网络结构
(图片来自原论文:FCOS: Fully Convolutional One-Stage Object Detection)
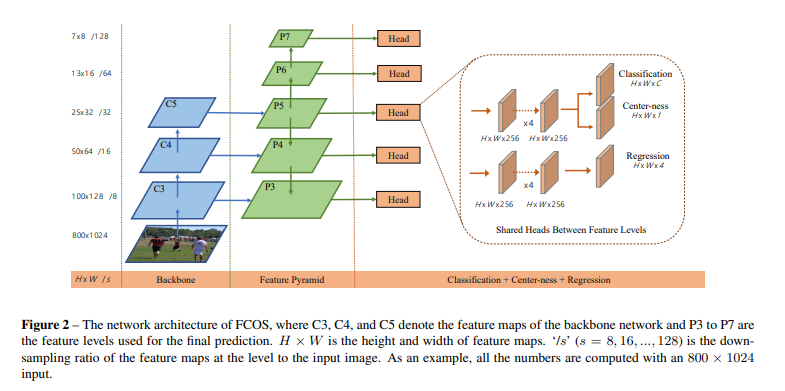
在ResNet50 Backbone中, C 3 , C 4 , C 5 C3,C4,C5 C3,C4,C5是卷积特征图;
在FPN结构中, P 3 , P 4 , P 5 , P 6 , P 7 P3,P4,P5,P6,P7 P3,P4,P5,P6,P7是最后用于预测的特征图;
在预测阶段, P 3 , P 4 , P 5 , P 6 , P 7 P3,P4,P5,P6,P7 P3,P4,P5,P6,P7共享一个Head;
Head有三个分支,分别用于预测分类(80类别)、回归预测中心点到真实框的上高t,下高b,左宽l,右宽r、Center-ness;
重要点
从Anchor到Anchor Free
Anchor方面
- Anchor框的大小固定,对于具有形态大小变化的目标难以检测,可扩展性差。
- Anchor框的大小对检测精度的影响较大。
- 正负样本的Anchor比例不均,即无目标与有目标的比例,且训练繁杂。
Anchor Free方面

x m i n = c x − l ∗ s y m i n = c y − t ∗ s x m a x = c x + r ∗ s y m a x = c y + b ∗ s x_{min}=c_x-l*s\\y_{min}=c_y-t*s\\x_{max}=c_x+r*s\\y_{max}=c_y+b*s xmin=cx−l∗symin=cy−t∗sxmax=cx+r∗symax=cy+b∗s
其中 ( x m i n , y m i n ) (x_{min},y_{min}) (xmin,ymin)为预测框左上角坐标, ( x m a x , y m a x ) (x_{max},y_{max}) (xmax,ymax)为预测框右下角坐标;

C e n t e r n e s s = m i n ( l ∗ , r ∗ ) m a x ( l ∗ , r ∗ ) ∗ m i n ( t ∗ , b ∗ ) m a x ( t ∗ , b ∗ ) Center ness=\sqrt{\frac{min(l^*,r^*)}{max(l^*,r^*)}*\frac{min(t^*,b^*)}{max(t^*,b^*)}} Centerness=max(l∗,r∗)min(l∗,r∗)∗max(t∗,b∗)min(t∗,b∗)
Center ness用于衡量预测中心与真实框中心的距离,越接近于真实框的中心点,该值越接近于数值1.
正负样本框匹配
在YOLO系列使用anchor与真实框的IOU值与阈值比较,判断是否作为正样本。而在FCOS中,使用anchor free方式,即不存在anchor框。
采取的另一种方式为:只要预测中心坐标在真实框的内部,那么这些预测中心点都作为正样本,其他作为负样本。
当然,为了追求更好的效果,将范围进一步缩小,若预测中心点落在 ( c x − r ∗ s , c y − r ∗ s , c x + r ∗ s , c y + r ∗ s ) (c_x-r*s,c_y-r*s,c_x+r*s,c_y+r*s) (cx−r∗s,cy−r∗s,cx+r∗s,cy+r∗s)范围内,则作为正样本,其中r为超参数,s为特征图相对于原图的缩放比例。
存在一种特殊情况,若预测的中心点落在两个真实框的范围内,则默认将该预测中心点分配给面积最小的真实框。
损失函数
L ( { p x , y } , { t x , y } , { s x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + 1 N p o s ∑ x , y 1 { c x , y ∗ > 0 } L r e g ( t x , y , t x , y ∗ ) + 1 N p o s ∑ x , y 1 { c x , y ∗ > 0 } L c t r n e s s ( s x , y , s x , y ∗ ) L(\{p_{x,y}\},\{t_{x,y}\},\{s_{x,y}\})=\frac{1}{N_{pos}}\sum_{x,y}^{}L_{cls}(p_{x,y},c_{x,y}^*)\\+\frac{1}{N_{pos}}\sum_{x,y}^{}1_{\{c_{x,y}^*>0\}L_{reg}(t_{x,y},t_{x,y}^*)}\\+\frac{1}{N_{pos}}\sum_{x,y}^{}1_{\{c_{x,y}^*>0\}L_{ctrness}(s_{x,y},s_{x,y}^*) } L({ px,y},{ tx,y},{ sx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Npos1x,y∑1{ cx,y∗>0}Lreg(tx,y,tx,y∗)+Npos1x,y∑1{ cx,y∗>0}Lctrness(sx,y,sx,y∗)
第一行为分类损失;
第二行为边界框损失;
第三行为"置信度"损失;
N p o s N_{pos} Npos为匹配的正样本数目;
p x , y p_{x,y} px,y表示在特征图(x,y)处预测的每个类别的分数;
c x , y ∗ c_{x,y}^* cx,y∗表示在特征图(x,y)处对应的真实类别标签;
1 { c x , y ∗ > 0 } 1_{\{c_{x,y}^*>0\}} 1{
cx,y∗>0}表示在特征图(x,y)处正样本为1,负样本为0;
t x , y , t x , y ∗ t_{x,y},t_{x,y}^* tx,y,tx,y∗分别表示在特征图(x,y)处预测的边界框位置与真实框的位置信息;
s x , y , s x , y ∗ s_{x,y},s_{x,y}^* sx,y,sx,y∗分别表示在特征图(x,y)处预测的center-ness与真实的center-ness;