研究基于深度学习的特征提取,顺便记录一下阅读的文献,任务驱动,能更加高效。
会不时修改文章内容!
0 摘要
本文提出一种基于深度学习的网络GCNv2,用于关键点和描述子的生成。GCNv2是建立在我们之前的方法GCN上的。GCN是一个为3D射影几何进行训练的网络。GCNv2采用二进制描述子向量作为ORB特征,可以方便地在ORB- slam2等系统中替换ORB。与仅能在桌面硬件上运行的GCN相比,GCNv2显著提高了计算效率。展示了使用GCNv2功能的ORB-SLAM2的修改版本如何在嵌入式低功耗平台Jetson TX2上运行。实验结果表明,GCNv2保持了与GCN相当的精度,具有足够的鲁棒性,可用于控制飞行的无人机。源代码可在:https://github.com/jiexiong2016/GCNv2_SLAM
1 介绍
位置估计能力是大多数涉及移动机器人应用的关键。本文主要研究视觉里程计(VO),即基于视觉信息的相对运动估计问题。这是基于视觉的SLAM系统的基石,就像我们演示方法所使用的那样。与我们之前的工作一样,[1],我们仅使用RGB-D传感器来估计运动,我们的目标平台是在室内环境中操作的无人机。RGB-D传感器使尺度直接可观测,而不需要视觉惯性融合或使用神经网络推断深度的计算成本,如[2], [3], [4]。这增加了鲁棒性,这是无人机的一个关键属性。特别是室内环境,这里的误差很小,而且通常比户外的纹理更少。该方法适用于含有RGB-D传感器的系统,不需要复杂的标定和与其他传感器的同步。相反,聚变可以以更低的速率进行,对精确计时的需求也更少,例如,这使得与无人机的飞行控制系统的集成更简单。
研究基于深度学习的方法是SLAM的一个趋势。在[5]中提出了一种基于CNN的关键点检测和描述方法SuperPoint。实验结果表明,SuperPoint比SIFT等经典方法具有更强的特征描述子,SuperPoint的检测器与经典方法相当。在我们之前的工作[1]中,我们引入了几何对应网络,GCN,专门为产生相机运动估计的关键点而定制,实现了比经典方法更好的精度。然而,由于GCN及其多帧匹配设置的计算需求,难以在无人机等全操作SLAM系统中实现实时性能。关键点提取和匹配的计算量都很大。确实,在[6]中性能受限的环境中将深度学习集成到SLAM系统中被确定为的一个开放问题。
在本文中,我们基于[1]的结论引入了GCNv2,以提高计算效率,同时仍然保持GCN的高精度。我们纠正多帧设置问题,改为预测单个一次帧。我们的贡献是:
(1)GCNv2 保持与 GCN 相当的精度,与基于深度学习的相关特征提取方法相比在运动估计方向获得显著的进步,同时显著缩短推理时间。
(2)我们将特征向量的二值化包含在训练,大大加快了匹配速度。我们将 GCNv2 设计为具有与ORB 功能,可直接使用作为 SLAM 系统中的关键点提取器,如 ORB-SLAM2 [7] 或 SVO2 [8]。
(3)我们证明了我们的有效性和健壮性,通过在真实无人机上使用GCN-SLAM进行控制,并表明它可以处理ORB-SLAM2的失败情况。GCN-SLAM在嵌入式低功耗硬件(如Jetson TX2)上实时运行,而不是像 GCN,需要桌面 GPU 进行实时推理。
批注:贡献分三个部分:客观的性能提升;模块化设计,便于嵌入系统;系统验证。
2 相关工作
在本节中,我们将介绍两个方面的相关工作。首先介绍了VO和SLAM方法,然后特别关注基于深度学习的图像相关方法的工作。
A. VO和SLAM
在 VO 和 SLAM 的直接方法中,估计运动通过直接根据像素强度对齐帧,[9]是一个早期的例子。DVO(直接视觉里程计)在[10]中介绍,增加了一个姿势图以减少错误。DSO [11] 是一种直接和稀疏的方法,它添加所有模型参数的联合优化。另一种选择到帧到帧的匹配就是匹配每个新帧和KinectFusion [12], Kintinous [13] 和 ElasticFusion [14]中的体积表示。
在间接方法中,典型管道中的第一步是提取关键点,然后将其与前一个匹配帧来估计运动。匹配基于关键点描述符和几何约束。该类别中的最新技术仍然由ORB-SLAM2定义[15],[7]. ORB 描述符是一个允许高性能匹配的二进制向量。
我们发现介于直接和间接方法之间半直接方法。SVO2 [8] 是在此类别中的一种稀疏方法,并且可以以数百赫兹的速度运行。其中LSD-SLAM [16]是第一个半密集方法。RGBDTAM [17] 组合半稠密光度误差和稠密几何误差姿势估计。
最近有许多基于深度学习的映射系统像[18],[19]。这些方法的重点是基于深度学习的单视图深度估计,以减少单目系统固有的尺度漂移。CNN-SLAM [18]将深度输入 LSD-SLAM。在 DVSO [20] 中,深度为以类似于 [2] 的方式预测,使用虚拟立体视图。CodeSLAM [21] 学习可优化的表示来自用于 3D 重建的条件自动编码。在S2D [22],我们以 DSO [11] 为基础,并通过联合一个优化的CNN利用深度和常规预测。也存在一些工作运动估计的无监督训练。图像重建损失用于无监督学习在[4],[23]。但是,基于几何的优化方法性能仍然优于端到端系统,如 [20] 所示。
B. Deep Correspondence Matching
有大量近期作品部署于训练深度特征的度量学习变体,为查找图像对应关系 [24], [25], [26], [27], [28],[29],[30],[31],[5]。[32]、[33]中的工作重点是改进基于学习的检测,具有更好的不变性。针对不同的方面,[34],[35],[36]用自我监督的方式创造生成样本,以改善一般特征匹配。
在上述方法中,LIFT [30]特别使用基于补丁的方法执行两个关键点。检测和描述符提取。 SuperPoint[5] 预测用在单个网络的关键点和描述符使用[36]中的自我监督策略。值得注意的是,在[5]中表现[5]、[30]、[31] 与经典方法相当,如用于运动估计的 SIFT。
在GCN[1]中,我们通过学习关键点和专门针对运动估计的描述符,性能得到改善 – 与其他报告相反,是更通用的基于深度学习的关键点提取器系统[5],[31]。在本文中,我们介绍了一种高吞吐量GCN的变体,称为GCNv2。我们展示了这些关键点对SLAM的适用性,并以此ORB-SLAM2为基础,因为它提供了一个全面的多线程最先进的间接SLAM系统,支持单目以及RGB-D相机。ORB-SLAM2 补充了跟踪前端,和同时执行姿势图的后端。该后端使用 G2O [37] 进行优化,并使用一个二进制的词袋模型[38]。为了简化这一点,我们设计 GCNv2 描述符具有与 ORB 的格式相同。
3 GEOMETRIC CORRESPONDENCE NETWORK
在本节中,我们将介绍GCNv2的设计,旨在使GCN适用于在嵌入式硬件上运行的实时SLAM应用。我们首先介绍修订后的网络结构,然后详细说明用于二值化特征描述符和关键点检测器的训练方法。
A. Network Structure
[1] 中提出的原始 GCN 结构包括两个主要部分:带有 ResNet-50 骨干的 FCN [39] 结构和一个双向循环卷积网络。FCN 适用于密集特征提取,而双向循环网络用于查找关键点位置。[1] 表明,与现有方法相比,GCN 具有令人印象深刻的跟踪性能,然而还注意到,该算法有实际局限性在实时 SLAM 系统上。我们确定两个主要问题:一是网络架构比较大,因此需要强大的计算硬件使其无法在嵌入式板上实时运行,例如 Jetson TX2 用于我们的无人机实验;其次,GCN推理需要同时输入两个或多个帧时间,不仅增加计算,而且增加算法复杂性。
为了解决这些限制,我们引入了一个单一视图基于简化网络结构GCNv2,用于改进效率。GCNv2网络整体结构如图2所示。与GCN一样,GCNv2同时预测关键点和描述符,即该网络输出关键点置信度的概率图和描述符的密集特征图。受SuperPoint [5]的启发,GCNv2是以低分辨率执行预测,而不是原始图像,并且仅使用单个图像。首先,在低分辨率图预测概率图和稠密特征图,然后将256通道概率图 pixel shuffle 到原始分辨率,最后在全分辨率概率图上执行非极大值抑制,使用这些位置从低分辨率密集特征图中对相应的特征向量进行双倍采样(图 2 中的右侧部分)
图2
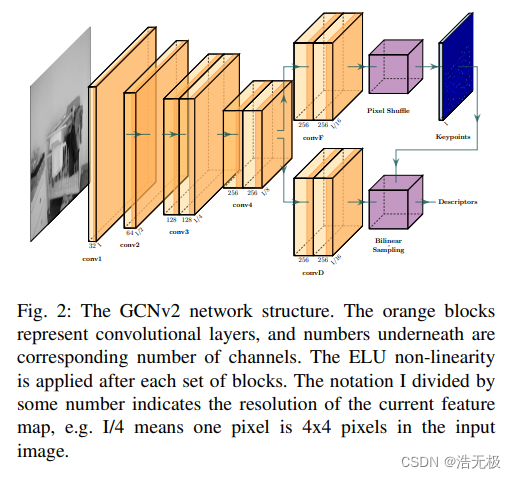
GCNv2 与我们采用的 SLAM 方法 GCN-SLAM 一起,在配备英特尔 i7-7700HQ 和移动版 NVIDIA 1070 的笔记本电脑上以大约 80 Hz 的频率运行。为了在 Jetson TX2 上实现实时推理所需的更高帧速率,我们推出了更小版本的 GCNv2,称为GCNv2-tiny,我们将特征映射的数量从conv2及以后减少一半。GCNv2-tiny 以 40 Hz 运行,使用它的 GCN-SLAM 在 TX2 上运行 20 Hz,因此非常适合部署在无人机上。除了移动平台,更全面的比较台式计算机上的推理和匹配时间如图3所示。可以看出,输入的分辨率以模糊二次的倍数影响推理时间。在相同分辨率下,GCNv2 与 GCN 和 SuperPoint 相比,可实现更短的推理时间。这主要是由于我们对网络架构的修改。有关GCNv2和GCNv2-tiny 网络细节的更多详细信息,请参见可在我们公开的源代码3。
图3
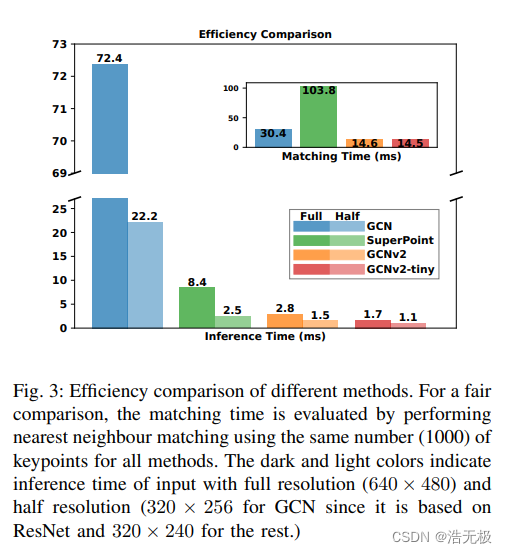
批注:inference time–推理时间
B. Feature Extractor
关键字:metric learning;triplet loss
Lfeat是描述子的损失函数:
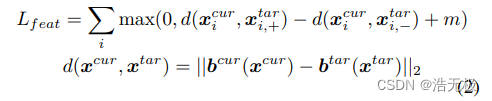
更新位置:
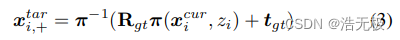
二值化特征:
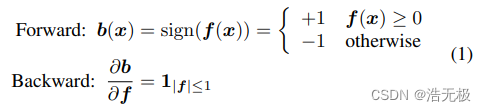
批注:要看懂这里可以看看GCNv1和上面提到的关键字资料
C. Distributed Keypoint Detector
和GCN一样,我们将特征检测作为一个二分类问题。网络中概率图的目标 o 是掩码 0和1。这些值指示一个像素是否是关键点。然后将加权交叉熵用作训练的目标函数(损失函数)。损失值始终在两个连续帧上评估,目的是增强提取的关键点的一致性。
特征点的损失函数:
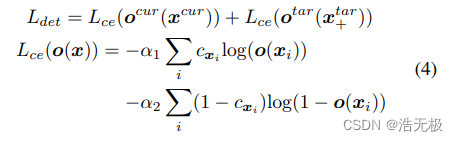
其中 α1 和 α2 用于处理不平衡类,以防止不是关键点的像素主导损失。我们通过检测 16 × 16 网格中的 Shi-Tomasi 角并使用方程 (3) 将它们 warp 到下一帧来生成ground truth。这样可以更好地分布关键点,目标函数直接反映了基于纹理跟踪关键点的能力。
D. Training Details
最终训练的loss由上诉两部分loss加权组合而成,Lfeat 权重100而 Ldet 权重为1。权重是为了平衡两项的规模。triplet loss中的m参数设为1。穷举负样本挖掘的宽松标准 c 设置为 8。(Relaxed criteria c for exhaustive negative sample mining is set to 8.)交叉熵 [a1, a2] 设置为 [0.1, 1.0]。使用Adam优化器,初始训练率 lr = 1e-4,每40epochs减半,总共100epochs。GCNv2的权重在均匀分布下随机初始化。
4 GCN-SLAM
对于一个基于关键点的SLAM系统,一个最重要的设计选择是关键点提取器。这些关键点会在各个阶段被重复使用。ORB-SLAM2中的ORB特征是一种健壮的特征,因为它比起其余相同性质的关键点提取器运算速度更快,并有一个为了快速匹配紧凑的描述子。
正如之前在 [1] 中所展示的,GCN使用一个很简单的姿态估计器就能比ORB-SLAM2表现更好,起码是平齐的。显见的,这是一个低阶的SLAM系统,没有位姿图优化,没有全局BA,没有回环检测。将GCN和这些功能做成一个完整的SLAM系统很可能会产生比这之前更好的结果。然而,GCN作为一个相当花销大的部件用在我们嵌入式硬件的实时系统中。在下面,我们将讲解如何将GCNv2加入到ORB-SLAM2中,并将这个系统取名为 GCN-SLAM。
ORB-SLAM2的动作估计是基于跟踪帧到帧的关键点和基于特征的BA问题。我们将会简短的描述特征的检测和描述。ORB-SLAM2使用一个尺度金字塔,通过在多个重新缩放的图片运行单尺度算法,它可以将输入图片迭代缩小实现多尺度特征检测。对于每个尺度等级,FAST角点检测器用于30*30的网格中。如果在一个单元内没有检测到目标,FAST再跑一遍,并衰减阈值。在所有检测器都从特定层级的尺度金字塔搜索一遍全部单元,使用空间划分算法首先按图像坐标剔除关键点,然后按检测分数剔除关键点。最终,通常一次提取1000个关键点,计算出每个关键点的视角。然后,用高斯模糊滤除每层尺度金字塔,并且在每层每个关键点256位的ORB描述子将被计算得出根据模糊图像。
我们的方法在网络的单个正向传递中同时计算关键点位置和描述符。如前所述,其最终结果旨在直接替代上述 ORB 特征提取器。这两种关键点提取方式如图4所示。
图4
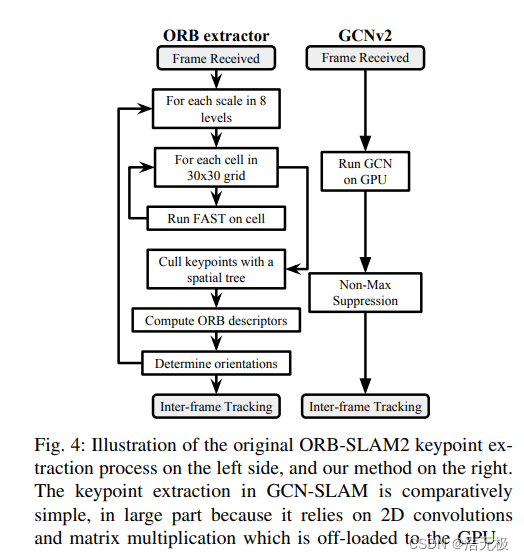
一旦找到关键点及其对应的描述符,ORB-SLAM2 主要依赖于两种帧到帧跟踪方法:首先,通过假设恒定速度和将前一帧的关键点投影到当前帧中。如果失败,通过使用词袋相似性将当前帧的关键点与上次创建的关键帧进行匹配。我们禁用了前者,以便仅使用后者基于关键点的参考系跟踪。我们还在实验中用标准的最近邻搜索替换了匹配算法。进行这些修改是为了检查我们的关键点提取方法的性能,而不是 ORB-SLAM2 的其他跟踪启发式方法的性能。
最后,我们保留了ORB-SLAM2的回环检测和姿态图优化,除了通过在V-A节中介绍的训练数据集上计算词袋词汇以适应GCNv2特征描述符之外。
5 实验结果
在本节中,我们介绍了实验结果,以证明我们关于关键点提取方法的性能及其在GCN-SLAM系统中的实施例的结论。我们的工作不是作为ORB-SLAM2的替代品,而是一种关键点提取方法,即:i)为运动估计量身定制,ii)计算效率高,以及iii)适合在SLAM系统中使用。第 V-B 部分通过GCN-SLAM 与 ORB-SLAM2 和一些相关方法进行基准测试来介绍我们的定量结果。第 V-C 节 将我们的方法与 ORB 特征定性地进行比较,通过在与 IV 节中所述的相同 SLAM 框架中使用它们。
对于定量实验,使用配备英特尔 i7-7700HQ 处理器和移动版 NVIDIA 1070 的笔记本电脑进行评估。对于定性实验和真实场景,我们使用 NVIDIA Jetson TX2 嵌入式计算机进行处理,并在定制无人机上使用英特尔实感 D435 RGB-D 摄像头传感器(见图 1)。
A. Training Data
原始GCN是使用来自传感器 fr2 的TUM数据集[44]训练的。它通过动作捕捉系统提供准确的相机姿势。在GCNv2中,我们使用在最近的工作[22]中创建的SUN-3D [45]数据集的一个子集来训练网络。SUN-3D包含数百万张在各种典型室内环境中真实世界记录的RGB-D图像。总共提取了 44624 帧,大约每秒一帧。SUN-3D是一个非常丰富的数据集,其多样性可能会产生一个更通用的网络。然而,所提供的 ground truth 姿势是通过带有闭环的视觉跟踪估计的,因此在全局意义上相对准确,但在帧级别存在错位。为了解决这种局部误差,我们提取SIFT特征,并使用提供的姿势作为BA问题的初始预测,以更新每个帧对的相对姿势。从这个意义上说,GCNv2的训练是使用来自RGB-D相机的自注释数据。
B. Quantitative Results
为了与原始GCN进行比较,我们选择了与[1]中相同的TUM数据集序列,并使用开环和闭环系统评估跟踪性能。我们使用绝对轨迹误差 (ATE) [44] 作为指标。由于我们在与原始GCN [1]不同的数据集上训练了GCNv2,因此我们还使用原始循环结构显示结果进行比较。因此,我们还创建了GCNv2-large,以ResNet-18为主干,并对特征图进行反卷积上采样。双向特征检测器与其他两个版本的GCNv2一样移至最低比例。
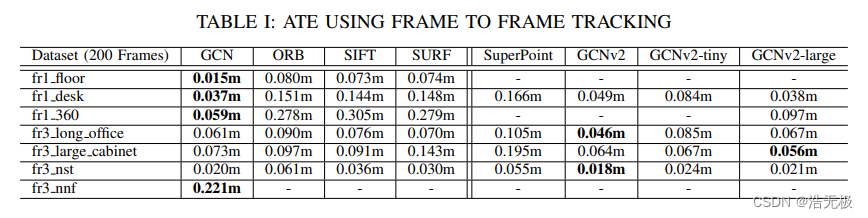
帧间跟踪结果见表一。双垂直线左侧的列来自 [1],其中使用了 640 × 480 张图像,双垂直线右侧的列的图像分辨率减半,即 320 × 240,因为这是我们在无人机上使用的分辨率。结果与[5]中报告的结果一致。SuperPoint的性能与SIFT等经典方法相当,而GCNv2的性能接近GCN,但明显优于SuperPoint。GCNv2的性能与GCN相当,在两种情况下甚至略好一些,可能是由于使用了更大的训练数据集,如第 V-A 节所述。例外情况(应该是指GCNv2比GCN更差的情况,破折号是失败情况)是 fr1_floor 和 fr1_360。这些序列需要精细的细节,并且由于GCNv2使用较低比例的特征图执行检测和描述符提取,因此性能会相应受到影响。GCNv2-large成功跟踪fr1 360的事实证明了这一点。最后,我们注意到GCNv2的较小版本GCNv2-tiny仅比GCNv2稍微低一点。(好像也不止一点了。。。)
表一
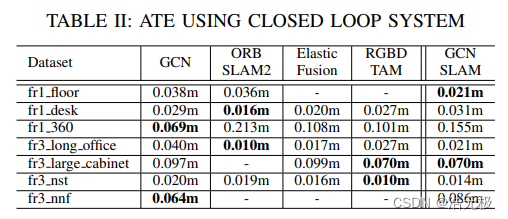
在表二中,我们将GCN-SLAM的闭环性能与我们之前的工作以及ORB-SLAM2,ElasticFusion和RGBD-TAM进行了比较。GCN-SLAM成功跟踪所有序列,其误差与GCN相当,而ORB-SLAM2在两个序列上失败。GCNv2在fr1_360的快速旋转中的误差小于ORB-SLAM2。同样值得注意的是,对于这个特定的序列,原始GCN的表现明显优于ORB-SLAM2和GCN-SLAM。ORB-SLAM2在所有其他序列中跟踪良好,GCN-SLAM和ORB-SLAM2的误差都很小。这些结果特别令人鼓舞,因为 GCN-SLAM 不使用 ORB-SLAM2 中存在的特定于 ORB 的功能匹配启发式方法,从而为进一步的性能留下了改进空间。
批注:这个里面的说法见仁见智了,但是真如论文所说的在这上面所有序列都成功了,那还是有可取之处的。
表二
C. Qualitative Results
为了进一步验证在实际SLAM设置中使用GCNv2的鲁棒性,我们展示了在不同条件下在我们的环境中收集的四个数据集的结果:a)走上走廊,转180度,带着手持相机走回去,b)在白天用手持传感器在室外停车场绕圈行走,c)在带窗户的壁龛中飞行并旋转 180 度,d)在厨房中飞行并在使用 GCN-SLAM 进行定位时旋转 360 度。
由于我们收集的数据集没有基本事实,因此这些结果只能定性解释(定性结果就是直观上的现象解释),并作为V-B节中提供的定量结果的补充。选择这些数据集是为了表明我们的方法可以处理困难的场景,是稳健的,并且可以用于无人机的实时定位。图5显示了使用ORB与GCNv2作为关键点的GCN-SLAM的估计轨迹。请注意,这两种方法都在完全相同的跟踪管道(pipeline这个词译为管道其实有点难以理解,实质就是一模一样的实验,就像不同的介质通过同一个管子一样)中进行评估,以便进行公平比较,即GCNv2或ORB特征是唯一的区别。有关确切的详细信息,请参阅源代码。在图 5a 中,ORB 特征为无法应对轨迹右上角的180度转弯。在图 5b 中,跟踪几乎立即失败。此外,图5c和5d表明,使用GCN-SLAM作为无人机控制的基础可以提高性能。具体来说,在图5c中,仅使用光流传感器估计位置,而在图5d中,GCN-SLAM用作定位源。很明显,无人机能够更好地保持其位置,并且后一条轨迹的噪音更少。在所有四个数据集中,跟踪使用 GCNv2 保持,但使用 ORB 丢失。我们使用遥控器将设定值发送到无人机上的飞行控制单元进行控制,使用内置的位置保持模式。
图5

在图 6 中,我们进一步比较了我们的关键点提取器与ORB 关键点提取器的性能。我们在跟踪我们的SLAM系统的局部地图期间绘制了内在数量,首先使用ORB关键点,然后使用GCNv2关键点。如图所示,虽然有更多的ORB特征,但我们的方法具有更高的内在百分比。此外,如图 1 所示,与 ORB 相比,GCNv2 具有更好的分布式特征。
图6
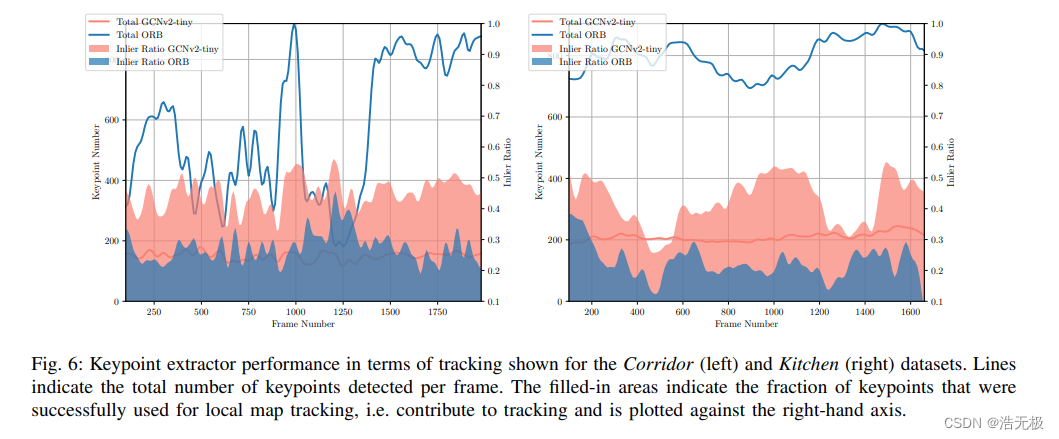
图1

6 结果
在我们之前的工作[1]中,我们发现GCN在视觉跟踪方面比现有的深度学习和经典方法具有更好的性能。然而,GCN由于其计算需求和使用多个图像帧,无法以有效的方式直接部署到实时SLAM系统中。在本文中,我们通过提出一个更小、更高效的GCN版本(称为GCNv2)来解决这些问题,该版本很容易适应现有的SLAM系统。我们证明了GCNv2可以有效地用于基于特征的现代SLAM系统中,以实现状态跟踪性能。通过将GCNv2整合到GCN-SLAM中并在我们的无人机上使用它进行定位,验证了该方法的鲁棒性和性能。
限制
GCNv2 被训练用于预测射影几何,而不是通用特征匹配。这是我们有意限制范围。与基于学习的方法一样,泛化是一个重要因素。GCNv2 在户外场景中效果相对较好,正如我们的实验(见图 5b)所示,即使训练数据集不包含户外数据,在该环境中的性能也可能得到提高。这里我们的目标是室内环境,我们没有进一步调查室外环境。
未来工作
在未来,我们有兴趣利用语义信息来拒绝使用更高层次信息的异常值,并将这些信息融合到运动估计中,以提高我们系统的能力,特别是在具有非静态对象的环境中。我们还想以自我监督或无监督的方式调查培训GCN,以使我们的系统能够在线自我改进,并随着时间的推移。
后话
终于完成了,花了两天多时间,但也是一种新的尝试。
可能对于很多看论文高手来说,我这篇博客并没有意义,也就是机翻+修正。但对我而言,把它做完就是意义。后面可能也会转型,阐述一些论文关键的信息就好了。
参考链接:
https://blog.csdn.net/NolanTHU/article/details/123815708
GCNv1
修改
2023.9.8 修改了一些排版问题
2023.9.10 增加了一些GCNv1相关知识的链接
2023.9.11 把第三章好好完善了一下