美团小美排序
n的排列是指有一个长度为n的数组[pi]中所有数各不相同,并且均在1到n之间,例如[3, 1, 2]是3的排列。小美想把序列排成递增序列,即[1, 2, 3, …, n],但她只能进行一种操作。首先她要在排列中任意选择两个不同的数取出。然后她将两个数中较大的放在排列的最后一位,较小的放在排列的第一位。她可以进行无限次这样的操作。请问她最少需要多少次才能将排序排列为递增序列。
题目分析:每次取两个必须放两端,那么最大最小肯定不能第一时间取出来,不然后面就被包裹在里面了,所以这个题属于贪心算法,首先看最中间的两个满足顺序不(如3这个数的下标一定要在4的下标前),满足,那么再看他们两边的,不满足,那么最中间的要先取出放两边,剩下的肯定都要取出,次数为n/2。
样例输入
5
1 5 4 2 3
样例输出
2#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
void main() {
int n;
cin >> n;
vector<int> nums(n);
for (int i = 0; i < n; i++) {
cin >> nums[i];
}
unordered_map<int, int> mp;
for (int i = 0; i < n; i++) {
mp[nums[i]] = i;
}
int i, j;
if (n % 2){
i = n / 2;
j = n / 2 + 2;
}
else {
i = n / 2;
j = n / 2 + 1;
}
int result = n / 2;
while (i >= 0) {
if (mp[i] < mp[j]) result--;
if (mp[i - 1] < mp[i] && mp[j] < mp[j + 1]) {
i--;
j++;
}
else break;
}
cout << result << endl;
}美团小美的树
小美在森林里有一棵树。树每年都会生长,生长是随机的,但也有规律。
1、 每个节点每年至多会长出一个儿子节点(也可能不长)
2、 当年新生的节点必定是叶子节点。
3、 树的根为1
给出两棵树,请你判断第一棵树明年有没有可能长成第二棵树的样子。
输入描述
首先输入T,表示T组数据
对于每一组数据,包含4行,
第一行是第一棵树的节点数:n。
第二行有n-1个数字li(i=2,3,...,n)表示第 i 的节点的父亲为li。
第三行是第二棵树的节点数:m。
第四行有m-1个数字ri(i=2,3,...,n)表示第 i 的节点的父亲为ri。
输入保证两棵树的对应节点序号相同,即两棵树的共有点父节点相同,且第二棵树包括第一棵树的所有节点。
1≤n,m≤50000, 1≤li,ri≤i, 1≤T≤10
输出描述
如果第一颗树明年有可能长成第二颗,输出“yes“,否则输出”no”。
1
4
1 1 2
6
1 1 2 2 4
样例输出
yes
提示
输入样例2
1
4
1 1 2
6
1 1 2 4 5
输出样例2
no样例解释2
样例2中5为新生节点,不应有子节点。
输入样例3
2
4
1 1 2
6
1 1 2 2 4
4
1 1 2
6
1 1 2 4 5
输出样例3
yes
no题目分析:限制条件1.每个已存节点最多只能生一个节点,那么表示tree_2后面的部分不能有重复的数字,不然就是一个父节点长出来的了。限制条件2,当年新生的节点必定是叶子节点,说明当年新生的节点只能从第一个tree长出来,不能从新生的节点长出来,也就是tree_2后面的部分不能有大于tree_1总结点值的数。
#include <iostream>
#include <vector>
using namespace std;
int main() {
int T;
cin >> T;
vector<int> ns(T);
vector<vector<int>> nnum(T);
vector<int> ms(T);
vector<vector<int>> mnum(T);
for (int i = 0; i < T; i++) {
cin >> ns[i];
for (int j = 0; j < (ns[i] - 1); j++) {
int n;
cin >> n;
nnum[i].push_back(n);
}
cin >> ms[i];
for (int j = 0; j < (ms[i] - 1); j++) {
int m;
cin >> m;
mnum[i].push_back(m);
}
}
for (int i = 0; i < T; i++) {
int n = ns[i];
int m = ms[i];
vector<int> tree_1 = nnum[i];
vector<int> tree_2 = mnum[i];
bool istrue = false;
for (int j = tree_1.size(); j < tree_2.size(); j++) {
if (tree_2[j] > n) {
cout << "no" << endl;
istrue = true;
break;
}
if (j > tree_1.size() && tree_2[j] == tree_2[j - 1]) {
cout << "no" << endl;
istrue = true;
break;
}
}
if (!istrue) cout << "yes" << endl;
}
return 0;
}美团小美的文件夹
小美喜欢整理电脑文件路径。但是她不喜欢一层一层查看文件夹。于是她写了一个程序,将文件信息写入了一行类html代码中。其中“<folder:name1 >…<\folder>”表示一个叫name1的文件夹,省略号中可能包括文件夹和文件,“<file:name2\ >”表示一个叫name2的文件。代码中仅有这两种信息,且文件名或文件夹名中保证不包括“>”、“<”或”\”且不为空,相同文件夹中的文件夹名各不相同,文件名各不相同。小美希望清除文件夹中无用的文件夹,即空的文件夹。具体定义为:(1) 没有任何文件和文件夹的文件夹是空文件夹(2) 只包含空文件夹的文件夹也是空文件夹。即当前目录树下没有任何文件的文件夹就是空文件夹。小美希望知道有多少空文件夹。
输入描述
题目包括T组数据
对于每一组数据,包含1行字符串s。
1≤|s|≤50000, 1≤T≤5
输出描述
对每组数据,输出一个整数,表示空文件夹的数量。
样例输入
2
<folder:name1><folder:name2><folder:name3><\folder><\folder><file:name4\><\folder>
<folder:name1><folder:name2><folder:name3><file:name4\><\folder><\folder><\folder>
样例输出
2
0题目分析:每一个文件夹都是以<\folder>结尾,在开头和其之间的东西都是属于该文件夹内的,类似于消消乐的感觉,每次得到一个<\folder>就把它前面的一个文件夹开头取出来与它组成一对。这就是栈的问题,碰见文件夹开头先入栈,当碰到文件<file:name2\ >时,说明文件在文件夹开头和结尾之间,栈里的文件夹就都不为空了,直接返回。当在碰到文件之前就碰到文件夹结尾,说明这个文件夹里没有文件,我们直接把空文件res++。这道题目还有注意的地方是,cin之后调用getline,一定要先cin.ignore()。还有字符串转义的问题,为了防止转义,我们多加一个\表示后面的\不转义。
#include <iostream>
#include <vector>
#include <string>
#include <stack>
using namespace std;
int main() {
int T;
cin >> T;
cin.ignore(); //这一行很关键,不然下面的getline会读取到上面的cin最后的回车符。
vector<int> result(T, 0);
for (int i = 0; i < T; i++) {
string s;
stack<string> folders;
getline(cin, s);
int start = 0;
int res = 0;
for (int j = 0; j < s.size(); j++) {
if (s[j] == '>') {
string fold = s.substr(start, j - start + 1);
start = j + 1;
if (fold != "<\\folder>") { //这里两个斜杠是为了防止转义
folders.push(fold);
}
else {
string file = folders.top();
folders.pop();
string head = file.substr(0, 5);
if (head == "<file") {
result[i] = res;
break;
}
else {
res++;
}
}
}
}
}
for (int i = 0; i < T; i++) {
cout << result[i] << endl;
}
return 0;
}华为批量初始化次数
某部门在开发一个代码分析工具,需要分析模块之间的依赖关系,用来确定模块的初始化顺序、是否有循环依期等问题。"批量初始化”是指一次可以初始化一个或多个模块。例如模块1依赖模块2,模块3也依赖模块2,但模块1和3没有依赖关系,则必须先"批量初始化”模块2,再"批量初始化"模块1和3。现给定一组模块间的依赖关系,请计算需要“批量初始化"的次数。
解答要求
时间限制: C/C++ 1000ms.其他语言: 2000ms
内存限制: C/C++ 256MB,其他语言: 512MB
输入
(1)第1行只有一个数字.表示模块总数N。
(2)随后的N行依次表示模块1到N的依赖数据。每行的第1个数表示依赖的模块数量(不会超过N),之后的数字表示当前模块依赖的ID序列。该序列不会重复出现相同的数字,模块ID的取值定在[1,N]之内。
(3)模块总数N取值范围 1<=N<=1000.
(4)每一行里面的数字按1个空格分隔。
输出
输出"批量初始化次数”.若有循环依赖无法完成初始化,则输出-1。
样例1
输入: 5
3 2 3 4
1 5
1 5
0
输出: 3
解释:共5个模块。
模块1依赖模块2、3、4;
模块2依赖模块5
模块3依赖模块5
模块4依赖模块5
模块5没有依赖任何模块
批量初始化顺序为{5}->{2,3,4}->{1},共需”批量初始化”3次
样例2
输入: 3
1 2
1 3
1 1
输出: -1
解释:存在循环依赖,无法完成初始化,返回-1#include <string>
#include <iostream>
#include <vector>
#include <stack>
#include <unordered_map>
using namespace std;
int resetnum = -1;
void dfs(vector<vector<int>>& neednodes, vector<bool>& visiter, int result) {
int have_vis = 0;
for (int i = 0; i < visiter.size(); i++) {
if (visiter[i]) have_vis++;
}
if (have_vis == visiter.size()) {
resetnum = result;
return;
}
bool no_change = true;
for (int i = 0; i < visiter.size(); i++) {
if (visiter[i]) continue;
vector<int> need = neednodes[i];
bool all_need = true;
for (int j = 0; j < need.size(); j++) {
if (visiter[need[j] - 1]) continue;
else {
all_need = false;
break;
}
}
if (!all_need) continue;
else {
visiter[i] = true;
no_change = false;
}
}
if (no_change) return;
dfs(neednodes, visiter, result + 1);
}
int main() {
int N;
cin >> N;
vector<vector<int>> neednodes;
for (int i = 0; i < N; i++) {
int num;
cin >> num;
vector<int> neednode(num);
for (int j = 0; j < num; j++) {
cin >> neednode[j];
}
neednodes.push_back(neednode);
}
vector<bool> visiter(N, false);
dfs(neednodes, visiter, 0);
cout << resetnum << endl;
}华为
#include <iostream>
#include <string>
#include <vector>
#include <cmath>
#include <unordered_map>
using namespace std;
int main() {
int start;
int end;
cin >> start >> end;
vector<int> ID;
unordered_map<int, bool> visited;
for (int i = start; i <= end; i++) {
ID.push_back(i);
visited[i] = false;
}
int n;
cin >> n;
vector<pair<int, int>> works(n);
for (int i = 0; i < n; i++) {
cin >> works[i].first >> works[i].second;
}
for (int i = 0; i < n; i++) {
if (works[i].first == 1 && works[i].second <= ID.size()) {
int num = works[i].second;
while (num--) {
visited[ID[0]] = true;
ID.erase(ID.begin());
}
}
else if (works[i].first == 2) {
if (visited[works[i].second]) continue;
if (works[i].second < start || works[i].second > end) continue;
int j = 0;
while (ID[j] != works[i].second) j++;
ID.erase(ID.begin() + j);
visited[works[i].second] = true;
}
else {
if (works[i].second < start || works[i].second > end) continue;
if (!visited[works[i].second]) continue;
visited[works[i].second] = false;
ID.push_back(works[i].second);
}
}
cout << ID[0] << endl;
}用友计算被直线划分区域
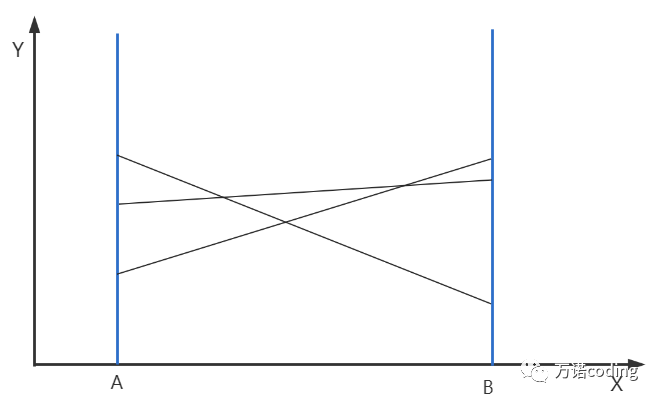
在笛卡尔坐标系,存在区域[A,B],被不同线划分成多块小的区域,简单起见,假设这些不同线都直线并且不存在三条直线相交于一点的情况。
那么,如何快速计算某个时刻,在 X 坐标轴上[ A, B] 区间面积被直线划分成多少块?
A轴平行坐标Y轴,A (x=1)
B轴平行坐标Y轴, B(x = 20);
输入描述
输入采用多行输入,一行4个数据,分别表示两个坐标点,一行一条直线;
1,4,20,100 - 表两个点,点t1的坐标为(1,4),点t2坐标为(20,100)
输出描述
输出为整数,表示被输入线段划分的面积个数
示例1
输入
1,37,20,4
1,7,20,121
输出
4
备注
AB之间的线段不平行于Y轴题目分析:这道题目难的地方有两个,一个是输入。没有给个数,一次性输入多行,必须用while接收。另一个是技巧,进来一根线,区域数先加1,与其他的每有一个交点就再加1.
#include <iostream>
#include <string>
#include <unordered_map>
#include <algorithm>
using namespace std;
int main() {
int x1, y1, x2, y2;
int result = 1;
vector<vector<int>> lines;
while (cin >> x1 >> y1 >> x2 >> y2) {
result++;
for (auto& line : lines) {
if ((line[1] > y1 && line[3] > y2) || (line[1] < y1 && line[3] < y2) || line[1] == y1 || line[3] == y2) {
continue;
}
result++;
}
lines.push_back({ x1, y1, x2, y2 });
}
cout << result << endl;
return 0;
}
用友最佳面试策略
小明最近在找工作,收到了许多面试邀约,可参加的面试由interviews 数组表示,其中 interviews[i] = [startTimei, endTimei, possibilityi],表示第 i 个面试在 startTimei 开始,endTimei 结束,面试成功的可能性是 possibilityi,该值越大,通过面试的可能性越大,由于精力限制,小明最多可以参加 k 场面试。
小明同一时间只能参加一场面试,如果要参加某场面试,必须完整参加这场面试才可能通过面试,即不能同时参加一个开始时间和另一个结束时间相同的两场面试。
请给出小明面试成功可能性的最大和。
示例1
输入
[[1,2,3],[3,4,2],[2,4,4]],2
输出
5
说明
小明参加 [1, 2, 3], [3, 4, 2] 两场面试,面试通过可能性的和为 3 + 2 = 5
示例2
输入
[[1,2,3],[3,4,2],[2,4,6]],2
输出
6
说明
只参加面试 [2, 4, 6],面试通过的可能性的和最大,为 6 题目分析:有点像hot100里合并区间的题,但是这个题,最多只能面K个,同时要结果最高。一开始想的DP,动态规划,但我想不出来dp[i][j]表示啥。所以用的回溯暴力解法。每次到达一个节点,有两个选择,一个是面试,一个是不面试,同时面试也是有条件的,那就是当前节点的起始时间一定要大于现在没空的截止时间。那么回溯的终止条件是,第一个面试次数到达K了,第二个,面试遍历完了。所以我们回溯的参数里有个当前遍历节点的下表index,以及当前面试的个数count
#include <iostream>
#include <string>
#include <unordered_map>
#include <algorithm>
using namespace std;
int result = 0;
void dfs(vector<vector<int>>& interviews, int index, int count, int k, int end_length, int res) {
if (count == k) {
result = max(result, res);
return;
}
if (index >= interviews.size()) {
result = max(result, res);
return;
}
if (interviews[index][0] > end_length) {
dfs(interviews, index + 1, count + 1, k, interviews[index][1], res + interviews[index][2]);
}
dfs(interviews, index + 1, count, k, end_length, res);
}
int main() {
vector<vector<int>> interviews = { {1, 2, 3}, {3, 4, 2} ,{2, 4, 6} };
int k = 2;
sort(interviews.begin(), interviews.end(), [](const vector<int>& a1, const vector<int>& a2) {
if (a1[0] == a2[0]) return a1[1] < a2[1];
return a1[0] < a2[0];
});
dfs(interviews, 0, 0, k, 0, 0);
cout << result << endl;
return 0;
}用友星球间的最短通路
在一个遥远的银河中,有N个星球(编号从1到N),这些星球之间通过星际门进行连接。每个星际门都连接两个星球,并且可以双向通行。
每个星际门的开启需要消耗一定的能量,这个能量由星际门上的数字表示。每个星际门上的数字都是唯一的。
现在,由于某种原因,所有的星际门都处于关闭状态。作为一个探索者,你的任务是找出一种方式,开启最少的星际门,使得所有的星球都至少通过一个开启的星际门与其他星球连接。
给你一些可连接的选项 connections,其中 connections[i] = [Xi, Yi, Mi] 表示星球 Xi 和星球 Yi 之间可以开启一个星际门,并消耗 Mi 能量。
计算联通所有星球所需的最小能量消耗。如果无法联通所有星球,则输出-1。
示例1
输入
3,[[1, 2, 5], [1, 3, 6], [2, 3, 1]]
输出
6
备注
1 ≤ N ≤ 100题目分析:这个题目是典型的最小生成树的问题,题目给的是一个带有权值的图,你的任务是用最小的代价把图中所有的点串联到一起,串联起来所使用的权值最小。而题目中需要把所有的星球连接,相当于就是构建一个图。同时需要边的权值最小。
最小生成树一般有两种解法一种是Prim方法,一种是克鲁斯卡尔算法。今天主要搞prim算法。
把树中的点分为两类,A类遍历过,B类没有遍历过。一开始都在B类,从B中随机选择一个加入A类,然后看B类中离A类节点权值最小的一个点,把他加入到A中,然后再找B离A最近的,一直到B中没有顶点。
先构建邻接表,遍历已知通路,然后把连接关系和权值放入邻接表。构建visited防止多次遍历一个节点,dist表示B中的点(遍历过的)到这个点的最小距离初始化为无穷大。每次找最近所以我们用小顶堆实现,调用优先级队列,里面的pair保存的是,到达这个点的最小的代价以及这个点的下标。
先把第一个点初始化为0,说明把他加入A,他的dist就变为0,把他放入优先级队列。while(que)
取出来一个,如果visited,continue,没有遇到过就遍历他的临近节点,如果临近节点没有遍历过,同时到达临近节点的权值是小于dist[临近],就把这个邻接点以及它的最小连接权重放入。
#include <iostream>
#include <string>
#include <unordered_map>
#include <algorithm>
#include <queue>
using namespace std;
int prim(vector<vector<int>>& connections, int N) {
int result = 0;
vector<vector<pair<int, int>>> graph(N + 1);
for (auto& con : connections) {
graph[con[0]].push_back({ con[1], con[2] });
graph[con[1]].push_back({ con[0], con[2] });
}
vector<bool> visit(N + 1, false);
vector<int> dist(N + 1, INT_MAX);
dist[1] = 0;
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> que;
que.push({ 0, 1 });
while (!que.empty()) {
int weight = que.top().first;
int node = que.top().second;
que.pop();
if (visit[node]) continue;
visit[node] = true;
result += weight;
for (auto neighbor : graph[node]) {
int neighbornode = neighbor.first;
int weigh = neighbor.second;
if (!visit[neighbornode] && weigh < dist[neighbornode]) {
dist[neighbornode] = weigh;
que.push({ weigh, neighbornode });
}
}
}
for (int i = 1; i <= N; i++) {
if (!visit[i]) return -1;
}
return result;
}
int main() {
vector<vector<int>> connections = { {1, 2, 5}, {1, 3, 6}, {2, 3, 1} };
int N = 3;
int result = prim(connections, N);
cout << result << endl;
return 0;
}美团小美的树上染色(23年秋招压轴真题)
小美拿到了一棵树,每个节点有一个权值。初始每个节点都是白色。
小美有若干次操作,每次操作可以选择两个相邻的节点,如果它们都是白色且权值的乘积是完全平方数,小美就可以把这两个节点同时染红。
小美想知道,自己最多可以染红多少个节点?
输入描述
第一行输入一个正整数n,代表节点的数量。第二行输入n个正整数ai,代表每个节点的权值。接下来的n-1行,每行输入两个正整数u,v,代表节点u和节点v有一条边连接。
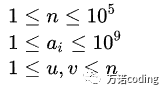
输出描述
输出一个整数,表示最多可以染红的节点数量。
示例1
输入
3
3 3 12
1 2
2 3
输出
2
说明
可以染红第二个和第三个节点。
请注意,此时不能再染红第一个和第二个节点,因为第二个节点已经被染红。
因此,最多染红 2 个节点。题目分析:这个题给的是一个树形结构,每次染色满足条件的相邻的两个,那么一个父节点和其中一个子节点染色的话,它就不能和其他的子节点染色了,这是很重要的一个递归逻辑。本题是典型的树形DP算法,对于一个节点有两种状态,一个是其不染色,一个是其染色。
每次DFS时,传入当前节点和他的父节点,是为了防止其反向从当前节点到父节点。也就是只能从上往下。同时父节点染不染色取决于子节点的状态,所以我们先递归到底部节点,再一步一步往上dp。
#include <iostream>
#include <vector>
using namespace std;
void dfs(int u, int fa, vector<vector<int>>& g, vector<int>& a, vector<vector<int>>& dp) {
for (int v : g[u]) {
if (v == fa) continue;
dfs(v, u, g, a, dp);
dp[u][0] += max(dp[v][0], dp[v][1]); //这里每次子节点dfs处理完,都会取子节点的max,然后更新u的不染红的情况。
//这里u不染色时,他的子节点既可以染色(子节点a和a的子节点染色),也可以不染色。所以取max
}
for (int v : g[u]) {
if (v == fa) continue;
long long val = a[v] * a[u]; //要是想把uv都染色,就要看uv满不满足条件
long long sq = sqrt(val);
if (sq * sq != val) continue;
dp[u][1] = max(dp[u][1], dp[u][0] - max(dp[v][0], dp[v][1]) + dp[v][0] + 2);
//这里如果u想染色,前面必须满足条件,然后因为是for循环,我们要看u和哪个子节点一起染色时值最大。所以在循环里不断取max
//这里的dp[u][1]表示u和当前v染色的情况,那么这个uv都必须空出来,这样才能染色。所以我们一开始就要找u不染色的节点数dp[u][0],但是dp[u][0]里包含了v的染色和不染色的情况(看第九行),所以我们减去这个值也就是max(dp[v][0],dp[v][1]),
//此时dp[u][0] - max(dp[v][0], dp[v][1])表示的是不染色u节点,同时不考虑v分支时的染色个数,那么我们想染色v,就必须把v空出来,所以加dp[v][0]表示不染色v时v下面的分支有多少,最后再加2,表示uv这两个节点染色。
}
}
int main() {
int n;
cin >> n;
vector<int> a(n);
for (int i = 0; i < n; i++) {
cin >> a[i];
}
vector<vector<int>> g(n);
for (int i = 1; i < n; i++) {
int u, v;
cin >> u >> v;
--u, --v;
g[u].push_back(v);
g[v].push_back(u);
}
vector<vector<int>> dp(n, vector<int>(2, 0));
dfs(0, -1, g, a, dp);
cout << max(dp[0][0], dp[0][1]);
return 0;
}元神抽卡
已知《原神》和《崩坏:星穹铁道》中的抽卡系统的概率如下:
在未触发大保底机制时,每抽一发有 p/2 的概率抽到当期5星,有p/2 的概率抽到常驻5星,其余的1- p 概率不出5星。
当抽到常驻5星后,触发了大保底机制,以后每抽一发有 p 的概率抽到当期5星,其余的 1-p 概率不出5星。
另外,当连续89抽未出5星时,下一抽必出5星。也就是说,若未触发大保底机制,本次抽卡 1/2 概率抽到当期5星,有 1/2 的概率抽到常驻5星,若已触发了大保底机制,则100%概率抽到当期5星。
现在给定了抽中5星的概率 p。米小游想要抽到一张当期5星卡,她想知道抽卡次数的期望是多少?
输入描述
一个小数 p(0 < p< 1),代表抽中5星的概率。
输出描述
一个浮点数,代表抽卡次数的期望。如果你的答案和正确答案的误差不超过 10^-6,则认为答案正确。
示例1
输入
0.006
输出
104.5497057题目分析:典型的概率估计问题,跟折断绳子一样。但这个题明显更复杂一点。首先我们要分两种情况,第一种第一次抽到5星卡就是当期五星,第二种第一次抽到的五星卡是常驻五星,第二次抽到五星卡才是当期五星。
//第n次抽卡出5星的概率
double cal(int n, double p) {
if (n < 90) {
return pow(1 - p, n - 1) * p;
}
return pow(1 - p, n - 1);
}
int main() {
double p;
cin >> p;
double result = 0;
//第一次抽到5星就是当期五星
for (int i = 1; i < 91; i++) {
result += i * cal(i, p) / 2;
}
//第一次抽到五星是常驻五星,第二
for (int i = 1; i < 91; i++) {
for (int j = 1; j < 91; j++) {
double p1 = cal(i, p) / 2;
double p2 = cal(j, p);
result += (i + j) * (p1 * p2);
}
}
cout << result << endl;
return 0;
}字节所有字串权重和
小红定义一个字符串的权值为:极长“连续段”的数量。所谓极长“连续段”,指尽可能长的一段字符全部相同的连续子串。例如,"1100111"共有3个连续段:"11"、"00”和"111”,所以权值为 3。
现在小红拿到了一个01串,小红希望你帮她求出所有子串的权值之和。
输入描述
第一行输入一个正整数n,代表字符串的长度。
第二行输入一个长度为n,且仅由‘0’和‘1’两种字符组成的字符串。
1<=n<=200000
输出描述
一个正整数,代表所有子串的权值之和。
示例1
输入
4
1101
输入
17
说明
4个长度为1的子串的权值均为1。
长度为2的子串中,”11"的权值为1,”10”和”01”的权值均为2。
长度为3的子串中,”110"的权值为2,"101”的权值为3。
长度为4的子串”1101”的权值为3。
总权值为1*4+1+2+2+2+3+3=17
题目分析:这个题求一个字符串的权值很简单,直接for循环,遇到变化就加1。题目中要求求所有子串的权值和,我一开始笔试的时候就是这种两个for循环,遍历所有的子串,然后求权值。只能通过30%,后续下来发现大神的dp真牛逼,一阵见血。复杂度直接降到o(n)。
下面详细说一下dp的思路,很难理解。dp[i]表示以i结尾的所有子串的权值之和。那么我们想一下,如果s[i] == s[i - 1]也就是当前字符和前一个字符相同,那么只要以i - 1字符结尾的子串 (dp[i - 1]),加上i这个字符是不是权值都不会变呀。因为下表i和i - 1的字符一样,加个一样的肯定权值不变呀,不懂的看一下题目中权值的定义。第二种情况,如果s[i] != s[i - 1],那么任何一个以i - 1结尾的子串加上i这个字符他们的权值都要加1,具体的dp流程见下面代码。
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main() {
int n;
cin >> n;
string str;
cin >> str;
long long ans = 1;
vector<long long> dp(n, 0);
dp[0] = 1;
for (int i = 1; i < n; i++) {
if (str[i] == str[i - 1])
dp[i] = dp[i - 1] + 1; //如果相同,那么以i结尾的子串权值等于i - 1结尾的子串权值 + i字符这个单独的子串
else
dp[i] = dp[i - 1] + i + 1; //如果不同,那么以i结尾的子串权值等于i - 1结尾的子串权值都 + 1, 再+i字符这个单独的子串
ans += dp[i];
}
cout << ans << endl;
return 0;
}字节项链三珠互斥
小红将n个珠子排成一排,然后将它们串起来,连接成了一串项链(连接后为一个环,即第一个和最后一个珠子也是相邻的),任意相邻两个珠子的距离为1。已知初始共有3个珠子是红色的,其余珠子是白色的。
小红拥有无穷的魔力,她可以对项链上的相邻两个珠子进行交险。小红希望用最小的交换次数,使得红意两个红色的珠子的最小阳距离小干k,你能帮小红求出最小的交换次数吗?
输入描述
第一行输入一个正些数t,代表询问次数。
每行为一次询间,输出五个正整数n,k,a1,a2,a3,分别代表珠子总数量,要求的珠子距离,以及三个珠子的位置。
1<=t<=10^4
1<=n<=10^9
1<=k,a1,a2,a3<=n
保证ai互不相同。
输出描述
输出t行,每行输入一个整数,代表最小的交换次数。如果无法完成目的,则输出-1。
示例1
输入
2
6 2 1 2 3
5 2 1 3 4
输出
2
-1
说明
第一组样例,六个珠子为红红红白白白。第一次操作交换第一个和第六个珠子,第二次操作交换第三个和第四个珠子。
第二组询问,一共有5个珠子,其中有3个红珠子,因此无论如何都会有两个红珠子相邻,不可能满足任意两个红珠子的最小距离不小于2。
题目分析:首先给了三个珠子的位置,但是他们不知道是不是有序的,先sort,然后求两两间的距离,把三个距离也放到vector里,这样方便排序(因为我们每次改变完距离,需要找最大最小的两个)。我当时笔试的时候太傻逼了,三个数每次判断看哪个小于k,小于k看另外两个大的减一,小的加一。这样每次都只能移动一位,时间复杂度超时,具体操作应该是最大的和最小的同时加减min(k - q[0], q[2] - k)。
#include <iostream>
#include <string>
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long ll;
vector<int> p(3);
vector<int> q(3);
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
{
int m, k, x, y, z;
cin >> m >> k >> x >> y >> z;
p[0] = x;
p[1] = y;
p[2] = z;
sort(p.begin(), p.end());
if (3ll * k > m)
{
cout << -1 << endl;
continue;
}
q[0] = p[1] - p[0];
q[1] = p[2] - p[1];
q[2] = p[0] + m - p[2];
sort(q.begin(), q.end());
ll ans = 0;
while (q[0] < k)
{
int now = min(k - q[0], q[2] - k);
ans += now;
q[2] -= now;
q[0] += now;
sort(q.begin(), q.end());
}
cout << ans << endl;
}
return 0;
}字节扑克牌同花顺
小红最近迷上了纸牌。纸牌有黑桃(Spade)、红桃(Heart)、方块 (Diamond) 、梅花(Club) 四种花色,并且每张纸牌上面写了一个正整数。小红拿到了许多牌,准备玩以下游戏:
每次操作在这堆牌中任取5张牌,计算这5张牌的分数,然后将其丢弃(丢弃的牌不可再次选取)。
为了简化,本题仅计算同花顺这一牌型:即取出的5张牌构成同花顺,则可以获得1分。其他牌型均不得分。
所谓同花顺,即五张牌花色相同,且排序后满足 ai+1=a(i+l)。
小红想知道,经过若干次操作后,自己最多可以得到多少分?
请注意,同一个牌型可能出现多次!
输入描述
第一行输入一个正整教n,代表牌堆中牌的种类(如果两张牌的花色或数值不同,则认为种类不同)。
接下来的n行,每行输入两个正整教:ai和cnti和一个字符ci。分别代表每种牌的大小、数量以及花色。
1<=n<=10^5
1<=ai,cnti<=10^9
ci∈{'s','H','D','C'},代表扑克牌的四种花色: 黑桃(Spade)、红桃(Heart)、方块(Diaond)、梅花(Club)。
保证每个种类的牌在输入中只出现了一次。
输出描述
一个整数,代表小红可以最多获得的分数。
示例1
输入
6
1 1 s
2 2 s
3 2 s
4 2 s
5 2 s
1 10 h
输出
1
说明
可以取到一个同花顺:[1S,2S,3S,4S,5S]。虽然有10个红桃1,但无法和其他牌凑成同花顺。
题目分析:同花顺只能出现在一种花色里。那么我们分花色统计。进来后先根据花色,把他们放入字典,键是string花色,值则是一个自定义的类型。因为我们既要知道这个花色有哪些值,也要知道这个值有几个。所以自定义类型里有一个set和一个map,此时我们for循环花色。取到每个花色有哪些值,并且这些值有几个。对set里的值for循环(必须用set,因为他是默认排好序的),统计值的个数,以及当前值到当前值+4这五个值里面的最小个数,这个就是以当前值开始的同花顺的个数,同时map里的个数要减去这个同花顺的个数。具体代码如下:
#include <iostream>
#include <vector>
#include <string>
#include <unordered_map>
#include <set>
using namespace std;
struct node {
set<int> st;
unordered_map<int, int> cnt;
};
unordered_map<string, node> mp;
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
int a, num;
string c;
cin >> a >> num >> c;
mp[c].st.insert(a);
mp[c].cnt[a] += num;
}
int result = 0;
for (auto& col : mp) {
node x1 = col.second;
for (int start : x1.st) {
int count = x1.cnt[start];
for (int j = start + 1; j < start + 5; j++) count = min(count, x1.cnt[j]);
result += count;
for (int i = start; i < start + 5; i++) x1.cnt[i] -= count;
}
}
cout << result << endl;
return 0;
}