更多思路代码查看文末名片
1.如何有效应用双偏振变量改进强对流预报,仍是目前气象预报的重点难点问题。请利用题目提供的数据,建立可提取用于强对流临近预报双偏振雷达资料中微物理特征信息的数学模型。临近预报的输入为前面一小时(10帧)的雷达观测量(ZH 、ZDR、KDP),输出为后续一小时(10帧)的ZH预报。
这个问题我们可以考虑使用深度学习模型,特别是时间序列模型如LSTM或GRU,来处理雷达观测数据序列。输入可以是过去一小时的雷达观测量(ZH、ZDR、KDP),输出则是未来一小时的ZH预报。模型可以设计成多层的RNN结构,每一层学习不同层次的特征,最终输出预测的ZH值。
2.当前一些数据驱动的算法在进行强对流预报时,倾向于生成接近于平均值的预报,即存在“回归到平均(Regression to the mean)”问题,因此预报总是趋于模糊。在问题1的基础上,请设计数学模型以缓解预报的模糊效应,使预报出的雷达回波细节更充分、更真实。
为了缓解“回归到平均”的问题,可以考虑在模型训练时引入一些正则化技术,如Dropout,来防止模型过拟合。另外,可以加入对模型预测结果的不确定性估计,比如使用贝叶斯神经网络。模型不仅仅给出一个预测值,还会给出这个预测值的不确定性,去准确评估预报的可靠性。
3.请利用题目提供的ZH、ZDR和降水量数据,设计适当的数学模型,利用ZH及ZDR进行定量降水估计。模型输入为ZH和ZDR,输出为降水量。(注意:算法不可使用KDP变量。)
我们可以使用线性回归模型来估计降水量,其中输入特征为ZH和ZDR。模型的形式可以是: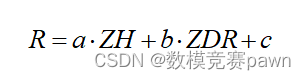
其中,R是降水量,a,b,c 是模型参数,通过最小化预测降水量和实际降水量之间的差异来学习。
4.请设计数学模型来评估双偏振雷达资料在强对流降水临近预报中的贡献,并优化数据融合策略,以便更好地应对突发性和局地性强的强对流天气。
更多思路查看下方名片