目录
1 连接查询
准备工作:
create database k1;
use k1;
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
UPDATE store_info SET store_name='Washington' WHERE sales=300;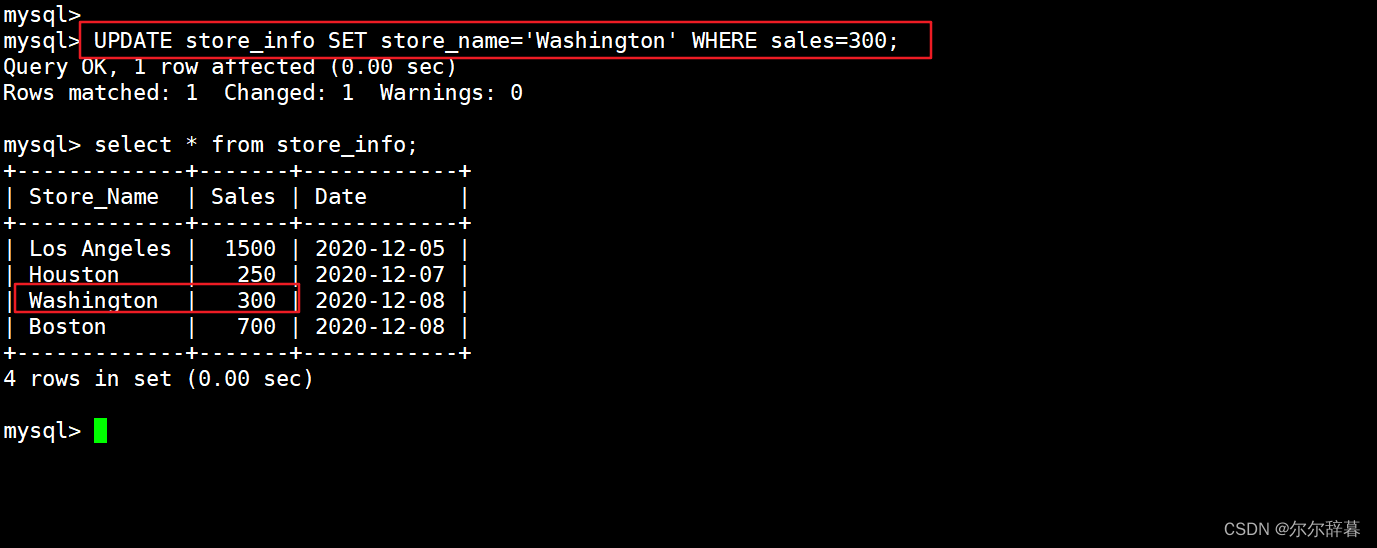
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
1.1 内连接
MySQL 中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。通常在 FROM 子句中使用关键字 INNER JOIN 来连接多张表,并使用 ON 子句设置连接条件,内连接是系统默认的表连接,所以在 FROM 子句后可以省略 INNER 关键字,只使用 关键字 JOIN。同时有多个表时,也可以连续使用 INNER JOIN 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
(1)语法 求交集
SELECT column_name(s)FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
SELECT * FROM location A INNER JOIN store_info B on A.Store_Name = B.Store_Name ;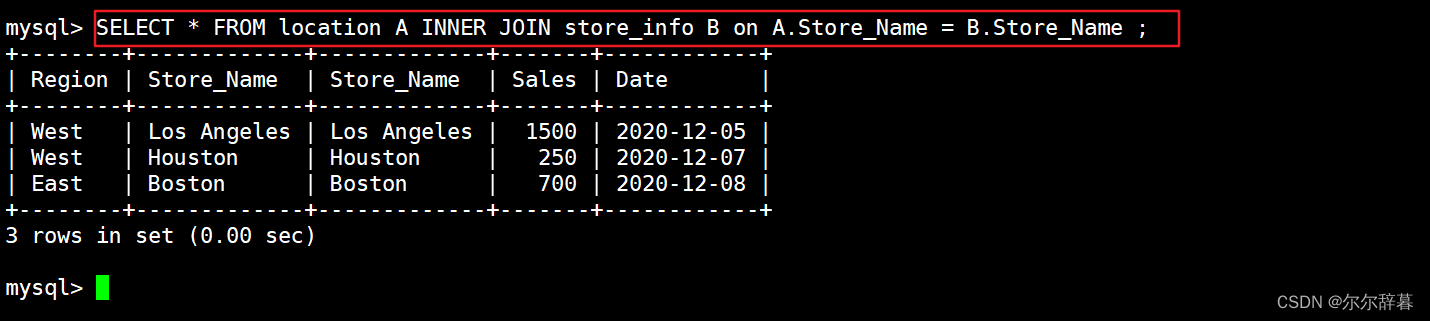
内连查询:通过inner join 的方式将两张表指定的相同字段的记录行输出出来
1.2 左连接
左连接也可以被称为左外连接,在 FROM 子句中使用 LEFT JOIN 或者 LEFT OUTER JOIN 关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参 考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
SELECT * FROM location A LEFT JOIN store_info B on A.Store_Name = B.Store_Name ;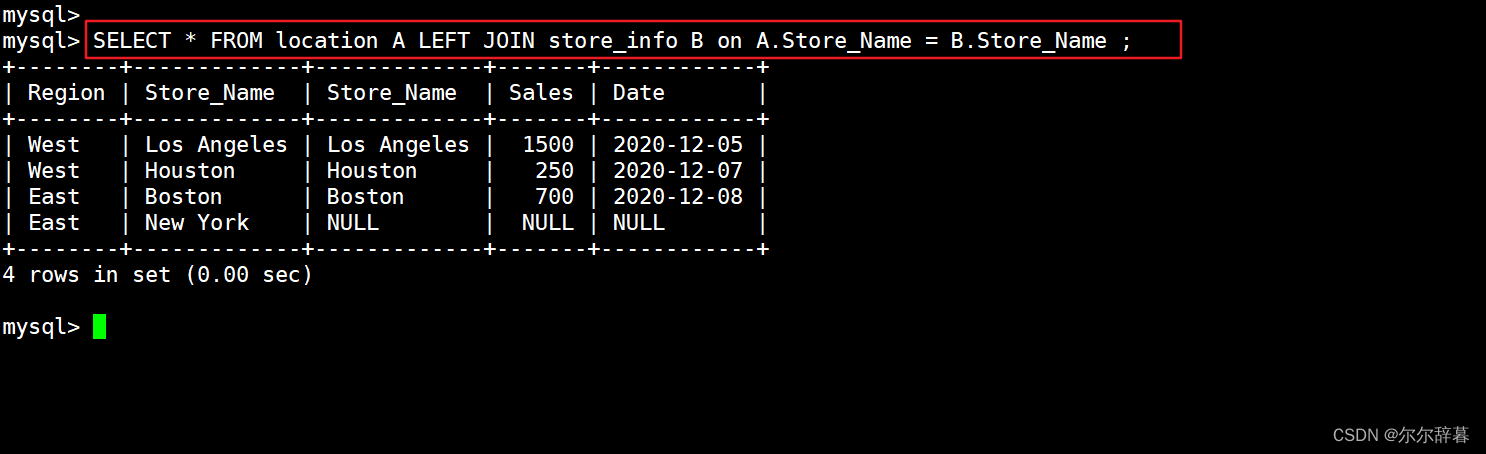
左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为 NULL。
1.3 右连接
右连接也被称为右外连接,在 FROM 子句中使用 RIGHT JOIN 或者 RIGHT OUTER JOIN 关键字来表示。右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配
SELECT * FROM location A RIGHT JOIN store_info B on A.Store_Name = B.Store_Name ;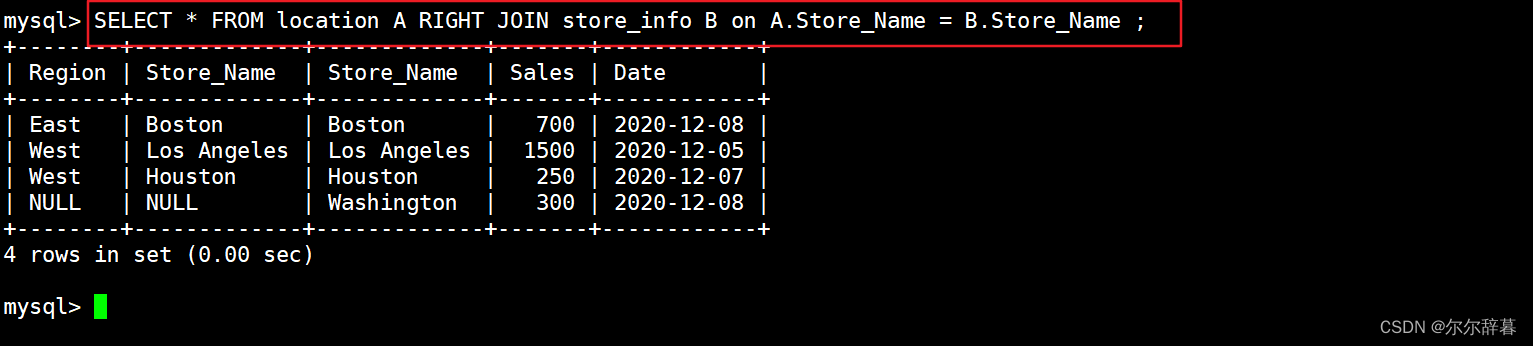
2 UNION ----联集
将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM store_info;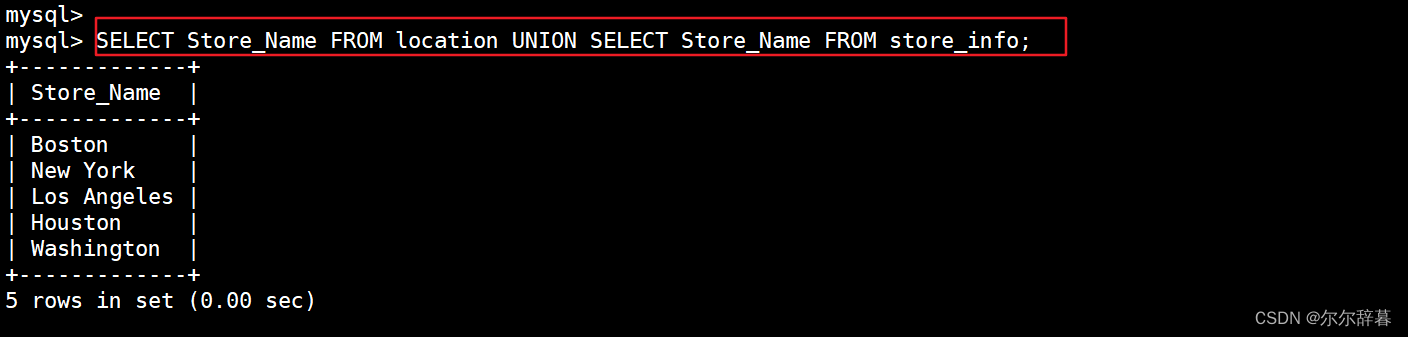
UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_info;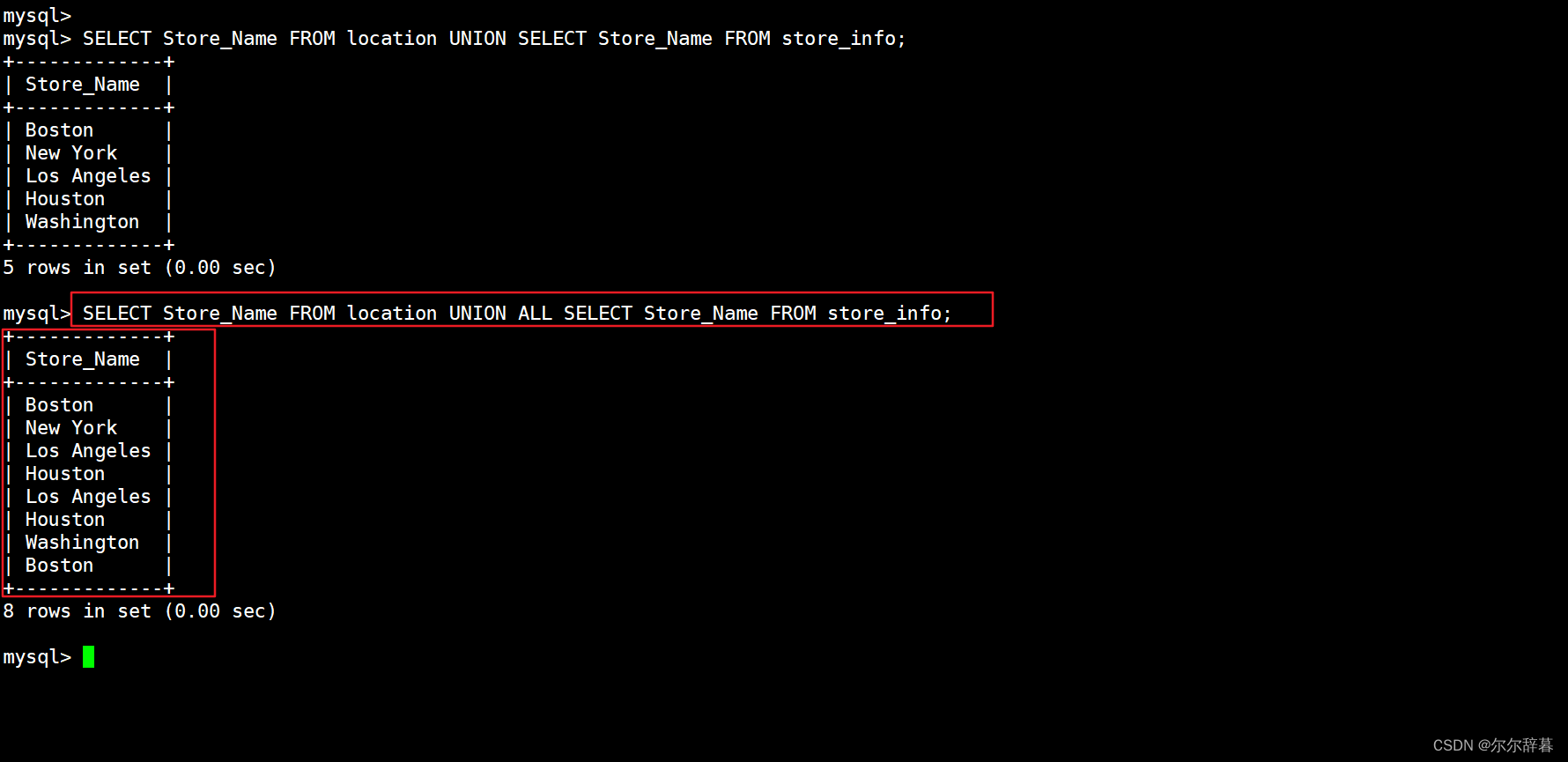
2.1 交集值
取两个SQL语句结果的交集
SELECT A.Store_Name FROM location A INNER JOIN store_info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);
取两个SQL语句结果的交集,且没有重复
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM store_info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
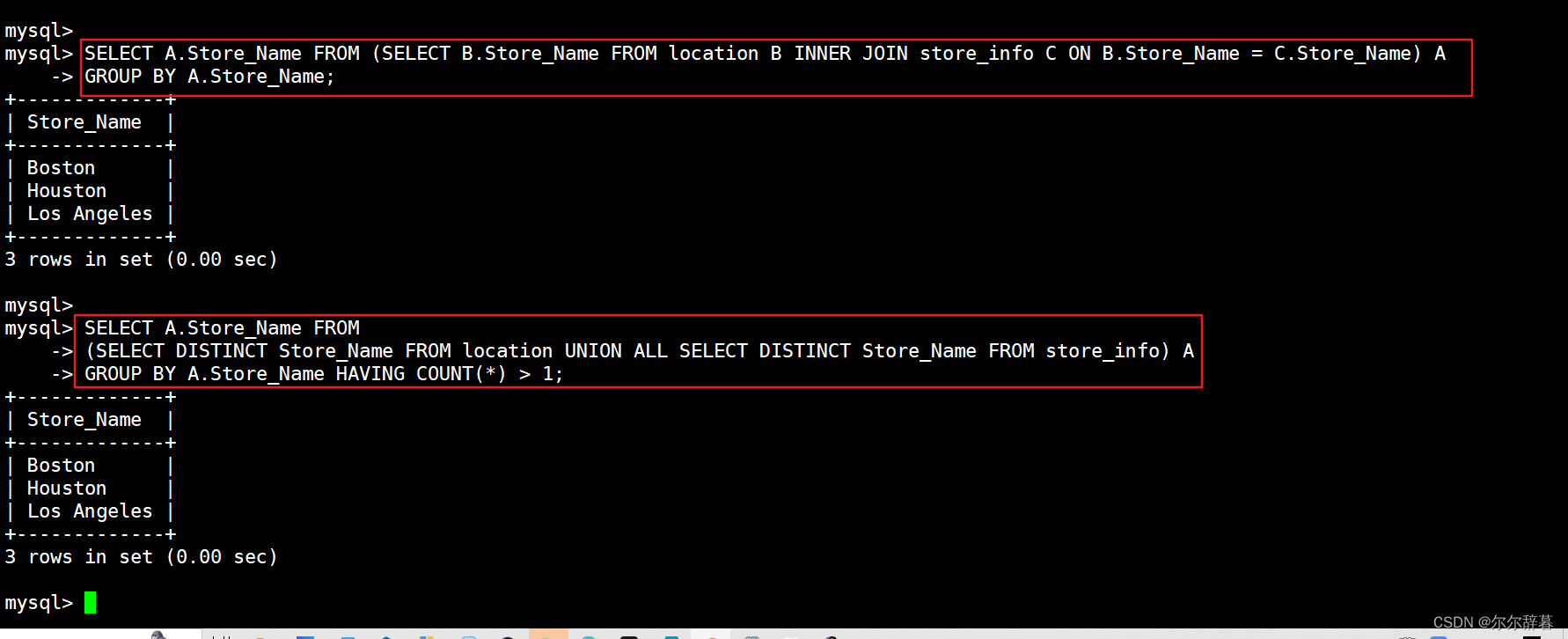
SELECT A.Store_Name FROM (SELECT B.Store_Name FROM location B INNER JOIN store_info C ON B.Store_Name = C.Store_Name) A
GROUP BY A.Store_Name;
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
2.2 无交集值
显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM store_info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NULL;
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A
GROUP BY A.Store_Name HAVING COUNT(*) = 1;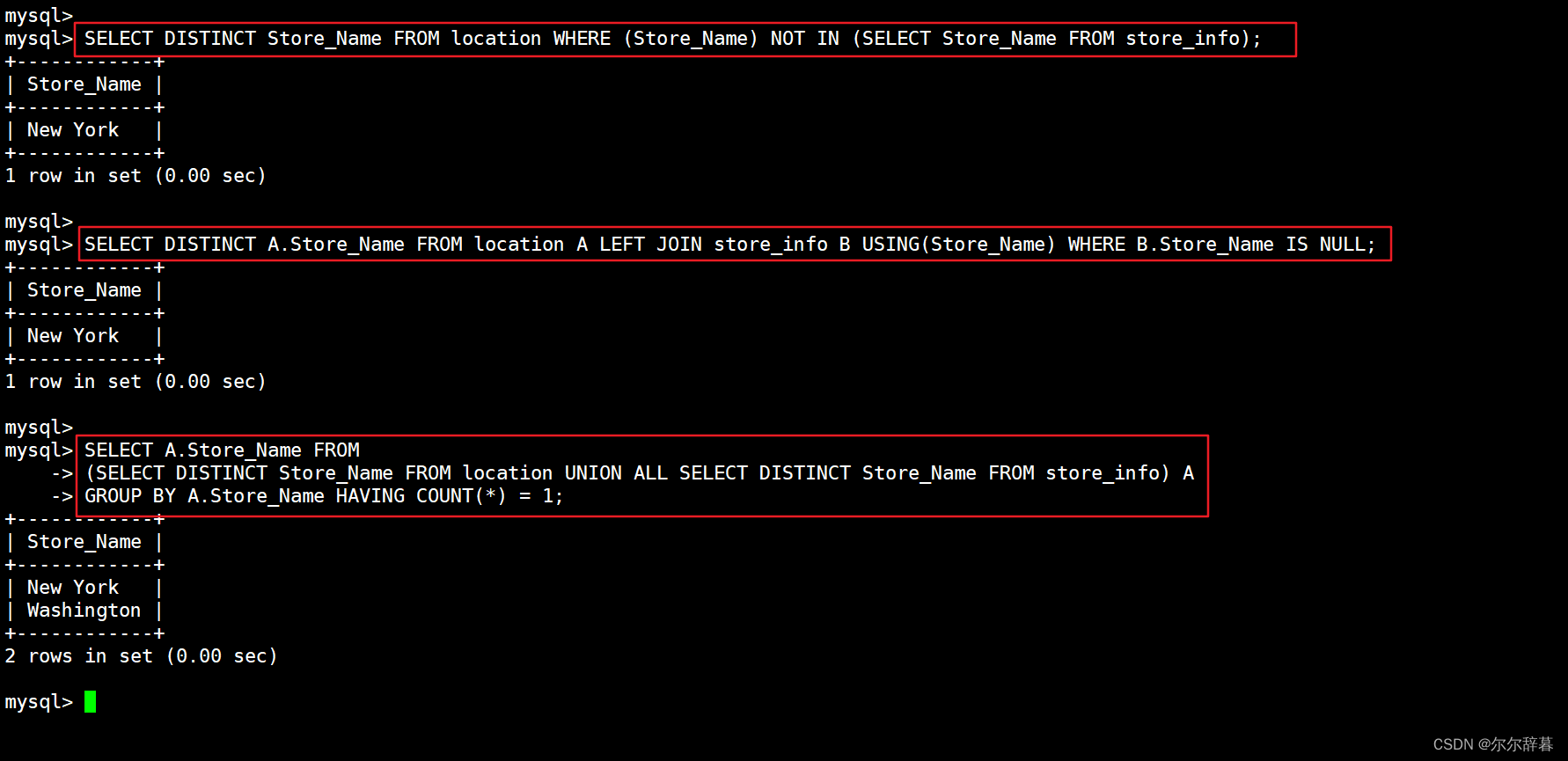
3 case
是 SQL 用来做为 IF-THEN-ELSE 之类逻辑的关键字
语法:
SELECT CASE ("字段名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
...
[ELSE "结果N"]
END
FROM "表名";# "条件" 可以是一个数值或是公式。 ELSE 子句则并不是必须的。
SELECT Store_Name, CASE Store_Name
WHEN 'Los Angeles' THEN Sales * 2
WHEN 'Boston' THEN 2000
ELSE Sales
END
"New Sales",Date
FROM store_info;
#"New Sales" 是用于 CASE 那个字段的字段名。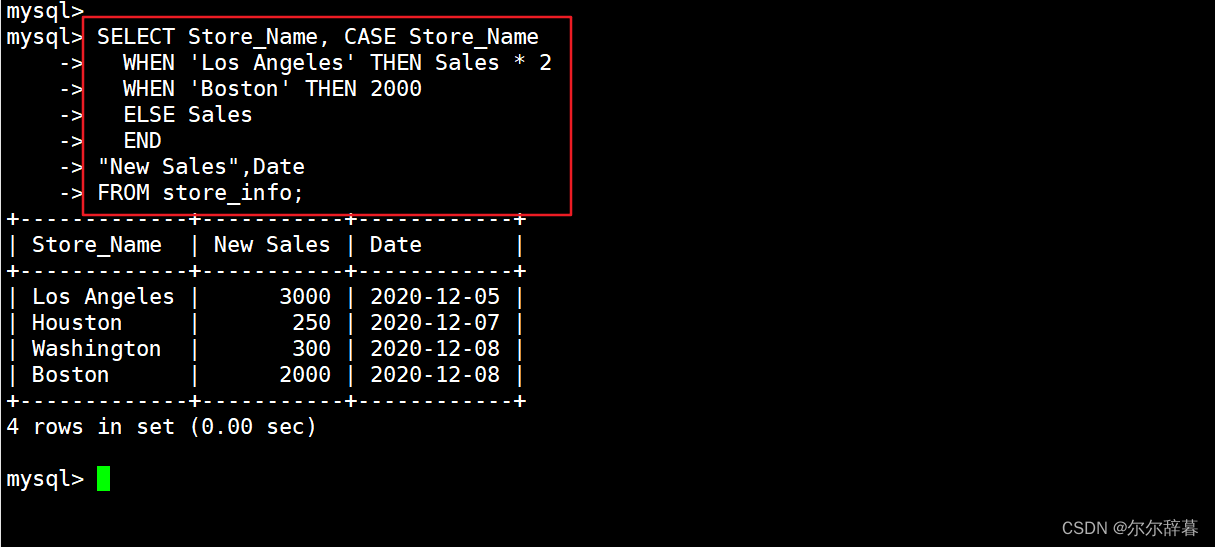
4 正则表达式
| 匹配模式 | 描述 | 实例 |
| ^ | 匹配文本的结束字符 | ‘^bd’ 匹配以 bd 开头的字符串 |
| $ | 匹配文本的结束字符 | ‘qn$’ 匹配以 qn 结尾的字符串 |
| . | 匹配任何单个字符 | ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
| * | 匹配零个或多个在它前面的字符 | ‘fo*t’ 匹配 t 前面有任意个 o |
| + | 匹配前面的字符 1 次或多次 | ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串 |
| 字符串 | 匹配包含指定的字符串 | ‘clo’ 匹配含有 clo 的字符串 |
| p1|p2 | 匹配 p1 或 p2 | ‘bg|fg’ 匹配 bg 或者 fg |
| [...] | 匹配字符集合中的任意一个字符 | ‘[abc]’ 匹配 a 或者 b 或者 c |
| [^...] | 匹配不在括号中的任何字符 | ‘[^ab]’ 匹配不包含 a 或者 b 的字符串 |
| {n} | 匹配前面的字符串 n 次 | ‘g{2}’ 匹配含有 2 个 g 的字符串 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 | ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次 |
语法:SELECT "字段" FROM "表名" WHERE "字段" REGEXP {模式};
SELECT * FROM store_info WHERE Store_Name REGEXP 'os';
SELECT * FROM store_info WHERE Store_Name REGEXP '^[A-G]';
SELECT * FROM store_info WHERE Store_Name REGEXP 'Ho|Bo';