原创 予墨 AI速览 2023-10-07 13:30
收录于合集
#AI论文解读3个
##Agent5个
在人工智能领域,人们对Agent的期待日益增长。每当基于Agent的新开源工具或产品出现时,都能引发热烈的讨论,比如之前的AutoGPT。对于对Agent感兴趣的朋友们,我推荐一篇论文,它全面地介绍了Agent的架构,对于理解Agent的全局有着重要的价值。

https://browse.arxiv.org/pdf/2308.11432.pdf
这篇论文详细解读了Agent的概念、发展历史以及近期的研究热点。除了这些基础知识,我认为最有价值的部分在于,它总结了基于大型语言模型(LLM)的Agent的架构,使我们能够按照一定的标准范式去设计自己的Agent。
我这篇文章主要从两个关键方面来阐述基于LLM的Agent的构建策略:设计Agent架构以更好地发挥LLM的能力,以及如何赋予Agent完成不同任务的能力。
在Agent架构设计方面,该论文提出了一个统一的框架,包括Profile模块、Memory模块、Planning模块和Action模块。

Profile模块:
定义和管理Agent角色的特性和行为。它包含一系列参数和规则,描述了Agent的各种属性,如角色、目标、能力、知识和行为方式等。这些属性决定了Agent如何与环境交互,如何理解和响应任务,以及如何进行决策和规划。这个模块提出了三种Agent角色生成方式,包括LLM生成方法、数据集对齐方法和组合方法。
1. LLM生成方法:利用大语言模型自动生成代理的个人特征,比如年龄、性别、个人喜好等背景信息。具体做法是:首先设定代理的组成规则,明确目标人群中代理应具备的属性;然后指定几个手工创建的种子配置文件作为示例;最后利用语言模型生成大量代理配置文件。这种方法可以快速批量生成配置文件,但由于缺乏精确控制,生成的代理可能会缺乏细节。
2. 数据集对齐方法:是从真实世界的人口数据集中获取代理的配置文件信息,比如通过抽取人口调查数据组织成自然语言描述。这样可以使代理行为更真实可信,准确反映真实人口的属性分布。但需要可靠的大规模数据集支持。
3. 组合方法:利用真实数据集生成一部分关键代理,确保反映真实世界规律;然后用LLM生成方法补充大量其他代理,拓展代理数量。这样既保证了代理的真实性,又实现了充足的代理数量,使系统可以模拟更复杂的社会交互。谨慎的配置文件设计是构建有效代理系统的基础。
Memory模块:
在Agent系统中扮演重要角色,它存储和组织从环境中获取的信息,以指导未来行动。
结构上,内存模块通常包含短期记忆和长期记忆两个部分。短期记忆暂存最近的感知,长期记忆存储重要信息供随时检索。
格式上,内存信息可以用自然语言表达,也可以编码为向量嵌入提高检索效率。还可以利用数据库存储,或组织为结构化列表表示内存语义。
操作上,主要通过记忆读取、写入和反射三种机制与环境交互。读取提取相关信息指导行动,写入存储重要信息,反射总结见解提升抽象水平。
Planning模块:
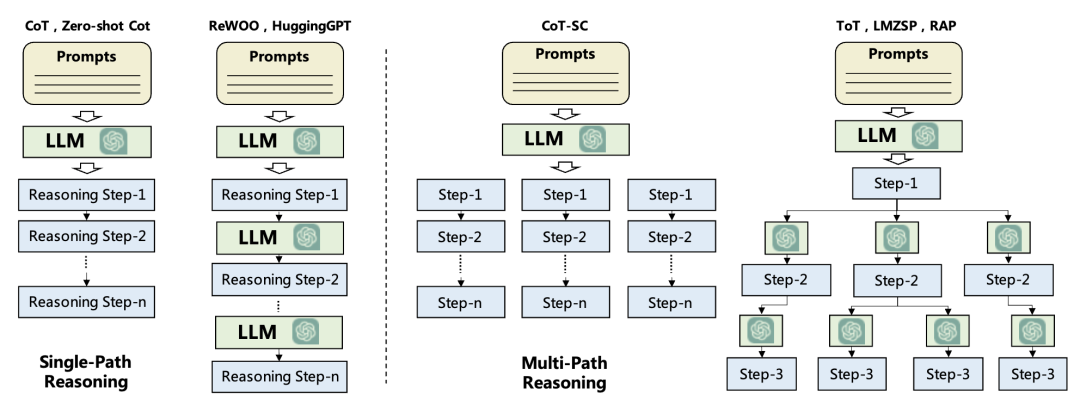
主要任务是帮助Agent将复杂的任务分解为更易处理的子任务,并制定出有效的策略。它大致分为两种类型,一种是不依赖反馈的计划,另一种则是基于反馈的计划。
不依赖反馈的计划在制定过程中并不参考任务执行后的反馈,它有几种常用的策略。比如单路径推理,它按照级联的方式,一步一步地生成计划。另外,还有多路径推理,它会生成多个备选的计划路径,形成树状或图状的结构。当然,我们也可以利用外部的规划器进行快速搜索,以找出最优的计划。
基于反馈的计划,它会根据任务执行后的反馈来调整计划,这种方式更适合需要进行长期规划的情况。反馈的来源可能来自任务执行结果的客观反馈,也可能是根据人的主观判断给出的反馈,甚至还可以是由辅助模型提供的反馈。
Action模块:
职责是将抽象的决策转化为具体的行动,它就像是一个桥梁,连接了Agent的内部世界与外部环境。在执行任务时,需要考虑行动的目标、生成方式、应用范围以及可能产生的影响。
理想的行动应当是有目的的,例如完成特定任务、与其他代理进行交流或者探索环境。行动的产生可以依赖于查询过去的记忆经验,或者遵循预设的计划。而行动的范围,不仅可以通过利用如API和知识库等外部工具来扩展,还需要发挥大型语言模型(LLM)的内在能力,例如规划、对话及理解常识等。
架构就像PC的硬件,但仅依赖架构设计是不够的,我们还需要赋予Agent完成不同任务的能力,这些被视为“软件”资源。论文中提出了几种方法,包括模型微调、提示工程和机械工程。其中提示工程应该是最为常见的一种形式了,我们常听说的提示词工程师就是在这个语境下的角色。

-
模型微调。使用特定任务数据对模型进行微调,提升相关能力。数据可以来自人类注释、LLM生成或实际应用中收集。这可以使Agent行为更符合人类价值观。
-
提示工程。通过自然语言描述向LLM灌输所需的能力,然后将描述作为提示指导Agent操作。这可以让Agent快速获得指定的软件能力。
-
机械工程。主要涵盖:
-
试错法:Agent先执行操作,根据效果调整行动。逐步优化。
-
众包法:整合多个Agent的见解,形成更新的集体响应。
-
经验积累法:Agent通过不断探索积累经验,逐步提升软件能力。
-
自我驱动法:Agent自主设置目标并在环境中不断探索,最终获得软件能力。
基于LLM的Agent的设计和构建策略是一个复杂且有挑战性的任务。随着技术的进步,我相信未来会有更多优秀的AI应用通过Agent产生,普通用户也能通过开源项目打造自己的Agent,成为AI时代的超级个体。希望大家能早点行动起来,多做些知识储备,待技术成熟时,尽快使用或做出自己的Agent。

AI速览
49篇原创内容
公众号
相关阅读:
实战:如何用AI Agent实现ChatGPT流程化写作,产能翻倍