前言
我们前面几期介绍了线性和非线性的基本数据结构。例如顺序表、链表、栈和队列、二叉树等~!本期和接下来的几期我们来详解介绍各个排序的概念、实现以及性能分析!
本期内容
排序的概念以及其运用
常见的排序算法
直接插入排序
希尔排序
一、排序的概念及其运用
排序的概念
排序:按照一定的规则,把一组元素序列以递增或递减排列起来的操作!
稳定性:假设在待排序的一组序列中有多个相同的元素,若经过排序,这些元素的相对位置(相对次序)是不变的,则称为这种排序是稳定的。否则就是不稳定的!
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时在内存中,根据排序的过程要求不能在内存和外存之间移动数据的排序!
关于哪些是内部排序、哪些是外部排序后面性能分析会在介绍!
排序的运用
排序在日常生活中是极其常见的:例如你每天看的京东、淘宝、拼夕夕等购物平台上的综合、销量、好评、价格、等一系列都是对商品的排序!
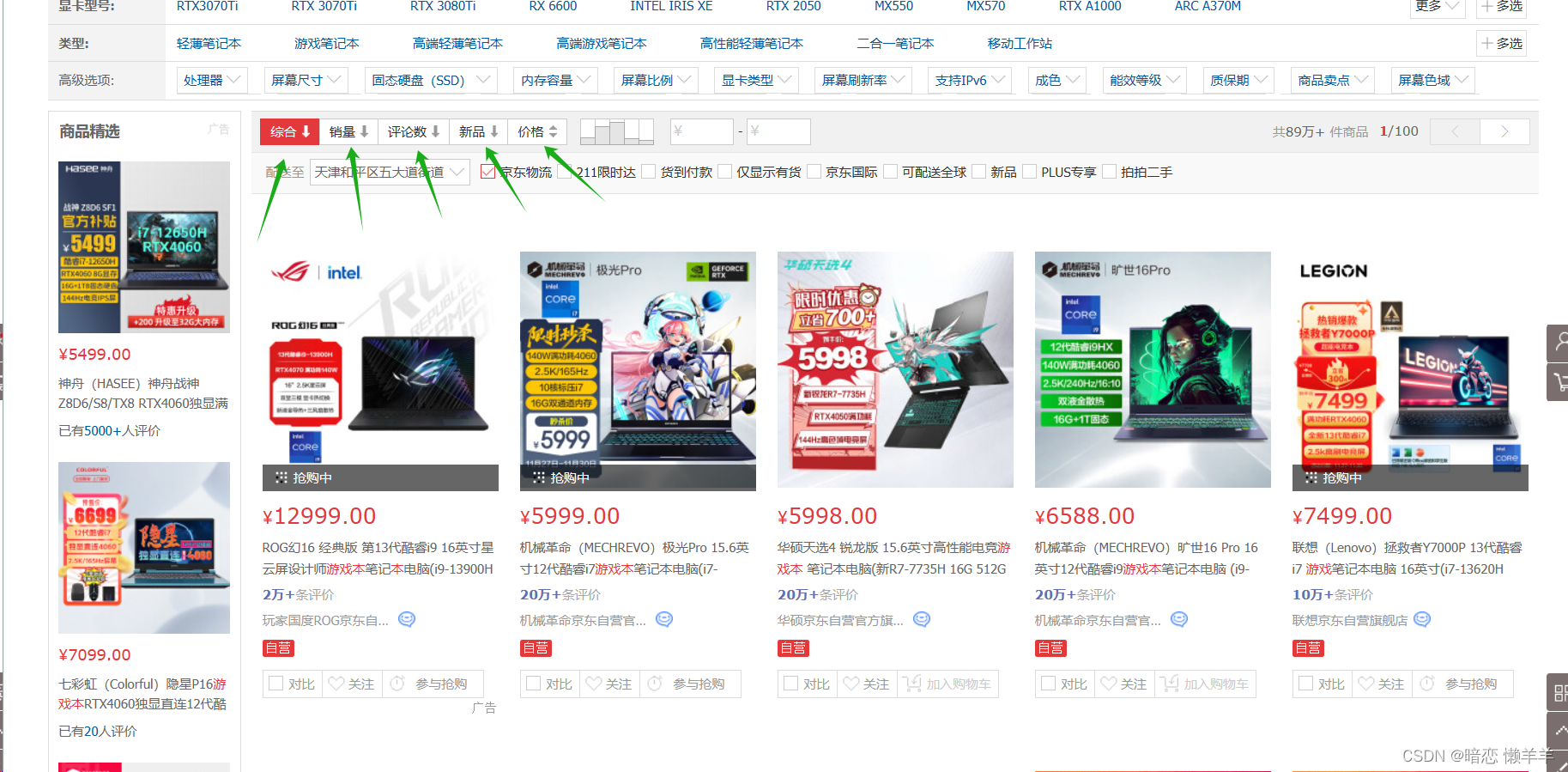
还有高校排名:
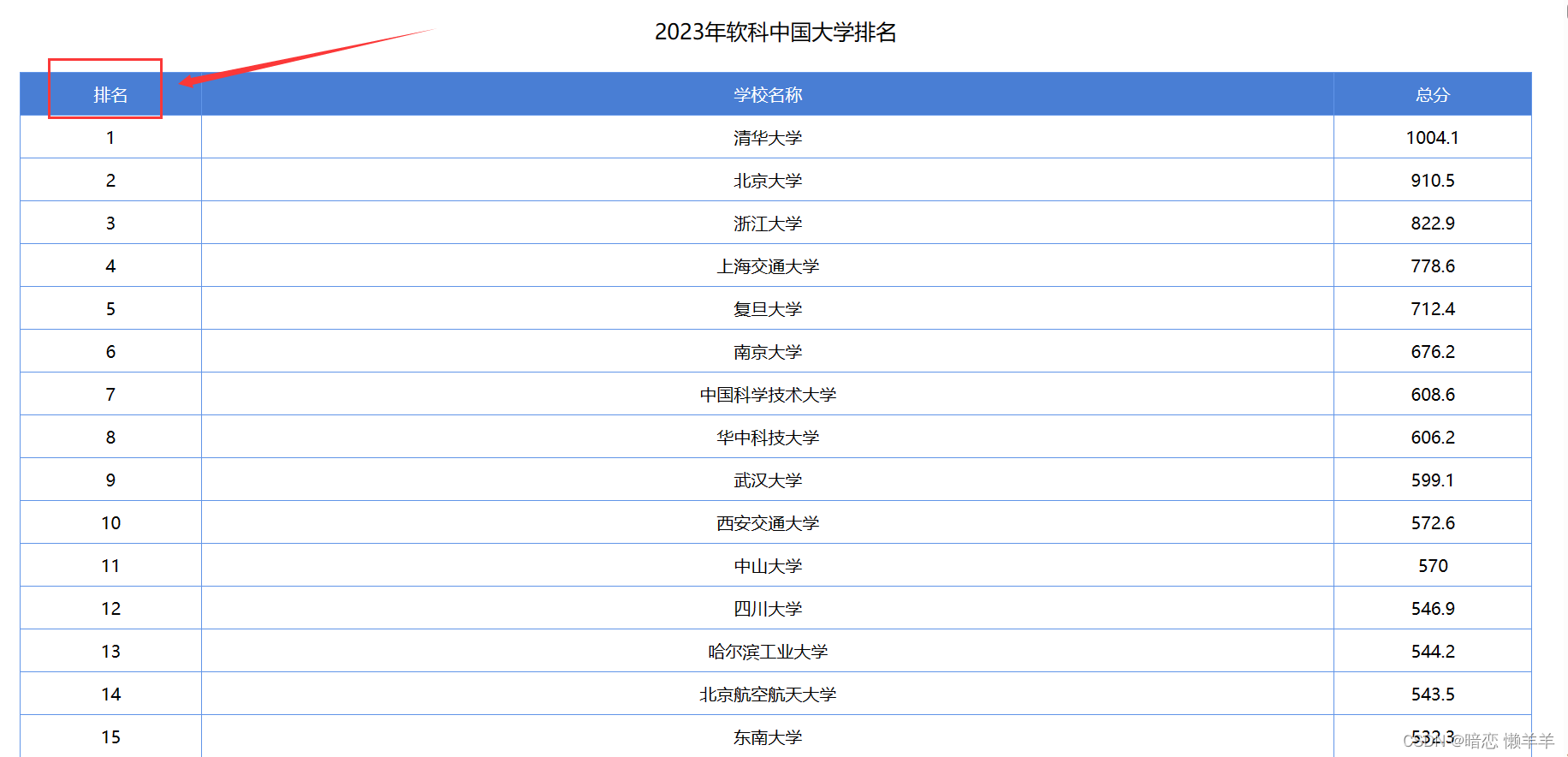
还有大家考试的时候的排名,这些都是排序~!排序在生活只能是很常见的!!!
常见的排序算法

二、直接插入排序及其实现
插入排序的基本思想
把待排序的元素序列按照其大小逐个插入到已经排序好的有序序列中,直到所有待排序的元素插入完为止, 而此时得到的新的序列就是有序的序列!
这就和我们小时候玩扑克牌摸牌整理的一样,一次与前面的排比较找到合适的位置插入!
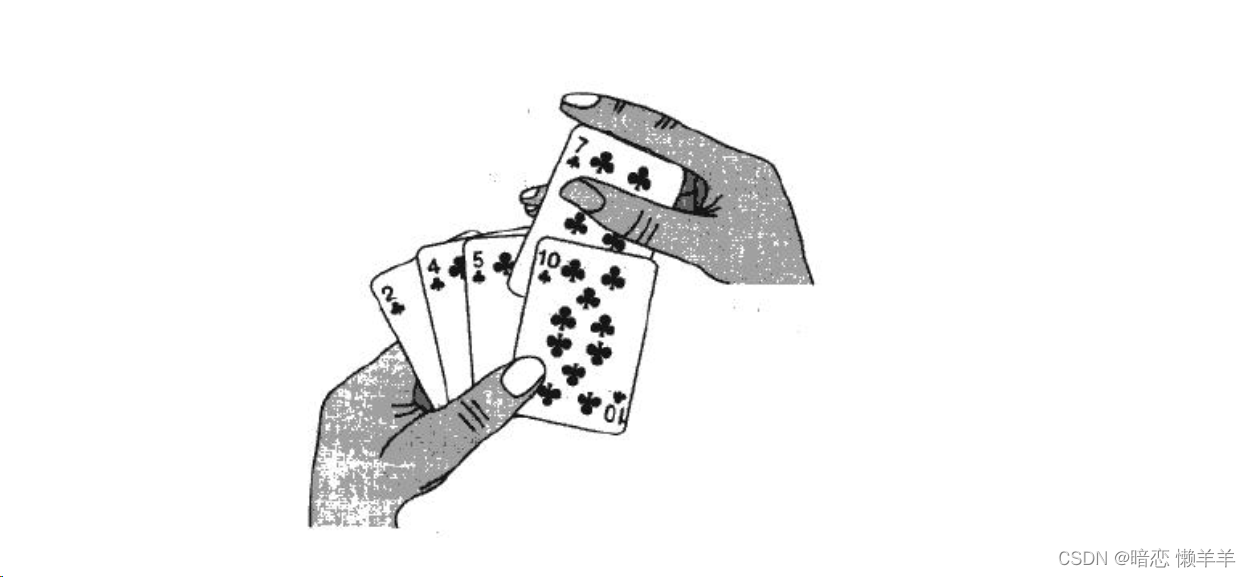
直接插入排序
当第i个元素插入时(i >= 1),前面的序列已经是有序的, 此时只需要用array[i]的元素与前面的所有元素逐一比较,前面的元素比当前的大则前面的元素插入到当前位置(升序),否则当前元素插入到前面元素的后面!
我们根据上述思路先来写单趟,再来改造整体
int end = 0;//一开始end置0位置
int tmp = a[end + 1];//tmp是end 的下一个位置的元素
while (end >= 0)
{
if (a[end] > tmp)//前面元素比当前的元素大
{
a[end + 1] = a[end];//前面元素的插入到前面元素的后一个位置
}
else//前面元素不比当前的元素大
{
a[end + 1] = tmp;//当前元素插入到前面元素的下一个位置
break;//记得结束否则会又把排好的区间搞乱
}
--end;
}
if (end < 0)//所有的都比tmp大,此时end一直减会减到-1
{
a[0] = tmp;//此时把tmp(end的下一个位置的元素)插入到0下标位置
}整体:
其实单趟写出来,改造整体就会很容易,我们在外面在套一层循环即可!让end从i 开始,每个元素与前面的逐一比较走单趟,直至最后有序!
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;//一开始end置0位置
int tmp = a[end + 1];//tmp是end 的下一个位置的元素
while (end >= 0)
{
if (a[end] > tmp)//前面元素比当前的元素大
{
a[end + 1] = a[end];//前面元素的插入到前面元素的后一个位置
}
else//前面元素不比当前的元素大
{
a[end + 1] = tmp;//当前元素插入到前面元素的下一个位置
break;//记得结束否则会又把排好的区间搞乱
}
--end;
}
if (end < 0)//所有的都比tmp大,此时end一直减会减到-1
{
a[0] = tmp;//此时把tmp(end的下一个位置的元素)插入到0下标位置
}
}
}但要注意的是:外面的for循环的判断条件,i < n - 1, 也就是说i最多走到n - 2的位置即倒数第二个元素!原因是:tmp才是每次要插入的元素,而tmp = a[end +1]是end(i)的下一个位置,如果让i 到最后一个元素的位置即n-1处,那tmp = a[end+1]就会越界!!!所以i 只能到倒数第二个元素的位置!
OK, 直接插入写完了,测试一下:
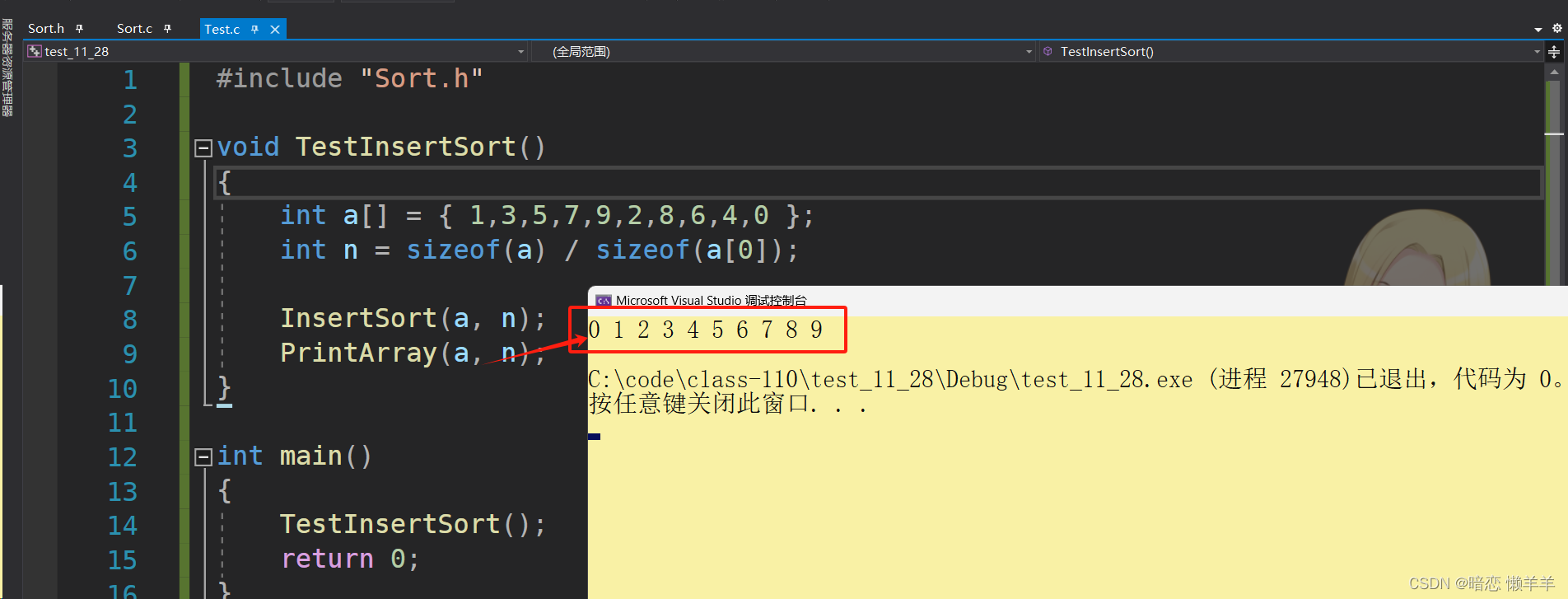
这样写是没问题,但感觉稍微有点挫~!我们在当前元素不大于前面元素的时候要判断一次,是否越界也要判断一次。

我们能不能想办法给优化一下呢?答案是肯定的!我们无论是判断当前的元素不比前面的大还是越界最后插入的都是end+1的位置,所以当在单趟的循环(while)内一旦不满足当前的比前面的大则立刻跳出当前循环。到了单趟循环外有可能是break结束的,也有可能是end < 0结束的,但我们根本不需要关心他,直接插入到end+1的位置即可~!
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
}
else
{
break;
}
--end;
}
a[end + 1] = tmp;
}
}这样写简洁了不少吗,也不容易出错了~!我以前学的时候老是把上面第一种的break给忘了,最后找半天(Q^Q)....所以建议大家一般写第二种~!
复杂度分析
时间复杂度:O(N^2) ---> 单趟是O(N),最坏情况N个元素都要走一次单趟
空间复杂度:O(1) ---> 额外使用空间的个数是常数个
当要排序的序列接近有序时性能最好O(N)~!
OK, 我们直接插入排序就介绍到这里,下面我们来介绍一下它的优化版 ----- 希尔排序!!
三、希尔排序及其实现
我们上面介绍过直接插入的时间复杂度是O(N^2),它的性能一般~!有一天一位叫D.L.Shell的大佬去学习了直接插入排序后,想既然你直接插入排序在接近有序的情况下性能很好(O(N)),那我能不能把一组无序的元素经过处理先让他变得接近有序然后再来一趟直接插入呢?其实他这种想法直接把直接插入排序优化到几乎能和快排平起平坐了~!就是下面这位大佬:

OK,我们来看看大佬的具体思路!
希尔排序的思路
1、进行多组预排序
2、最后再来一次直接插入
什么意思呢?我来解释一下:这里的多组预排是:
先选定一个整数增量gap(一开始gap = n / 2),将数组的元素分为gap 组,将每个距离为gap的分为一组,并对每个小组进行距离为gap的"直接插排",然后不断的缩小gap(gap /= 2),重复上述操作,直到gap == 1时就说明各个组的都已经排好,此时相较于一开始已经是非常有序的了~!最后我们再来一趟直接插入排序则该序列就是有序的了!
OK, 画个图理解一下:
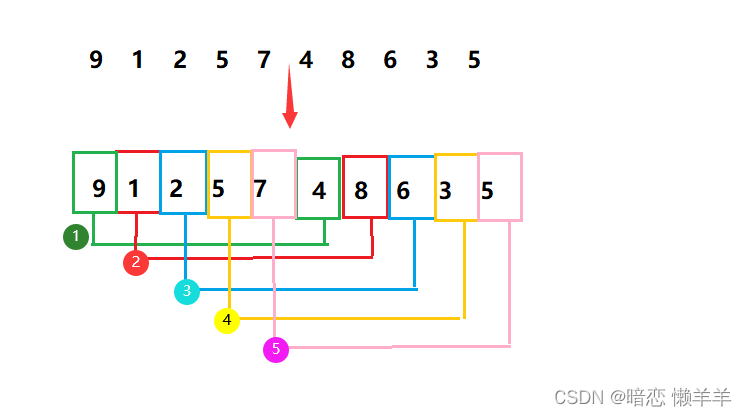
这就将一个完整的数组分成了gap 组,此时的gap 是 5,我们走一下预排序的一个gap:

他这样走下去,gap最后一定会到gap == 1,当gap == 1那就是直接插排了:
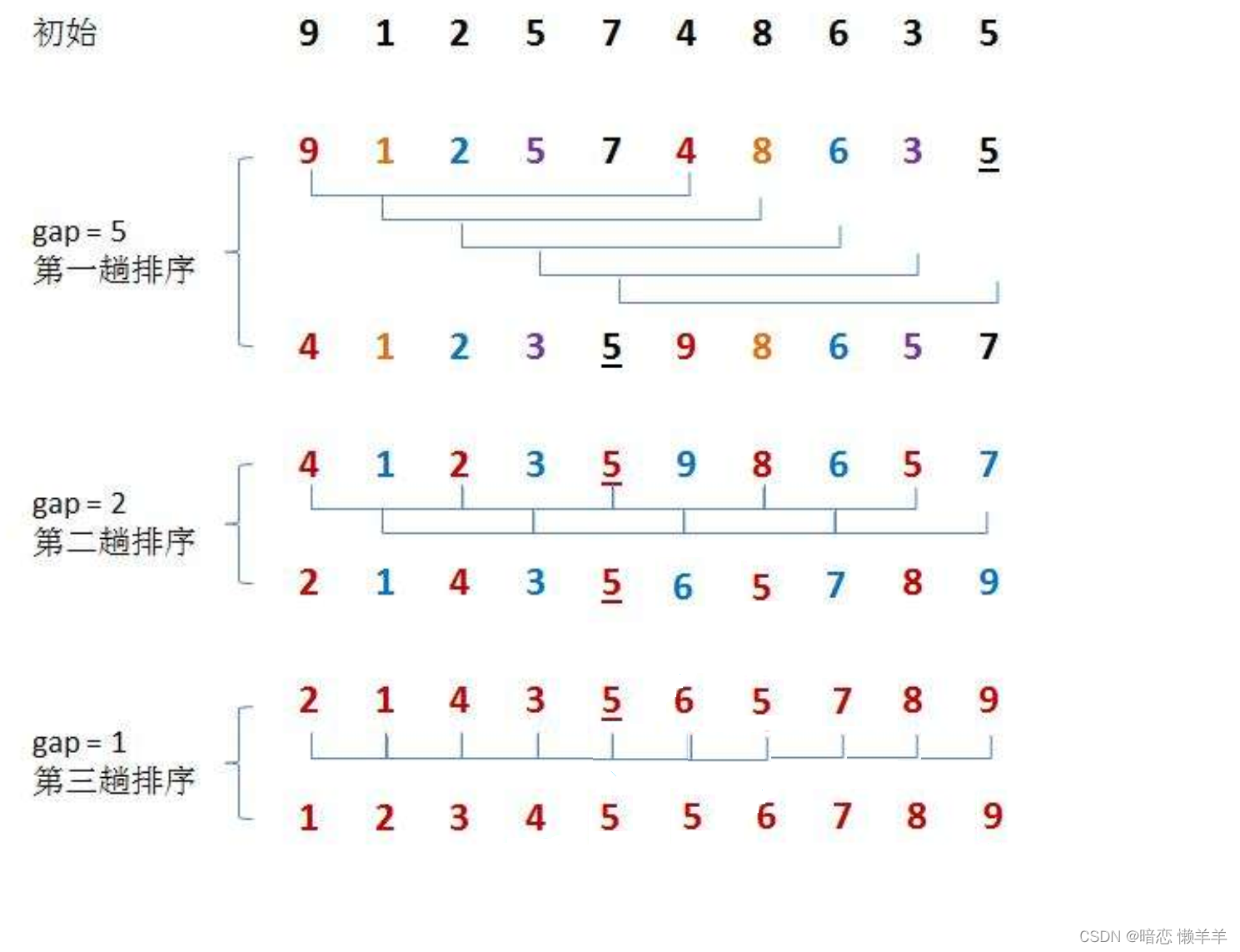
上述栗子可以清楚的看到当gap == 1时,未开始最后一次直接插排前的数组已经是很有序了,当经过最后一趟直接插入排序后就是有序了~!

希尔排序的实现
还是先单趟,再整体~!
单趟
每一组的单趟
for (int i = 0; i < n - gap; i += gap)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = tmp;
}注意的是这里是n - gap 而不是n - gap - 1
这是一组的单趟,这里和直接插入排序几乎一样,当gap == 1就是直接插排~!此时有多少组,就走多少组这样的单趟,所以在外面在套一层循环才是所有组的单趟~!
所有组的单趟
for (int i = 0; i < gap; i++)
{
for (int i = 0; i < n - gap; i += gap)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = tmp;
}
}这就是所有的预排序的单趟,那他到底走多少趟预排呢?具体不知道,当gap最后通过调整到(gap /= 2或gap = gap / 3 + 1) gap == 1即可!所以总体应该在外面套个循环:
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap /= 2;
for (int i = 0; i < gap; i++)
{
for (int i = 0; i < n - gap; i += gap)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = tmp;
}
}
}
}gap 一开始是n,然后开始执行第一趟时时gap /= 2;然后每次调整都是/=2,最后一次进入循环一定是1(n, n / 2, n / 4, n / 8, n / 16, n /32 ..... 4, 2, 1),即直接插入排序了~!
OK,测试一下:
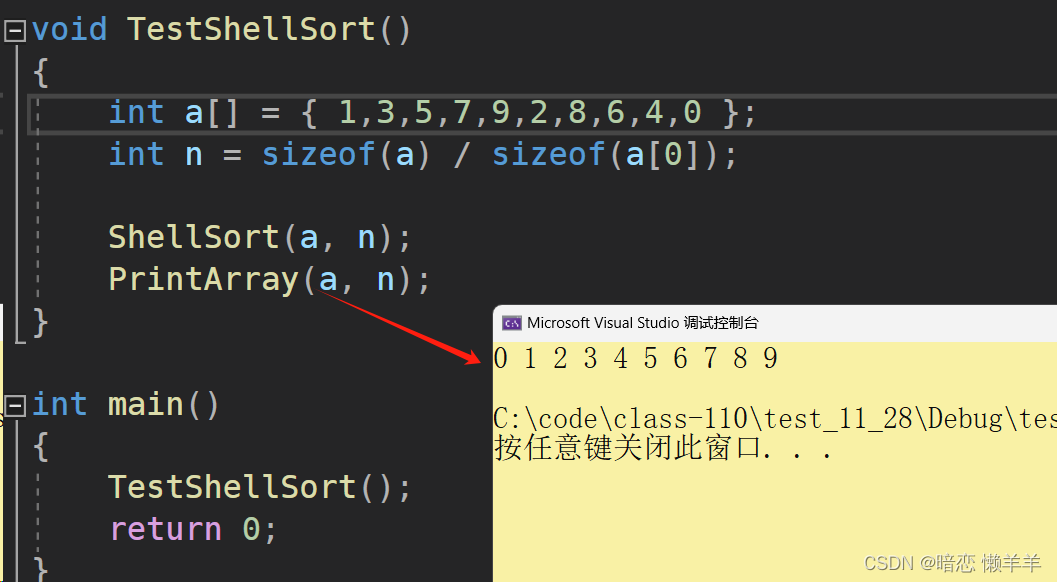
没问题!但这段代码被另一位大佬进行过优化,如下:
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = tmp;
}
}
}他这里把,单组逐一排改成了多组并排~~!以前我们是一组跑完了再去排另一组,他改完后直接一遍就可以把多组排好~!但性能上没有差别,,。
这里他给的gap = gap / 3 + 1;这样写的效率其实比gap /= 2的要好一点(网上以前看到的),他这里+1是因为,gap / 3有时候会小于1(例如: 2 / 3),这样最后一趟就排不了了~!+1就可以解决这个问题!
复杂度分析
希尔排序的时间复杂度是极其不好计算的,因为它的gap 的取值方法太多,很难精确地去计算,在好多书中给的都不同:例如严蔚敏老师的书中是如下:

殷人昆老师的书中如下:

由于这里我们的gap是按照殷人昆老师提出的方式取的,而殷人昆老师也对其进行了大量的数据实验统计,我们可以暂时认为
希尔排序的时间复杂度为:O(N^1.25)或O(N^1.3)
希尔排序的空间复O(1)
OK,本期插入排序就先介绍到这里,好兄弟,我们下期选择排序见~!