代码:https://github.com/ashkamath/mdetr
摘要
多模态推理系统依靠预训练的目标检测器从图像中提取感兴趣的区域。然而,这个关键模块通常用作黑匣子,独立于下游任务进行训练,并使用固定的对象和属性词汇表。这使得此类系统难以捕捉以自由形式文本表达的视觉概念的长尾。在本文中,我们提出了MDETR,这是一种端到端调制检测器,可以检测以原始文本查询(如标题或问题)为条件的图像中的对象。我们使用基于Transformer的架构,通过在模型的早期阶段融合两种模式来对文本和图像进行联合推理。我们在130万个文本-图像对上预训练网络,这些文本-图像对是从已有的多模态数据集中挖掘出来的,文本中的短语和图像中的对象之间有明确的对齐。然后,我们对几个下游任务进行微调,如短语基础、参考表达理解和分割,在流行的基准上获得最先进的结果。我们还研究了我们的模型在给定标签集上作为对象检测器的效用,当在几个镜头设置中进行微调时。我们表明,我们的预训练方法提供了一种方法来处理具有很少标记实例的对象类别的长尾。我们的方法可以很容易地扩展到可视化问答,在GQA和CLEVR上取得有竞争力的表现。
背景
我们的方法MDETR是基于最近的DETR[2]检测框架的端到端调制检测器,并将对象检测与自然语言理解结合起来,实现真正的端到端多模态推理。MDETR仅依赖文本和对齐框作为图像中概念的监督形式。因此,与当前的检测方法不同,MDETR从自由格式的文本中检测细微的概念,并将其推广到不可见的类别和属性组合。图1中我们展示了这样的组合以及调制检测。

贡献
•介绍了一种端到端文本调制检测系统,源自于DETR检测器。
•证明了调制检测方法可以无缝地应用于解决诸如短语基础和参考表达理解等任务,并使用具有合成图像和真实图像的数据集在这两个任务上设置了新的最先进的性能。
•表明,良好的调制检测性能自然地转化为下游任务性能,例如在视觉问题回答、参考表达式分割和少数镜头长尾对象检测上实现竞争性性能。
相关工作
我们的调制检测方法建立在DETR系统[2]上,我们在这里简要回顾一下。我们建议读者参阅原文了解更多细节。DETR是一种端到端检测模型,由主干(通常是卷积残差网络[12])和变压器编码器-解码器[59]组成。DETR:End-to-End Object Detection with Transformers-CSDN博客
方法
网络结构

我们在图2中描述了MDETR的体系结构。与DETR一样,图像由卷积主干编码并被平面化。为了保留空间信息,在该平面向量上添加了二维位置嵌入。我们使用预训练的转换语言模型对文本进行编码,以产生与输入大小相同的隐藏向量序列。然后,我们对图像和文本特征应用模态相关的线性投影,将它们投影到共享嵌入空间中。然后将这些特征向量在序列维度上进行连接,以产生单个图像和文本特征序列。这个序列被馈送到一个称为交叉编码器的联合Transformer编码器。遵循DETR,我们在交叉关注交叉编码器的最终隐藏状态时对object queries 应用Transformer解码器。解码器的输出用于预测实际的box。
训练
我们给出了MDETR使用的两个额外的损失函数,鼓励图像和文本之间的对齐。它们都使用相同的注释源:带有对齐边界框的自由格式文本。我们称之为soft token prediction loss 的第一个损失函数是非参数对齐损失。第二种,称为text-query contrastive alignment,是一个参数损失函数,强制对齐对象查询和标记之间的相似性。
Soft token prediction
对于调制检测,与标准检测设置不同,我们对预测每个检测对象的分类类别不感兴趣。相反,我们从引用每个匹配对象的原始文本中预测标记的范围。
具体地说,我们首先将任何给定句子的最大标记数设置为L = 256。对于使用bi-partite matching与ground truth box匹配的每个预测框,该模型被训练为预测与对象对应的所有token positions的均匀分布。
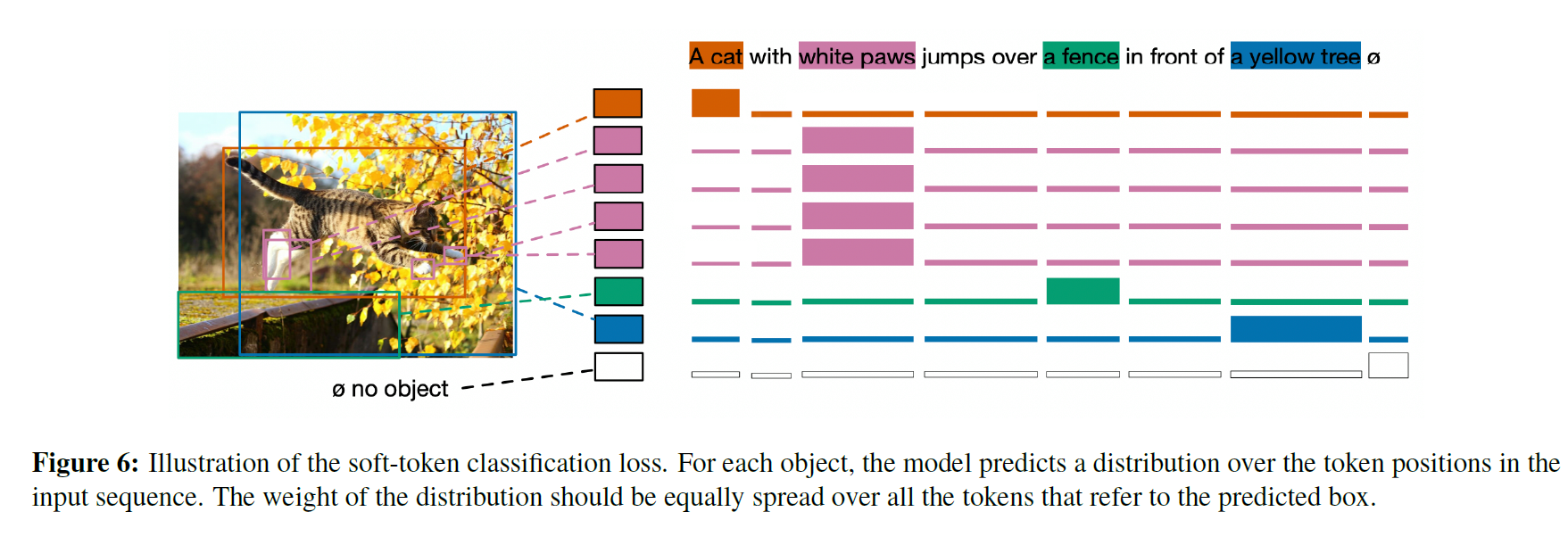
图2显示了一个例子,其中猫的框被训练来预测前两个单词的均匀分布。

在图6中,我们展示了本例损失的简化可视化,根据每个框的单词分布,但在实践中,我们使用BPE方案进行标记化后使用token spans[52]。任何与目标不匹配的查询都被训练为预测“无对象”标签∅。请注意,文本中的几个单词可能对应于图像中的同一个对象,反过来,几个对象也可能对应于相同的文本。例如,图像中的两个方框提到的“a couple”可以在同一标题中单独提到。通过这样设计损失函数,我们的模型能够从相同的引用表达式中学习到共同引用的对象。
Contrastive alignment
虽然soft token prediction使用位置信息将对象与文本对齐,但对比对齐损失强制在解码器输出处的对象的embedded representations与交叉编码器输出处的text representation之间进行对齐。
但是这种额外的对比对齐Contrastive alignment损失确保了(视觉)对象及其对应的(文本)标记的嵌入比不相关标记的嵌入在特征空间中更接近。这种约束比soft token prediction loss更强,因为它直接对表示进行操作,而不仅仅基于位置信息。更具体地说,考虑令牌的最大数量为L,对象的最大数量为n。设T+ i为给定对象oi应与之对齐的令牌集合,O+ i为给定令牌ti应与之对齐的对象集合。
所有对象的对比损失contrastive loss,灵感来自InfoNCE[40]按每个对象的正令牌数归一化,可以写成如下:其中τ是一个温度参数,我们根据文献[63,47]将其设置为0.07。
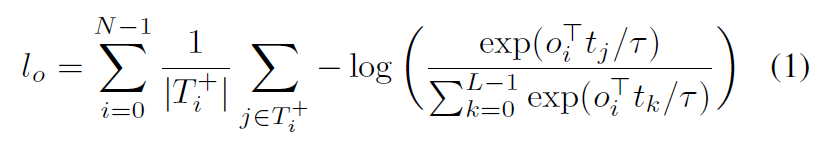
通过对称,所有标记的对比损失,通过每个标记的正对象数归一化,给出如下:

我们取这两个损失函数的平均值作为对比对齐损失。
Combining all the losses
在MDETR中,像在DETR中一样,使用二部匹配 bipartite matching来寻找预测与真实目标之间的最佳匹配。主要区别在于,没有为每个对象预测类标签,而是在文本中对应于该对象的相关位置上预测均匀分布(soft token predictions),使用软交叉熵(soft cross entropy)进行监督。匹配成本除了在DETR中预测框和目标框之间的L1和GIoU损失之外,还包括这个。匹配后的总loss 有 box
prediction losses (L1 & GIoU), soft-token prediction loss,和 contrastive alignment loss。
实验
数据集
CLEVR
合成的数据集,由一些简单的几何形状组成的视觉图像。数据集中的问题多涉及到复杂推理,问题类别包括:属性查询(querying attribute),属性比较(comparing attributes),存在(existence),计数(counting),整数比较(integer comparison),这些问题都是程序生成的。
详细可以看这一篇博客:
Visual Reasoning(1): CLEVR Dataset-CSDN博客

Pre-training Modulated Detection
对于预训练,我们专注于调制检测任务,其目的是检测在对齐的自由格式文本中引用的所有对象。
数据集:Flickr30k [46], MS COCO [30] 和 Visual Genome (VG)
Data combination
句子的组合是使用图着色算法完成的,该算法确保只有GIoU≤0.5的方框的短语被组合,并且组合句子的总长度小于250个字符。通过这种方式,我们得到了一个有130万个对齐的图像-文本对的数据集。
这个组合步骤很重要,有两个原因:1)数据效率,通过将更多信息打包到单个训练样例中,2)它为我们的软令牌预测损失提供了更好的学习信号,因为模型必须学习消除同一对象类别多次出现之间的歧义,如图3所示。

在单句情况下,软标记预测任务变得微不足道,因为它总是可以预测句子的词根而无需查看图像。在实验中,我们发现这种密集的注释转化为文本和图像之间更好的grounding,从而获得更好的下游性能。
模型
文本
我们使用预训练的RoBERTa-base[32]作为我们的文本编码器,有12个Transformer编码器层,每个层的隐藏维度为768,在多头注意力中有12个头。我们使用HuggingFace[61]的实现和权重。
视觉
第一个是ResNet-101[12]在ImageNet上用冻结的Batch Normalization层进行预训练
这可以与多模态理解领域的当前文献相比较,其中流行的方法是使用BUTD对象检测器,并使用来自[1]的在VG数据集上训练的Resnet-101主干。这可以与多模态理解领域的当前文献相比较,其中流行的方法是使用BUTD对象检测器,并使用来自[1]的在VG数据集上训练的Resnet-101主干。
在我们的工作中,我们不受预先训练的检测器存在的限制,并且受到其在目标检测方面的成功[58]的启发,我们选择探索effentnet家族[57]作为我们的骨干。除了ImageNet之外,我们使用了一个在大量未标记数据上训练的模型,使用了一种称为noise - student的伪标记技术[64]。我们选择了仅使用12M权重就能在ImageNet上达到84.1%的top 1准确率的EfficientNetB3和使用30M权重就能达到86.1%的EfficientB5。我们使用Timm库[?]],并冻结批次规范层。
实现细节
我们在32个V100 gpu上预训练了40个epoch的模型,有效批大小为64个,大约需要一周的时间来训练。训练超参数的详细信息见附录A。
下游任务
Phrase grounding
Referring expression comprehension
Referring expression segmentation
Visual Question Answering

实验结果
消融实验
总结
我们提出了MDETR,一个完全可微的调制检测器。我们在各种数据集的多模态理解任务上建立了它的强大性能,并展示了它在其他下游应用中的潜力,如少镜头检测和视觉问答。我们希望这项工作为开发完全集成的多模态架构开辟了新的机会,而不依赖于黑盒目标检测器。