目录
PS:纯粹为学习分享经验,不参与商用价值运作,若有侵权请及时联系!!!
一、 TensorRT分析
模型推理性能分析:使用工具如TensorRT Profiler、PyTorch Profiler、TensorFlow Profiler等,可以对模型的推理性能进行详细分析,包括推理时间、内存占用、吞吐量等指标。这些工具可以帮助确定模型中的瓶颈,进而优化模型和系统配置。
PyTorch Profiler:
-
PyTorch Profiler是PyTorch框架提供的一种性能分析工具,用于评估和优化PyTorch模型的性能。
-
它提供了对模型执行的详细性能分析,包括前向传播、反向传播、数据加载、内存使用等方面的信息。
PyTorch Profiler还提供了一些功能,如Tensor分析、GPU利用率、内存分配情况等,以帮助理解模型在训练和推理过程中的性能状况。
import torch
from torch.profiler import profile, record_function, ProfilerActivity
# 定义PyTorch模型和示例输入
model = ...
input_data = ...
# 使用PyTorch Profiler进行性能分析
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof:
with record_function("推理"):
# 执行推理过程
output = model(input_data)
print(prof.key_averages().table(sort_by="self_cpu_time_total")) 在上述代码中,我们使用了PyTorch Profiler进行性能分析。通过将代码块包装在profile上下文管理器中,我们可以记录性能数据。activities参数指定了需要记录的活动类型,例如CPU和CUDA。通过使用record_function上下文管理器,我们可以在性能分析结果中标记关键的代码块。最后,通过调用prof.key_averages().table()函数打印Profiler记录的性能数据表格。
TensorRT Profiler:
#include <iostream>
#include <NvInfer.h>
#include <NvInferProfiler.h>
int main()
{
// 创建TensorRT的Profiler对象
nvinfer1::Profiler profiler;
// 创建TensorRT的Builder对象和NetworkDefinition对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
nvinfer1::INetworkDefinition* network = builder->createNetwork();
// 设置Profiler对象到Builder中
builder->setProfiler(&profiler);
// 构建TensorRT的Engine
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// 创建TensorRT的执行上下文
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
// 进行推理,性能数据会被Profiler记录
context->enqueue(...); // 填充输入数据并执行推理
// 打印Profiler记录的性能数据
profiler.print(std::cout);
// 释放资源
context->destroy();
engine->destroy();
network->destroy();
builder->destroy();
return 0;
}打印TRT优化后的网络结构与精度
当使用Python的TensorRT API时,可以使用tensorrt.IBuilder和tensorrt.INetworkDefinition对象获取优化后的网络结构信息,并使用Python脚本进行精度评估。
import tensorrt as trt
# Step 1: 创建Logger对象
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# Step 2: 创建Builder对象和Network对象
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network:
# Step 3: 使用ONNX解析器解析模型
with trt.OnnxParser(network, TRT_LOGGER) as parser:
model_path = "resnet18.onnx"
with open(model_path, "rb") as model:
parser.parse(model.read())
# Step 4: 配置推理引擎
builder.max_workspace_size = 1 << 30 # 设置最大工作空间大小为1GB
engine = builder.build_cuda_engine(network)
# Step 5: 打印网络结构信息
print("TensorRT optimized network:")
print(network.num_layers, " layers in the network.")
# Step 6: 精度评估
# 进行推理并与原始模型的推理结果进行比较
# ...
print("TensorRT engine created successfully!") 在TensorRT中,可以通过nvinfer1::ICudaEngine对象获取优化后的网络结构信息,也可以通过比较优化前后的推理结果来评估模型精度。
#include <iostream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
int main() {
// Step 1: 创建Logger对象
nvinfer1::ILogger* logger = new nvinfer1::ILogger(nvinfer1::ILogger::Severity::kWARNING);
// Step 2: 创建Builder对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(*logger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// Step 3: 使用ONNX解析器解析模型
nvinfer1::IOnnxParser* parser = nvinfer1::createParser(*network, *logger);
const char* model_path = "resnet18.onnx";
parser->parseFromFile(model_path, static_cast<int>(nvinfer1::ILogger::Severity::kWARNING));
// Step 4: 配置推理引擎
builder->setMaxWorkspaceSize(1 << 30); // 设置最大工作空间大小为1GB
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// Step 5: 打印网络结构信息
std::cout << "TensorRT optimized network:" << std::endl;
std::cout << network->getNbLayers() << " layers in the network." << std::endl;
// Step 6: 释放资源
network->destroy();
parser->destroy();
builder->destroy();
std::cout << "TensorRT engine created successfully!" << std::endl;
return 0;
}
过network->getNbLayers()获取优化后的网络层数,并打印网络结构信息。
至于评估精度,通常需要使用推理数据进行推理,并与原始模型的推理结果进行比较。请注意,由于TensorRT对网络进行优化,优化后的精度可能与原始模型存在细微差异。在某些情况下,为了提高精度,可能需要对优化后的模型进行进一步的训练(Fine-tuning)。
二、 Nsys和NSight分析模型性能
NSys和NSight是NVIDIA提供的用于分析GPU应用性能和调试的工具。它们可以帮助深入了解深度学习模型的性能瓶颈和优化潜力。以下是对NSys和NSight的简要介绍:
-
NSys:
-
NSys是一款命令行性能分析工具,用于分析GPU应用程序的性能和资源利用情况。
-
它可以提供有关GPU的各种指标,如计算性能、内存使用、带宽利用率等的信息。
-
NSys还支持多种分析模式,包括时间线(Timeline)视图、统计视图等,以帮助深入分析和理解应用程序的性能状况。
-
-
NSight:
-
NSight是一套面向GPU开发的集成开发环境(IDE),包括NSight Systems和NSight Compute等组件。
-
NSight Systems用于分析和优化GPU应用程序的整体性能,提供了时间线视图、调用栈跟踪、资源使用等功能。
-
NSight Compute用于分析和优化CUDA应用程序的性能,提供了指令级的分析、内核分析、资源利用率等功能。
-
NSight还提供了GPU调试的功能,包括断点调试、变量查看、内存访问跟踪等。
-
要使用NSight Systems和NSight Compute工具,需要确保已正确安装和配置NVIDIA驱动和NSight软件包,并在支持CUDA的NVIDIA GPU上运行代码。在进行性能分析时,建议将数据量和迭代次数设置得足够小,以便快速获取结果并进行调优。
参考链接:(262条消息) NVIDIA Nsight Systems 入门及使用_AliceWanderAI的博客-CSDN博客
三、 加载QAT模型并分析TRT底层优化
QAT(Quantization-Aware Training)技术是一种用于深度学习模型量化的训练方法。它的目的是在模型训练过程中考虑量化对模型性能的影响,使得模型在量化后仍能保持较好的精度。
传统的模型量化是在训练完成后进行的,将训练好的浮点模型转换为低精度(如INT8或INT4)的模型。但由于量化会引入量化误差,这种方法可能会导致精度的下降。
QAT技术通过在训练过程中引入量化误差,以及使用模拟量化计算方法,使得模型能够适应低精度的推理环境。具体来说,QAT技术主要包括以下步骤:
-
量化感知的损失函数:在模型训练过程中,引入与量化相关的损失函数,以考虑量化误差对模型精度的影响。这样,模型在训练过程中会逐渐适应低精度的特性。
-
模拟量化计算:在前向传播过程中,将激活值和权重值模拟量化为指定的低精度。这样,模型在训练过程中可以获取量化后的特性,并减少由于量化带来的精度损失。
-
动态量化:在训练过程中,可以使用动态量化的方法,动态调整量化的参数,如量化范围或缩放因子,以更好地适应数据的变化。
QAT技术的优势在于,它可以在训练过程中优化模型的量化效果,减少量化后的精度损失,从而在推理时能够获得更高的性能和较小的模型尺寸。由于QAT技术考虑了量化过程中的误差,因此可以在训练时将量化的特性嵌入到模型中,而不是简单地将训练好的浮点模型转换为量化模型。
要加载一个QAT(量化感知训练)模型并分析TensorRT的底层优化,需要进行以下步骤:
-
创建TensorRT引擎并加载QAT模型:使用TensorRT的C++或Python API,根据QAT模型创建一个TensorRT引擎。
-
运行QAT模型:使用TensorRT引擎对QAT模型进行推理,可以通过输入模拟数据进行推理。
-
分析TensorRT优化:使用NSight Systems和NSight Compute等工具,对TensorRT推理进行系统级和内核级性能分析,以查看TensorRT的底层优化效果。
实现代码:
在PyTorch中使用QAT技术,可以使用PyTorch的torch.quantization.quantize_dynamic函数来实现。
import torch
import torchvision
import torch.quantization
# Step 1: 加载训练数据和模型
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
model = torchvision.models.resnet18(pretrained=True)
model.eval() # 将模型设置为评估模式
# Step 2: 量化感知训练
qat_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
# Step 3: 训练模型
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(qat_model.parameters(), lr=0.001, momentum=0.9)
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
# 使用量化感知训练的模型进行前向传播
outputs = qat_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}")
# Step 4: 导出量化感知训练后的模型
torch.save(qat_model.state_dict(), "qat_model.pth")
C++实现代码:
#include <iostream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
int main() {
// Step 1: 创建Logger对象
nvinfer1::ILogger* logger = new nvinfer1::ILogger(nvinfer1::ILogger::Severity::kWARNING);
// Step 2: 创建Builder对象和Network对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(*logger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// Step 3: 使用ONNX解析器解析QAT模型
nvinfer1::IOnnxParser* parser = nvinfer1::createParser(*network, *logger);
const char* model_path = "qat_model.onnx";
parser->parseFromFile(model_path, static_cast<int>(nvinfer1::ILogger::Severity::kWARNING));
// Step 4: 配置推理引擎
builder->setMaxWorkspaceSize(1 << 30); // 设置最大工作空间大小为1GB
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// Step 5: 分析TensorRT优化
// 使用NSight Compute等工具对TensorRT推理进行性能分析
// ...
// Step 6: 释放资源
network->destroy();
parser->destroy();
builder->destroy();
std::cout << "TensorRT engine created successfully!" << std::endl;
return 0;
}
四、 使用polygraphy分析模型
Polygraphy是一个用于深度学习模型推理和优化的开源工具。它提供了丰富的功能,包括模型转换、推理性能分析、模型可视化、模型比较和推理准确性评估等。
pip install polygraphy我们假设已经有了一个模型文件(如ONNX或TensorRT引擎文件),并希望使用Polygraphy来分析模型的推理性能。
-
推理性能分析:
使用
polygraphy run命令可以对模型进行推理性能分析。以下是一个简单的示例,演示如何使用Polygraphy对TensorRT引擎进行推理性能分析:polygraphy run trt_engine.engine --bench上述命令会对名为
trt_engine.engine的TensorRT引擎文件进行推理性能分析,并输出推理性能的统计信息。 -
更多功能:
Polygraphy还提供了许多其他功能,例如模型转换、推理准确性评估、模型比较和可视化等。可以使用不同的子命令来执行这些功能。例如:
- 使用
polygraphy convert命令可以执行模型转换。 - 使用
polygraphy accuracy命令可以评估模型推理的准确性。 - 使用
polygraphy compare命令可以比较不同模型或推理引擎之间的性能和准确性。 - 使用
polygraphy visualize命令可以可视化模型。 - 可以通过
polygraphy --help命令查看所有可用的子命令和选项,以及具体的使用方法。
请注意,Polygraphy是一个功能强大且灵活的工具,可以根据需求进行多种配置和调整。对于更复杂的用例,可以参考Polygraphy的官方文档以获取更详细的信息和示例。
参考链接:(262条消息) Polygraphy 安装教程_科技那些事儿的博客-CSDN博客
polygraphy 是一个深度学习模型调试工具,包含 python API 和 命令行工具,它的功能如下:
-
使用多种后端运行推理计算,包括 TensorRT, onnxruntime, TensorFlow;
-
比较不同后端的逐层计算结果;
-
由模型生成 TensorRT 引擎并序列化为.plan;
-
查看模型网络的逐层信息;
-
修改 Onnx 模型,如提取子图,计算图化简;
-
分析 Onnx 转 TensorRT 失败原因,将原计算图中可以 / 不可以转 TensorRT 的子图分割保存;
-
隔离 TensorRT 终端 错误 tactic;
使用示例:
polygraphy run yawn_224.onnx --onnxrt --trt --workspace 256M --save-engine yawn-test.plan --fp16 --verbose --trt-min-shapes 'data:[1,3,224,224]' --trt-opt-shapes 'data:[3,3,224,224]' --trt-max-shapes 'data:[8,3,224,224]' > test.txt
# 命令解析
polygraphy run yawn_224.onnx # 使用onnx模型
--onnxrt --trt # 使用 onnxruntime 和 trt 后端进行推理
--workspace 256M # 使用256M空间用于生成.plan 文件
--save-engine yawn-test.plan # 保存文件
--fp16 # 开启fp16模式
--verbose # 显示生成细节
--trt-min-shapes 'data:[1,3,224,224]' # 设定 最小输入形状
--trt-opt-shapes 'data:[3,3,224,224]' # 设定 最佳输入形状
--trt-max-shapes 'data:[8,3,224,224]' # 设定 最大输入形状
> test.txt # 将终端显示重定向test.txt 文件中
复制代码result: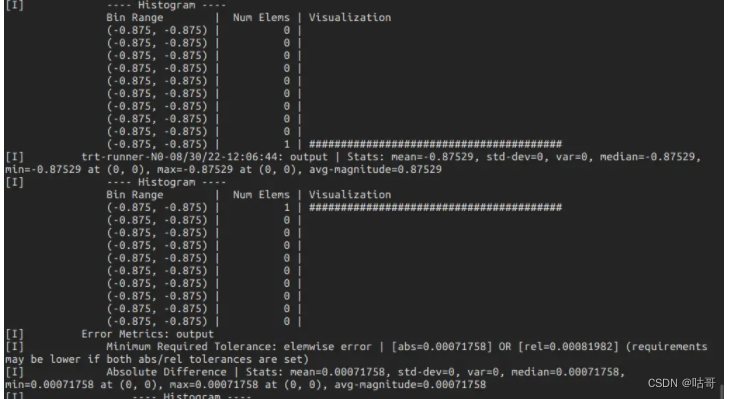
五、 实战操作:使用TensorRT对模型进行优化
对VGG设置不同的量化策略
可以使用PyTorch的量化 API 和 torch.quantization 模块。PyTorch提供了不同的量化策略和配置选项。
示例代码:
import torch
import torchvision
import torch.quantization
# Step 1: 加载VGG模型
model = torchvision.models.vgg16(pretrained=True)
model.eval() # 将模型设置为评估模式
# Step 2: 定义量化配置
# 可以设置不同层的量化配置,例如设置量化位数、量化范围等
quant_config = torch.quantization.default_qconfig
quant_config_dict = {
torch.nn.Conv2d: torch.quantization.default_qconfig,
torch.nn.Linear: torch.quantization.default_qconfig
}
# Step 3: 量化感知训练
qat_model = torch.quantization.quantize_dynamic(model, quant_config_dict, dtype=torch.qint8)
# Step 4: 导出量化感知训练后的模型
torch.save(qat_model.state_dict(), "qat_vgg_model.pth")
5.2.2 构建一个self-attention模块及不同版本TRT对attention进行优化
代码:
import torch
import torch.nn as nn
import tensorrt as trt
import numpy as np
# Step 1: 构建Self-Attention模块
class SelfAttention(nn.Module):
def __init__(self, in_channels, key_channels, value_channels):
super(SelfAttention, self).__init__()
self.key_channels = key_channels
self.value_channels = value_channels
self.query = nn.Conv2d(in_channels, key_channels, kernel_size=1)
self.key = nn.Conv2d(in_channels, key_channels, kernel_size=1)
self.value = nn.Conv2d(in_channels, value_channels, kernel_size=1)
def forward(self, x):
query = self.query(x)
key = self.key(x)
value = self.value(x)
attention_map = torch.matmul(query.view(query.size(0), self.key_channels, -1).permute(0, 2, 1),
key.view(key.size(0), self.key_channels, -1))
attention_map = nn.functional.softmax(attention_map, dim=-1)
out = torch.matmul(attention_map, value.view(value.size(0), self.value_channels, -1))
out = out.view(x.size(0), self.value_channels, *x.size()[2:])
return out
# Step 2: 创建示例输入并导出模型为ONNX格式
model = SelfAttention(in_channels=64, key_channels=32, value_channels=32)
x = torch.randn(1, 64, 32, 32)
onnx_file = "self_attention.onnx"
torch.onnx.export(model, x, onnx_file, opset_version=11)
# Step 3: 使用TensorRT优化模型
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
with open(onnx_file, "rb") as model:
parser.parse(model.read())
builder.max_workspace_size = 1 << 30
engine = builder.build_cuda_engine(network)
# Step 4: 保存优化后的模型
trt_file = "self_attention.trt"
with open(trt_file, "wb") as f:
f.write(engine.serialize())
print("TensorRT engine created successfully and saved as:", trt_file)
总结:
经过整个篇幅学习,相信大家已经掌握了tensorrt的整套开发流程。可以针对性地对模型采取不同的优化方案进行改进,若需要更深入地拓展知识请留言,相互交流,十分感谢!!!!
PS:纯粹为学习分享经验,不参与商用价值运作,若有侵权请及时联系!!!
下篇内容预告:
-
深度学习模型部署OpenVINO加速