篇章十:TensorRT部署分析与优化方案
目录
2.3 CUDA Core vs TensorRT Core

4.2 常见的 channel pruning 与 Filter pruning
PS:纯粹为学习分享经验,不参与商用价值运作,若有侵权请及时联系!!!
深度学习模型部署TensorRT加速(十一):TensorRT部署分析与优化方案(二)
前言:
模型推理性能分析:使用工具如TensorRT Profiler、PyTorch Profiler、TensorFlow Profiler等,可以对模型的推理性能进行详细分析,包括推理时间、内存占用、吞吐量等指标。这些工具可以帮助确定模型中的瓶颈,进而优化模型和系统配置。
一、模型部署指标分析
1.1 FLOPS与TOPS
经典的模型性能分析有算力 TOPS(Trillions of Operations Per Second)和 FLOPS(Floating-point Operations Per Second)两种不同的计算性能指标。
1)FLOPS是指每秒钟浮点数运算的次数,它通常用于衡量计算机的通用浮点数计算性能。例如,如果一个处理器能够执行10亿次浮点数运算,则它的浮点运算速度为1 GFLOPS。在深度学习领域,FLOPS也被用来衡量神经网络模型的计算复杂度。
2)算力 TOPS则是指每秒钟执行的整数和/或定点数运算次数,它主要用于衡量处理器的特定功能的性能,如人工智能领域的卷积计算等。通常,深度学习处理器的算力 TOPS 比普通处理器的 FLOPS 高得多。
在选择处理器时,需要根据具体应用来选择算力 TOPS 或 FLOPS 作为评估指标。如果需要进行通用浮点数计算,则 FLOPS 更适合,如果需要进行特定类型的计算,如神经网络卷积运算,则算力 TOPS 更为重要。
1.2 Roofline model与计算密度
任何模型模型和计算硬件之间的匹配程度会决定模型的实际表现。
Roofline Model
主要提出了计算强度Operational Intensity 概念,能够计算出模型在计算平台上的理论性能上限。
参考链接:Roofline Model与深度学习模型的性能分析 - 知乎 (zhihu.com)[推荐]
·定义:模型在一个计算平台的限制下,能达到最快的浮点计算速度
·形态:由计算平台的算力和带宽上限这两个参数所决定的“屋顶”形态。
-
算力决定“屋顶”的高度(绿色线段)
-
带宽决定“房檐”的斜率(红色线段)
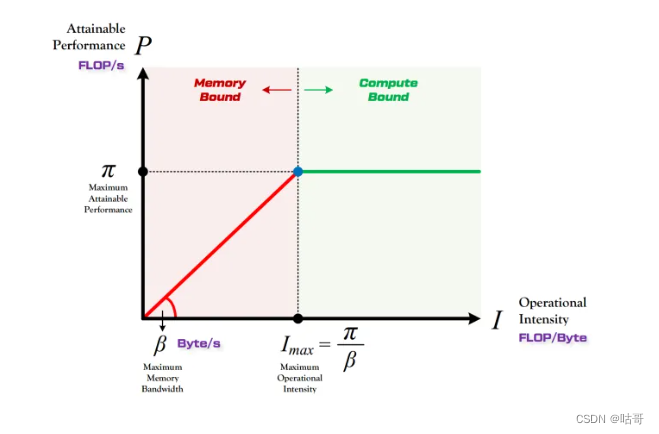 通过计算性能分析可以判断哪些模型适合在对应的平台上进行运行部署,如Vgg-16和MobileNet,可以在1080Ti 等计算平台上分析对比它们的计算性能。结合对应任务选择。尤其是针对于检测率差别不大的情况下,对计算性能的择优也是个很重要的切入点。
通过计算性能分析可以判断哪些模型适合在对应的平台上进行运行部署,如Vgg-16和MobileNet,可以在1080Ti 等计算平台上分析对比它们的计算性能。结合对应任务选择。尤其是针对于检测率差别不大的情况下,对计算性能的择优也是个很重要的切入点。
1.3 FP32/FP16/INT8/INT4/FP8参数
· 参数介绍
-
FP32(单精度浮点数):
-
FP32使用32位浮点数表示,提供了最高的精度和数值范围。
-
它是深度学习模型训练和推理中最常用的数据类型之一。
-
FP32模型具有最高的精度,但在存储和计算资源方面要求较高。
-
-
FP16(半精度浮点数):
-
FP16使用16位浮点数表示,提供了较高的计算性能和较低的存储需求。
-
FP16适用于深度学习模型的推理阶段,可以在一定程度上加速推理过程。
-
由于精度降低,FP16可能会导致模型的性能损失,特别是对于具有复杂特征和小梯度的任务。
-
-
INT8(8位整数):
-
INT8使用8位整数表示,提供了较低的存储需求和计算复杂度。
-
INT8适用于深度学习模型的推理阶段,并在一定程度上减少了计算资源的需求。
-
由于精度更低,INT8模型通常需要进行量化训练和量化推理,可能会导致一定的精度损失。
-
-
INT4(4位整数):
-
INT4使用4位整数表示,提供了更低的存储需求和计算复杂度。
-
INT4通常用于具有高度优化的硬件加速器,例如NVIDIA Tensor Cores等。
-
INT4模型需要进行量化训练和量化推理,并进一步减少了模型的精度。
-
-
FP8(8位浮点数):
-
FP8使用8位浮点数表示,提供了介于FP16和INT8之间的存储需求和计算复杂度。
-
FP8通常在一些专用硬件上使用,以平衡计算性能和模型精度。
-
FP8模型需要特定的硬件和软件支持,以进行FP8数据类型的计算和推理。
-
在深度学习部署中,选择适当的数据类型取决于需求和硬件平台的支持。高精度的数据类型(如FP32)提供了最高的精度,但需要更多的计算和存储资源。较低精度的数据类型(如INT8)可以在一定程度上提高推理性能,但可能会导致精度损失。因此,需要权衡精度、性能和资源需求,选择适合应用场景的数据类型。
其中低精度技术 (high speed reduced precision)是TensorRT部署的一个优势。在training阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。但是在inference阶段,精度要求相对不高或影响不大的情形下,一般F16(半精度)就可以,甚至可以用INT8(8位整型),精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在嵌入式模型里面。
参考:[TensorRT模型转换及部署,FP32/FP16/INT8精度区分tensorrt半精度BourneA的博客-CSDN博客]
英伟达显卡对精度的支持情况:
-
FP16 (Pascal P100 and V100 (tensor core))
-
INT8 (P4/P40)

二、模型部署的几大误区
2.1 FLOPS并不能衡量模型性能
FLOPS通常被用作衡量计算设备(如CPU、GPU)或深度学习模型的计算能力或性能的指标。FLOPS的值越高,意味着设备或模型具有更高的计算能力。
然而,虽然FLOPS可以作为一个参考指标,但它并不能完全衡量模型的性能或实际推理速度。实际评估模型性能时,应综合考虑计算、内存访问、数据传输、算法复杂度以及硬件优化等因素,并结合具体应用场景进行综合评估。
2.2 TensorRT并非万能
TensorRT是一个优化引擎,可以显著提高深度学习模型的推理性能。然而,它不能完全依靠性能指标来评估模型的性能,因为模型的性能受到多个因素的影响,包括硬件平台、模型特性、数据集特征和应用场景。
2.3 CUDA Core vs TensorRT Core
-
CUDA Core(Compute Unified Device Architecture Core):
-
CUDA Core是NVIDIA GPU架构中的基本计算单元。它是用于执行并行计算任务的GPU硬件单元。
-
CUDA Core执行单个浮点运算操作,并可以通过并行处理多个数据元素来提高计算效率。
-
CUDA Core是用于执行通用计算任务的基本构建块,可用于编写并行计算的CUDA程序。
-
-
TensorRT Core:
-
TensorRT Core是TensorRT推理引擎中的组件,用于加速和优化深度学习模型的推理。
-
TensorRT Core利用GPU硬件和深度学习模型的特性进行推理优化,以提高推理性能和效率。
-
TensorRT Core实现了各种优化技术,如层融合、内存优化、精度调整等,以提高模型推理的速度和资源利用率。
-
总结来说,CUDA Core是NVIDIA GPU架构中的计算单元,用于执行通用并行计算任务,而TensorRT Core是TensorRT推理引擎中的组件,用于加速和优化深度学习模型的推理。CUDA Core是底层硬件层面的概念,而TensorRT Core是高层软件层面的概念。它们在不同层次上发挥着不同的作用,但都对深度学习模型的推理性能有重要影响。
2.4 1x1 与 depthwise conv的部署缺点
1x1卷积和深度可分离卷积(Depthwise Convolution)在深度学习模型中经常被使用,它们具有一些特定的部署缺点。下面是它们的一些常见缺点:
-
1x1卷积的部署缺点:
-
计算复杂度:尽管1x1卷积的计算量相对较小,但在处理特征图时仍需要进行相乘和相加操作,因此在某些情况下仍可能成为性能瓶颈。
-
内存占用:1x1卷积需要在内存中存储和处理大量的中间特征图,特别是在输入通道和输出通道数目较大的情况下,可能导致较高的内存占用。
-
参数数量:1x1卷积涉及到一定数量的权重和偏置参数,特别是在具有较多输入通道和输出通道的情况下,会增加模型的参数数量。
-
-
深度可分离卷积的部署缺点:
-
内存占用:深度可分离卷积通常需要在内存中存储和处理多个中间特征图,包括深度方向的分离卷积和逐点卷积的结果。这可能导致较高的内存占用。
-
网络深度:深度可分离卷积通常用于减少参数数量和计算量,但在一些情况下,它可能导致网络变得更深,从而增加了模型的计算和内存开销。
-
特征表示能力:相对于传统的卷积操作,深度可分离卷积的特征表示能力可能较弱。它更适用于具有较简单特征的任务,对于复杂特征的捕获可能有一定限制。
-
总结来说,1x1卷积和深度可分离卷积在深度学习模型中具有一些缺点。它们可能增加计算和内存开销,导致网络变得更复杂或限制特征表示能力。在使用这些卷积操作时,需要权衡性能、内存和模型表达能力,并根据具体任务的需求进行选择和优化。
三、 模型部署优化-量化
3.1 量化的基本概念和优缺点:
TensorRT中的量化(Quantization)是一种优化技术,用于减少模型的存储需求和计算开销。量化通过减少模型中参数和激活值的位数来实现,从而降低了模型的内存占用和计算复杂度。
参考链接:(261条消息) 7.TensorRT中文版开发教程-----TensorRT中的INT8量化详解tensorrt-int8量化扫地的小何尚的博客-CSDN博客
TensorRT 支持使用 8 位整数来表示量化的浮点值。量化方案是对称均匀量化 - 量化值以有符号 INT8 表示,从量化到非量化值的转换只是一个乘法。在相反的方向上,量化使用倒数尺度,然后是舍入和钳位。
要启用任何量化操作,必须在构建器配置中设置 INT8 标志。
·有两种常见的量化尺度粒度:
每张量量化:其中使用单个比例值(标量)来缩放整个张量。 每通道量化:沿给定轴广播尺度张量 - 对于卷积神经网络,这通常是通道轴。 通过显式量化,权重可以使用每张量量化进行量化,也可以使用每通道量化进行量化。在任何一种情况下,比例精度都是 FP32。激活只能使用每张量量化来量化。
优点:
-
存储需求减少:量化可以大幅减少模型中参数和激活值的位数,从而显著降低了模型的存储需求,节省内存空间。
-
计算开销减少:低位数的整数运算相对于浮点数运算更高效,可以减少模型的计算开销,提高推理速度和效率。
-
加速硬件支持:一些硬件平台(如NVIDIA的Tensor Cores)对于整数计算有特殊的加速支持,通过量化可以利用这些硬件特性提高推理性能。
缺点:
-
精度损失:由于量化过程中降低了位数,模型的精度可能会有所降低。特别是在较低位数的量化中,精度损失可能更加明显。
-
量化训练需求:对于参数量化,需要在训练过程中进行量化感知训练,以保持量化后模型的性能和精度。这可能需要额外的计算和训练成本。
-
硬件支持限制:量化技术可能需要特定的硬件支持,例如支持整数计算的加速器。在没有相应硬件支持的情况下,量化的优势可能有所减弱。
综上所述,TensorRT中的量化技术通过减少参数和激活值的位数来降低模型的存储需求和计算开销。它可以提高推理性能和效率,但可能会损失一定的模型精度,并对硬件支持和训练过程提出一定要求。在使用量化技术时,需要权衡精度、存储、计算和硬件支持等因素,并根据具体场景选择适当的量化策略。
3.2 QAT和PTQ
QAT(Quantization-Aware Training)和PTQ(Post-Training Quantization)是两种常见的深度学习模型量化技术。
-
QAT(Quantization-Aware Training):
-
QAT是在训练过程中进行量化感知训练的技术,旨在在训练期间考虑量化的影响,以便更好地适应量化后的模型。
-
在QAT中,模型的权重和激活值会在训练期间以浮点数形式进行计算,但在计算梯度和更新参数时,会使用量化操作和缩放因子。
-
QAT通过在训练期间模拟量化的效果,使得模型能够更好地适应量化后的数值范围,从而在量化推理时获得更好的精度和性能。
-
import torch
import torch.nn as nn
import torch.quantization
# 定义并训练浮点模型
float_model = MyModel()
# ...
# 将浮点模型转换为量化感知模型
quantized_model = torch.quantization.quantize_qat(float_model, qconfig=torch.quantization.get_default_qat_qconfig('fbgemm'))
# 进行量化感知训练
quantized_model.train()
# ...
# 停止量化感知训练并切换为推理模式
quantized_model.eval()
# ...-
PTQ(Post-Training Quantization):
-
PTQ是在训练完成后对模型进行量化的技术,它通过将训练好的浮点模型转换为定点模型来实现量化。
-
在PTQ中,模型在训练期间以浮点数形式进行训练,训练完成后,对模型的权重和激活值进行量化操作,将其转换为低位数的整数表示。
-
PTQ相对于QAT来说更简单,因为它不需要在训练过程中进行特殊的量化感知训练。然而,由于训练阶段不考虑量化的影响,PTQ可能需要一些微调或校准来提高量化后模型的性能和精度。
import torch
import torch.nn as nn
import torch.quantization
# 定义并训练浮点模型
float_model = MyModel()
# ...
# 将浮点模型转换为量化模型
quantized_model = torch.quantization.quantize(float_model, qconfig=torch.quantization.get_default_qconfig('fbgemm'))
# 使用量化模型进行推理
quantized_model.eval()
# ...
QAT和PTQ都是用于深度学习模型量化的技术,它们可以在一定程度上减少模型的存储需求和计算开销,并提高推理性能和效率。QAT通过在训练期间考虑量化的影响来适应量化,而PTQ则是在训练完成后将模型转换为定点表示。选择哪种技术取决于具体的需求和场景,以及对精度和训练过程的要求。
3.3 量化Per-tensor与Per-channel
量化技术中的Per-tensor(每张量)和Per-channel(每通道)是两种不同的量化方式,用于指定参数和激活值的量化粒度。
Per-tensor量化:
-
Per-tensor量化是指对整个张量(如权重参数或激活值)进行统一的量化操作,即所有元素都使用相同的缩放因子和量化参数。
-
在Per-tensor量化中,所有元素共享相同的量化范围和精度,适用于那些各个通道或位置上的元素差异不大的情况。
-
Per-tensor量化可以简化量化操作,减少计算和存储开销。
Per-channel量化:
-
Per-channel量化是指对张量中的每个通道(例如卷积层的输入通道或输出通道)分别进行量化操作,即每个通道有独立的缩放因子和量化参数。
-
在Per-channel量化中,不同通道的元素可以有不同的量化范围和精度,适用于那些通道间元素差异较大的情况。
-
Per-channel量化可以提供更好的精度保持能力,特别是对于那些具有通道相关性的模型。
选择Per-tensor量化还是Per-channel量化取决于具体的模型和任务需求。一般来说,如果模型中各个通道或位置的元素具有相似的数值分布和范围,则Per-tensor量化可能是一个简化且有效的选择。而对于那些具有不同通道相关性和差异的模型,Per-channel量化可以提供更好的精度保持能力,但可能会增加一些额外的计算和存储开销。
在实现量化时,可以根据模型结构和需求选择适当的量化方式,并使用相应的工具和库进行实现。例如,TensorRT提供了Per-tensor和Per-channel量化的支持,并根据模型结构自动选择最佳的量化方式。
四、 模型部署优化-剪枝
4.1 剪枝基本概念
模型剪枝(Model Pruning)是一种常用的模型部署优化技术,通过减少模型中冗余参数或结构,以达到减小模型大小、加速推理速度和降低计算资源需求的目的。剪枝技术通常可以分为以下几个步骤:
-
选择剪枝策略:确定要剪枝的目标,例如剪枝权重、剪枝通道(对于卷积层)、剪枝结构(对于网络结构中的连接)等。选择合适的剪枝策略是一个关键的决策,可以根据具体任务和需求来确定。
-
训练和评估:使用原始模型进行训练和评估,获取基准性能和精度。这是为了与剪枝后的模型进行比较,并确保剪枝后模型的性能不会显著下降。
-
剪枝操作:根据选择的剪枝策略,执行剪枝操作,将冗余参数或结构进行剪枝。常见的剪枝方法包括按阈值裁剪(如权重小于某个阈值的被剪枝)、剪枝比例(按比例裁剪权重)等。
-
精调(Fine-tuning):剪枝后,由于模型参数和结构的变化,可能导致性能下降。因此,需要进行精调,即在剪枝后的模型上进行进一步的训练,以恢复并提升性能。通常,精调使用原始训练数据集或一个更小的数据集进行。
-
评估和验证:在完成精调后,对剪枝模型进行评估和验证,确保性能和精度满足要求。根据需求,可以在剪枝后模型上进行推理性能和资源占用的测量,以验证剪枝效果。
剪枝技术可以显著减小模型的尺寸、加速推理速度,并降低计算资源需求。但需要注意的是,剪枝会引入稀疏性,可能对一些硬件加速器的性能造成影响。因此,在进行剪枝优化时,需要综合考虑模型大小、推理速度、精度和硬件支持等因素,以获得最佳的部署优化效果。剪枝技术可以成为单纯的一门研究课题。
具体操作示例参考:(261条消息) YOLOV5通道剪枝【附代码】_爱吃肉的鹏的博客-CSDN博客
(261条消息) 《模型轻量化-剪枝蒸馏量化系列》YOLOv5无损剪枝(附源码)_cv君的博客-CSDN博客
4.2 常见的 channel pruning 与 Filter pruning
常见的模型剪枝方法中,包括通道剪枝(Channel Pruning)和滤波器剪枝(Filter Pruning)。它们都是针对卷积神经网络中的通道(通道剪枝)或滤波器(滤波器剪枝)进行剪枝操作,以减少模型的参数数量和计算开销。
通道剪枝(Channel Pruning): 通道剪枝是指对卷积层中的通道(也称为特征映射或输出通道)进行剪枝操作,即减少卷积层输出通道的数量。剪枝的方式可以是根据某个阈值选择要剪枝的通道,或者基于重要性评估指标(如权重的L1范数、梯度的L2范数等)进行选择。通道剪枝可以降低计算开销,并且在一定程度上减少模型的存储需求,因为剪枝后的模型可以少计算和存储一部分通道的输出特征。
滤波器剪枝(Filter Pruning): 滤波器剪枝是指对卷积层中的滤波器(也称为卷积核或卷积窗口)进行剪枝操作,即减少卷积层中滤波器的数量。滤波器剪枝的方式通常基于滤波器的重要性评估指标,例如滤波器权重的L1范数、梯度的L2范数等。滤波器剪枝可以减少模型的参数数量和计算量,并且有助于提高模型的推理速度和效率。
通道剪枝和滤波器剪枝可以单独应用,也可以组合使用以进一步压缩和优化模型。这些剪枝技术可以帮助减小模型的尺寸、提高推理速度,并降低计算资源需求。在进行剪枝操作时,需要综合考虑模型性能、精度损失和硬件支持等因素,以达到最佳的剪枝效果。
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 定义一个简单的卷积神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(64, 128, kernel_size=3)
self.fc = nn.Linear(128 * 10 * 10, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 创建模型实例
model = Net()
# 进行模型训练
# ...
# 定义剪枝比例和剪枝策略
prune_ratio = 0.5
prune_strategy = prune.RandomUnstructured
# 对模型中的某一层进行通道剪枝
module_to_prune = model.conv1
prune.l1_unstructured(module_to_prune, name="weight", amount=prune_ratio)
# 打印剪枝后的模型
print(model)
# 进行剪枝后的模型评估
# ...
.3 模型剪枝的常见技巧
参考操作链接: (261条消息) 模型优化之模型剪枝_小树苗m的博客-CSDN博客
官方教程:
Pruning Tutorial — PyTorch Tutorials 2.0.1+cu117 documentation
模型剪枝按照结构划分,主要包括结构化剪枝和非结构化剪枝:
(1)结构化剪枝:剪掉神经元节点之间的不重要的连接。相当于把权重矩阵中的单个权重值设置为0。

(2)非结构化剪枝:把权重矩阵中某个神经元节点去掉,则和神经元相连接的突触也要全部去除。相当于同时去除权重矩阵中的某一行和列。如何判断神经元节点的重要程度呢?可以通过计算神经元对应的行和列的权重值的平方和的根的大小进行排序,把排序在后面一定比例的神经元节点去掉。
以下利用一个简单的案例对模型剪枝进行分析:
import torch
from torch import nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
(1)局部剪枝
def part_cut(model):
'''
######################################局部剪枝#########################################
剪枝之后会产生一个mask
剪枝api:prune.random_unstructured(layer1, name="weight", amount=0.3)
amount:剪枝的比例
layer1:需要剪的层对象
name:指定剪的权重还是偏执
剪枝固化api:prune.remove(layer1, 'weight')
参数不用过多介绍,功能是剪枝后的模型固化(永久化)
'''
layer1 = model.conv1
print("--------------------------------------剪枝前----------------------------------")
# print(list(layer1.named_parameters()))
# print(list(layer1.named_buffers()))
prune.random_unstructured(layer1, name="weight", amount=0.3)
print("--------------------------------------剪枝后-----------------------------------")
# print(list(layer1.named_parameters()))
# print(list(layer1.named_buffers()))
prune.remove(layer1, 'weight')
print("-------------------------------------模型固化后---------------------------------")
# print(list(layer1.named_parameters()))
# print(list(layer1.named_buffers()))
'''-------------------------------------多参数多网络结构剪枝---------------------------------'''
for name, module in model.named_modules():
print(name,module)
# prune 20% of connections in all 2D-conv layers
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
prune.remove(module, 'weight')
# prune 40% of connections in all linear layers
elif isinstance(module, torch.nn.Linear):
prune.l1_unstructured(module, name='weight', amount=0.4)
prune.remove(module, 'weight')
print(dict(model.named_buffers()).keys()) # to verify that all masks exist
return 0
(2) 全局剪枝:
def glob_cut(model):
'''
全局剪枝:
'''
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.6,
)
print(list(model.named_parameters()))
print(list(model.named_buffers()))
4.4 模型剪枝过程中的overhead
在剪枝过程中,会引入一些额外的计算和存储开销,这被称为剪枝过程中的overhead。下面是剪枝过程中可能产生的一些overhead:
-
额外的计算开销:剪枝过程通常涉及计算模型参数的重要性评估指标,例如梯度的L2范数或权重的L1范数。这些评估指标需要额外的计算开销,特别是在大型模型中。
-
额外的存储开销:剪枝过程中需要存储额外的信息,如剪枝比例、剪枝策略以及剪枝后的模型结构等。这些信息可能会增加模型的存储开销,尤其是当剪枝比例较大时。
-
重训练或精调开销:剪枝后,为了恢复模型性能或提高精度,通常需要进行重训练或精调。这会引入额外的训练迭代和计算开销,以重新调整剪枝后模型的参数。
-
推理性能的变化:剪枝后的模型可能会引入稀疏性,这可能对一些硬件加速器(如GPU)的性能产生影响。稀疏性可能导致并行计算效率下降或不利于某些优化技术的应用,从而影响推理性能。
虽然剪枝过程中存在一些overhead,但通过适当的策略和优化可以减少其影响。例如,可以选择高效的剪枝算法和指标评估方法,减少额外的计算开销。此外,剪枝后的模型可以通过量化、压缩或特定硬件加速器的支持来优化推理性能。
在进行剪枝优化时,需要综合考虑剪枝带来的overhead和剪枝效果,以及特定任务和硬件平台的需求。通过权衡这些因素,可以选择最佳的剪枝策略和方法,以获得最佳的模型压缩和优化效果。
总结:
经过上述学习,已经掌握了tensorrt的优化方案以及优化指标。可以针对性地对模型采取不同的优化方案进行改进,下章将介绍如何利用tensorrt提供的API进行性能数据和改进部署方案!!!!
PS:纯粹为学习分享经验,不参与商用价值运作,若有侵权请及时联系!!!
下篇内容预告:
-
深度学习模型部署TensorRT加速(十一):TensorRT部署分析与优化方案(二)