目录
前言
我们平时在写代码的时候会出现各种错误,面对程序出现的错误我们之前好像没有介绍过如何高效、科学、系统地处理这种错误!您平时一般是如何说处理的呢?走读?猜?还是???无论哪种方式其实都是不是最高效且合理的!本期小编将介绍VS常用调试技巧!
本期内容介绍
什么是Bug?
调试及调试的重要性
Debug和Release介绍
windows环境调试介绍
一些调试实例
如何写出"好"代码?
常见错误解析
一、什么是Bug?
Bug的意思是:飞蛾或昆虫!在计算机中用Bug来代指一些未被发现的或隐藏的错误或缺陷!
下面是百度百科的介绍以及历史上第一个Bug的图片:


这是关于Bug的更详细的链接程序错误_百度百科 (baidu.com)感兴趣的可以看看!
二、调试以及调试的重要性
2.1什么是调试?
调试又称除错!是当程序或电子仪器出现了问题之后对程序或电子仪器进行科学排查、寻找问题以及解决问题的过程!
2.2调试的基本步骤

OK,我们来写个有问题程序来走一遍上面步骤:(求n的阶乘和)
int main()
{
int n = 0;
scanf("%d", &n);
int sum = 0, ret = 1;//sum存储n的阶乘和 ret用于存储每一个的阶乘
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("sum = %d",sum);
return 0;
}我们知道3!和为:1!+ 2! + 3! = 1 + 2*1 + 3* 2*1 = 9 我们来看结果:
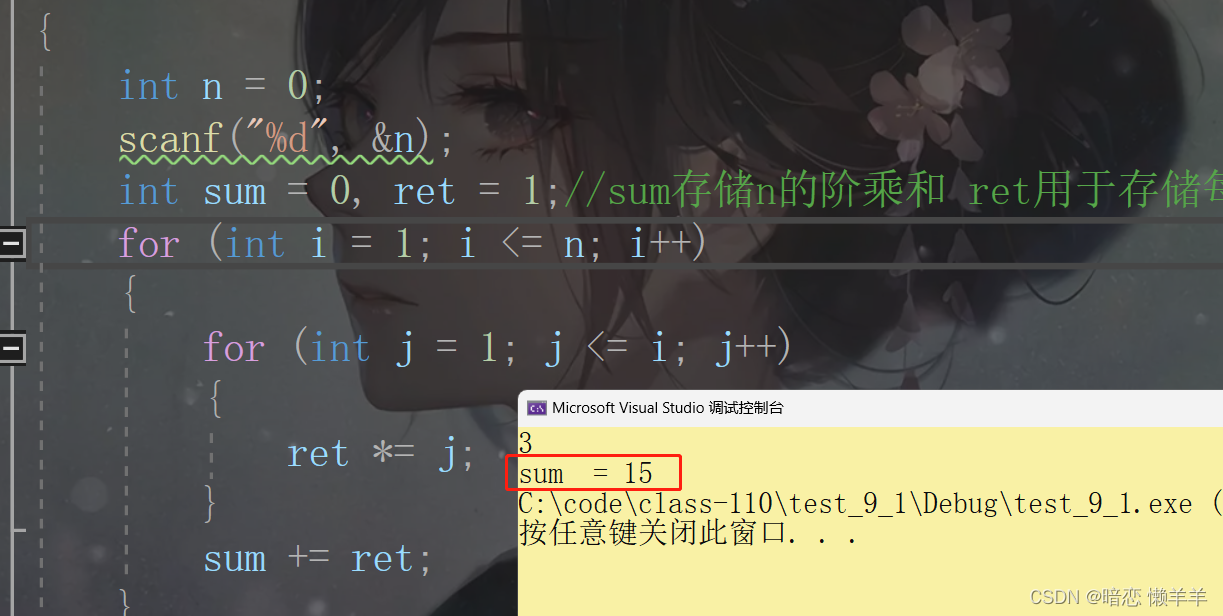
怎么是15???这和我们的预期不一样,是不是就是出现了Bug了!我们就得想办法来解决这个问题!第一步:发现问题,结果和预期不一样,已经发现问题!第二步:定位问题:我们这里对变量sum 和 ret分别监视,一一比对每一次sum、ret的值是否与预期一样!第三步:确定错误原因:

这里确定了问题的原因,怎么解决呢?我们发现这里应该对每一个i的阶乘都要单独算,要就是说每一个ret都应该独立的,每一次的ret都应该是没有被用过的!那我们在每次计算每个i的时候对ret一开始先置 1即可!第四步:解决问题
int main()
{
int n = 0;
scanf("%d", &n);
int sum = 0, ret = 1;//sum存储n的阶乘和 ret用于存储每一个的阶乘
for (int i = 1; i <= n; i++)
{
ret = 1;//防止后面的值重复叠加
for (int j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("sum = %d",sum);
return 0;
}OK,第五步:重新测试:

三、Debug和Release介绍
我们的VS编译器上会经常看到一个东西是Debug!

其实不止有Debug还有一个是Release!

他们是什么呢?下面我们就来介绍一下Debug和Release:
Debug和Release
Debug:
Debug被称为调试版本,它包含了调试信息,不做任何优化,用于程序员调试解决问题!
Release:
Release被称为发布版本,它往往是对程序进行了优化,是的代码在运行速度以及空间大小都是最优的!用于用户使用的!
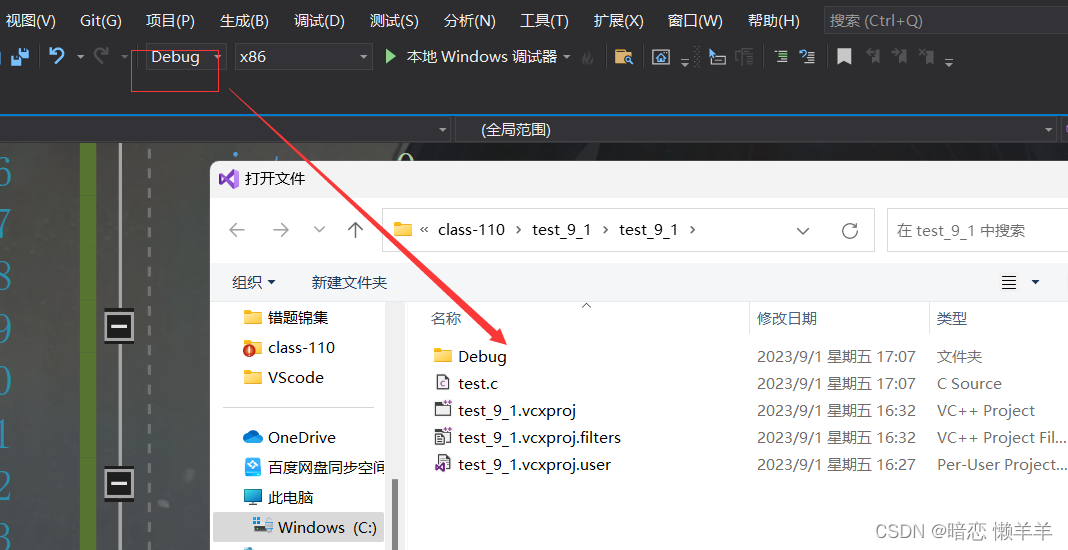
无论是Debug还是Release只要编译就会有相应的文件包,(就和Java中的.class类似,一个类编译一次有一个.class文件):
只在Debug编译:
再在Release下编译:
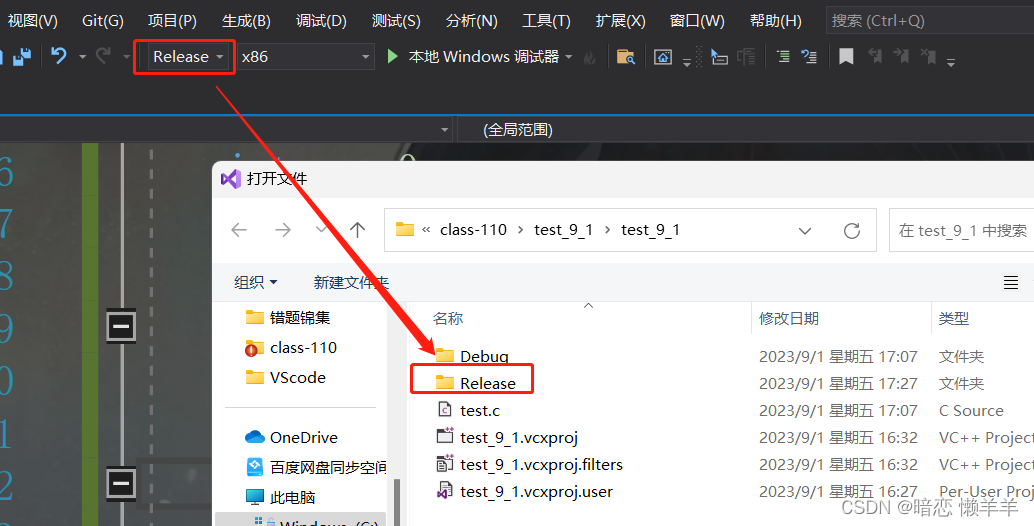
由于Release是用户使用的所以不能用来调试,而Debug是对程序员的所以可以用来调试!
OK。我们来看一段代码看看在两个版本下的差异:
Debug:
int main()
{
int i = 0;
int arr[10] = { 0 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}我们先不管结果为什么是这样!我们先来看看两者结果的差别!:
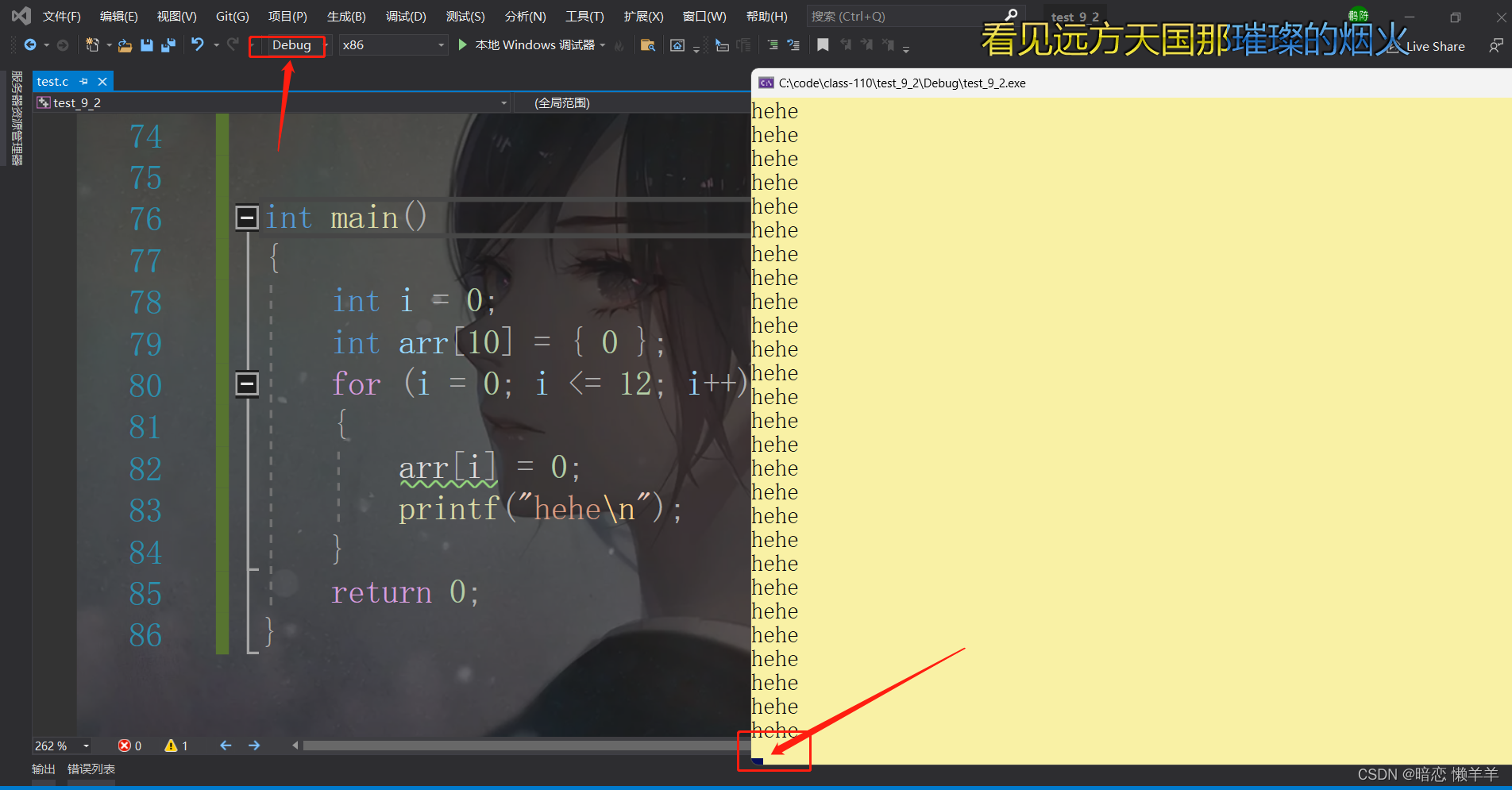
这可不是结束了,这就是典型的死循环!!!为什么死循环我们不管,待会分析!
再来看看Release版本下的结果:

这就很好的说明了release版本对程序的优化!!!具体如何优化的这个得问问微软的开发工程师~
四、windows环境下的调试介绍
4.1调试环境
本期所有调试都是在VS2019的Debug下进行的!!!
4.2一些调试常用的快捷键

这里应该最清楚的一个就是:ctrl+F5了我们执行代码就是这个,他其实是开始执行不调试!!!除此之外还有很多快捷键!我们下面介绍几个最常用的!
F5
启动调试,常用于直接跳到下一个断点处!(这个断点是逻辑断点,非物理断点)
F9
创建和取消断点,然后F5直接跳过去到当前断点位置,然后就可以一步一步调试观察是否和预期一样!
所以,F5和F9是一起配合使用的!
F10
逐过程,通常是用来处理一个过程例如一次函数调用或一条语句!
F11
逐语句,每一次只能执行一条语句,可以进到函数内部!
如果您在调试的时候,上面的键按一下不起作用的话,有可能是Fn打开了,关掉Fn即可或者是上面的键+Fn配合使用即可!!!
下面是知乎的一篇VS2019的调试技巧快捷键介绍:VS2019调试快捷键大全
4.3调试时查看当前程序的信息
a、查看临时变量的值
在开始调试之后如何查看临时变量的值!其实我们上面已经用到了,只不过刚刚没有介绍!
我们按下F10之后,启动调试后,点击调试,进去选择窗口找到监视,有四个窗口随便一个都可以!
OK,我们在来一个看一个代码顺便调试看一下临时变量!
void swap(int x, int y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 3;
int b = 5;
printf("交换前:a = %d b = %d\n", a, b);
swap(a, b);
printf("交换后:a = %d b = %d\n", a, b);
return 0;
}这就是交换两个数的代码,我们先来看看结果!

似乎没有交换,其实原因我们都清楚--》形参是实参的一份临时拷贝,改变形参不改变实参!
这里我们假装不知道,我们此时程序的结果和我们的预期不符合出了问题!就需要调试,我们来练习一下刚刚学的!
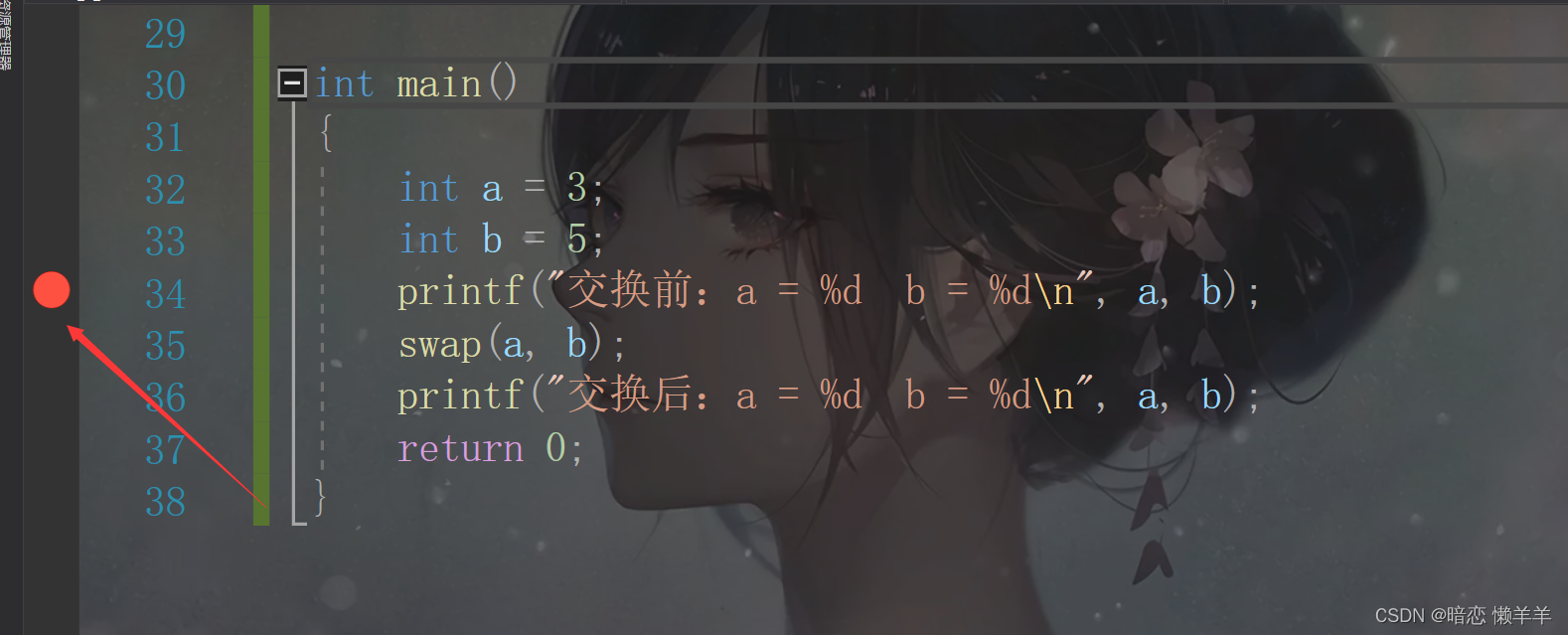
这就是F9打的断点,我们分析程序是在swap函数出问题的,所以F9直接跳过没问题的.然后F5到当前断点来!

此时问题在函数里面,我们介绍过。F11是逐语句执行,我们可以用它进入函数内部,看看!

注意此时监视x = 3, y = 5, a = 3, b = 5, 我们待会观察a,b,x,y的变化情况!

这是调试结束的结果,此时x = 5, y = 3确实交换了,但a = 3, b = 5好像一点也没变!我们结束打印的是a 和 b:
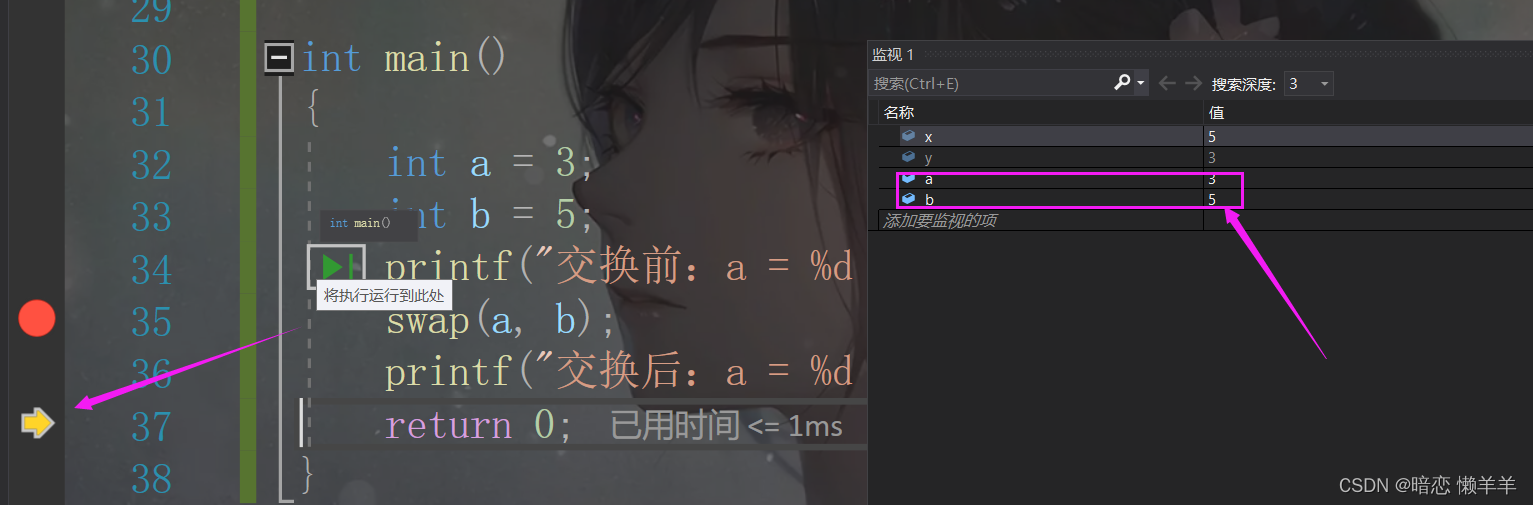
结果还是a = 3, b = 5;所以没有交换成功!这里小编也就不废话了,这里改变了形参形参是实参的一份拷贝,两者的空间不同,改变形参实参不受影响!我们前面已经不止一遍的介绍过这东西了,这里就不在唠叨了!
b、查看程序的内存信息
int main()
{
int a = 0x11223344;
return 0;
}这段代码的内存布局以及a的值在内存中是如何存的?我们一起来look一look:
还是先调试起来!!! 点调试--->窗口--->内存-->4个窗口随便一个!
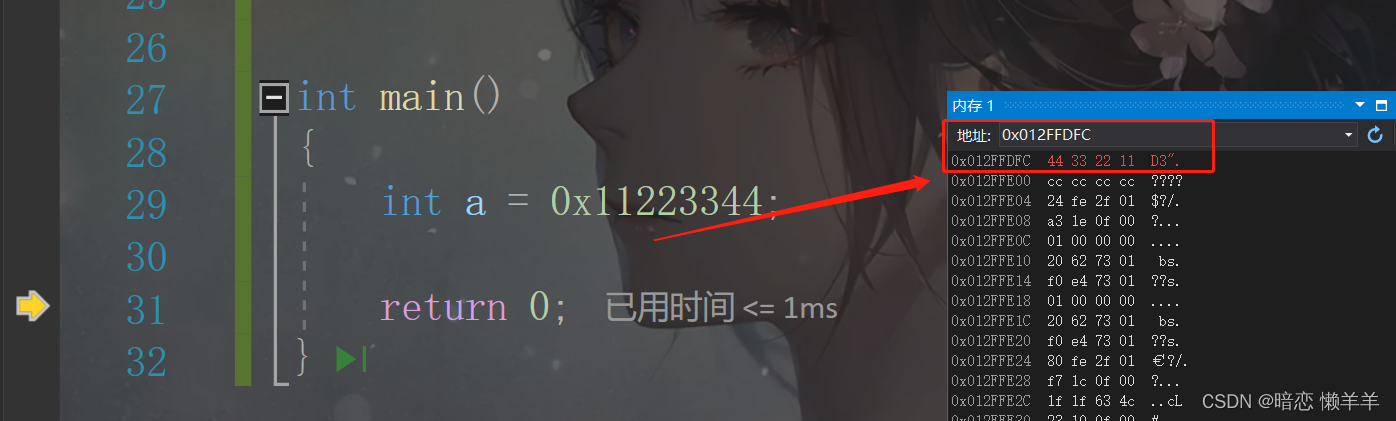
这里输入&a就可以看到,a的内存布局以及a中的值在内存中的存储形式,我们前面介绍过倒着存是因为对当前平台是小端存储模式!
c、查看程序的调用堆栈
我们就用下面这个简单的代码演示一下:
void test2()
{
printf("hahaha\n");
}
void test1()
{
test2();
}
int main()
{
test1();
return 0;
}这个代码就是打印一个haha,但它是如何调用的?我们就可以来看看调用堆栈!
先调试起来!!!再点击调试-->窗口-->调用堆栈

一开始还没有调用test1只有main函数的栈帧!
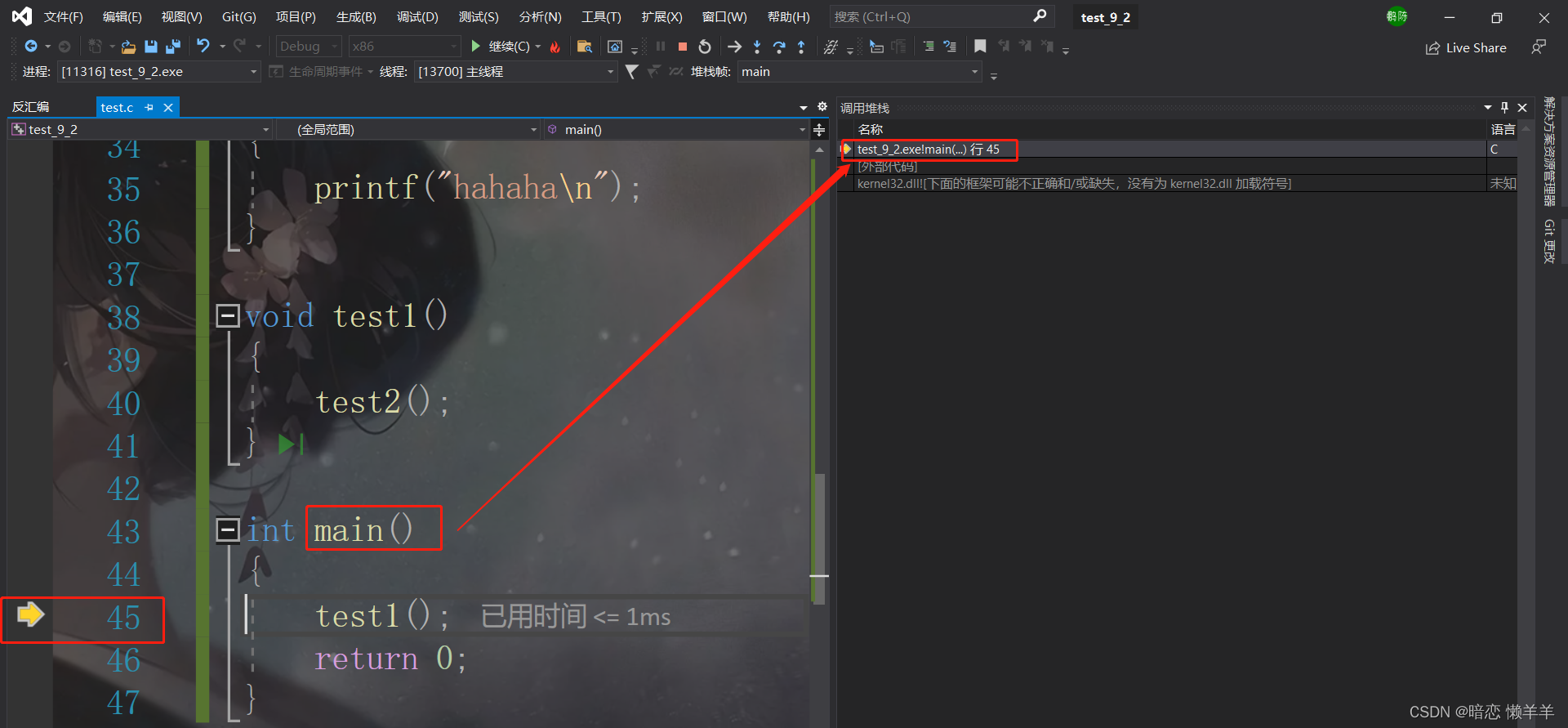
F11调用test1在main函数的上面开辟了test1的栈帧:
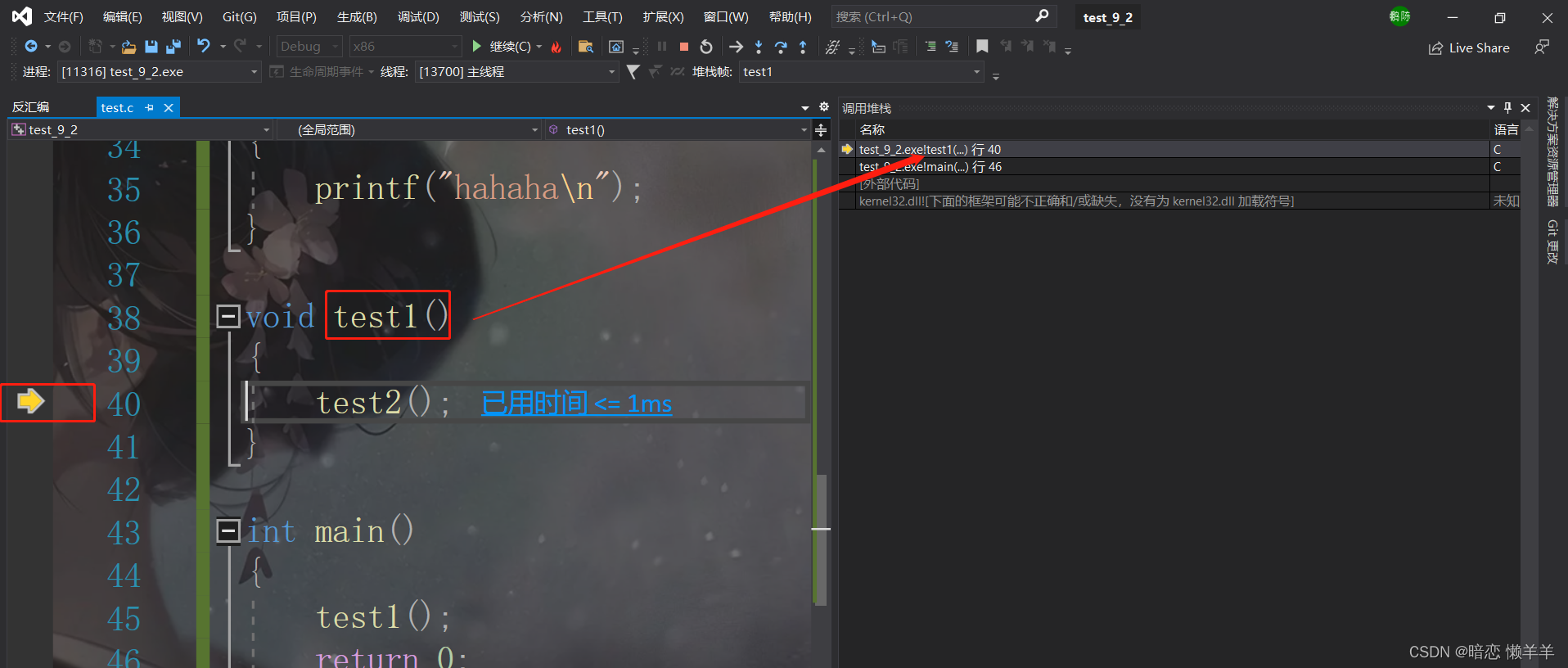
在调用test2就有在test1上面创建了test2的函数栈帧:
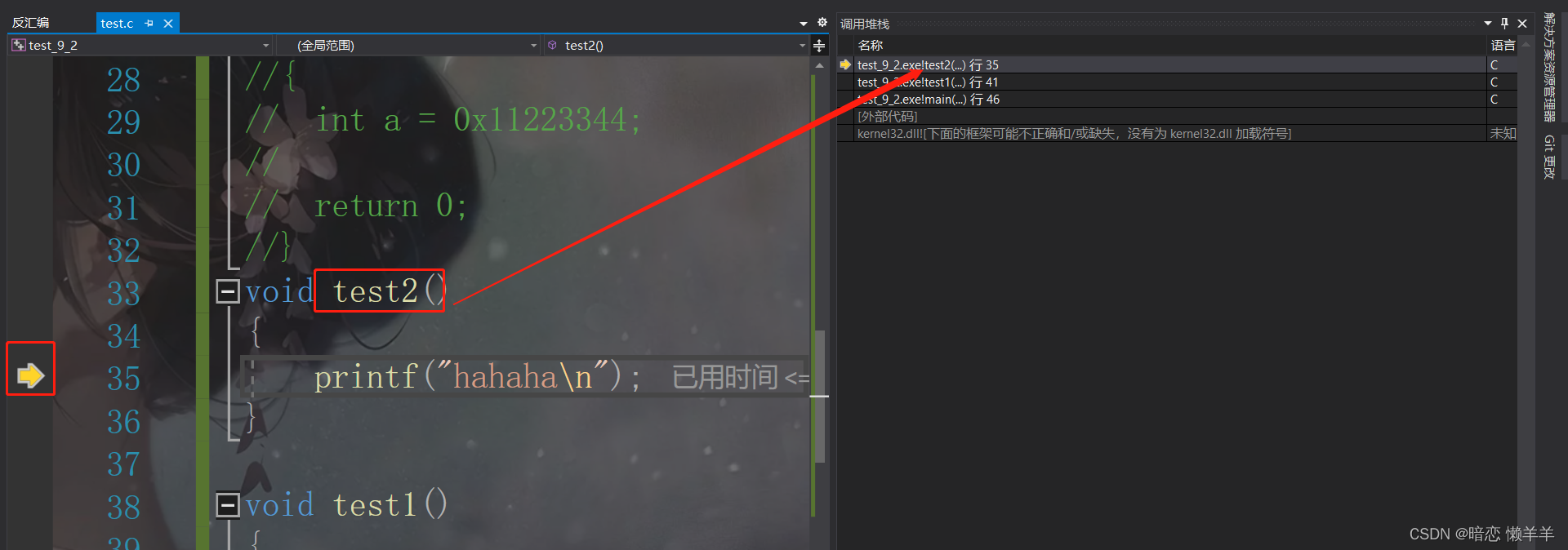
然后接下来打印完haha后就会把test2的函数栈帧销毁,我们在函数栈帧的那一期介绍过,在调用一个函数的时候会把当前语句的下一条语句提前存起来,等栈帧销毁的时候就直接执行下一条语句了!所以test2带哦万就销毁了,只剩test1和main函数的栈帧了!

然后会最后main函数的栈帧也会销毁!!!这里我又想起来了我在介绍函数栈帧的时候说过main函数是被其他函数调用的,但那时候操作不当在调用堆栈那里没有找到!今天小编找到了!
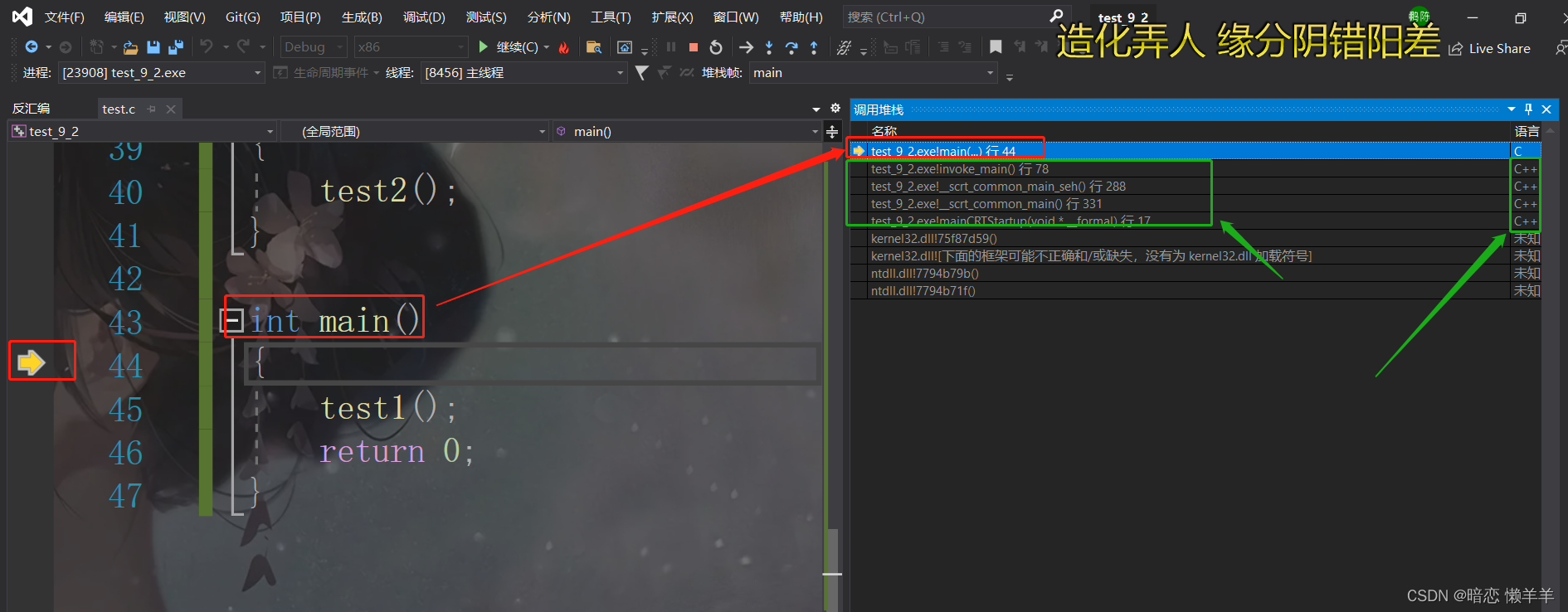
在VS上调用main函数的函数是用C++写的!当然这个具体实现得看编译器,各个编译器可能不一样!
d、查看程序的汇编信息
先调试起来!!!再点击调试-->窗口-->反汇编

int maxNum(int x, int y)
{
return x > y ? x : y;
}
int main()
{
int a = 3;
int b = 5;
int ret = maxNum(a, b);
printf("max = %d", ret);
return 0;
}
红色的框是在建立函数栈帧!这个我们函数栈帧介绍过!下面蓝色的框是在创建变量!

这就是调用函数的指令!
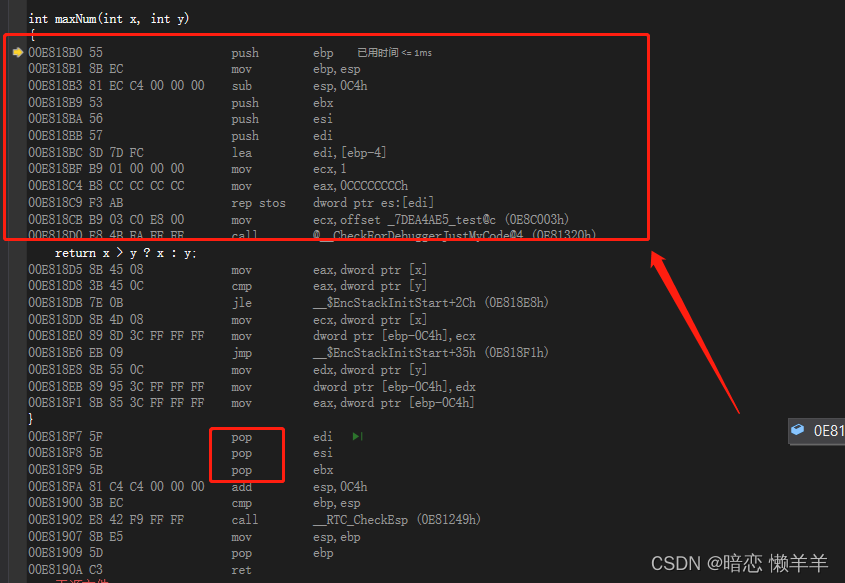
这个就是maxNum的函数栈帧!!!!的创建以及销毁的反汇编!
e、查看寄存器信息
这个可能很多刚刚入门的或者还没入门的小伙伴都不知道!
寄存器(register)是cpu周围的暂时放数据的地方,由于在cpu周围所以访问速度很快但空间不大!而且在寄存器上创建的变量是没有地址的!!!!
OK,我们来段代码看看:
int main()
{
int a = 3;
register int b = 5;
return 0;
}b就是一个寄存器的变量!他是没有地址的!我们先对a取地址:
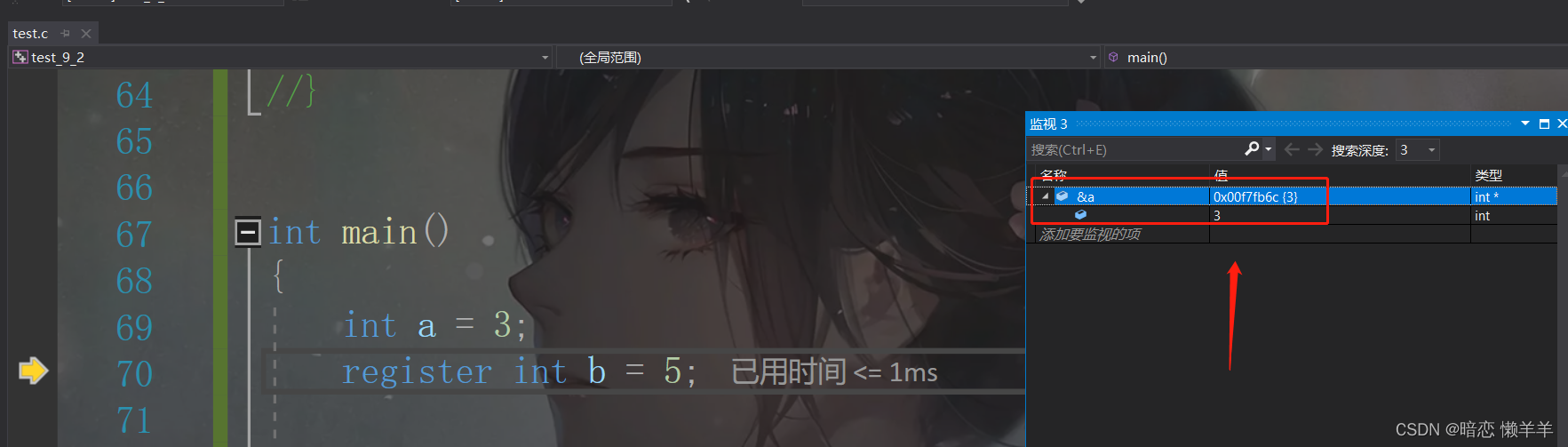
在对b 取地址:
在cpu周围不需要开辟内存直接可以使用!!!
五、一些调试实例
(一)、代码实现:1! + 2! + ...+n!
int main()
{
int sum = 0;
int ret = 1;
int n = 0;
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d", sum);
return 0;
}这段代码我们其实一开始就介绍了,它的错误原因在于:每一次没有对ret初始化为1,导致后面的ret把前面的结果叠加的乘了上去!!!我们上面也调试了,这里就不在调试了!正确代码如下:
int main()
{
int sum = 0;
int ret = 1;
int n = 0;
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
ret = 1;
for (int j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d", sum);
return 0;
}(二)、下列程序打印机次haha?
int main()
{
int i = 0;
int arr[10] = { 0 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("haha\n");
}
return 0;
}如果你以前没有见过这道题或了解过地层相关的知识的话,这道题你可能100%会回答错!你可能只会说这道题的问题不就是越界嘛!打印13个haha然后报错!但事实真的是这样吗?我们看结果: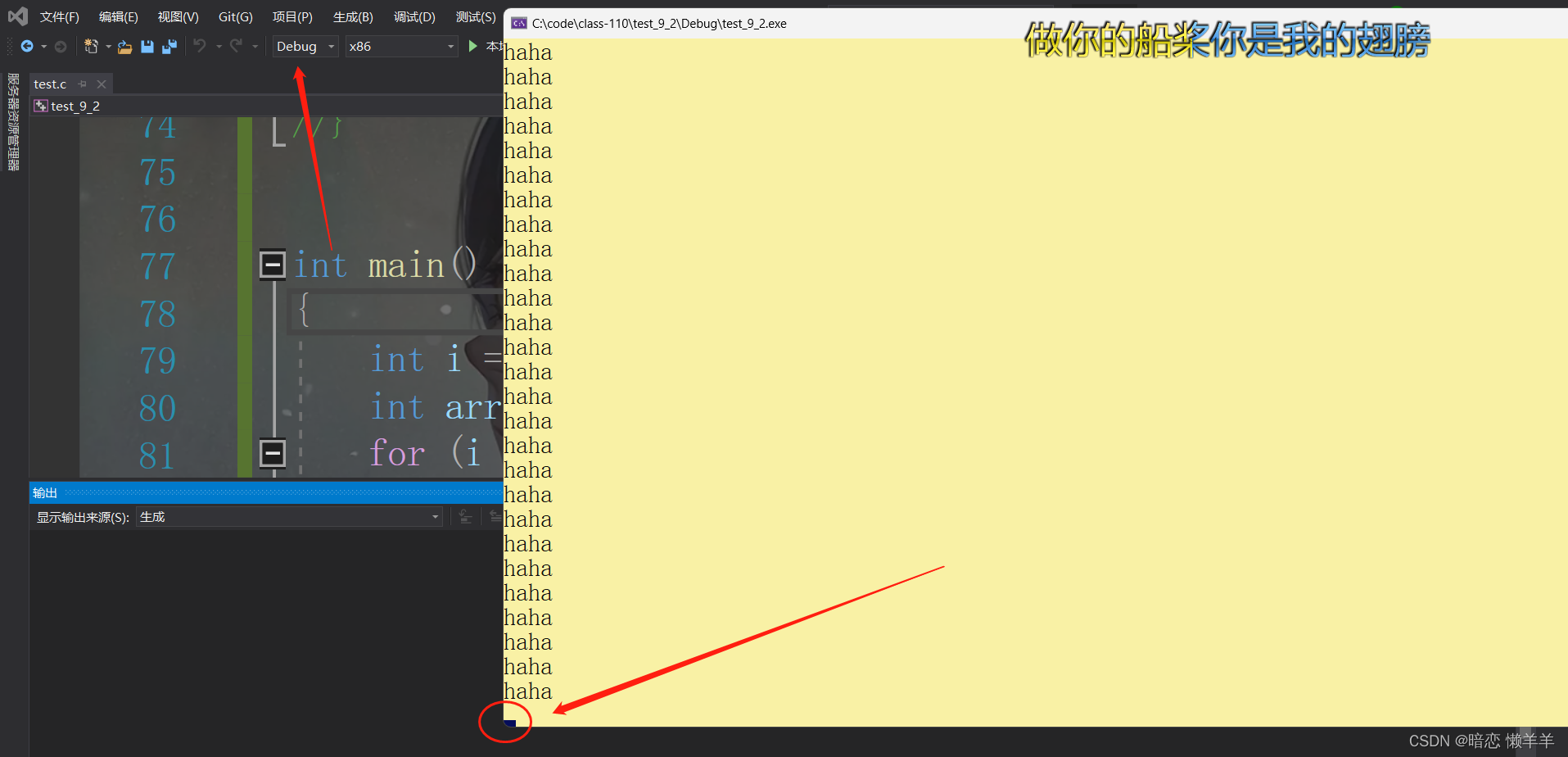
死循环了!!!问什么呢?我们先来找原因,其实如果之前看过函数栈帧的那一期的伙伴应该会反映过来,在VS上,创建的变量一个里一个差两行0hcccccccccc:
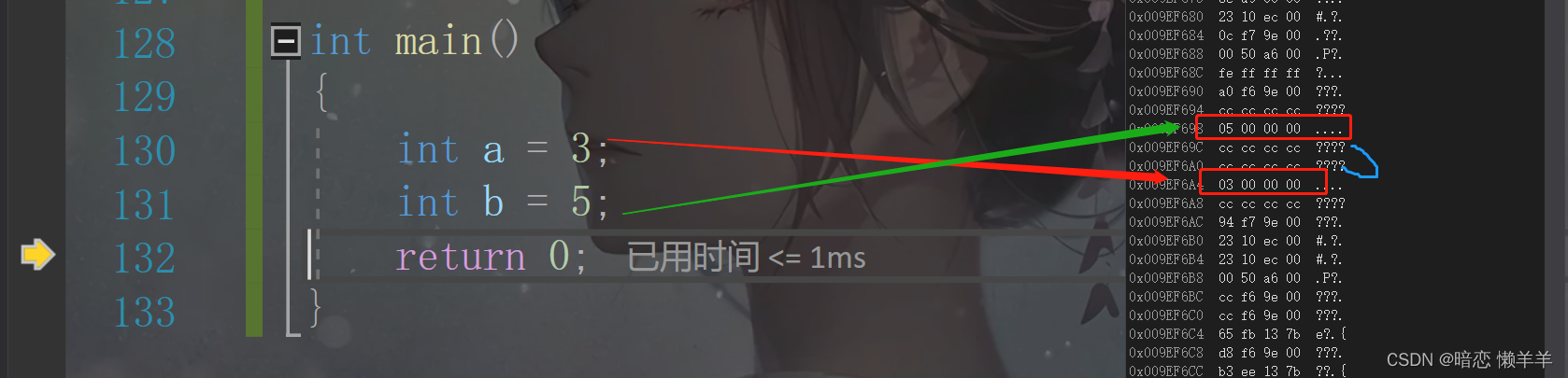
这里我们就不在用这种方式往下解释了,我们用调试:

果然他也是差了两行的ccccccccc,我们知道栈的使用规则是:先试用高地址,在使用低地址!而,数组的下标访问是先用低地址,后用高地址!
所以数组访问的地址路线如下:
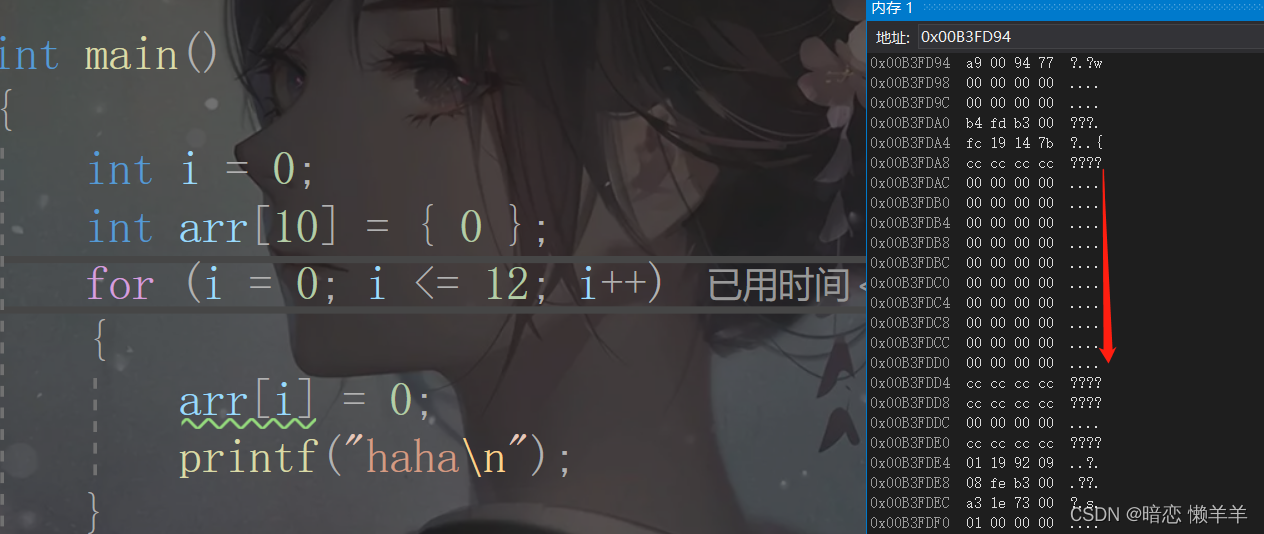
会不会是在越界的时候把i改了呢?我们来监视看看:
刚刚创建好变量和数组:

i==9是,马上要越界了:

i == 12:
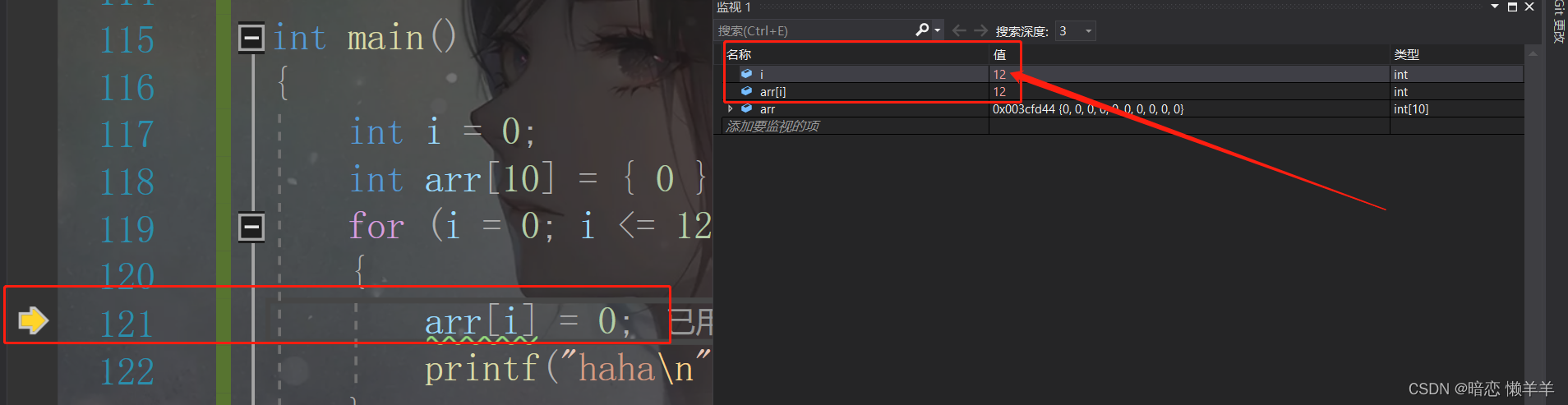

在i == 12,将arr[12] = 0;执行完后i也变成了0,我们猜想会不是越界的时候到i=12时将i的值改为了0?换句话说i的地址和arr[12]是一样的,他们是一块空间?我们此时只需要看看他两的地址即可:

果然一模一样!!!!我们上面的分析是正确的!!我在画个图来解释一下上面:
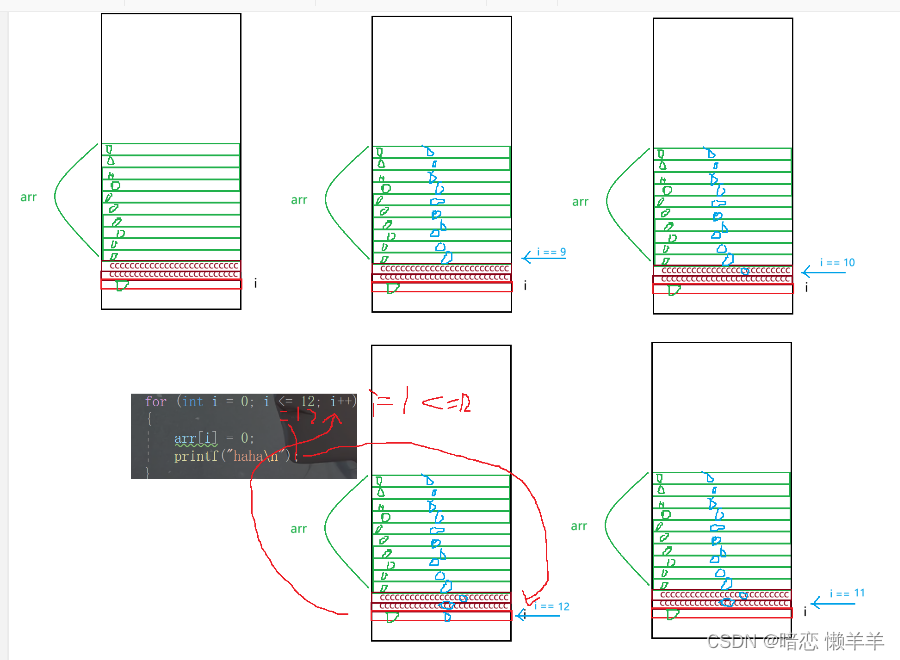
那找到了问题,确定了原因,就得解决问题:
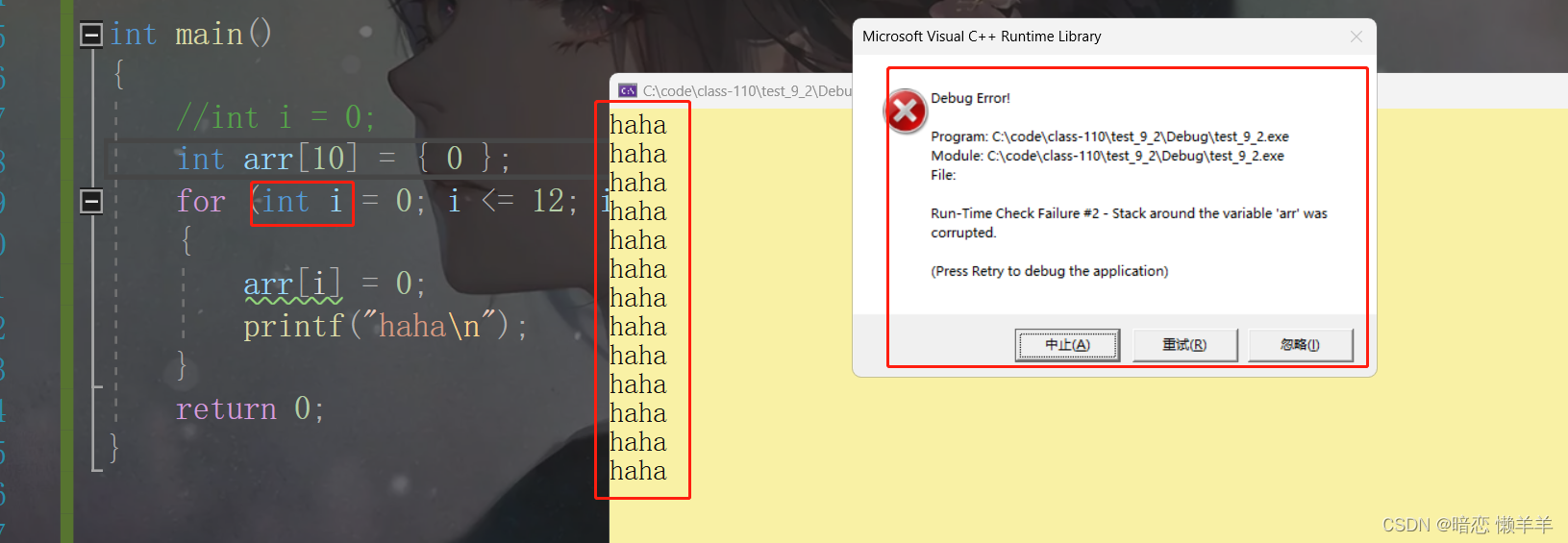
int main()
{
int arr[10] = { 0 };
for (int i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("haha\n");
}
return 0;
}这样写的话他i的创建在i的后面,前面的那块空间一单越界就会报错!
当然这种代码在实践中肯定是一般碰不到的!这个栗子仅仅是说明遇到问题了如何去解决!!!虽然在实践中遇不到但不一定在笔试面试中碰不到:这道题曾经就是一家叫Nice公司的笔试题:

这道提不就和刚刚这道题一样吗?只是换了数字而已!思路、问题、解决方法都是一样的!!!!
六、如何写出“好”代码?
6.1什么是好代码?
我们经常听说好代码,什么是好代码呢?我们认为具备以下特征的代码就是好代码!
1、能正常运行
2、Bug很少
3、效率高
4、可维护性高
5、注释清晰
6、可读性高
7、文档齐全
假设说你写了个代码,运行不了,或者即使运行起来了也全是Bug,你写的代码只有你自己你看的懂,不加注释。你可能说只有自己看得懂那不就公司裁不了我了吗?这样想就太天真了!当代码有几十万行时出了问题,你自己都控制不了的时候,,,你细品~。所以我们平时写代码要注重可读性以及注释!!!
6.2如何写出好代码?
这是一些写好代码的几个tips:
1、使用assert
2、使用const
3、编码风格规范
4、添加注释
这里提到了assert和const,我们以前经常用但没有介绍过这两个!下面我就先来介绍一下:
assert介绍
assert 中文意思就是断言的意思。顾名思义就是判断!他是一个宏!使用时要包含相应的头文件:#include <assert.h>

这是官网对他的介绍,人家明确说了这是一个宏!!!长得像函数的宏!作用是断言!如果它的判断的那个表达式判断失败就会调用:abort这个函数!并终止程序!这个宏所显示的消息与具体的实现库有关,一个编译器和一个编译器不一样!但他至少显示:断言失败的源文件名和对应的行数!如果你包含了头文件还是不能用就得添加上面我画出来的#definede 那个了!加上就OK了!!
这里还提到了一个函数:abort:

这个函数的作用是终止当前进程,进程是网络那部分的东西,这里就不多介绍了!这里就理解为终止当前程序(异常终止)!调用这个函数时这个函数会捕捉去一个信号,如果没有捕捉到,就会导致程序终止,并向平台返回一个错误码!程序被终止是不会破坏任何对象!!
OK!我们来写个代码用一下:
typedef struct Stu
{
char name[20];
int age;
}S;
void print(S* ps)
{
assert(ps);
printf("%d", ps->age);
}
void Modif(S* ps, int age)
{
assert(ps);
ps->age = age;
}
int main()
{
S s = { "张三",20 };
Modif(&s, 19);
print(&s);
return 0;
}这就是assert的作用, 当然你可以按自己的需要判断值是否符合预期~!
const介绍
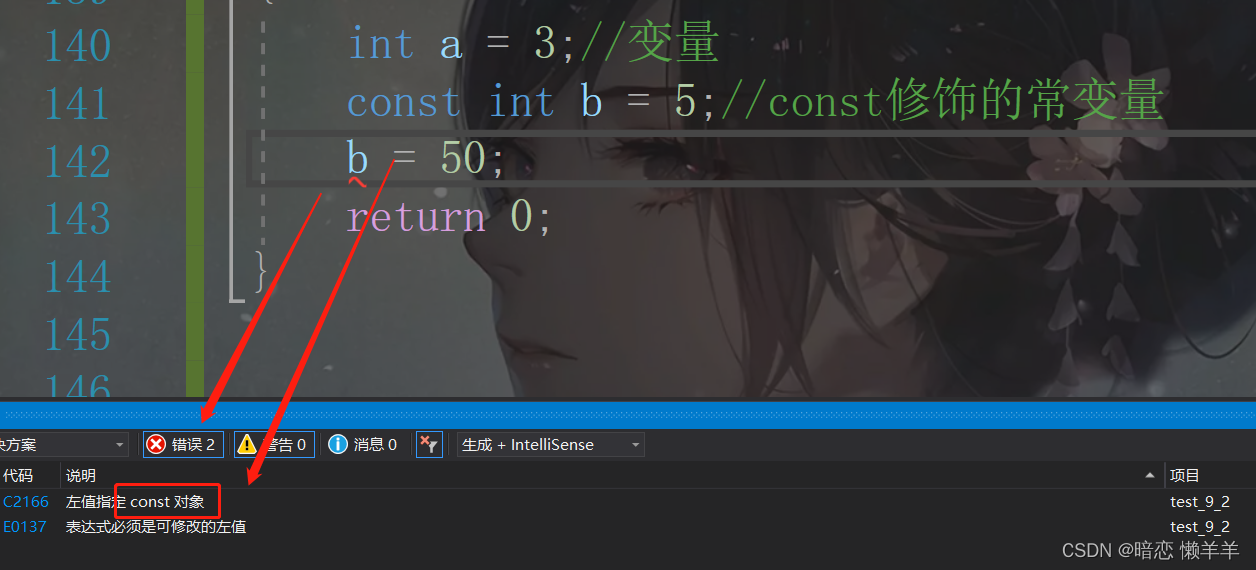
const这是一个关键字,我们前面开始介绍常量和变量的时候说过,被const 修饰的变量是常变量!具有常量属性但本质是个变量(只不过这个变量被初始化以后就不能在被修改了)!例如:
#define M 10//#define定义的常量
int main()
{
int a = 3;//变量
const int b = 5;//const修饰的常变量
return 0;
}因为b是被const修饰具有常量属性不能被改,所以这里对他的值进行修改就会报错:
而且也不可以用它来定义数组!我们知道定义数组时[ ]里面的是一个常量(变长数组除外),变量就不行,b是常变量所以他也不行!!!

当然我们今天不是为了回忆以前学的,而是在此基础上再进行拔高一层!比如const修饰指针的问题!先看如下代码:
void test1()
{
int m = 3;
int n = 5;
int* p = &n;
*p = 20;
p = &m;
}
void test2()
{
int m = 3;
int n = 5;
const int* p = &n;
*p = 20;
p = &m;
}
void test3()
{
int m = 3;
int n = 5;
int* const p = &n;
*p = 20;
p = &m;
}
void test4()
{
int m = 3;
int n = 5;
const int* const p = &n;
*p = 20;
p = &m;
}
int main()
{
test1();
test2();
test3();
test4();
return 0;
}上面的4个代码分是对指针p的 * 两边都不用const修饰,在*左边修饰右边不修饰,右边修饰左边不修饰,以及两边都修饰!具体会出什么结果过呢?我们一个一个看一看!
test1两边都不修饰:
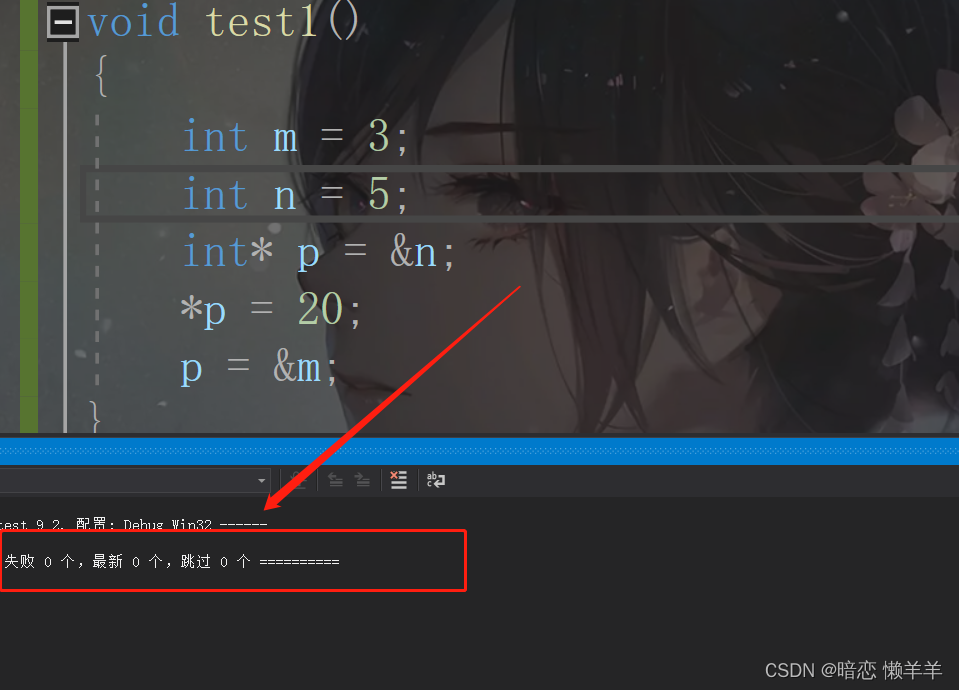
考虑此时的 m 和 n值是多少?

这个不怎么难一看就知道但我想说的是!这里有一行很不起眼的代码你可能没有注意到!就是倒数第二行!p = &m;你可能会说这不就是一行很简单的赋值吗?这有啥可介绍的!你这么想就可使有点外行了!这可是指针啊!!!有了指针可以直接修改的!!!例如:
void test1()
{
int m = 3;
int n = 5;
int* p = &n;
*p = 20;
p = &m;
printf("m = %d n = %d\n", m, n);
*p = 200;
printf("m = %d n = %d\n", m, n);
}看结果:

这里你还觉得他仅仅赋值那么简单吗?是不是感觉他很不安全呀!的确指针使用不当很危险!所以在使用指针前对他进行检查以及作相应的修饰限制,例如const,下面就来看看被const此时的各种情况吧!
const在*左边:
void test2()
{
int m = 3;
int n = 5;
const int* p = &n;
*p = 20;
p = &m;
}这个就是const修饰*左边的例子!如果被const修饰了左边,会和不修饰有什么区别呢?我们想爱你编译看看!
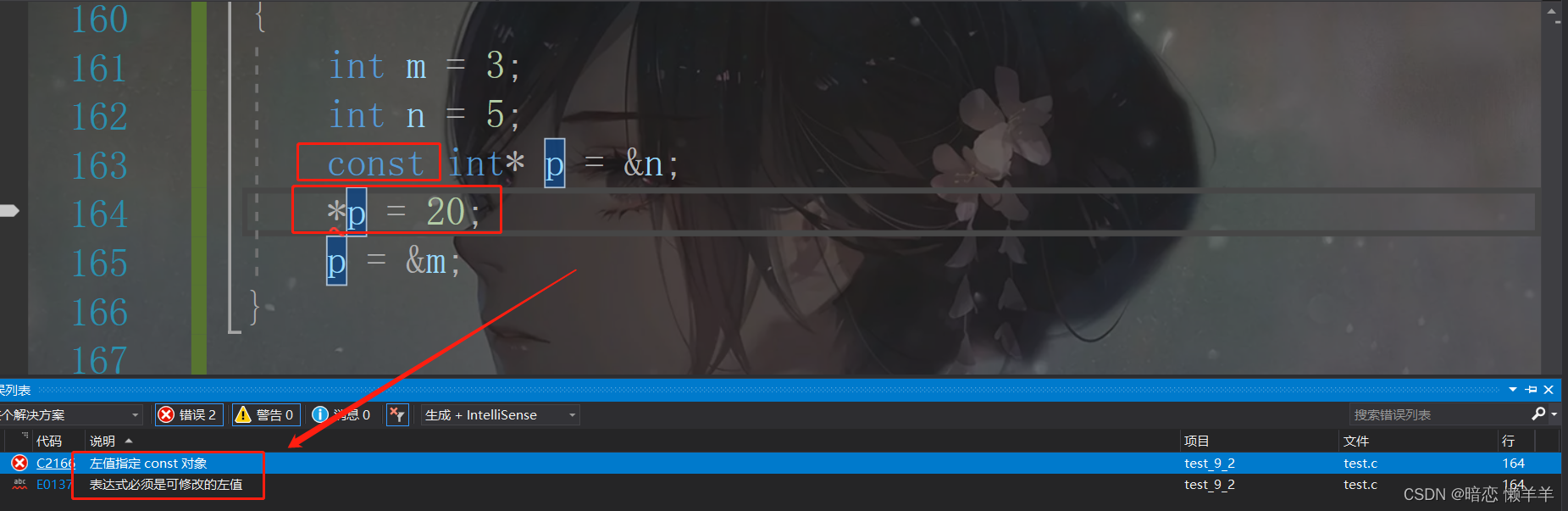
这貌似和const修饰一般的变量一样!不能被修改,这个在左边好像不能修改p指向那块空间的值!那我们猜测:如果在右边是不是不能改变p的值呢?我们来看看:
void test3()
{
int m = 3;
int n = 5;
int* const p = &n;
*p = 20;
p = &m;
}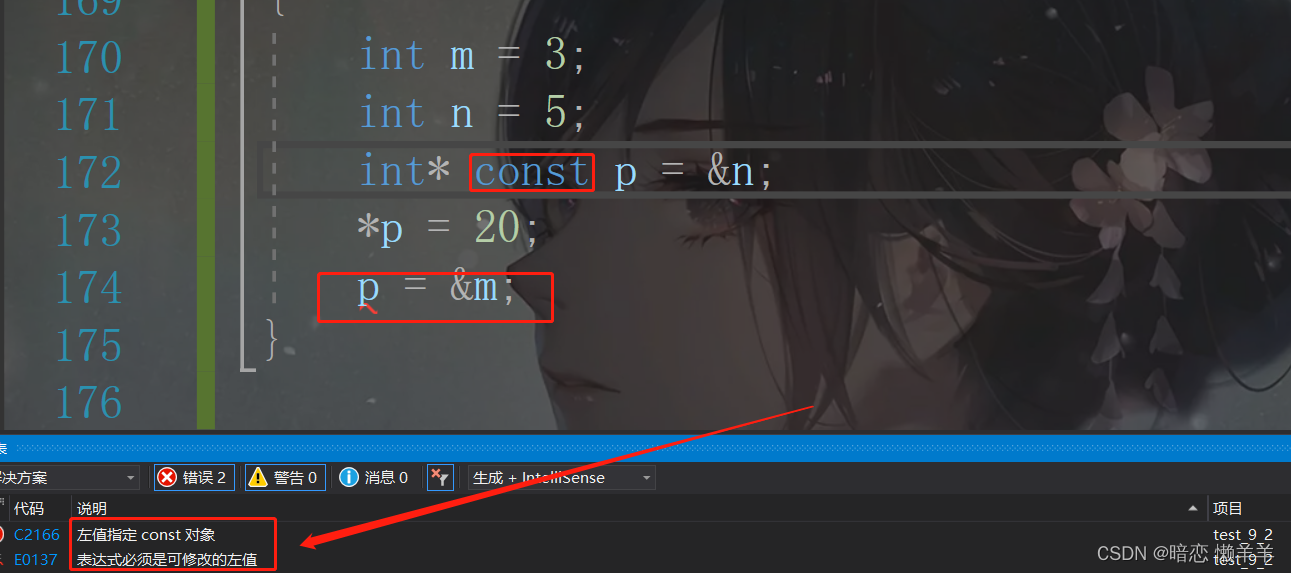
还真和我们猜的一样!再回到上面的栗子test2:
void test2()
{
int m = 3;
int n = 5;
const int* p = &n;
//*p = 20;
p = &m;
p = NULL;
}既然不让修改p指向的值的话,那我改变p的值,的确可以!

和这个类比一下,在右边我不能改 p的值,那我可以改p指向的那块空间的值吧!验证一下:

果然!那我们可以再猜测一下是不是在两边修饰就是既不能修改p的值也不能修改p只向空间的值呢?试一试:

果然!这样好像更安全了~的确是!我们现在就可以进行总结一下!
const 两边都不修饰
很不安全!!!只要拿到指针既可以修改指针也可以修改指针指向的空间的值!
const 修饰*左边
不能对指针指向的那块空间的值进行修改!但可以对指针的修改!
const 修饰*右边
不能修改指针的值,但可以修改指针指向空间的值!
const 修饰两边
既不能修改指针的值,也不能修改指针指向空间的值!
OK,这三种修饰看具体情况使用!!!!!我们刚刚上面的aeesrt的那个代码是不是可以再来用优化一下呢?
typedef struct Stu
{
char name[20];
int age;
}S;
void print(const S* const ps)
{
assert(ps);
printf("%d", ps->age);
}
void Modif(S* const ps, int age)
{
assert(ps);
assert(age);
ps->age = age;
}
int main()
{
S s = { "张三",20 };
Modif(&s, 19);
print(&s);
return 0;
}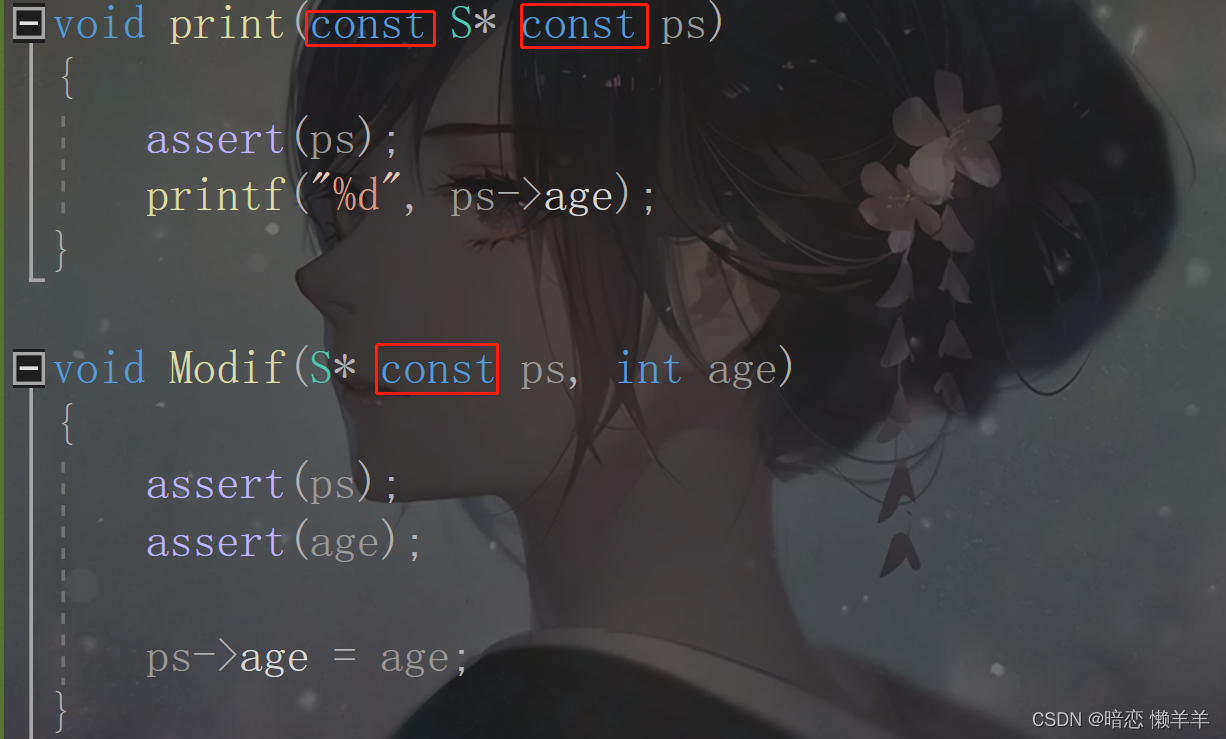
print函数只是打印信息不需要改变ps的值以及ps指向空间的值!下面的修改函数是需要修改ps指向空间的值但不需要改变自身的值~,加上assert和const的代码是不是更加健壮了!以后能用就多用!!!另外多加注释!!!OK,下面我们就来完整的写一个好代码!模拟实现strcpy!这个函数不必多介绍了吧,我们已经前面模拟实现了两遍了!它的作用就是拷贝字符串!~函数原型如下:

两个参数,destination是目的地也即是要拷贝到的空间!另一个是,cosnt修饰的source是源头,也就是要拷贝的数据!因为他只要求拷贝不让修改,所以const修饰左边!我们下面来实现一个:
char* MyStrcpy(char* dest, const char* src)
{
//检查空指针
assert(dest);
assert(src);
//拷贝
char* ret = dest;
while (*dest++ = *src++)
;
return ret;
}
int main()
{
char dest[20] = { 0 };
char* src = "hello world!";
strcpy(dest, src);//库函数
printf("%s\n", dest);
printf("-----------------------\n");
MyStrcpy(dest, src);//自己函数
printf("%s\n", dest);
return 0;
}看结果:
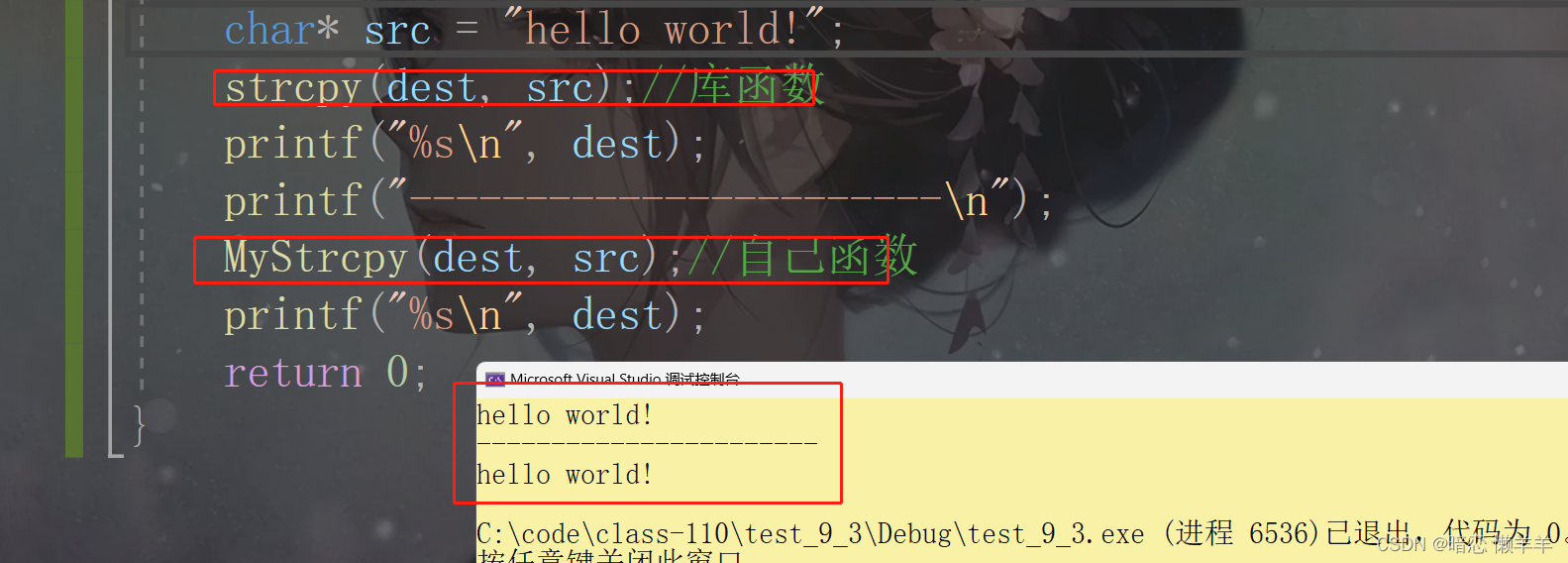
OK!模拟完成!
七、常见错误解析
7.1编译型错误
一般可以直接看到错误信息,凭借经验就可以解决!一半多为语法错误~
例如:
int main()
{
int a = 3
return 0;
}这里是少个封号,导致语法错误!看编译错误信息:
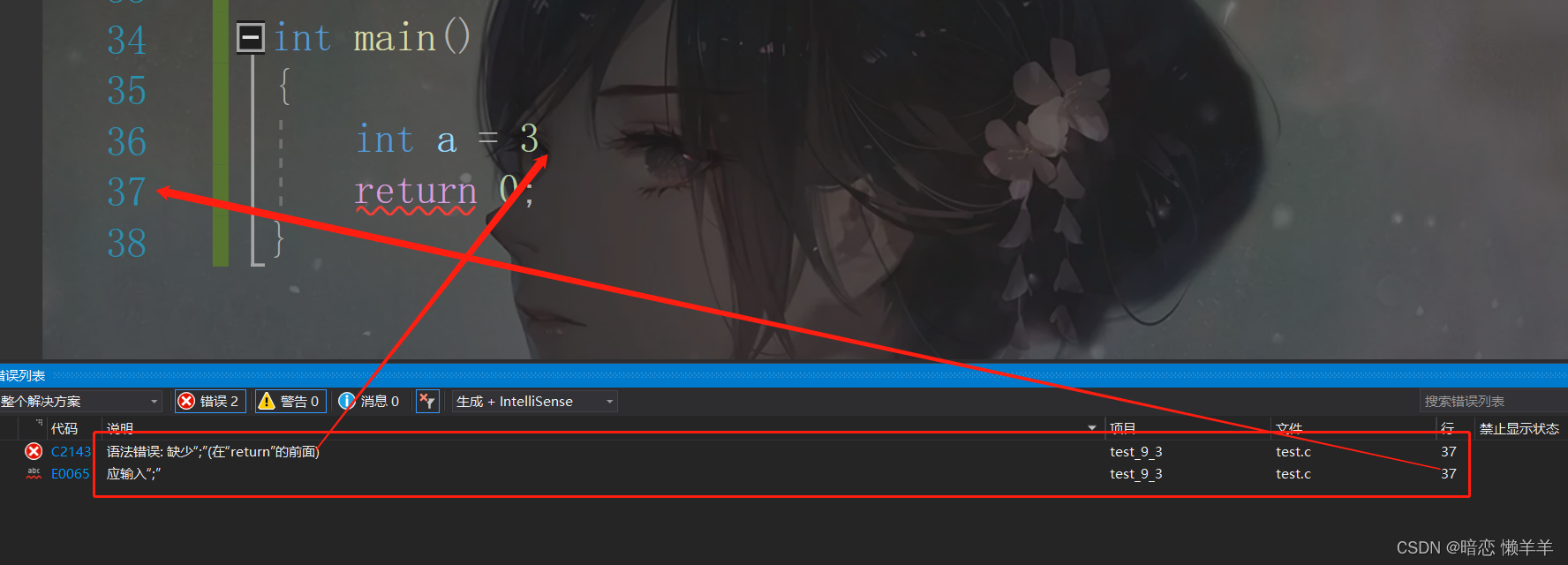
这种问题一般会很简单,看看错误信息就可以解决!
7.2链接型错误
这种错误一般是由标识符错误火不存在导致的!看错误信息也很容易解决!
int Add(int a, int b)
{
return a + b;
}
int main()
{
int a = 3;
int b = 5;
int ret = add(a, b);
printf("%d", ret);
return 0;
}这里add和Add不是一个东西就会表连接时错误!
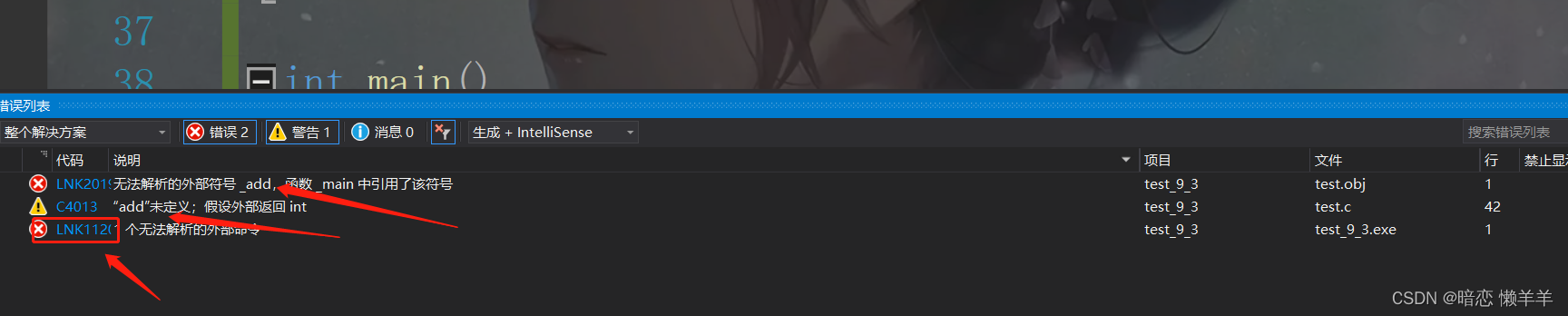
这种找到改回来就好了!
7.3运行时错误
这是最麻烦的一种,语法没有问题可是结果就是不符合预期,得一步一步调试~
调试也是程序员的内功,非一日之功!~得多练习~,!
OK,好兄弟本期分享就到这里,我们下期再见~!