本文共计1310字,预计阅读时间5分钟
目录
查找
假设我们现在有一组已经排序好的数组,见下方。而当前任务是找出数组中是否存在某个元素。

我们需要在这个数组中找出值为 57 的元素。
方法1:线性查找
正如其名,在线性查找方式下你需要从列表中从头到尾遍历一遍,并比较每一个项中的值是否是你正在寻找的。当你查找到匹配的值时,遍历便会结束。
查找数值57

当搜索到一个大于你目前正在查找的值时,这趟搜索便可以结束了(因为后面的值都只会比你要查找的值大)。
比如,查找数值35

这是一个好方法吗?
这个解决方案是可行的。但如果你稍加注意一点,你会发现它并没有充分利用好数组有序性的特性。在最糟糕的情况下,这个算法的时间复杂度将是O(N)——当所要查找的元素不再数组中,那么我们将要把欲查找的值与数组中每一个元素作比较。
是否可以把方法设计的更好些?
当然可以,尝试用二分查找
方式2:二分查找
二分查找这个概念很简单。想一想你平时是如何在一本英文词典中查找单词的。比如你想在字典中查找一个“quirky”的单词,你没必要从字典中从第一页翻到最后一页,一个一个地去找这个单词,因为字典中已经把每个单词按照字母表顺序进行了排序。你可以快速地略过在字母q前以及字母q后的那些页码。
回到我们的示例,让我们首先在看下这个数组中间的值 48 ,如果这个值与我们的目标值匹配,那么我们就可以直接结束这趟搜索。

但如果我们并不是查找值 48 呢?那么我们将要用中间这个位置的值与我们的目标值作比较。如果我们的目标值比这小,那么我们就需要查找比这个更小的值,即以48为起点往左边搜索而不再考虑右边的值。
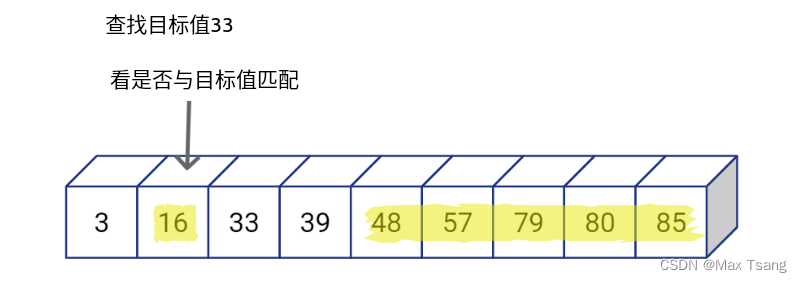
查找数值33


通过二分查找,我们可以缩短搜索序列,并把欲比较的数值减少至一半。此外,我们还可以不断重复这样的过程,即通过不断选取“中间值”与目标值进行比较,判断是否匹配结果,若不匹配,则再继续判断是向左搜索还是向右搜索,这样便可以把欲搜索的序列不断缩小,减少查询次数。


现在的时间复杂度如何呢?
算法的时间复杂度由比较次数决定。如果你了解这个算法,那么应该知道这个算法的时间复杂度为,具体的推导公式可以参考 big O - 什么因素会影响到时间复杂度?
这个算法充分利用了数组有序性的特点。当大量数值被顺序存储在数组中时,这个算法能够充分利用好性能。
那么这是一个完美的解决方法吗?
很显然,这种方法在查找的情况下确实很省力。但如果我们要进行插入或者删除元素时,顺序数组并不适合这类情形。
比如:
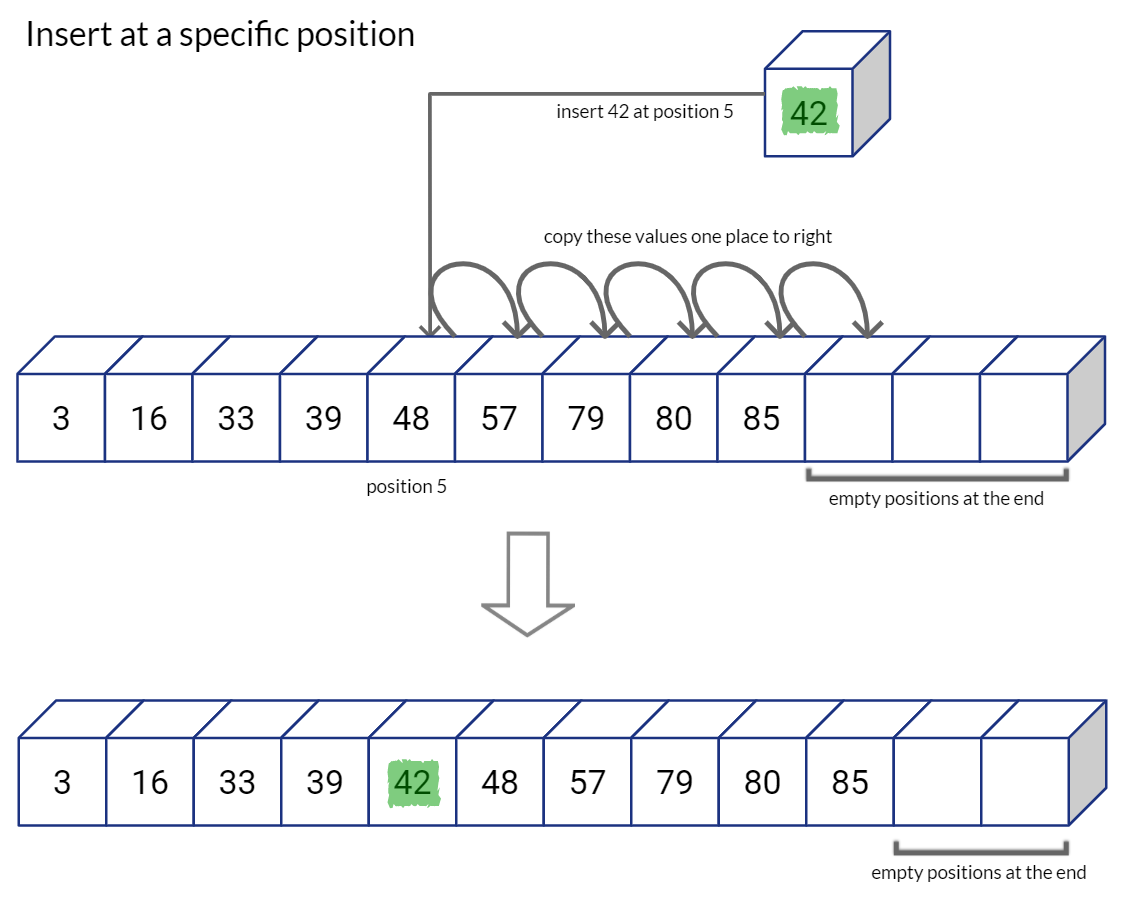
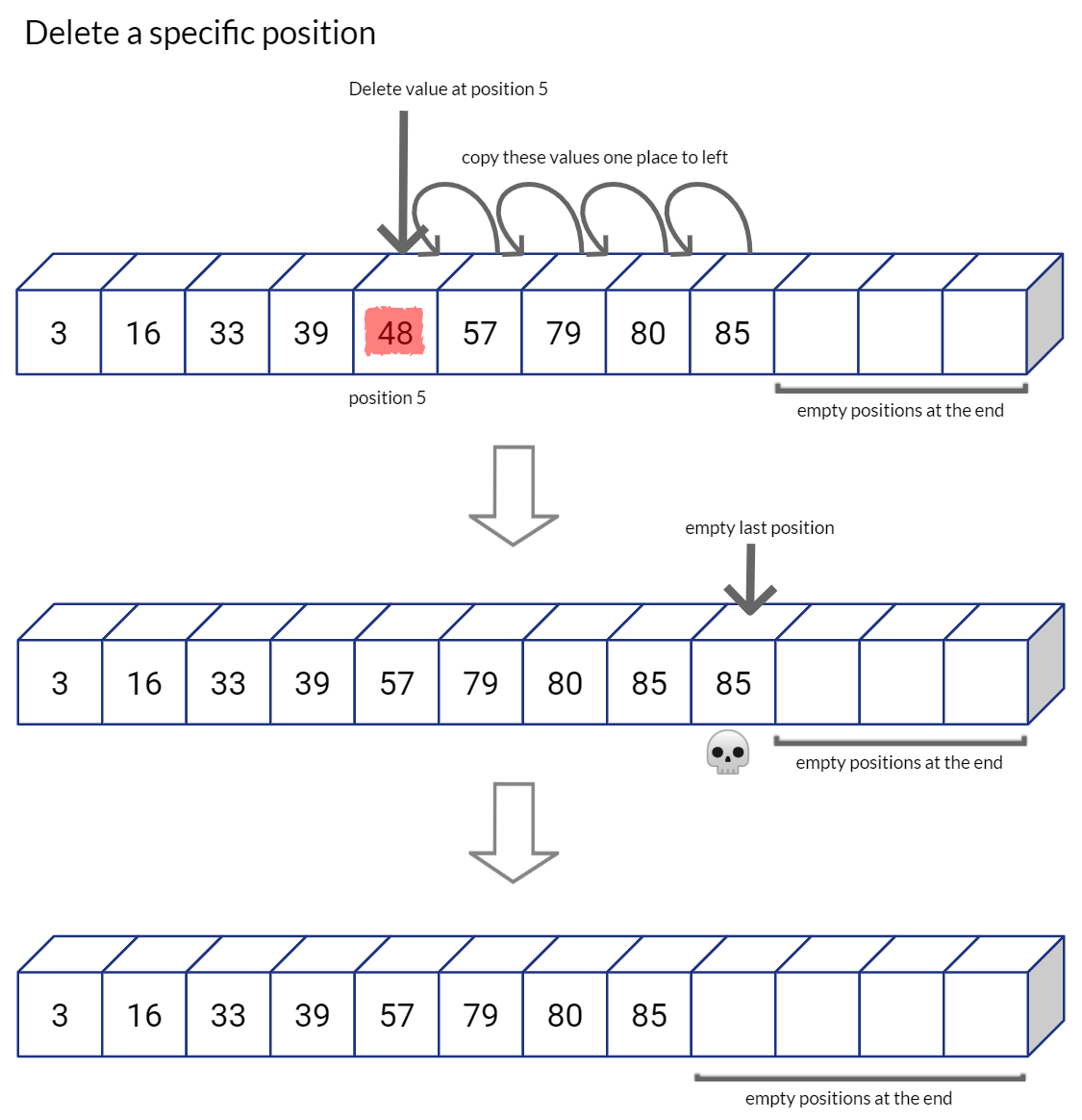
正如你想的一样,如果数组的右侧有额外的空间,那么插入删除操作将会很方便;否则,在每次插入时都必须调用动态内存分配,并将整个数组复制到新分配的数组中。Python中的List数据结构,以类似的方式分配List,在序列的末尾留下容量以供将来扩展。如果我们用完了List中的空间,Python会分配一个更大的新List,将旧List中的每个值复制到新List中,然后删除旧List。(这就是为什么Python列表中的插入是时间复杂度O(1)的原因)
有没有更好的方法去构造一个在插入和删除中性能更好的数据结构呢?
当然有,那就是链表!
翻译中……