目录
一、任务背景
阿普尔星球最大的电商网站阿普闪购计划策划一场推广活动,通过发短信的形式,向潜在的用户发送广告和优惠信息,吸引他们来阿普闪购注册并购物。
由于预算以及短信服务商的限制,没有办法对大范围的用户投放,这就需要缩小人群的范围,找出最有可能产生转化的人群。此外,人们的下单行为往往也和时间呈现一定的相关性,什么时候推送营销短信也很重要。
现阶段你作为阿普闪购的数据分析师,这个任务自然就落到了你的肩上,你的目标是:
1.通过数据分析,找到最有可能转化的人群特征(年龄、性别、地域)等;
2.通过数据分析,决定出最有利于转化的营销短信投放时间。
3.通过和多个部门的沟通,最终你从阿普闪购的数据部门申请到了如下数据权限。
4.用户行为表:最近 6 个月的用户行为记录。
5.VIP 会员表:用户 VIP 会员开通情况。
6.用户信息表:用户的相关信息。
二、数据集的获取与解读
2.1 查看数据表
user_behavior_time_resampled.csv、user_info.csv、vip_user.csv 一共三个数据表。
在不知道其数据内容的时候,先用python代码查看一下。
导入所需要的包和表
import pandas as pd
df_user_log = pd.read_csv('../data/user_behavior_time_resampled.csv')
df_vip_user = pd.read_csv('../data/vip_user.csv')
df_user_info = pd.read_csv('../data/user_info.csv')user_behavior_time_resampled.csv
print(df_user_log.info())
df_user_log.head()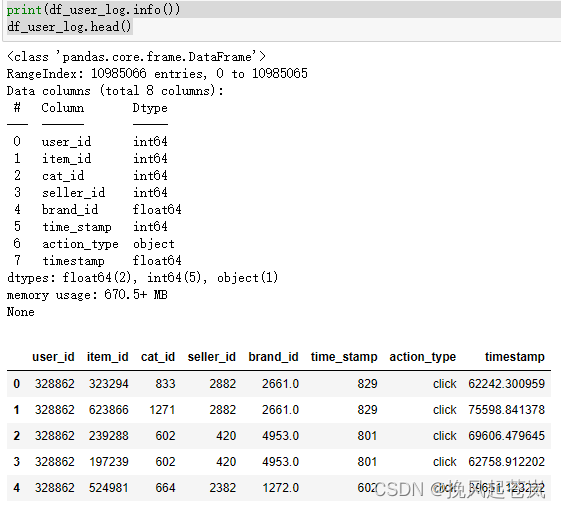
user_info.csv
print(df_user_info.info())
df_user_info.head()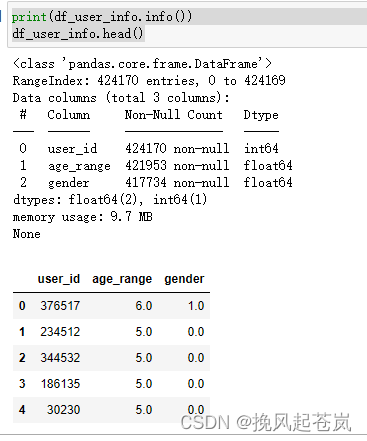
vip_user.csv
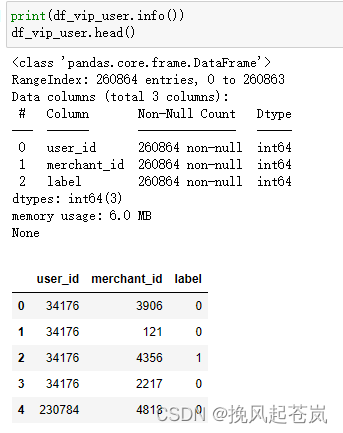
2.2 数据表字段大概的含义(应该是这些意思)
user_id:用户ID,表示购买该商品的用户。item_id:商品ID,表示用户购买的商品。cat_id:商品类别ID,表示该商品所属的类别。seller_id:卖家ID,表示销售该商品的商家。brand_id:品牌ID,表示该商品所属的品牌。time_stamp:时间戳,表示购买该商品的时间。action_type:行为类型,表示用户对该商品的行为(例如购买、评价等)age_range:年龄段,表示用户所属的年龄范围。gender:性别,表示用户的性别。merchant_id:商家ID,表示该商家在电商平台上的唯一标识符。label:标签,表示该商家被分配到的某一特定类别或属性。
通过以上的代码的查阅,我们对这三张数据表有了大概的了解,发现,三张表都有user_id这一个字段,因此,可以着重于从这里入手,做跨表联动分析。
2.3 timestamp 疑云
对于user_behavior_time_resampled.csv这张数据表,发现有俩个相同字段timestamp。
一般解决的方式:发现两个相似字段,和不明确含义的字段,通常的做法是先看一下它的边界(即最大值和最小值)
time_stamp_max = str(df_user_log['time_stamp'].max())
time_stamp_min = str(df_user_log['time_stamp'].min())
print("time_stamp max: " + time_stamp_max, "time_stamp min: " + time_stamp_min)
timestamp_max = str(df_user_log['timestamp'].max())
timestamp_min = str(df_user_log['timestamp'].min())
print("timestamp max: " + timestamp_max, "timestamp min: " + timestamp_min)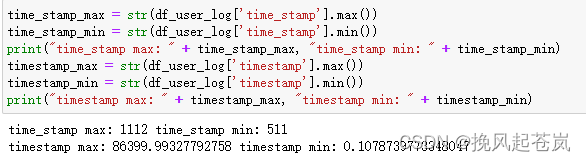
从数据集的描述中,用户行为表是用户 6 个月的行为,那 time_stamp 最大 1112,最小 511 看起来就特别像日期。代表最小日期是 5 月 11 日,最大日期是 11 月 12 日。那既然 time_stamp 是日期,那 timestamp 会不会是具体的时间呢?timestamp 的最大值为 86399 ,而一天最大的秒数为 24*3600 = 86400。两个数字非常接近,那基本可以认定 timestamp 代表的是一天中的第几秒发生了这个行为。
将期中的time_stamp列名改为date,方便区分
df_user_log.rename(columns={'time_stamp':'date'}, inplace=True)
df_user_log.head()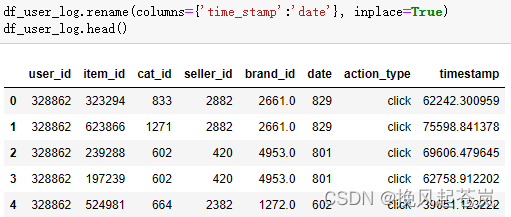
三、数据清洗
3.1 查看数据表缺失值情况
print(df_user_log.isnull().sum(),'/n')
print('********************************')
print(df_user_info.isnull().sum(),'/n')
print('********************************')
print(df_vip_user.isnull().sum(),'/n')
小结:从上述结果中可以看出,user_log 表中大概有 1.8 w 条数据缺少品牌 id 的字段,缺失率为0.16%(1.8w/1098w),一般这个数据量级不会影响到数据分布的分析,暂时不处理。
而user_info 由于缺失的数据量较少,所以我们选择直接删掉这些有缺失的记录。
从输出结果来看, vip_user 这个表没有数据缺失,不用清理。
3.2 对 user_info 做数据清洗
# 删除缺失值
print('删除前',df_user_info.shape)
df_user_info = df_user_info.dropna()
print('删除后',df_user_info.shape)
print('********************************')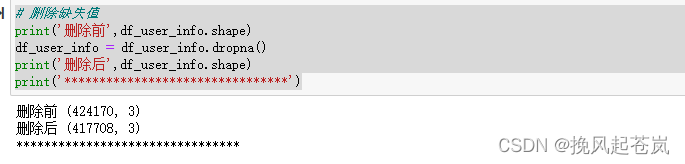
四、数据分布分析
4.1 用户信息分析
查看一下用户的年龄分布情况
df_user_info['age_range'].value_counts()
可以看到 统计年龄段为3.0和4.0(即25-34岁)用户占非0记录数较多(那个0.0的可能是缺失值,不过由于数据占比较大,先不做处理)。
统计年龄段为3.0和4.0(即25-34岁)用户占非0记录的比例 。
user_ages = df_user_info.loc[df_user_info['age_range'] != 0, 'age_range'] # 年龄非0的记录
user_ages.loc[(user_ages == 3) | (user_ages == 4)].shape[0] / user_ages.shape[0] 
可以看到,25~34 岁用户占到了 58% 的比例
4.2 用户性别分布
df_user_info['gender'].value_counts() 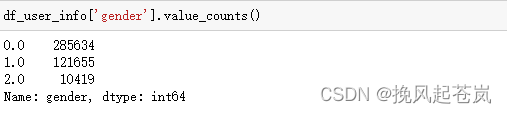
结合之前的数据集定义,0 代表女性,1 代表男性,2 代表未知。可以看到,阿普闪购的核心用户群是女性,是男性数量的 2.35 倍。从用户群体的分析上,我们大概已经勾勒出我们的目标用户画像,25~34 岁之间的女性群体。但目前分析的只是注册用户的信息,会不会存在男性虽然注册用户少但是购买力却更强呢?为了验证这个假象,我们就需要结合订单数据来分析。
4.3 将user_log和user_info合并
df_user_log = df_user_log.merge(df_user_info, how='left', on='user_id')
df_user_log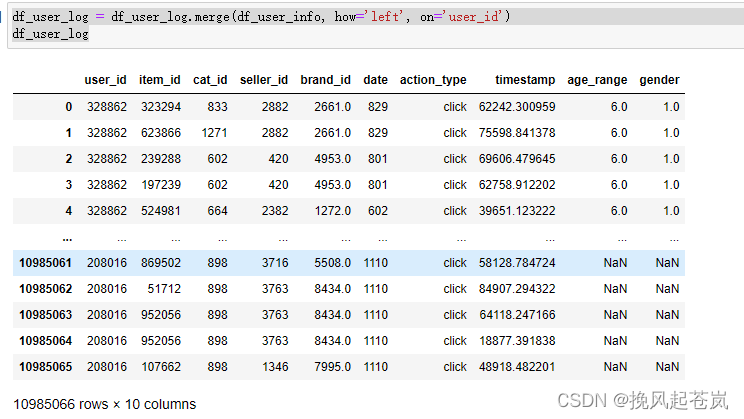
4.4 不同性别用户下单行为分析

可以看到,女性用户不仅注册用户远超过男性,购买力同样惊人,是男性下单量的 2.9 倍。基本可以确定,我们发送营销信息要聚焦的用户群应该是 25~34 岁的女性。用户群确定了之后,下一步要确定发送的时间。接下来,我们需要分析用户下单的时间特征。
4.5 不同日期的下单行为分析
print(df_user_log.loc[df_user_log['action_type'] == 'order', ['date']].date.value_counts(),'\n')
print(df_user_log.loc[df_user_log['action_type'] == 'order', ['date']].date.value_counts(bins=6),'\n')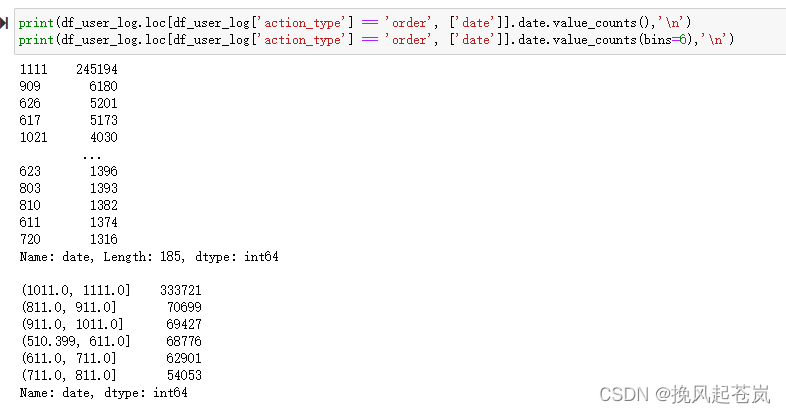
可以看到,用户在 10月中下旬一直到 11 月上旬这个时间段,下单量较为集中。分析完了日期分布后,接下来我们分析一下一天中的时间段的分布。
4.6 不同时间段的下单行为分析
# 增加一列,代表下单时刻(用小时表示)
df_user_log['time_hours_view'] = df_user_log['timestamp'] / 3600
df_user_log.head()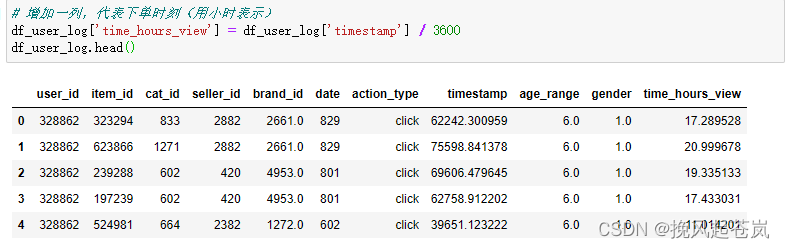
df_user_log.loc[df_user_log['action_type'] == 'order', ['time_hours_view']].time_hours_view.value_counts(bins=12)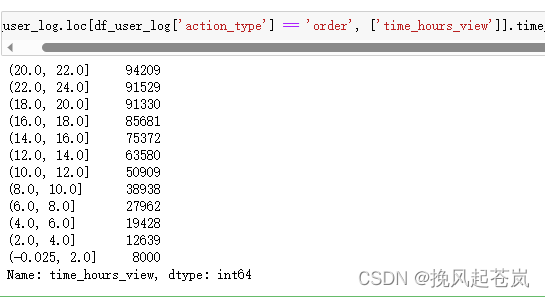
从上述结果可以看到,晚上 8 点到 10 点之间是下单最为密集的,订单量为 94209 单
小结:至此,我们本次短信营销的目标人群和时间就已经基本分析完毕了。我们应该针对 25~34 岁的女性,在 10 月中下旬到 11 月中旬的晚上 8 点到 10 点进行短信的批量发送,这样应该可以收获最好的转化效率。