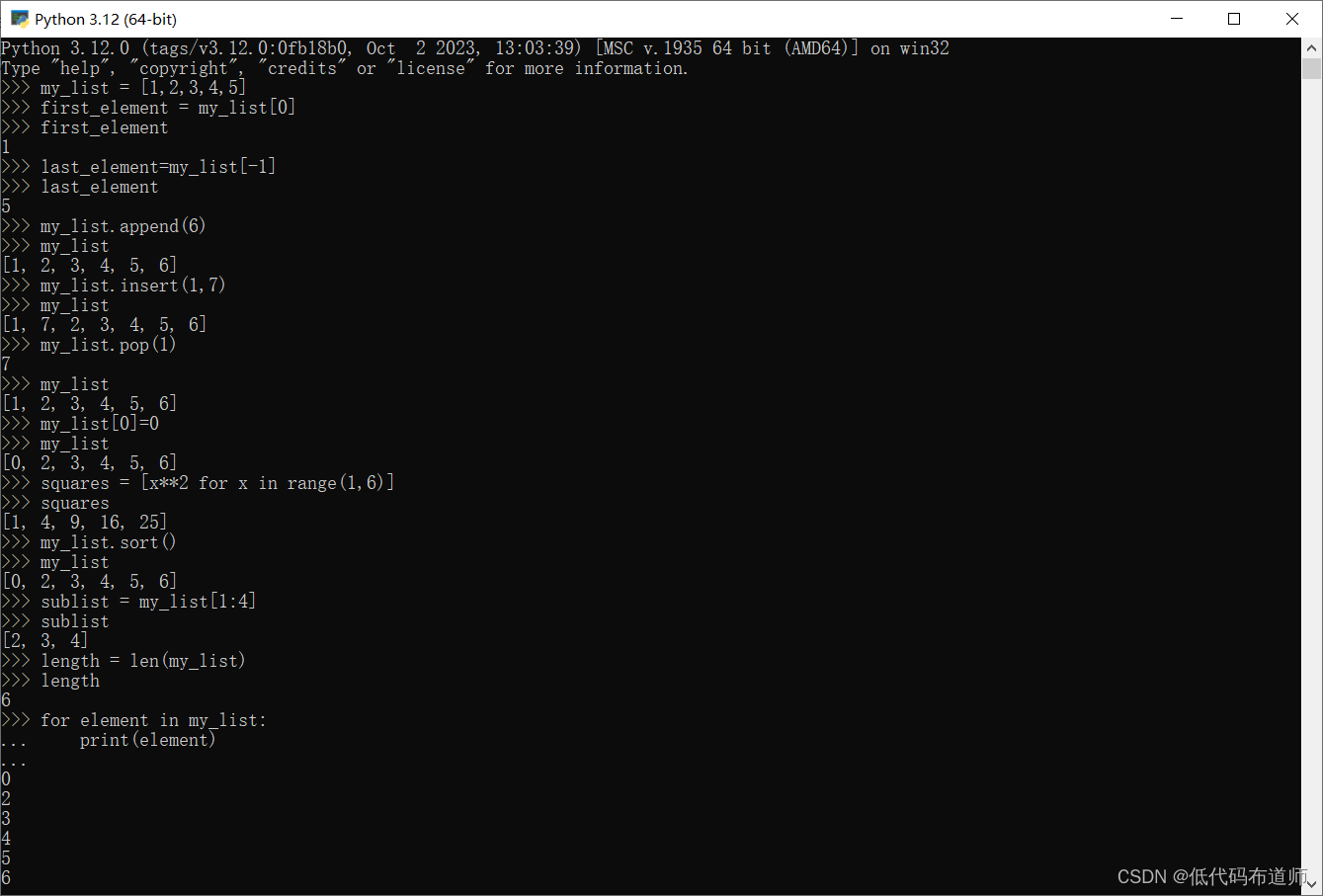
列表是Python中最常用的数据结构之一,它们在处理数据时非常方便和灵活。
5 元组
元组(Tuple)是 Python 中的一种数据结构,它是一个不可变的、有序的元素集合。元组中的元素可以是任何数据类型,如整数、浮点数、字符串、列表、元组、集合等。元组通常用于存储一组相关或不相关的数据,以便于后续的处理和分析。
元组的创建方式有以下几种:
-
使用圆括号
()创建空元组,然后添加元素:my_tuple = () my_tuple = (1, 2, 3, 4, 5) -
使用
tuple()函数创建元组,将多个值作为参数传递给函数:my_tuple = tuple() my_tuple = tuple([1, 2, 3, 4, 5]) -
使用列表的
tuple()方法将列表转换为元组:my_list = [1, 2, 3, 4, 5] my_tuple = tuple(my_list)
元组的主要操作包括:
-
获取元组中的元素:使用索引(从 0 开始)或切片操作来获取元组中的元素。例如:
first_element = my_tuple[0] second_element = my_tuple[1] third_element = my_tuple[2:] -
判断元组是否为空:使用
not运算符和len()函数来判断元组是否为空。例如:if not my_tuple: print('The tuple is empty') else: print('The tuple is not empty') -
获取元组的长度:使用
len()函数获取元组的长度。例如:length = len(my_tuple) -
遍历元组:使用
for循环遍历元组中的所有元素。例如:for element in my_tuple: print(element) -
连接元组:使用
+运算符将两个或多个元组连接起来。例如:tuple1 = (1, 2, 3) tuple2 = (4, 5, 6) combined_tuple = tuple1 + tuple2

元组在处理数据时非常有用,尤其是在需要存储和访问有序数据集的场合。与列表相比,元组是不可变的,这意味着一旦创建了元组,就不能修改其内容。这使得元组在某些情况下更安全、更易于处理。
6 列表和元组的应用场景
在Python中,元组和列表都是常用的数据结构,它们有以下区别:
- 可变性:列表是可变的,可以修改、添加和删除元素;而元组是不可变的,不能修改、添加或删除元素。
- 语法:列表使用方括号
[]表示,元组使用括弧()表示。 - 性能:由于元组是不可变的,它们在内存中的存储效率较高,而且在处理大量数据时,访问速度也较快。
根据这些区别,我们可以根据实际需求选择使用元组还是列表:
-
当需要存储不可变的数据时,使用元组。例如,一个日期(年、月、日)可以表示为一个元组,因为日期是不可变的。
date = (2022, 10, 1) -
当需要存储可变的数据时,使用列表。例如,一个购物车中的商品列表可以表示为一个列表,因为购物车中的商品可以被添加、删除或修改。
shopping_cart = ['apple', 'banana', 'orange'] -
当需要对数据进行修改、添加或删除操作时,使用列表。例如,在处理用户输入的数据时,我们可能需要添加、删除或修改数据。
user_data = ['Alice', 'Bob', 'Charlie'] user_data.append('David') # 添加新用户 user_data.remove('Bob') # 删除用户 user_data[0] = 'Alicia' # 修改用户名 -
当需要对数据进行快速访问和迭代操作时,使用元组。例如,在处理大量静态数据时,使用元组可以提高性能。
countries = ('China', 'USA', 'Japan', 'Germany', 'France') for country in countries: print(country)
总之,根据实际需求和数据的可变性,我们可以选择使用元组或列表来存储和操作数据。
7 集合
集合(Set)是Python中的一种数据结构,它是一个无序且不重复的元素集合。集合中的元素可以是任何可哈希(hashable)的类型,如整数、浮点数、字符串、元组等。集合的主要操作包括添加、删除、检查元素是否存在、计算元素数量等。
集合的创建方式有以下几种:
-
使用大括号
{}创建空集合,然后添加元素:my_set = { 1, 2, 3, 4, 5} -
使用
set()函数创建空集合,然后添加元素:my_set = set() my_set.add(1) my_set.add(2) my_set.add(3) my_set.add(4) my_set.add(5) -
使用集合运算符创建集合,如
|(并集)、&(交集)、-(差集)等:set1 = { 1, 2, 3, 4, 5} set2 = { 4, 5, 6, 7, 8} # 并集 union_set = set1 | set2 print(union_set) # {1, 2, 3, 4, 5, 6, 7, 8} # 交集 intersection_set = set1 & set2 print(intersection_set) # {4, 5} # 差集 difference_set = set1 - set2 print(difference_set) # {1, 2, 3}
集合的主要操作包括:
-
添加元素:使用
add()方法向集合中添加元素。my_set.add(6) -
删除元素:使用
remove()方法从集合中删除指定的元素。如果元素不存在,会引发KeyError。my_set.remove(1) -
检查元素是否存在:使用
in关键字或contains()方法检查元素是否在集合中。if 5 in my_set: print('5 is in the set') elif 6 in my_set: print('6 is in the set') else: print('Neither 5 nor 6 is in the set') -
计算元素数量:使用
len()函数或size()方法获取集合中元素的数量。num_elements = len(my_set) -
集合运算:使用集合运算符(如
|、&、-等)进行集合间的运算。union_set = set1 | set2 intersection_set = set1 & set2 difference_set = set1 - set2
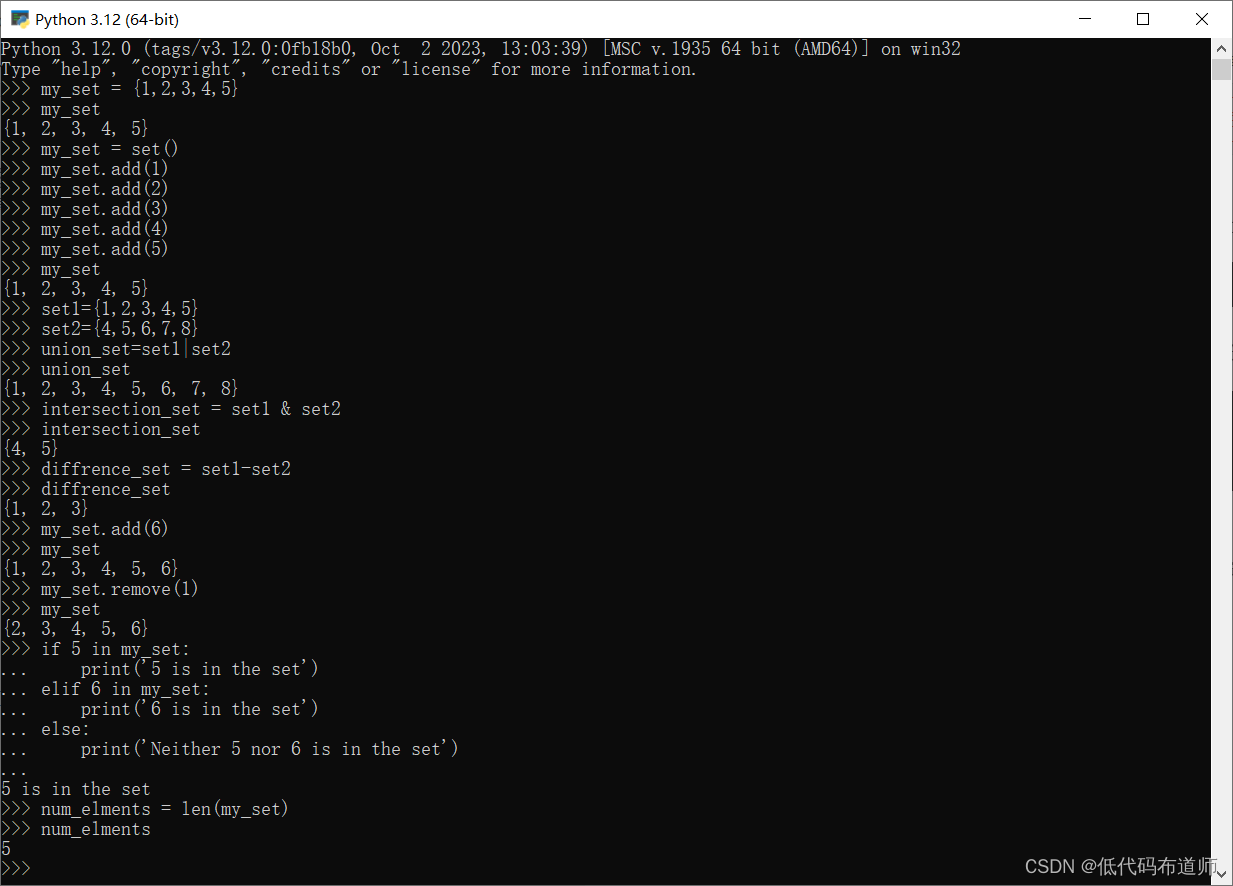
集合在处理数据时非常有用,尤其是在需要去除重复元素或进行集合运算的场景中。
8 字典
字典(Dictionary)是Python中的一种数据结构,它是一种无序的、可变的、键-值对(key-value)的数据类型。字典中的每个键(key)都是一个唯一的标识符,与之对应的值(value)可以是任何数据类型,如整数、浮点数、字符串、列表、元组、集合等。字典中的键和值之间通过冒号(:)分隔,每个键-值对之间用逗号(,)分隔。
字典的主要操作包括:
-
创建字典:使用大括号
{}创建空字典,然后添加键-值对。例如:my_dict = { 'name': 'Alice', 'age': 30, 'city': 'New York'} -
获取字典中的值:使用键作为索引来获取字典中的值。例如:
name = my_dict['name'] age = my_dict.get('age') -
修改字典中的值:使用键作为索引来修改字典中的值。例如:
my_dict['age'] = 31 -
添加键-值对:使用键作为索引向字典中添加新的键-值对。如果键已经存在,则覆盖原有的值。例如:
my_dict['gender'] = 'female' -
删除键-值对:使用键作为索引从字典中删除指定的键-值对。如果键不存在,会引发
KeyError。例如:del my_dict['age'] -
检查键是否存在:使用
in关键字或has_key()方法检查键是否在字典中。例如:if 'name' in my_dict: print('name is in the dictionary') elif 'age' in my_dict: print('age is in the dictionary') else: print('Neither name nor age is in the dictionary') -
获取字典中的所有键:使用
keys()方法获取字典中的所有键。例如:keys = my_dict.keys() -
获取字典中的所有值:使用
values()方法获取字典中的所有值。例如:values = my_dict.values() -
获取字典中的键-值对:使用
items()方法获取字典中的所有键-值对。例如:items = my_dict.items()

字典在处理数据时非常有用,尤其是在需要存储和检索复杂数据结构的场景中。
9 生成器
生成器(Generator)是一种特殊的迭代器,它允许你创建一个可迭代对象,该对象在每次迭代时动态生成新的值,而不是预先计算所有值并将它们存储在内存中。生成器在处理大量数据或需要按需生成数据的场景中非常有用,因为它们可以节省内存并提高性能。
生成器使用yield关键字来返回一个值,并在下一次调用时暂停执行,直到再次请求下一个值。这使得生成器可以在需要时动态生成值,而不是一次性生成所有值。
以下是一个简单的生成器示例,用于生成前n个平方数:
def square_generator(n):
for i in range(1, n+1):
yield i**2
# 使用生成器
for square in square_generator(5):
print(square)
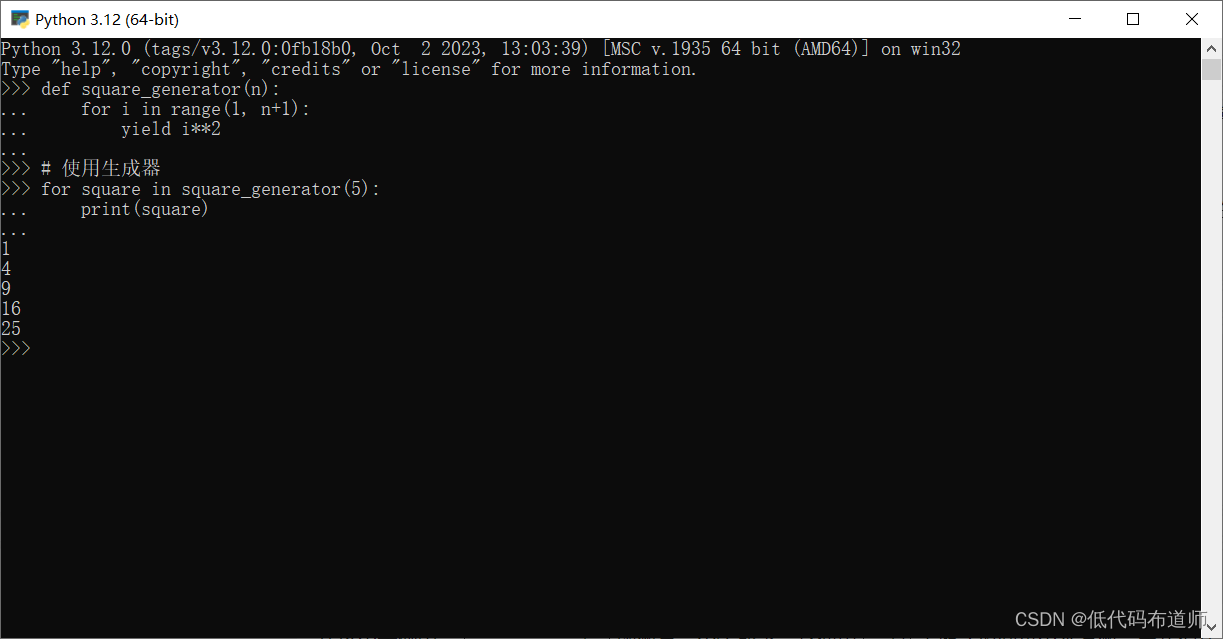
在这个示例中,square_generator函数是一个生成器,它使用yield关键字返回每个平方数。当我们在for循环中使用生成器时,它会在每次迭代时动态生成下一个平方数,而不是一次性计算所有平方数。这意味着生成器在处理大量数据时可以节省内存。