1 Wider Face标注格式转成YOLO格式
1.1 Wider Face标注介绍
The format of txt ground truth.
File name
Number of bounding box
x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
'''
0--Parade/0_Parade_marchingband_1_849.jpg
1
449 330 122 149 0 0 0 0 0 0
0--Parade/0_Parade_Parade_0_904.jpg
1
361 98 263 339 0 0 0 0 0 0
'''1.2 YOLO标注介绍
The format of txt ground truth.
class, cx, cy, w, h(坐标为归一化后的数值)
'''
0 0.04248046875 0.5455729166666666 0.0283203125 0.046875
0 0.2646484375 0.505859375 0.03125 0.05078125
0 0.33642578125 0.50390625 0.0185546875 0.028645833333333332
'''1.3 数据格式转换
1.3.1 Wider Face格式转成VOC格式
首先创建文件夹1_face2voc,在该文件夹下创建Annotations、JPEGImages、Labels文件夹
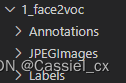
格式转换代码需要运行两次(将路径中的train换成val即可),分别生成对应的train和val文件,转换代码如下:
# coding:utf-8
import cv2
from xml.dom.minidom import Document
def writexml(filename, saveimg, bboxes, xmlpath):
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
folder = doc.createElement('folder')
folder_name = doc.createTextNode('widerface')
folder.appendChild(folder_name)
annotation.appendChild(folder)
filenamenode = doc.createElement('filename')
filename_name = doc.createTextNode(filename)
filenamenode.appendChild(filename_name)
annotation.appendChild(filenamenode)
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
database.appendChild(doc.createTextNode('wider face Database'))
source.appendChild(database)
annotation_s = doc.createElement('annotation')
annotation_s.appendChild(doc.createTextNode('PASCAL VOC2007'))
source.appendChild(annotation_s)
image = doc.createElement('image')
image.appendChild(doc.createTextNode('flickr'))
source.appendChild(image)
flickrid = doc.createElement('flickrid')
flickrid.appendChild(doc.createTextNode('-1'))
source.appendChild(flickrid)
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid_o = doc.createElement('flickrid')
flickrid_o.appendChild(doc.createTextNode('muke'))
owner.appendChild(flickrid_o)
name_o = doc.createElement('name')
name_o.appendChild(doc.createTextNode('muke'))
owner.appendChild(name_o)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(saveimg.shape[1])))
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(saveimg.shape[0])))
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(saveimg.shape[2])))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode('0'))
annotation.appendChild(segmented)
for i in range(len(bboxes)):
bbox = bboxes[i]
objects = doc.createElement('object')
annotation.appendChild(objects)
object_name = doc.createElement('name')
object_name.appendChild(doc.createTextNode('face'))
objects.appendChild(object_name)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode('Unspecified'))
objects.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode('0'))
objects.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode('0'))
objects.appendChild(difficult)
bndbox = doc.createElement('bndbox')
objects.appendChild(bndbox)
xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(str(bbox[0])))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(str(bbox[1])))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(str(bbox[0] + bbox[2])))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(str(bbox[1] + bbox[3])))
bndbox.appendChild(ymax)
f = open(xmlpath, "w")
f.write(doc.toprettyxml(indent=''))
f.close()
rootdir = "/kaxier01/projects/FAS/yolov7/wider_face/1_face2voc" # 根目录
gtfile = "/kaxier01/projects/FAS/yolov7/wider_face/wider_face_split/wider_face_val_bbx_gt.txt" # Wider Face原始标注
im_folder = "/kaxier01/projects/FAS/yolov7/wider_face/WIDER_val/images"
fwrite = open("/kaxier01/projects/FAS/yolov7/wider_face/1_face2voc/Labels/val.txt", "w")
with open(gtfile, "r") as gt:
while(True):
gt_con = gt.readline()[:-1]
if gt_con is None or gt_con == "":
break
im_path = im_folder + "/" + gt_con
print(im_path)
im_data = cv2.imread(im_path)
if im_data is None:
continue
numbox = int(gt.readline())
# 获取每一行人脸数据
bboxes = []
if numbox == 0: # numbox 为0 的情况处理
gt.readline()
else:
for i in range(numbox):
line = gt.readline()
infos = line.split(" ") # 用空格分割
bbox = (int(infos[0]), int(infos[1]), int(infos[2]), int(infos[3]))
bboxes.append(bbox) # 将一张图片的所有人脸数据加入bboxes
filename = gt_con.replace("/", "_") # 将存储位置作为图片名称,斜杠转为下划线
fwrite.write(filename.split(".")[0] + "\n")
cv2.imwrite("{}/JPEGImages/{}".format(rootdir, filename), im_data)
xmlpath = "{}/Annotations/{}.xml".format(rootdir, filename.split(".")[0]) # xml文件保存路径
writexml(filename, im_data, bboxes, xmlpath)
fwrite.close()1.3.2 VOC格式转成COCO格式
首先创建2_voc2coco文件夹,在该文件夹下创建wider_coco文件夹,在wider_coco文件夹下创建images和xml_annotations文件夹
格式转换:1)利用1.3.1步骤中生成的xml文件(生成的train和val的xml文件合并放在一个文件夹内,路径为'1_face2voc/Annotations')以及'1_face2voc/Labels'下的train.txt和val.txt,将图片和xml文件分为训练集和验证集,
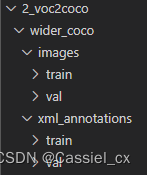
代码如下:
# coding:utf-8
import os
import shutil
from tqdm import tqdm
SPLIT_PATH = "/kaxier01/projects/FAS/yolov7/wider_face/1_face2voc/Labels"
IMGS_PATH = "/kaxier01/projects/FAS/yolov7/wider_face/1_face2voc/JPEGImages"
TXTS_PATH = "/kaxier01/projects/FAS/yolov7/wider_face/1_face2voc/Annotations"
TO_IMGS_PATH = '/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/wider_coco/images'
TO_TXTS_PATH = '/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/wider_coco/xml_annotations'
data_split = ['train.txt', 'val.txt']
to_split = ['train', 'val']
train_file = '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/images_train.txt'
val_file = '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/images_val.txt'
train_file_txt = ''
val_file_txt = ''
for index, split in enumerate(data_split):
split_path = os.path.join(SPLIT_PATH, split)
to_imgs_path = os.path.join(TO_IMGS_PATH, to_split[index])
if not os.path.exists(to_imgs_path):
os.makedirs(to_imgs_path)
to_txts_path = os.path.join(TO_TXTS_PATH, to_split[index])
if not os.path.exists(to_txts_path):
os.makedirs(to_txts_path)
f = open(split_path, 'r')
count = 1
for line in tqdm(f.readlines(), desc="{} is copying".format(to_split[index])):
# 复制图片
src_img_path = os.path.join(IMGS_PATH, line.strip() + '.jpg')
dst_img_path = os.path.join(to_imgs_path, line.strip() + '.jpg')
if os.path.exists(src_img_path):
shutil.copyfile(src_img_path, dst_img_path)
else:
print("error file: {}".format(src_img_path))
if to_split[index] == 'train':
train_file_txt = train_file_txt + dst_img_path + '\n'
elif to_split[index] == 'val':
val_file_txt = val_file_txt + dst_img_path + '\n'
# 复制txt标注文件
src_txt_path = os.path.join(TXTS_PATH, line.strip() + '.xml')
dst_txt_path = os.path.join(to_txts_path, line.strip() + '.xml')
if os.path.exists(src_txt_path):
shutil.copyfile(src_txt_path, dst_txt_path)
else:
print("error file: {}".format(src_txt_path))
with open(train_file, 'w') as out_train:
out_train.write(train_file_txt)
with open(val_file, 'w') as out_val:
out_val.write(val_file_txt)2)将VOC标注格式转换成COCO格式,生成的json文件用于评估模型性能,代码如下:
import sys
import os
import json
import xml.etree.ElementTree as ET
import glob
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = {"face" : 0}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
# print(filename,filename[6:])
filename = filename.replace("\\", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
if filename[:5] == "India" : return int("2"+filename[6:])
elif filename[:5] == "Japan" : return int("3"+filename[6:])
else : return int("1"+filename[6:])
#return int(filename[6:])
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
acceptable_classes = ["car","truck","bus"]
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
image_id = filename[:-4]
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": filename[:-4],
}
json_dict["images"].append(image)
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
continue
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict, indent=4)
json_fp.write(json_str)
json_fp.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
xml_path = '/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/wider_coco/xml_annotations/val' # 这是xml文件所在的地址
json_file = '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/annotations/val.json' # 这是你要生成的json文件
xml_files = glob.glob(os.path.join(xml_path, "*.xml"))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
print("Number of xml files: {}".format(len(xml_files)))
convert(xml_files, json_file)
print("Success: {}".format(json_file))1.3.3 VOC格式转成YOLO格式
首先创建3_voc2yolo文件夹,在该文件夹下创建images和labels文件夹
1)提取由1.3.2步骤划分好的xml文件的文件名('2_voc2coco/wider_coco/xml_annotations/val/***.xml')并将文件名保存在'2_voc2coco/name_val.txt or name_train.txt ',代码需要执行两次,代码如下:
import os
file_path = "/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/wider_coco/xml_annotations/val/"
path_list = os.listdir(file_path) # os.listdir(file)会历遍文件夹内的文件并返回一个列表
path_name = [] # 把文件列表写入save.txt中
def saveList(pathName):
for file_name in pathName:
with open("/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/name_val.txt", "a") as f:
f.write(file_name.split(".")[0] + "\n")
def dirList(path_list):
for i in range(0, len(path_list)):
path = os.path.join(file_path, path_list[i])
if os.path.isdir(path):
saveList(os.listdir(path))
dirList(path_list)
saveList(path_list)2)将xml格式转成YOLO格式,代码需要执行两次,代码如下:
import xml.etree.ElementTree as ET
import os
classes = ['face']
train_file = '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/wider_val.txt'
train_file_txt = ''
wd = os.getcwd()
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
box = list(box)
box[1] = min(box[1], size[0]) # 限制目标的范围在图片尺寸内
box[3] = min(box[3], size[1])
x = ((box[0] + box[1]) / 2.0) * dw
y = ((box[2] + box[3]) / 2.0) * dh
w = (box[1] - box[0]) * dw
h = (box[3] - box[2]) * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/wider_coco/xml_annotations/val/%s.xml' % (image_id)) # 读取xml文件路径
out_file = open('/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/labels/val/%s.txt' % (image_id), 'w') # 需要保存的txt格式文件路径
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
image_ids_train = open('/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/name_val.txt').read().strip().split() # 读取xml文件名索引
for image_id in image_ids_train:
convert_annotation(image_id)
anns = os.listdir('/kaxier01/projects/FAS/yolov7/wider_face/2_voc2coco/wider_coco/xml_annotations/val/')
for ann in anns:
ans = ''
outpath = '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/labels/val/' + ann
if ann[-3:] != 'xml':
continue
train_file_txt = train_file_txt + '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/images/val/' + ann[:-3] + 'jpg\n'
with open(train_file, 'w') as outfile:
outfile.write(train_file_txt)至此,便把Wider Face标注格式转换成了YOLO格式,对应的图片和标签分别保存在'wider_face/3_voc2yolo/images/'和'wider_face/3_voc2yolo/labels/',
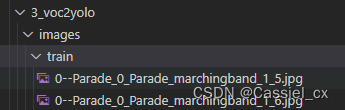
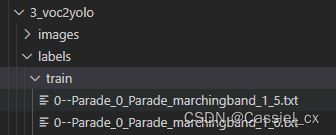
转换后的标注如下:
2 使用Wider Face数据集训练YOLOV7
模仿coco.yaml生成wider_face.yaml文件,文件内如如下:
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
# 以下两个txt文件由步骤1.3.2生成
train: /kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/wider_train.txt # 12876 images
val: /kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/wider_val.txt # 3226 images
# number of classes
nc: 1
# class names
names: [ 'face' ]配置文件'cfg/training/yolov7.yaml'中的anchors大小不需要修改,如果anchors不合适,算法会重新聚类anchors
修改YOLOV7工程中的test.py脚本中的anno_json(Line 257):
anno_json = '/kaxier01/projects/FAS/yolov7/wider_face/3_voc2yolo/annotations/val.json' # 该文件由1.3.2中格式转换的步骤2生成测试结果
目前模型训练到了46epoch(总共300epoch),性能如下:

可视化结果如下:


标注格式转换参考: