总结
将transformer机制融入到VO,获得更好的性能。是一种直接法和无监督学习的结合。主要机制是两个:TAPE 和 F2FPE。
TAPE
TAPE —— Transformer-based Auxiliary Pose Estimator
TAPE 是一种 transformer 式姿态估计器,用于对短时间内的几何和时间信息进行建模。
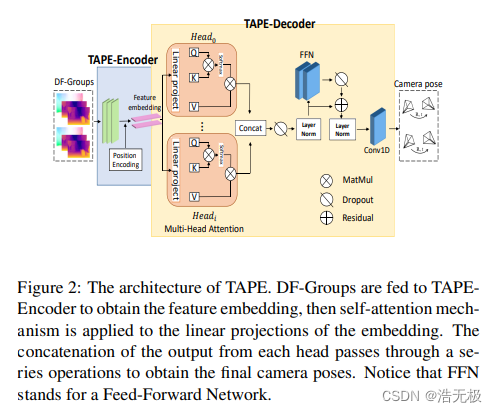
这个模块输入两组DF-Group(由光流图和深度图组成),每组由两张深度图和一张光流图组成,输入两个变换的位姿关系。相当于,将DF-Group一对一翻译成相机位姿。DF-Group经过卷积层,通过位置编码,获得 feature embedding。再经过多个注意力机制,dropout,残差链接,LN层等,最后获得结果。
F2FPE
Flow-to-Flow Pose Estimator (F2FPE)
几个关键词:Initial Flow Generator (IFG), Feature Encoder (FE), Pose Estimator (PE) and Final Flow Generator (FFG).
IFG用一个预训练的光流生成器产生初始光流图。初始光流图经过FE和FFG产生相机位姿,如图1号路线。初始光流图还走二号路线,得到一个改进的光流图,在这个方案里,FFG可以去除。
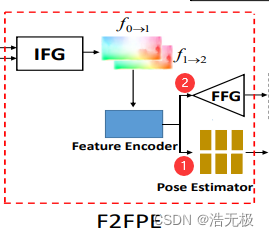
网络结构
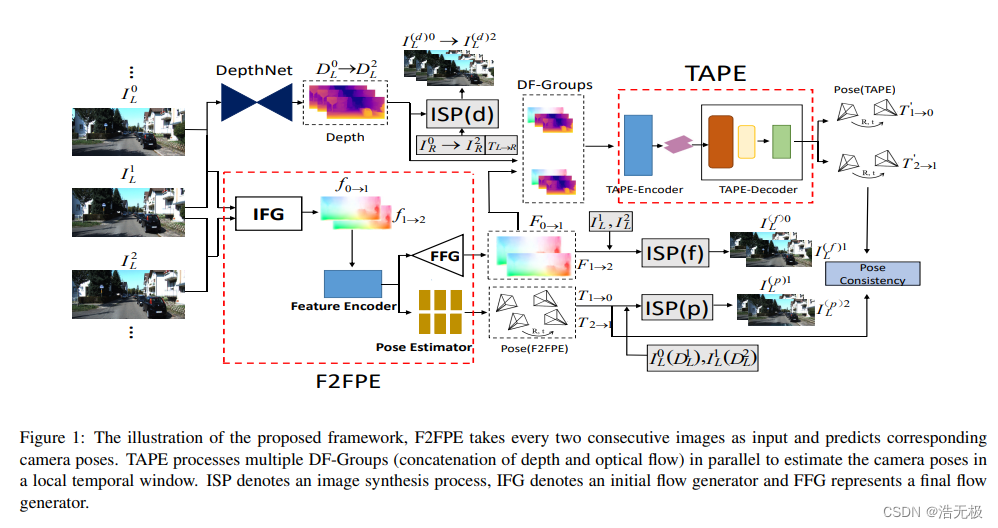
整个流程如下:
原始图片输入,往上经过深度网络提取深度图,往下经过F2FPE网络,生成光流图和相机位姿。由上面的深度图和下面的光流图组成DF-Group,输入TAPE,产生相机位姿。这两个相机位姿做姿势一致性评估。中间还有一些分支用ISP模块产生特定的图片,ISP–图片信息处理。