基本概念
Kubernetes集群分为一个Master节点和若干Node节点。
集群所有的控制命令都传递给Master组件,在Master节点上运行(kubectl命令在其他Node节点上无法执行)。
通常在Master节点启动所有的Master组件,包括etcd、api server、controller manager、scheduler。
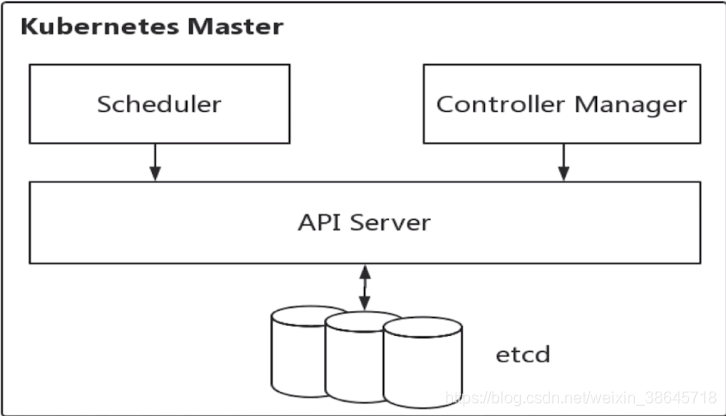
四个组件的主要功能可以概括为:
api server:其他Master组件都通过调用api server提供的rest接口实现各自的功能,如controller就是通过api server来实时监控各个资源的状态的。
etcd:集群数据配置中心。集群的主数据库(键值数据库),存储着所有的资源对象及其状态。数据变更都是通过api server进行的。
scheduler:监听新建pod副本信息,并通过调度算法为该pod选择一个最合适的Node节点。会检索到所有符合该Pod要求的Node节点,执行Pod调度逻辑。调度成功之后,会将Pod信息绑定到目标节点上,同时将信息写入到etcd中。
controller manager:集群内各种资源controller的核心管理者,保证其下每一个controller所对应的资源始终处于期望状态。
通常不会在Master节点上运行任何用户容器,Node节点才是真正运行工作负载的节点。
关系图
controller,即控制器,主要有Deployment,Daemonset、Replicaset(为Replicas controller的进化)等。
得到Pod、Deployment、Daemonset的详细信息,Replicaset同理
首先获得Pod、controller的列表
kubectl get daemonset -n monitoring
接着获得他们相应的详细信息,注意需要声明他们所处的命名空间
kubectl describe pod prometheus-core-6b5dc8dd4d-fs9jh -n monitoring
kubectl describe deployment prometheus-core -n monitoring
kubectl describe daemonset prometheus-node-exporter -n monitoring
Service、Pod以及Node间的关系为:
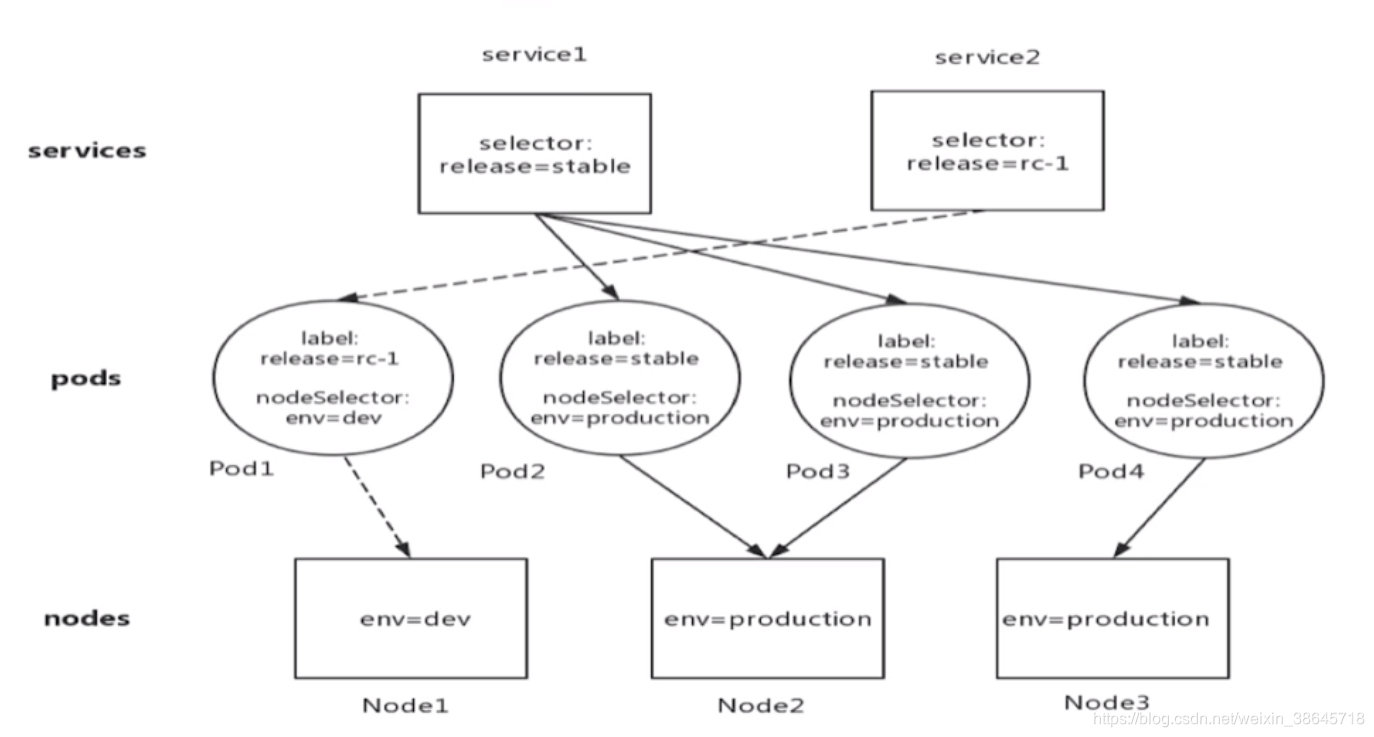
Deployment、Replicaset以及Pod之间的关系
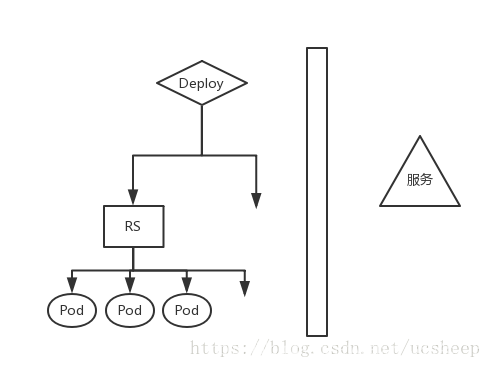
RS部署Pod,Deployment则使管理RS更加方便。
RS保证在同一时间能够运行指定数量的Pod副本,如果实际Pod数量比指定的多就结束掉多余的,如果实际数量比指定的少就启动缺少的。当Pod失败、被删除或被终结时,RC会自动创建新的Pod来保证副本数量。Deployment使用了RS,它是更高一层的概念。在一般情况下,我们推荐使用Deployment而不直接使用RS。
这一整套可以向外提供稳定可靠的Service。
Endpoint、Service和Pod的关系

Endpoint是可被访问的服务端点,只有Service关联的状态为Running 的pod才可能成为Endpoint。
Pod的状态
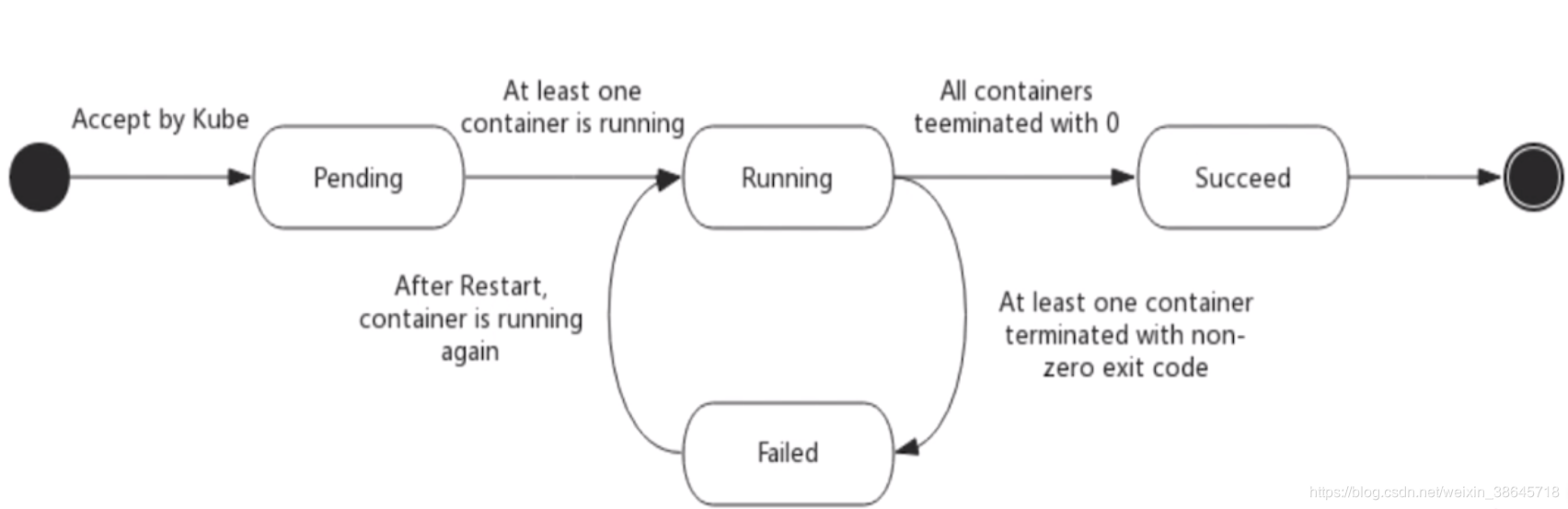
Pending:挂起,这时pod已经被k8s集群接受,但有一个或多个容器镜像尚未创建,等待时间包括调度pod的时间和通过网络下载容器镜像的时间。
Running:此时pod已经被绑定到某一个节点上,pod中所有的容器都被创建并且至少有一个容器正在运行或者处于启动或重启状态。
Succeed:此时pod中的所有容器都被成功终止并且不会重启。
Failed:pod中的所有容器都已经被终止,并且至少有一个容器因为失败而终止(容器以非0状态退出)。
资源对象
kubernetes Dashboard
1、Deployment:常与Namespace挂钩。在yaml文件中声明需要多少Pod副本。在创建完Deployment对象后就会自动部署多少个Pod。
2、Daemonset:常与Namespace挂钩。保证在每个node上都运行一个pod副本。
3、Pod:常与Node、Namespace挂钩。包含一个或多个container。Pod是kubernetes中可以创建和部署的最小单位,也是kubernetes的调度单元,一个pod就代表着集群中运行的一个进程。Pod本身没有资源,Pod中的容器具有资源。
4、Container:容器。
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-56797bdb65-x2qbv 1/1 Running 0 8d
此时说明pod中共有一个container且已经正常启动。
5、Replicaset:常与Namespace挂钩。Replicas Controller的进化。
6、Service:与云原生应用中的微服务概念对应。作为入口地址,向外提供稳定可靠的Service。
7、Endpoint
实例:
Deployment:prometheus-core、alertmanager、kube-state-metrics
Daemonset:prometheus-node-exporter
Pod:prometheus-core-6****-f****、alertmanager-5****-x****、kube-state-metrics-f****-8****、prometheus-node-exporter-5****、prometheus-node-exporter-l****
ReplicaSet:prometheus-core-6****、alertmanager-5****、kube-state-metrics-f****
Service:prometheus、alertmanager、kube-state-metrics、prometheus-node-exporter
注1:Replicas的后缀与Pod第一部分的后缀是一样的
注2:Pod前缀的类型有Deployment、Daemonset
注3:Pod被分配到Node之后会根据镜像下载策略进行镜像下载、
注4:从Deployment、ReplicaSet、Pod三者的关系是一个Deployment对应多个ReplicaSet、一个ReplicaSet对应多个Pod。
重要参考
1、k8s监控方案 – 相关yaml参考
https://blog.csdn.net/liukuan73/article/details/78881008