为什么转载?
这篇关于raft算法的文章,介绍的也很清晰明了,易于理解,直接拿过来用了
一致性问题
在分布式系统中,一致性问题(consensus problem)是指对于一组服务器,给定一组操作,我们需要一个协议使得最后它们的结果达成一致。
由于CAP理论告诉我们对于分布式系统,如果不想牺牲一致性,我们就只能放弃可用性,所以,数据一致性模型主要有以下几种:强一致性、弱一致性和最终一致性等,在本篇章中,我们主要讨论的算法Raft,是一种分布式系统中的强一致性的实现算法。
强一致性的一般实现的原理:当其中某个服务器收到客户端的一组指令时,它必须与其它服务器交流以保证所有的服务器都是以同样的顺序收到同样的指令,这样的话所有的服务器会产生一致的结果,看起来就像是一台机器一样.
Raft算法描述
在Raft被提出来之前,Paxos协议是第一个被证明的一致性算法,但是Paxos的论文非常难懂,导致基于Paxos的工程实践和教学都十分头疼,于是Raft在设计的过程中,就从可理解性出发,使用算法分解和减少状态等手段,目前已经应用非常广泛。
在Raft中,问题分解为:领导选取(Leader election)、日志复制(Log replication)、安全(Safty)和成员变化(membership changes)。
基本概念
复制状态机(Replicated State Machine)
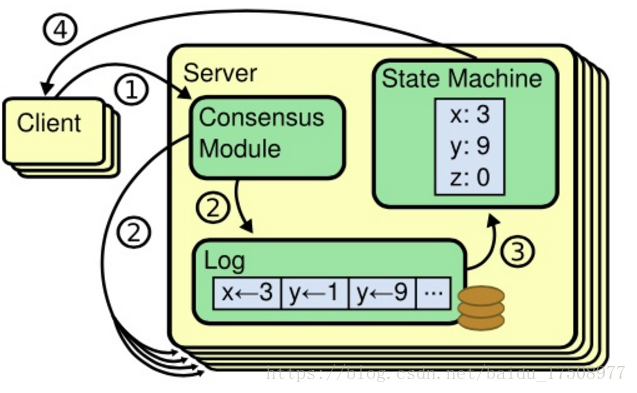
服务器状态
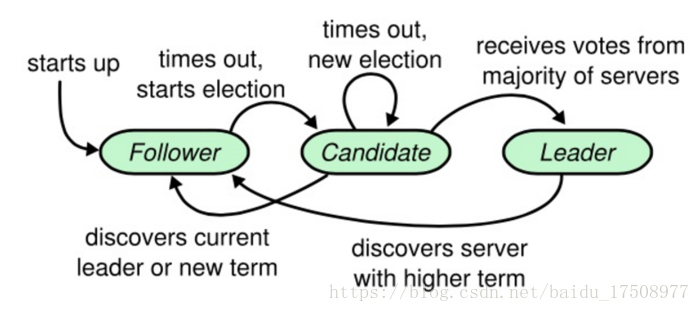
每台服务器一定会处于三种状态:
追随者只响应其他服务器的请求。如果追随者没有收到任何消息,它会成为一个候选人并且开始一次选举。收到大多数服务器投票的候选人会成为新的领导人。领导人在它们宕机之前会一直保持领导人的状态。
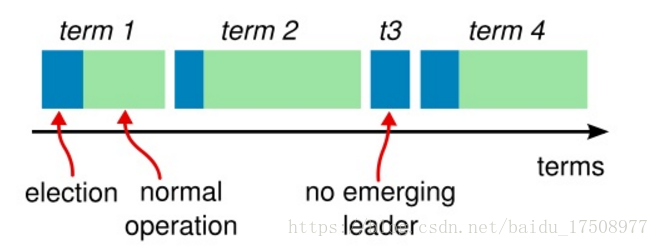
任期(Term)
Raft 算法将时间划分成为任意不同长度的任期(term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最多只有一个领导人。
RPC
Raft 算法中服务器节点之间通信使用远程过程调用(RPCs),并且基本的一致性算法只需要两种类型的 RPCs。请求投票(RequestVote) RPCs 由候选人在选举期间发起,然后附加条目(AppendEntries)RPCs 由领导人发起,用来复制日志和提供一种心跳机制。为了在服务器之间传输快照增加了第三种 RPC。当服务器没有及时的收到 RPC 的响应时,会进行重试, 并且他们能够并行的发起 RPCs 来获得最佳的性能。
RPC有三种:
- RequestVote RPC:候选人在选举期间发起
- AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成
- InstallSnapshot RPC: 领导者使用该RPC来发送快照给太落后的追随者。
超时设置:
- BroadcastTime : 领导者的心跳超时时间
- Election Timeout: 追随者设置的候选超时时间
- MTBT :指的是单个服务器发生故障的间隔时间的平均数
BroadcastTime << ElectionTimeout << MTBF
两个原则:
- BroadcastTime应该比ElectionTimeout小一个数量级,为的是使领导人能够持续发送心跳信息(heartbeat)来阻止追随者们开始选举;
- ElectionTimeout也要比MTBF小几个数量级,为的是使得系统稳定运行。
一般BroadcastTime大约为0.5毫秒到20毫秒,ElectionTimeout一般在10ms到500ms之间。大多数服务器的MTBF都在几个月甚至更长。
领导人选取
- 一般情况下,追随者接到领导者的心跳时,把ElectionTimeout清零,不会触发;
- 领导者故障,追随者的ElectionTimeout超时发生时,会变成候选者,触发领导人选取;
追随者自增当前任期,转换为Candidate,对自己投票,并发起RequestVote RPC,等待下面三种情形发生;
- 获得超过半数服务器的投票,赢得选举,成为领导者;
- 另一台服务器赢得选举,并接收到对应的心跳,成为追随者;
- 选举超时,没有任何一台服务器赢得选举,自增当前任期,重新发起选举;
- 服务器在一个任期内,最多能给一个候选人投票,采用先到先服务原则;
- 候选者等待投票时,可能会接收到来自其它声明为领导人的的AppendEntries RPC。如果该领导人的任期(RPC中有)比当前候选人的当前任期要大,则候选人认为该领导人合法,并转换成追随者;如果RPC中的任期小于候选人的当前任期,则候选人拒绝此次RPC,继续保持候选人状态;
- 候选人既没有赢得选举也没有输掉选举:如果许多追随者在同一时刻都成为了候选人,选票会被分散,可能没有候选人能获得大多数的选票。当这种情形发生时,每一个候选人都会超时,并且通过自增任期号和发起另一轮 RequestVote RPC 来开始新的选举。然而,如果没有其它手段来分配选票的话,这种情形可能会无限的重复下去。所以Raft使用的随机的选举超时时间(150~300ms之间),来避免这种情况发生。
可能的解释:
- 候选者已经给自己投票了,一个候选者在一个任期只会给一个人投票,不会给其他人再投票了;
- 也有可能算法本身设定候选者就拒绝所有的其他服务器的请求。
日志复制
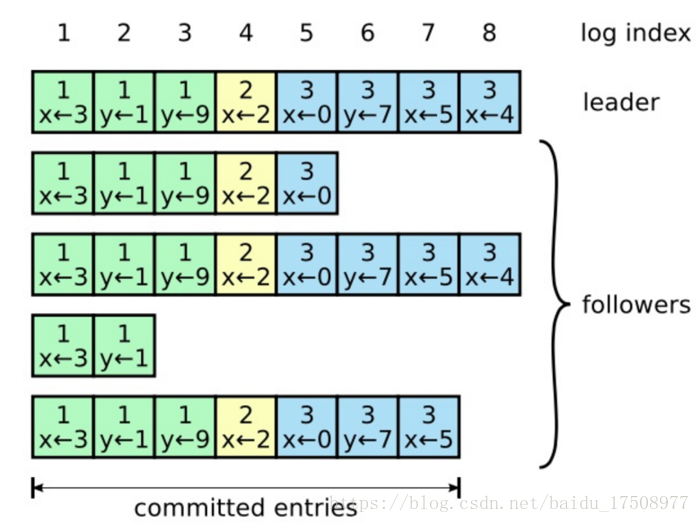
接受命令的过程:
- 领导者接受客户端请求;
- 领导者把指令追加到日志;
- 发送AppendEntries RPC到追随者;
- 领导者收到大多数追随者的确认后,领导者Commit该日志,把日志在状态机中回放,并返回结果给客户端;
提交过程:
- 在下一个心跳阶段,领导者再次发送AppendEntries RPC给追随者,日志已经commited;
- 追随者收到Commited日志后,将日志在状态机中回放。
安全性
到目前为止描述的机制并不能充分的保证每一个状态机会按照相同的顺序执行相同的指令,例如:一个跟随者可能会进入不可用状态同时领导人已经提交了若干的日志条目,然后这个跟随者可能会被选举为领导人并且覆盖这些日志条目;因此,不同的状态机可能会执行不同的指令序列。
领导者永远不会覆盖已经存在的日志条目;
日志永远只有一个流向:从领导者到追随者;
如果投票者的日志比候选人的新,拒绝投票请求;
这意味着要赢得选举,候选者的日志至少和大多数服务器的日志一样新,那么它一定包含全部的已经提交的日志条目。
在Raft算法中,当一个日志被安全的复制到绝大多数的机器上面,即AppendEntries RPC在绝大多数服务器正确返回了,那么这个日志就是被提交了,然后领导者会更新commit index。
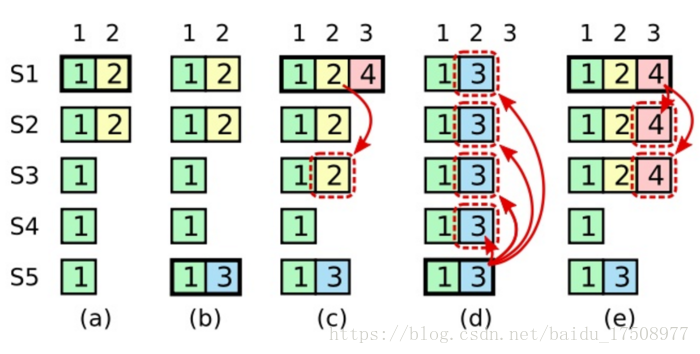
如果允许提交任期之前的日志条目,那么在步骤c中,我们就会把之前任期为2的日志提交到其他服务器中去,并造成了大多数机器存在了日志为2的情况。所以造成了d中S5中任期为3的日志条目会覆盖掉已经提交的日志的情况。
Raft 从来不会通过计算复制的数目来提交之前人气的日志条目。只有领导人当前任期的日志条目才能通过计算数目来进行提交。一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配原则(Log Matching Property),之前的日志条目也都会被间接的提交。
论文中的这段话比较难理解,更加直观的说:由于Raft不会提交任期之前的日志条目,那么就不会从b过渡到c的情况,只能从b发生S5down机的情况下直接过渡到e,这样就产生的更新的任期,这样S5就没有机会被选为领导者了。
候选者和追随者崩溃的情况处理要简单的多。如果这类角色崩溃了,那么后续发送给他们的 RequestVote和AppendEntries的所有RCP都会失败,Raft算法中处理这类失败就是简单的无限重试的方式。
如果这些服务器重新可用,那么这些RPC就会成功返回。如果一个服务器完成了一个RPC,但是在响应Leader前崩溃了,那么当他再次可用的时候还会收到相同的RPC请求,此时接收服务器负责检查,比如如果收到了已经包含该条日志的RPC请求,可以直接忽略这个请求,确保对系统是无害的。
集群成员变更
集群成员的变更和成员的宕机与重启不同,因为前者会修改成员个数进而影响到领导者的选取和决议过程,因为在分布式系统这对于majority这个集群中成员大多数的概念是极为重要的。
简单的做法是,运维人员将系统临时下线,修改配置,重新上线。但是这种做法存在两个缺点:
- 更改时集群不可用
- 人为操作失误风险
直接从一种配置转到新的配置是十分不安全的
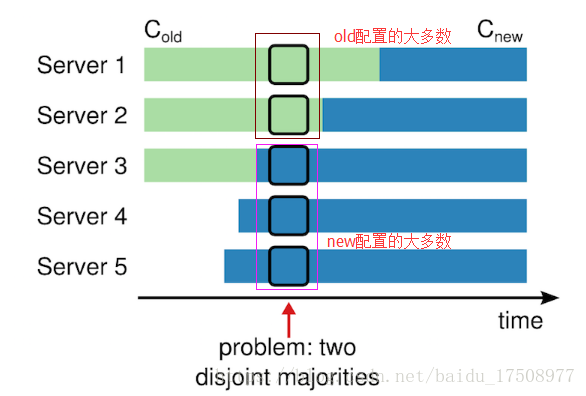
因为各个机器可能在任何的时候进行转换。在这个例子中,集群配额从 3 台机器变成了 5 台。不幸的是,存在这样的一个时间点,两个不同的领导人在同一个任期里都可以被选举成功。一个是通过旧的配置,一个通过新的配置。
两阶段方法保证安全性:
为了保证安全性,配置更改必须使用两阶段方法。在 Raft 中,集群先切换到一个过渡的配置,我们称之为共同一致;一旦共同一致已经被提交了,那么系统就切换到新的配置上。共同一致是老配置和新配置的结合。
共同一致允许独立的服务器在不影响安全性的前提下,在不同的时间进行配置转换过程。此外,共同一致可以让集群在配置转换的过程人依然响应服务器请求。
一个领导人接收到一个改变配置从 C-old 到 C-new 的请求,他会为了共同一致存储配置(图中的 C-old,new),以前面描述的日志条目和副本的形式。一旦一个服务器将新的配置日志条目增加到它的日志中,他就会用这个配置来做出未来所有的决定。领导人完全特性保证了只有拥有 C-old,new 日志条目的服务器才有可能被选举为领导人。当C-old,new日志条目被提交以后,领导人在使用相同的策略提交C-new,如下图所示,C-old 和 C-new 没有任何机会同时做出单方面的决定,这就保证了安全性。
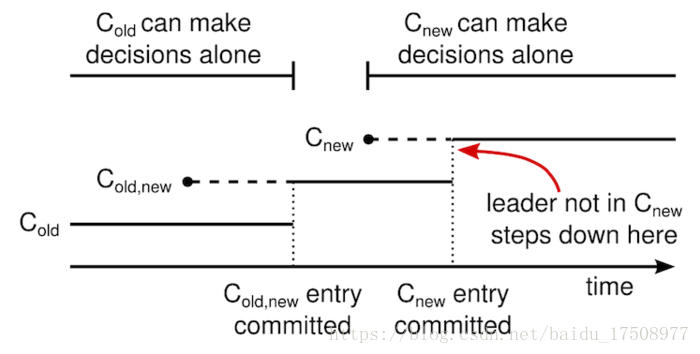
一个配置切换的时间线。虚线表示已经被创建但是还没有被提交的条目,实线表示最后被提交的日志条目。领导人首先创建了 C-old,new 的配置条目在自己的日志中,并提交到 C-old,new 中(C-old,new 的大多数和 C-new 的大多数)。然后他创建 C-new 条目并提交到 C-new 中的大多数。这样就不存在 C-new 和 C-old 可以同时做出决定的时间点。
日志压缩
日志会随着系统的不断运行会无限制的增长,这会给存储带来压力,几乎所有的分布式系统(Chubby、ZooKeeper)都采用快照的方式进行日志压缩,做完快照之后快照会在稳定持久存储中保存,而快照之前的日志和快照就可以丢弃掉。
Raft的具体做法如下图所示:
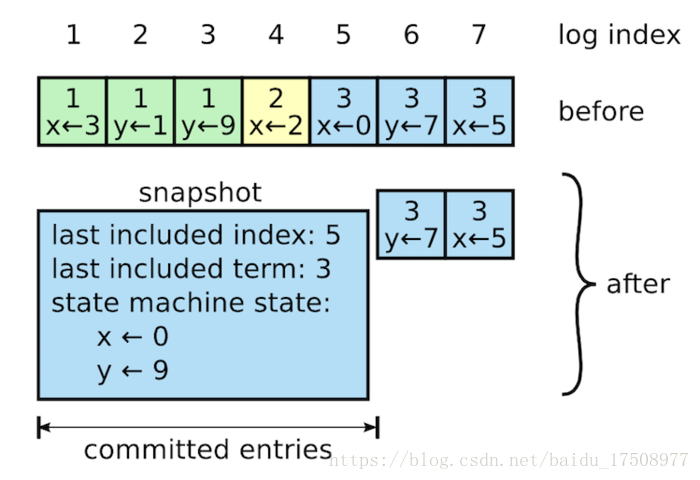
与Raft其它操作Leader-Based不同,snapshot是由各个节点独立生成的。除了日志压缩这一个作用之外,snapshot还可以用于同步状态:slow-follower以及new-server,Raft使用InstallSnapshot RPC完成该过程,不再赘述。
Client交互
- Client只向领导者发送请求;
- Client开始会向追随者发送请求,追随者拒绝Client的请求,并重定向到领导者;
- Client请求失败,会超时重新发送请求;
Raft算法要求Client的请求线性化,防止请求被多次执行。有两个解决方案:
- Raft算法提出要求每个请求有个唯一标识;
- Raft的请求保持幂等性;
关于raft算法,可以参考:
转载文章出处:Raft一致性算法笔记