基本原理
网络结构
CSPDarknet53
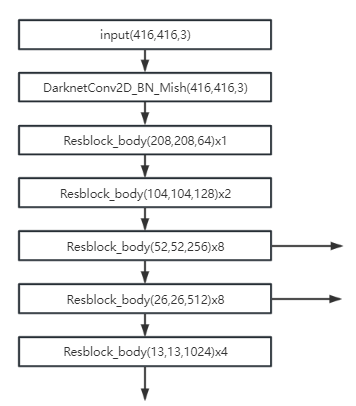
最后三个箭头指向输出即三种特征图
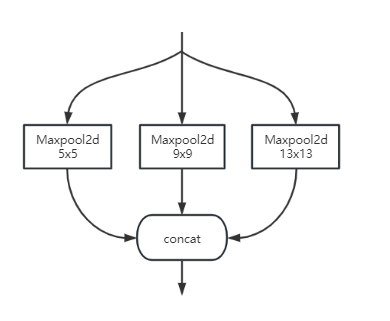
SPP
解决多尺度问题
对于同一个特征输出图,进行三种maxpool2d操作,然后将三种操作的输出进行叠加
PANet
融合上采样、下采样等特征,深度方向拼接
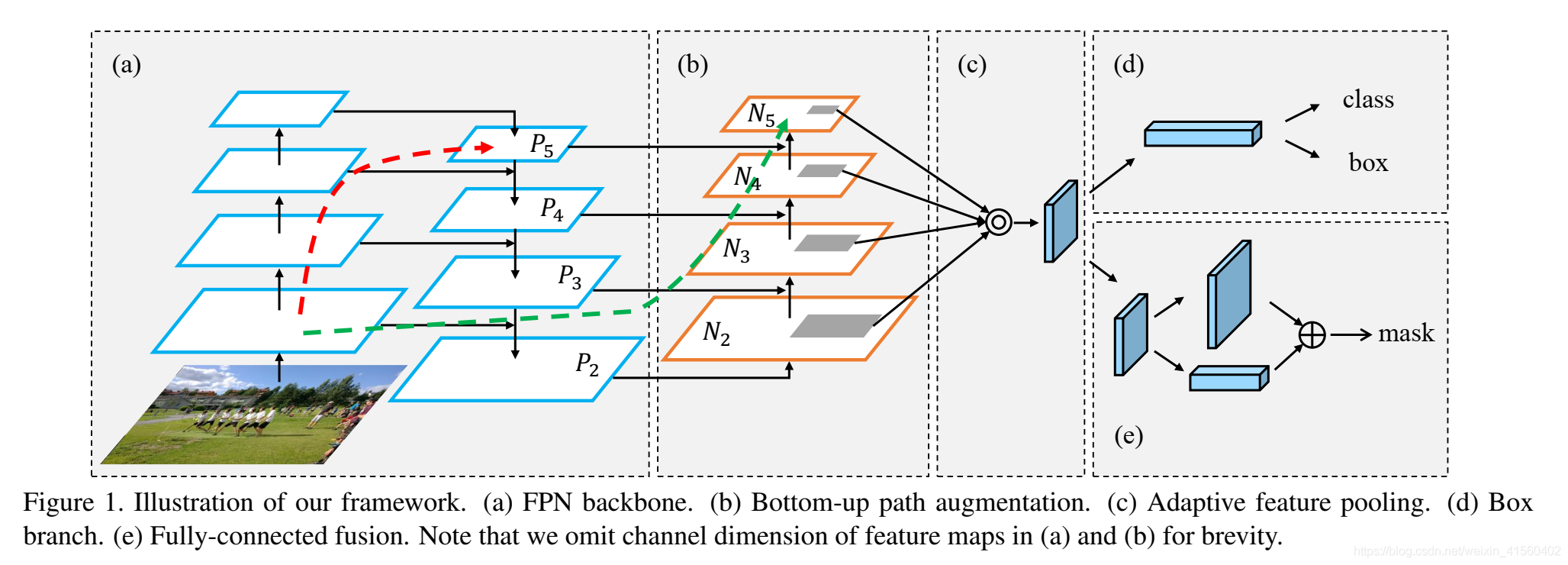
PANet由五个核心模块组成(a,b,c,d,e)
图中红色和绿色的虚线是跨越多层的shortcut,更高实现不同层次的特征融合。
图a中为FPN的自上而下结构,第一列的4个特征图为依次卷积的结果,浅层反应边缘等细节,深层反应更丰富语义特征,第二列为4组feature map,分别为 P 5 , P 4 , P 3 , P 2 P_5,P_4,P_3,P_2 P5,P4,P3,P2,上采样过程使用双线性插值方式。为何不直接使用第一列的特征图旨在单独使用每一层的特征图无法反映整体特征,会减弱表达能力;而使用第二列的特征,可以将浅层特征与深层特征进行融合,达到更为丰富的表达特征。
图b中为自下而上的路径,得到 N 2 , N 3 , N 4 , N 5 N_2,N_3,N_4,N_5 N2,N3,N4,N5共4个feature map.其中 N 2 N_2 N2就是复制 P 2 P_2 P2, N 3 N_3 N3是通过将 N 2 N_2 N2经过步长为2的 3 ∗ 3 3*3 3∗3卷积后的结果加上 P 3 P_3 P3得到的,其他一样处理。
图c为自适应特征池化,融合所有层的feature map,最后得到一个 1 ∗ 1 ∗ n 1*1*n 1∗1∗n的向量,用于分类与定位
损失函数
L o s s = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 M I i j o b j ( 2 − w i ∗ h i ) ( 1 − C I O U ) − ∑ i = 0 S 2 ∑ j = 0 M I i j o b j [ C i ^ l o g ( C i ) + ( 1 − C i ^ ) l o g ( 1 − C i ) ] − λ n o o b j ∑ i = 0 S 2 ∑ j = 0 M I i j n o o b j [ C i ^ l o g ( C i ) + ( 1 − C i ^ ) l o g ( 1 − C i ) ] − ∑ i = 0 S 2 ∑ j = 0 M I i j o b j ∑ c ϵ c l a s s e s [ p i ^ ( c ) l o g ( p i ( c ) ) + ( 1 − p i ^ ( c ) ) l o g ( 1 − p i ( c ) ) ] Loss=\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{M}I_{ij}^{obj}(2-w_i*h_i)(1-CIOU)\\ -\sum_{i=0}^{S^2}\sum_{j=0}^{M}I_{ij}^{obj}[\hat{C_i}log(C_i)+(1-\hat{C_i})log(1-C_i)]\\-\lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{M}I_{ij}^{noobj}[\hat{C_i}log(C_i)+(1-\hat{C_i})log(1-C_i)]\\-\sum_{i=0}^{S^2}\sum_{j=0}^{M}I_{ij}^{obj}\sum_{c\epsilon classes}^{}[\hat{p_i}(c)log(p_i(c))+(1-\hat{p_i}(c))log(1-p_i(c))] Loss=λcoordi=0∑S2j=0∑MIijobj(2−wi∗hi)(1−CIOU)−i=0∑S2j=0∑MIijobj[Ci^log(Ci)+(1−Ci^)log(1−Ci)]−λnoobji=0∑S2j=0∑MIijnoobj[Ci^log(Ci)+(1−Ci^)log(1−Ci)]−i=0∑S2j=0∑MIijobjcϵclasses∑[pi^(c)log(pi(c))+(1−pi^(c))log(1−pi(c))]
第一行为正样本的坐标损失, 2 − w i ∗ h i 2-w_i*h_i 2−wi∗hi为惩罚系数, C I O U CIOU CIOU损失为在DIOU基础上增加的尺度损失。计算公式为
C I O U = I O U − ( ρ 2 ( b , b g t ) c 2 + α ν ) ν = 4 π ( a r c t a n w g t h g t − a r c t a n w h ) 2 α = ν ( 1 − I O U ) + ν CIOU=IOU - (\frac{\rho ^2(b,b^{gt})}{c^2}+\alpha \nu )\\ \nu= \frac{4}{\pi}(arctan\frac{w^{gt}}{h^{gt}}-arctan\frac{w}{h})^2\\ \alpha =\frac{\nu }{(1-IOU)+\nu } CIOU=IOU−(c2ρ2(b,bgt)+αν)ν=π4(arctanhgtwgt−arctanhw)2α=(1−IOU)+νν
其中 b b b代表预测中心坐标, b g t b^{gt} bgt代表真实框中心坐标; ρ \rho ρ代表 b b b和 b g t b^{gt} bgt之间的欧氏距离; c c c代表预测框与真实框最小外接矩形对角线长度; w 、 h w、h w、h和 w g t 、 h g t w^{gt}、h^{gt} wgt、hgt分别代表预测框和真实框的宽、高;
第二行为正样本的置信度损失
第三行为负样本的置信度损失
第四行为分类损失
优化方案
边界框回归
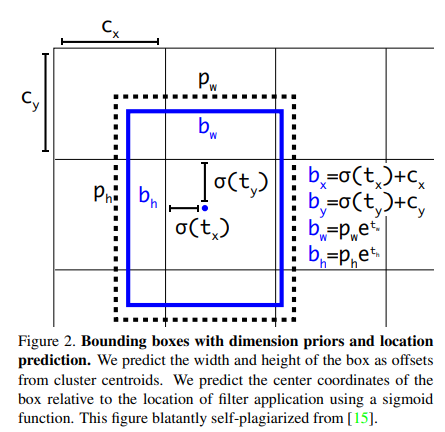
在yolov2和yolov3中都使用边界框回归的方案,预测 t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th四个与预测框位置和大小相关的参数,而在yolov4中沿用该方法,但采取一点优化:
原方法使用sigmoid函数限制 t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th这四个值在(0,1)之间。
由于 σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1+e^{-x}} σ(x)=1+e−x1

值域在 ( 0 , 1 ) (0,1) (0,1)之间,那么导致在基准点 ( c x , c y ) (c_x,c_y) (cx,cy)基础上,偏移量为 ( 0 , 1 ) (0,1) (0,1),那么预测框的中心点只能在grid cell格子内部。
此时,存在一种特殊情况,若真实框的中心点落在grid cell的边界线上,如 ( c x , c y ) (c_x,c_y) (cx,cy)位置,那么预测框的中心位置也在 ( c x , c y ) (c_x,c_y) (cx,cy)将会是最好的效果,到达此条件,就要求公式中 σ ( t x ) = 0 , σ ( t y ) = 0 \sigma(t_x)=0, \sigma(t_y)=0 σ(tx)=0,σ(ty)=0.但对于sigmoid函数而言,实现等于0的条件为x趋近于负无穷时,函数值为0。这种情况对于网络而言,难以实现。
为此,在yolov4中,引入缩放因子 s c a l e x y scale_{xy} scalexy,数学计算公式为
b x = ( σ ( t x ) ∗ s c a l e x y − s c a l e x y − 1 2 ) + c x b y = ( σ ( t y ) ∗ s c a l e x y − s c a l e x y − 1 2 ) + c y b_x=(\sigma(t_x) * scale_{xy}-\frac{scale_{xy}-1}{2})+c_x\\ b_y=(\sigma(t_y) * scale_{xy}-\frac{scale_{xy}-1}{2})+c_y bx=(σ(tx)∗scalexy−2scalexy−1)+cxby=(σ(ty)∗scalexy−2scalexy−1)+cy
在实际使用中, s c a l e x y scale_{xy} scalexy常取值为2,则原计算式为
b x = ( σ ( t x ) ∗ 2 − 0.5 ) + c x b y = ( σ ( t y ) ∗ 2 − 0.5 ) + c y b_x=(\sigma(t_x) * 2-0.5)+c_x\\ b_y=(\sigma(t_y) * 2-0.5)+c_y bx=(σ(tx)∗2−0.5)+cxby=(σ(ty)∗2−0.5)+cy
即在原 σ ( x ) \sigma{(x)} σ(x)乘以2,表达式为 σ ( x ) = 2 1 + e − x \sigma(x) = \frac{2}{1+e^{-x}} σ(x)=1+e−x2
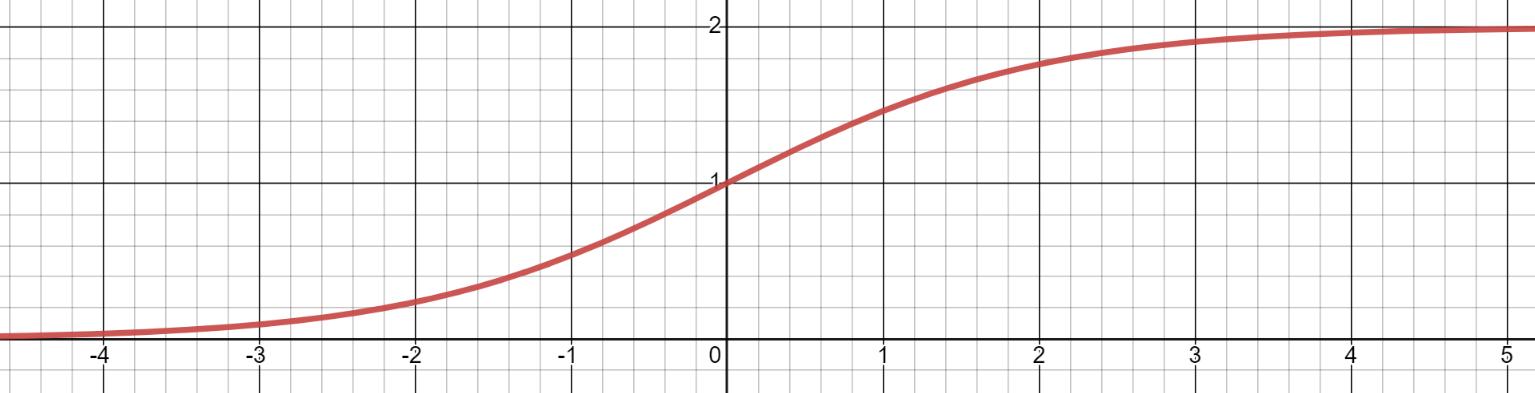
σ ( x ) = 2 1 + e − x − 2 \sigma(x) = \frac{2}{1+e^{-x}}-2 σ(x)=1+e−x2−2
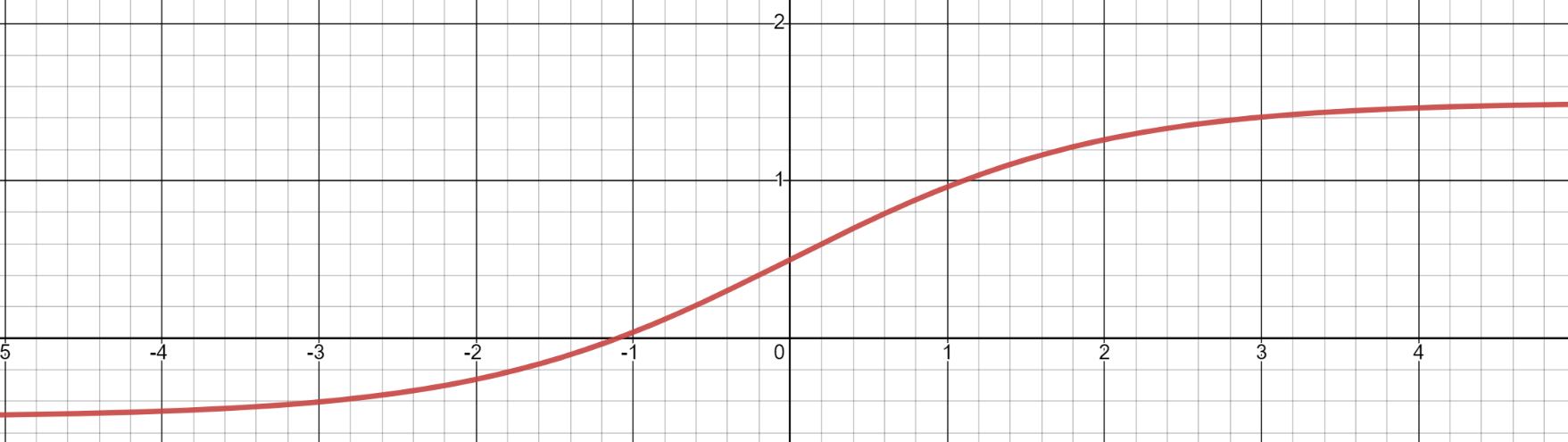
从上图可知值域变为 ( − 0.5 , 1.5 ) (-0.5,1.5) (−0.5,1.5)
那么最后得到的预测框的中心位置可以在偏离grid cell内部一定距离,如x坐标在 ( c x − 0.5 , c x + 1.5 ) (c_x -0.5,c_x+1.5) (cx−0.5,cx+1.5)之间,y坐标在 ( c y − 0.5 , c y + 1.5 ) (c_y -0.5,c_y+1.5) (cy−0.5,cy+1.5)之间,那么即使真实框的中心在边界线上也无关紧要了。
Mosaic 数据增强

mosaic是通过混合4张训练图像的数据增强方式,使模型具有更好的鲁棒性。
IOU阈值处理
对于每一个grid cell的anchor,若存在多个anchor与真实框的IOU值大于阈值,则令这几个anchor都进行预测,可以增加正样本数量。
具体实现方法为:

将每一个anchor与真实框左上角对齐,计算IOU值。
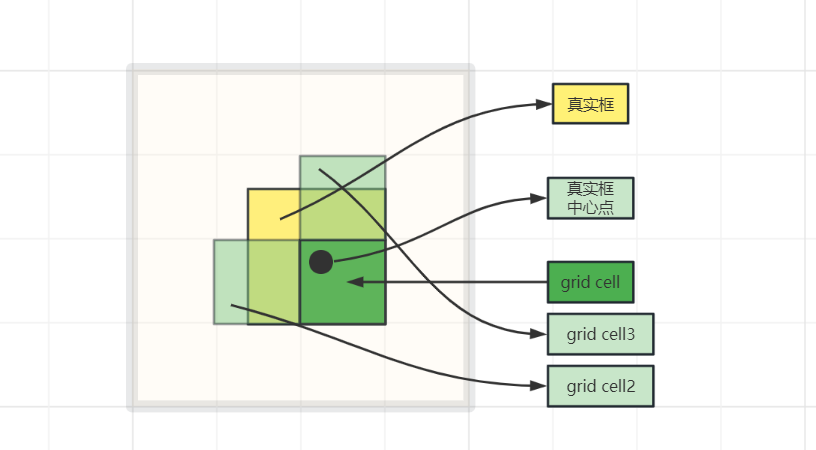
如上图,若对于某个真实框,中心点在深绿grid cell中,那么深绿grid cell生成的anchor中与真实框IOU最大(并且满足阈值)的anchor肯定是正样本,但不仅仅这一种正样本。对于深绿框左侧与上侧两个grid cell生成的anchor中,满足阈值的anchor也会作为该真实框的正样本,之所以这样做,可结合上面对边界框优化那一部分理解,由于偏移量在 ( − 0.5 , 1.5 ) (-0.5,1.5) (−0.5,1.5)之间,那么预测框的中心点位置是可能出现在左侧与上侧的。我们进行回归的目的在于使预测框与真实框更加接近,那么在优化之后,就有更多的预测框可以优化接近于真实框,使预测效果更好。