
作者:向军涛、雷万钧 来源:2023 上海 KubeCon 分享
可观测性来源
在 Kubernetes 集群上,各个维度的可观测性数据,可以让我们及时了解集群上应用的状态,以及集群本身的状态。
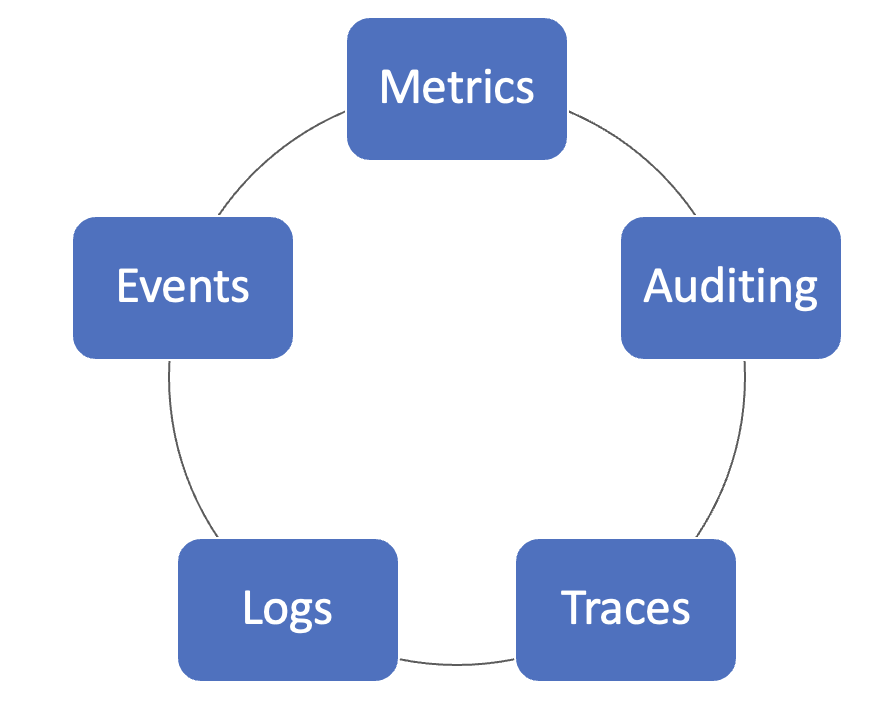
- Metrics 指标:监控对象状态的量化信息,通常会以时序数据的形式采集和存储。
- Events:这里特指的是 Kubernetes 集群上所报告的各种事件,他们是以 Kubernetes 资源对象的形式存在。
- Auditing:审计,是与用户 API 和安全相关的一些事件。
- Logs:日志,是应用和系统对它们内部所发生各种事件的详细记录。
- Traces:链路,主要记录了请求在系统中调用时的链路信息。
告警规则
接下来介绍一下几个可观测性维度上,我们是如何实现告警的。
metrics
在云原生监控领域,Prometheus 是被广泛使用的,它可以说是一个事实上的标准。
对于一个单独的集群来说,或者说是集群自己管理指标存储的场景,我们直接部署一个 Prometheus,就可以提供指标采集、存储、查询和告警的功能。当然也可以额外部署一个 Ruler 组件,来专门进行规则的评估和告警,这样可以减轻 Prometheus 组件的负担。
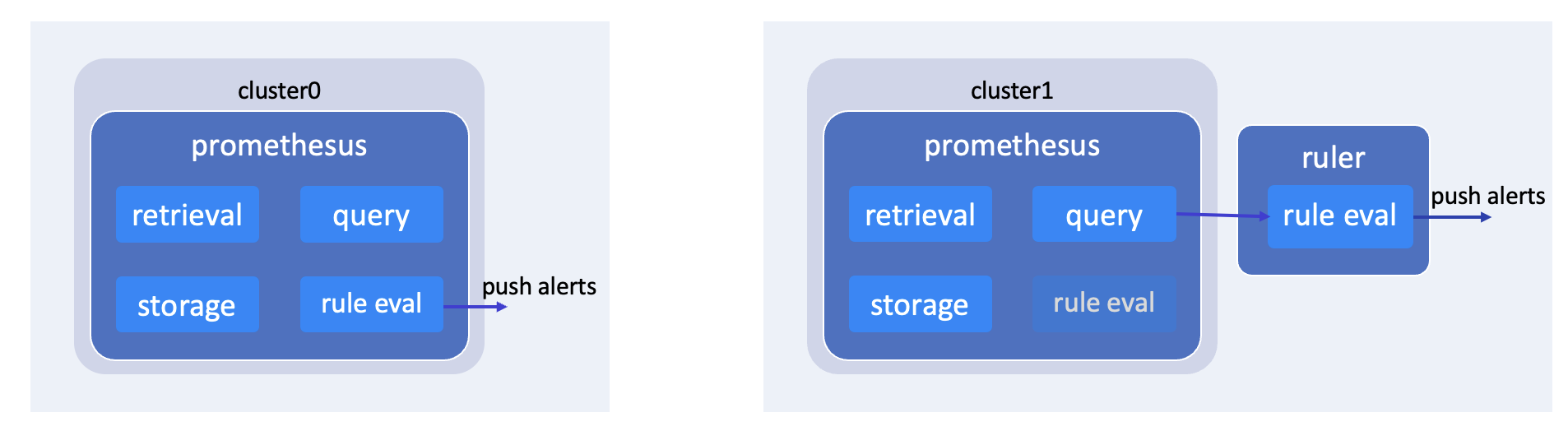
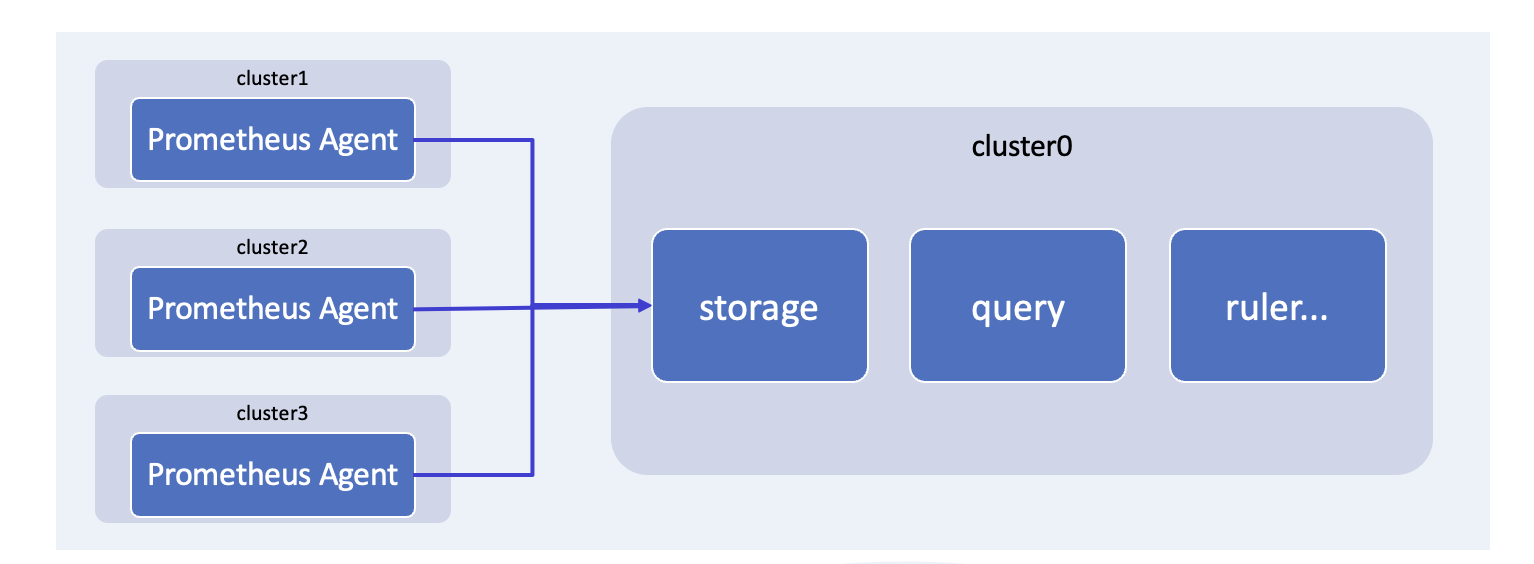
我们还会面临指标数据托管的场景,因为有一些集群会有轻量化的需求,它需要将指标数据托管到一个 host 集群上,或者是托管到专门的服务上。
Prometheus 是支持 Agent 模式的,这个模式下的 Prometheus 可以将指标进行采集,然后推送到一个主集群上进行存储。在主集群上,我们需要提供指标存储和查询的功能,当然告警也需要在主集群上进行,这时候的告警不只是要实现针对每个集群的单独告警,还需要支持多集群关联告警。
Prometheus Operator 作为管理 Prometheus 的 Kubernetes 原生方式,为部署和配置 Prometheus 提供了极大的便利。比如 Prometheus Operator 定义了一个 ServiceMonitor CRD,我们可以用它来方便的配置拉取指标的 targets。

另外 Prometheus Operator 还定义了一个 PrometheusRule CRD 来配置告警规则,但目前仍然存在一些不足:
- 配置粒度大,导致对并发更新的支持不足。
- 可配置性不够,比如不支持禁用告警规则。
- 对多租户和多集群场景的支持较差。
为了让规则配置更加灵活,并且能够更好的应用到多集群和多租户的场景,我们引入了三个新的 CRDs。这些 CRDs 以规则组为配置单元,配置粒度更加细化,可配置性也得到了增强。
- RuleGroup:项目级别的资源,只对所在项目的指标生效。
- ClusterRuleGroup:集群级别的资源,其生效范围是其实例所在集群的指标。
- GlobalRuleGroup:特殊资源,支持对多个指定集群的指标生效。

上方是 RuleGroup 的一个实例。
每个规则组都是一个配置单元,可以包含有关联关系的多个规则。
在单个规则的结构上,我们保留了 PrometheusRule CRD 中原始的规则结构,以确保和上游 PrometheusRule 的兼容性。
在 RuleGroup 的实例当中,我们可以通过设置一个资源标签来启用或者禁用整个规则组,也可以在规则配置中进行单个规则的禁用或启用。
另外我们还提供了一个 exprBuilder,以针对一些典型的告警场景,通过简单的配置即可进行规则表达式的自动化构建。
exprBuilder 提供了配置 Prometheus 查询表达式的便捷方法,涵盖了工作负载和节点的各种指标告警。
- 工作负载
- 类型:Deployment、StatefulSet、DaemonSet。
- 指标:工作负载的 CPU、内存、网络和副本。
- 节点(不适用于 RuleGroup 实例)
- 指标:节点的 CPU、内存、网络、磁盘、pod 使用率等。
RuleGroup,ClusterRuleGroup 和 GlobalRuleGroup 的实例可以组合成 PrometheusRule 的实例。在此过程中,会添加一些指标数据访问的限制。比如 RuleGroup 被合并生成到 PrometheusRule 实例中时,它会将 exprBuilder 构建成 Prometheus 查询表达式,同时也会将 namespace 的条件注入到表达式中,以限制规则可以访问的指标。

在多集群告警的场景下,还会涉及到 PrometheusRule 的跨集群同步。在这个同步过程中,我们会将 cluster 条件注入规则表达式中,这样可以限制规则访问的集群指标。

无论采用哪种指标存储管理模式,在数据侧评估告警规则的效率会更高。如果一个集群自己管理指标存储,那么同一集群的 Ruler 可以直接加载这些规则,然后进行评估和告警,RuleGroup 和 ClusterRuleGroup 的更新也会及时反馈到 Ruler 组件内部。

如果一个集群将指标数据托管到一个主集群上,在这个集群上仍然会有 RuleGroup 和 ClusterRuleGroup 合并生成 PrometheusRule 的过程,不过生成的 PrometheusRule 会被同步到主集群上,由主集群的 Ruler 进行评估和告警。这是因为在同步的过程中,规则表达式中已经注入了 cluster 的过滤条件,所以能够正常的对该集群的指标数据进行评估,并决定是否告警。
如果有多个集群将数据托管到一个主集群上,那么可以在主集群上配置多个 Ruler 来分担压力。在 KubeSphere 的某些版本中,可以根据多集群的规模来动态的扩展 Ruler 以及相关的查询组件,以确保告警评估过程高效运行。

由新定义的规则资源触发的告警不仅包含指标标签,还将通过以下标签丰富告警信息以方面故障定位:
- alerttype:区分不同的告警来源。
- cluster:用于多集群方案,快速定位告警对象。
- severity:对告警执行分级控制。
- rule_group:在规则组和告警之间建立有效的关系。
- rule_level:在规则组和告警之间建立有效的关系。
events
接下来介绍一下事件告警规则的实现方式。
Kubernetes 事件通常表示集群中的某些状态变化,作为 Kubernetes 资源对象,其保留时间有限。kube-events 项目中的 exporter 组件可以导出这些事件进行长期存储,并通过评估事件规则生成与 Alertmanager 兼容的告警。这些规则可以过滤掉告警、关键事件或者用户感兴趣的事件。
事件规则 CRD 定义了基于事件的告警配置:
- condition:它类似于一个 sql 语句的 where 部分(通过我们实现的 event-rule-engine 来提供语法支持),用于支持更灵活的事件过滤方式。
- labels:添加到告警中的额外标签。
- annotations:关于告警的详细信息。

在 KubeSphere 中,事件规则实例中的 kubesphere.io/rule-scope 标签可用于限制规则的生效范围:
- cluster:适用于集群中的所有事件。
- workspace:适用于属于同一工作区的多个命名空间中的事件。必须在规则实例中指定
workspace标签。 - namespace:规则实例所在的 namespace 需要与事件涉及对象所在的 namespace 相匹配。
audit events
接下来介绍一下审计告警规则的实现方式。
在 Kubernetes 集群中,是通过审计事件记录了所有 API 的调用,包含了请求响应信息和用户信息。审计组件在提供审计导出功能的时候,还可以根据相关的规则进行灵活的配置。
审计规则 CRD 定义了过滤审计事件的配置,这些事件将被长期存储或生成告警发送给用户。每个审计规则实例可包含多个规则。
定义了四种类型的规则:
- rule:真正完整的规则,带有条件字段,也是之前的类似 sql 的表达式。
- macro:精简规则,可被其他宏或规则调用。
- list:列表,可被宏或规则调用。
- alias:只是一个变量的别名。
如何配置接收告警通知
所有的告警都将通过通知系统,实时准确地发送给用户。KubeSphere 团队开源的 Notification Manager 是一个多租户的云原生通知管理工具,它支持多种通知渠道,比如微信、钉钉、飞书、邮件、Slack、Pushover、WeCom、Web hook 以及短信平台(阿里、腾讯、华为)等等。
下面就来通过 Notification Manager,快速地搭建出一套云原生的多租户通知系统。
Notification Manager 会接收来自 Prometheus、Alertmanager 发出的警告消息、K8s 产生的审计消息以及 K8s 本身的事件。在规划中我们还会实现接入 Prometheus 的告警消息和接入 Cloud Event 。消息在进入缓存之后,会经过静默、抑制、路由、过滤、聚合,最后进行实际的通知,并记录在历史中。

下面是对每个步骤的解析:
静默(Silence)
静默的作用是在特定的时间段阻止特定的告警发送,具有时效性。可以通过配置时间段或者 Cron 表达式来设置静默规则的生效时间。当然,也可以设置永久生效的静默规则。
静默规则有两种级别:全局级别和租户级别。全局级别的静默规则作用于所有的告警,租户级别的租户级别只作用于需要发送给某个租户的告警。
抑制(Inhibit)
抑制的作用是通过某些特定的告警去阻止其他告警的发送。一个节点宕机之后会发送大量告警,而这些告警不利于我们排查原因,我们可以通过设置抑制规则不再发送这部分告警给用户。
路由(Route)
告警、事件、审计都是由一个个标签组成的,路由的本质就是根据标签寻找需要接收标签的接收器。换句话说,路由的作用就是根据告警信息去寻找,要把告警发送给哪个用户,用户又通过什么方式去接收告警。
那么如何去定义用户接收告警的方式?
Notification Manager 引入了一个 Receiver 的概念。
Receiver 用于定义通知格式和发送通知的目的地。接收器包含以下信息:通知渠道信息,如电子邮件地址、Slack channel 等;生成通知消息的模板;过滤告警的标签选择器。
Receiver 分为两类:全局级别和租户级别。
全局级别的 Receiver 会接收所有的告警消息,租户级别的 Receiver 只会接收租户有权限访问的 namespace 下产生的告警消息。
有两种方式把告警和 Receiver 匹配起来:
- 路由匹配:用户可以制定一个路由规则,然后把特定的告警路由到特定的 Receiver 上。
- 根据 namespace 标签匹配:对于没有 namespace 标签的告警,会全部发送到全局级别的 Receiver;对于有 namespace 标签的告警,会根据标签的值,发送到有权限访问 namespace 租户创建的 Receiver 上。
这是一个路由规则,我们可以通过标签选择器去选择需要路由的告警,然后可以把这些告警路由到指定租户的所有 Receiver 上,或者把它路由到某一个指定的 Receiver 上。更进一步,我们可以选择某一些类型的 Receiver,比如我们可以把告警路由到所有的 Email Receiver,而不把它路由到 wechat Receiver。

对于这两种模式,有三种协同方式,分别是:
- All:同时使用两种方式匹配。
- 路由优先:优先使用路由规则匹配,未匹配成功的使用自动匹配。
- 只使用路由:使用路由规则未匹配到 Receiver,则不发送通知。
过滤(Filter)
每个用户对告警的需求是不一样的,我们需要为每个选定的 Receiver 过滤掉无效或不感兴趣的告警。这就是 Filter 的作用。
实现 Filter 的方式有两种,一种是通过在 Receiver 中设置标签选择器,过滤掉不重要的通知,对于单个通知有效,另一种是定义租户级别的静默规则,对部分通知进行静默。
聚合(Aggregation)
告警匹配到了对应的 Receiver,就可以通过设定的规则,将同一 Receiver 需要发送的告警做一个聚合。
聚合的作用有两个:
- 聚合告警消息,便于归档,方便用户定位故障。
- 减少调用频次,避免被微信、钉钉等禁言,节省资源。
模板(Template)
到了这一步,告警发送之前的所有准备工作已经完成了,接下来就要向用户发送通知。
首先,我们需要根据告警消息生成一条通知消息(根据不同的 Receiver 生成不同的消息)。我们支持用户自定义通知模板,用户可以定义全局模板,也可以为每个接收者定义模板。同时我们支持用户自定义语言包,然后实现语言切换。Notification Manager 为大家提供了内置的相关函数,可以实现语言的翻译功能。
Config
现在一切都准备就绪,是时候向用户发送通知了,但我们还缺少一些关键信息,例如:SMTP 服务器和用于发送电子邮件的电子邮件地址;用于向 Slack 频道发送通知的 Slack APP 令牌;飞书的 AppID 和 AppSecret,因此我们需要定义这些信息。
Config 就是用来定义发送通知消息所必需的一些信息的,同样分为全局类型和租户类型两种。
对于全局级别的 Receiver,默认情况下,会选择全局级别的 Config。对于租户级别的 Receiver,默认选择当前租户的创建的 Config。如果当前租户未创建 Config,会选择全局级别的 Config。
同时也支持 Receiver 通过标签选择器去指定 Config。
通过发送配置和接收配置分离的模式,我们可以最大限度的实现配置复用,同时可以实现多租户的通知设置。

举个简单的例子,比如对邮箱这种通知模式,整个公司可能只有一个 SMTP 服务器,这样就可以设置一个全局级别的 Email Config,然后所有的租户只配置一个 Receiver 就可以了。
至此我们就完整的搭建了一个多租户的云原生通知系统,然后就可以给用户发送通知了。
阿里云严重故障,全线产品受影响(已恢复) 汤不热 (Tumblr) 凉了 俄罗斯操作系统 Aurora OS 5.0 全新 UI 亮相 Delphi 12 & C++ Builder 12、RAD Studio 12 发布 多家互联网公司急招鸿蒙程序员 UNIX 时间即将进入 17 亿纪元(已进入) 美团招兵买马,拟开发鸿蒙系统 App 亚马逊开发基于 Linux 的操作系统,以摆脱 Android 依赖 Linux 上的 .NET 8 独立体积减少 50% FFmpeg 6.1 "Heaviside" 发布本文由博客一文多发平台 OpenWrite 发布!