目录
题型一(栈与队列的基本概念)
1、栈和队列都是()。
A、顺序存储的线性结构
B、链式存储的非线性结构
C、限制存取点的线性结构
D、限制存取点的非线性结构
解析:(C)
栈是一种只允许在一端进行插入或删除操作的线性表,它是一种特殊的线性表,它与队列具有相同的逻辑结构,都属于线性结构,区别在于对其中元素的处理不同,栈遵循的原则是先进后出(FILO),即后进的元素先被取出来,它是被限制存取点的线性结构。
队列与栈一样,也是一种特殊的线性表,其操作受限,它与栈具有相同的逻辑结构,都属于线性结构,区别在于其中元素的处理不同,队列只允许在一端进行插入,且只允许在另一端进行删除,队列遵循的原则是先进先出(FIFO),即先入队列的元素最先离开,它也是被限制存取点的线性结构,与日常生活中的排队是一样的。
2、栈和队列的共同点是()。
A、都是先进先出
B、都是先进后出
C、只允许在端点处插入和删除元素
D、没有共同点
解析:(C)
栈和队列的共同点是都只允许在一端进行插入或删除操作的特殊线性表,主要区别在于插入、删除操作的限定不一样。
题型二(栈与队列的综合)
1、设栈S和队列Q的初始状态为空,元素a,b,c,d,e,f依次通过栈S,一个元素出栈后即进队列Q,若6个元素出队的序列是a,c,f,e,d,b,则栈S的容量至少应该是()。
A、3
B、4
C、5
D、6
解析:(B)
栈是先进后出,队列是先进先出。
若容量为3,若要满足条件,首先元素a通过栈S后,然后进入队列Q,
得到出队为{a};b、c通过栈S后,c首先出栈通过队列,得到出队为
{a、c};此时若要第三个出队元素为f,则栈中由下至上应该为{b、d、e、f},所以栈S的容量至少应该是4。
题型三(共享栈)
1、采用共享栈的好处是()。
A、减少存取时间,降低发生上溢的可能
B、节省存储空间,降低发生上溢的可能
C、减少存取时间,降低发生下溢的可能
D、节省存储空间,降低发生下溢的可能
解析:(B)
使用共享栈可以更加有效地利用存储空间,降低发生上溢的可能,通过让两个顺序栈共享一个一维数组空间,将这两个顺序栈的栈底分别设置在数组空间的两端,其中两个栈的栈顶指针都指向栈顶元素,如下图:
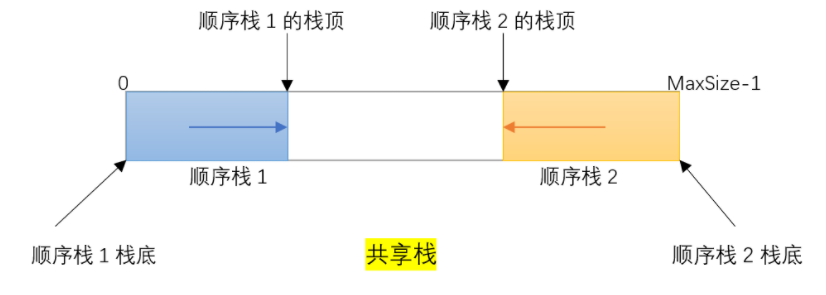
其中,当top1=-1时顺序栈1为空,当top2=MaxSize时顺序栈2为空,另外当两个栈顶指针相邻,即top2-top1=1时,此时共享栈满。
题型四(循环队列的判空与判满)
1、假设循环队列的最大容量为m,队头指针是front,队尾指针是rear,则队列为满的条件是()。
A、(rear+1)%m == front
B、rear == front
C、rear+1 == front
D、(rear-1)%m == front
解析:(A)
设MaxSize为循环队列的最大容量,(Q.rear+1)%MaxSize == Q.front即队尾指针进1与MaxSize取余的值等于头指针时,此时队列已满,如下:
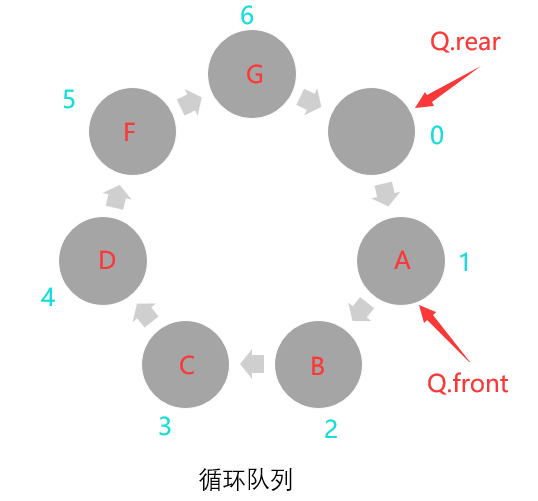
当前队头指针Q.front=1,Q.rear=0,即(Q.rear+1)%MaxSize=(0+1)%7=1%7=1,等于Q.front=1,所以此时队列为满队,此时队头指针在队尾指针的下一个位置。
题型五(循环链表表示队列)
1、用循环单链表来表示队列,设队列的长度为n,若只设尾指针,则出队和入队的时间复杂度分别为()。
A、O(1),O(1)
B、O(1),O(n)
C、O(n),O(1)
D、O(n),O(n)
解析:(A)
循环单链表表示队列相当于一个环,由于只设尾指针,出队时直接出队,出队的时间复杂度为O(1);因为队头队尾相连,尾指针的下一个结点即是队头,则入队的时间复杂度也为O(1)。
2、用循环单链表来表示队列,设队列的长度为n,若只设头指针,则出队和入队的时间复杂度分别为()。
A、O(1),O(1)
B、O(n),O(n)
C、O(1),O(n)
D、O(n),O(1)
解析:(D)
循环单链表表示队列相当于一个环,由于只设头指针,出队时指针需要从队头到队尾,经过n个结点到达队尾,所以出队的时间复杂度为O(n);入队时由于有头指针,可直接入队,出队的时间复杂度为O(1)。
题型六(循环队列的存储)
1、已知存储循环队列的数组长度为21,若当前队列的头指针和尾指针的值分别为9和3,则该队列的当前长度为()。
A、6
B、12
C、15
D、18
解析:(C)
通过队尾指针减队头指针加上MaxSize的值与MaxSize取余,可得到数据元素个数,即(Q.rear-Q.front+MaxSize)%MaxSize,代码如下:
//循环队列的数据元素个数
bool NumQueue(SqQueue Q){
if(Q.front==Q.rear) //若队列为空,则报错
return false;
int num=(Q.rear-Q.front+MaxSize)%MaxSize;
printf("当前循环队列的数据元素个数为:%d\n",num);
}
题中,Q.front=9,Q.rear=3,MaxSize=21,所以(Q.rear-Q.front+MaxSize)%MaxSize=(3-9+21)%21=15%21=15。
题型七(循环队列的入队和出队)
1、循环队列存储在数组A[0,…,m]中,用front和rear分别表示队头和队尾,则入队时的操作为()。
A、rear=rear+1
B、rear=(rear+1) mod (m-1)
C、rear=(rear+1) mod m
D、rear=(rear+1) mod (m+1)
解析:(D)
入队操作针对Q.rear,入队的代码通过取余运算实现,队尾指针加1,即Q.rear=(Q.rear+1)%MaxSize,不管前面(Q.rear+1)为多少,它与MaxSize(例如,MaxSize=5)取余的结果只可能是0、1、2、3、4,也就是队尾指针Q.rear的每次移动加1。
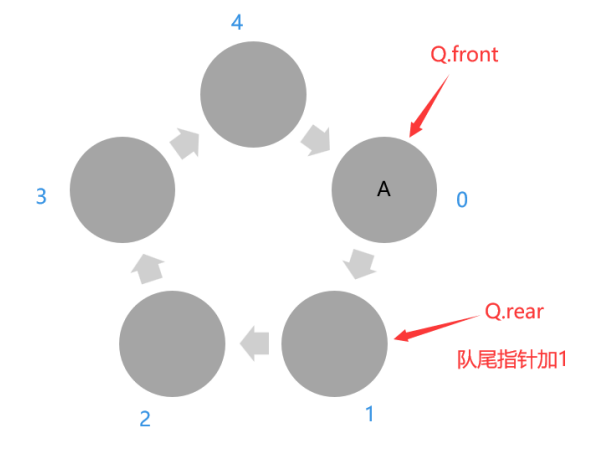
所以题中,入队时的操作为rear=(rear+1) mod (m+1)。
2、循环队列存储在数组A[0,…,m]中,用front和rear分别表示队头和队尾,则出队时的操作为()。
A、front=front+1
B、front=(front+1) mod (m-1)
C、front=(front+1) mod m
D、front=(front+1) mod (m+1)
解析:(D)
出队的代码依然是通过取余运算实现,队头指针加1,即Q.front=(Q.front+1)%MaxSize,我们知道不管前面(Q.front+1)为多少,它与MaxSize(例如,MaxSize=5)取余的结果只可能是0、1、2、3、4,也就是队头指针Q.front的每次移动加1。
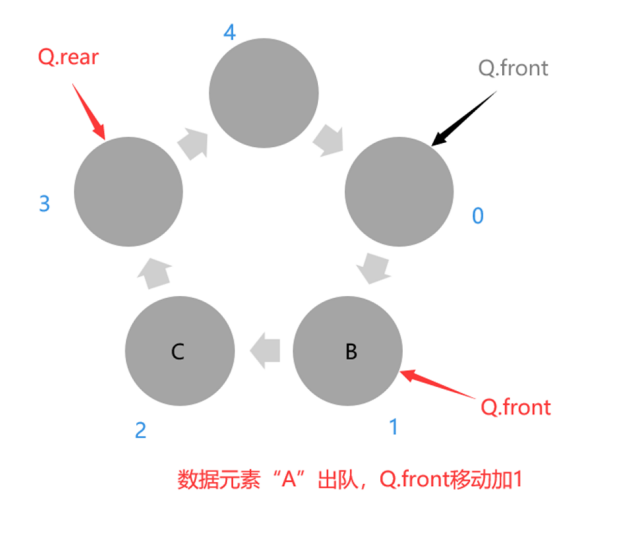
所以题中,出队时的操作为front=(front+1) mod (m+1)。
3、若用一个大小为6的数组来实现循环队列,且当前rear和front的值分别是0和3。当从队列中加入一个元素,删除两个元素,再加入三个元素后,再删除一个元素,此时rear和front的值分别是()。
A、1和3
B、0和4
C、4和0
D、3和1
解析:(C)
初始rear和front的值分别是0和3,加入一个元素,针对的是rear指针,所以rear=1;删除两个元素,针对的是front指针,所以front=1;再加入三个元素,针对的是rear指针,所以rear=4;再删除一个元素,针对的是front指针,所以front=0。故rear=4,front=0。
题型八(链式存储结构表示循环队列)
1、用链式存储结构的队列进行插入、删除操作时需要()。
A、仅修改头指针
B、仅修改尾指针
C、头尾指针都要修改
D、头尾指针可能都要修改
解析:(D)
当链式队列插入一个元素时,若队列不为空时,只需要修改尾指针;而当队列为空时,头、尾指针都要修改。
当链式队列删除一个元素时,若队列不为空时,只需要从表头删除,即修改头指针;而若队列中只有一个元素时,尾指针也需修改,即rear=front。
题型九(栈和队列的应用)
1、执行函数时,其局部变量一般采用()进行存储。
A、树形结构
B、静态链表
C、栈结构
D、队列结构
解析:(C)
2、(多选)栈的应用包括以下()。
A、括号匹配
B、表达式求值
C、页面替换算法
D、递归
E、进制转换
F、缓存机制
解析:( A、B、D、E、F)
除了页面替换算法是队列的应用,其他都是栈的应用。
3、为解决计算机主机与打印机之间速度不匹配问题,通常设置一个打印数据缓冲区, 主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是()。
A、栈
B、队列
C、树
D、图
解析:(B)
由于主机将要输出的数据依次写入该缓冲区,需要保证先后顺序,同时为了输出的数据也是有先后的,所以应该采用先进先出的特性,即队列。