文章目录
系列文章索引
Python爬虫基础(一):urllib库的使用详解
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据
Python爬虫基础(三):使用Selenium动态加载网页
Python爬虫基础(四):使用更方便的requests库
Python爬虫基础(五):使用scrapy框架
一、requests库的使用
requests 库是用Python语言编写,用于访问网络资源的第三方库,它基于urllib,但比 urllib更加简单、方便和人性化。通过requests库可以帮助实现自动爬取HTML网页页面以及模拟人类访问服务器自动提交网络请求。
使用起来注意与urllib进行比对。
1、官方文档
官方文档:
https://requests.readthedocs.io/projects/cn/zh_CN/latest/
快速上手:
https://requests.readthedocs.io/projects/cn/zh_CN/latest/user/quickstart.html
2、安装requests库
# 进入到python安装目录的Scripts目录
d:
cd D:\python\Scripts
# 安装
pip install requests -i https://pypi.douban.com/simple
3、简单使用
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)
# 一个类型和六个属性
# Response类型:<class 'requests.models.Response'>
print(type(response))
# 设置响应的编码格式
response.encoding = 'utf-8'
# 以字符串的形式来返回了网页的源码
print(response.text)
# 返回一个url地址
print(response.url)
# 返回的是二进制的数据
print(response.content)
# 返回响应的状态码
print(response.status_code)
# 返回的是响应头
print(response.headers)
4、使用get请求
总结:
(1)参数使用params传递
(2)参数无需urlencode编码
(3)不需要请求对象的定制
(4)请求资源路径中的问号?可以加也可以不加
import requests
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'wd':'北京'
}
# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)
5、使用post请求
总结:
(1)post请求 是不需要编解码
(2)post请求的参数是data
(3)不需要请求对象的定制
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'kw': 'eye'
}
# url 请求地址
# data 请求参数
# kwargs 字典
response = requests.post(url=url,data=data,headers=headers)
content =response.text
print(content)
import json
obj = json.loads(content)
print(obj)
6、使用代理
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
data = {
'wd':'ip'
}
proxy = {
'http':'212.129.251.55:16816'
}
response = requests.get(url = url,params=data,headers = headers,proxies = proxy)
content = response.text
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)
二、实战
1、实战:实现古诗文网的登录
(1)找到登录页面
进入古诗文网:https://www.gushiwen.cn/
点击【我的】,就进入了登录页面https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx:
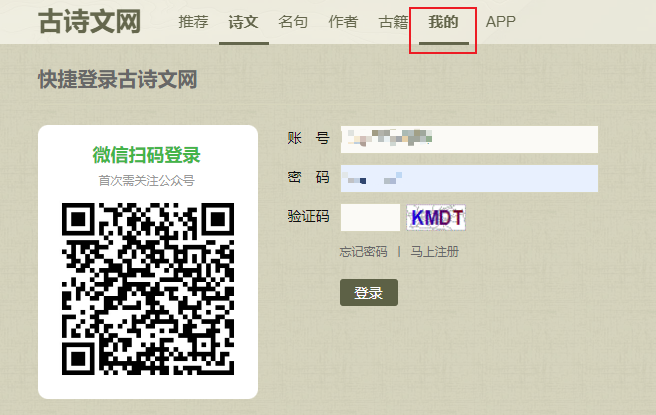
# 获取登录页的源码
import requests
# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 获取页面的源码
response = requests.get(url = url,headers = headers)
content = response.text
我们接下来需要做的就是,看这个网站进行登录操作,需要什么数据。
(2)登录操作需要的数据
我们输入错误的验证码,来判断调用登录接口需要的数据:
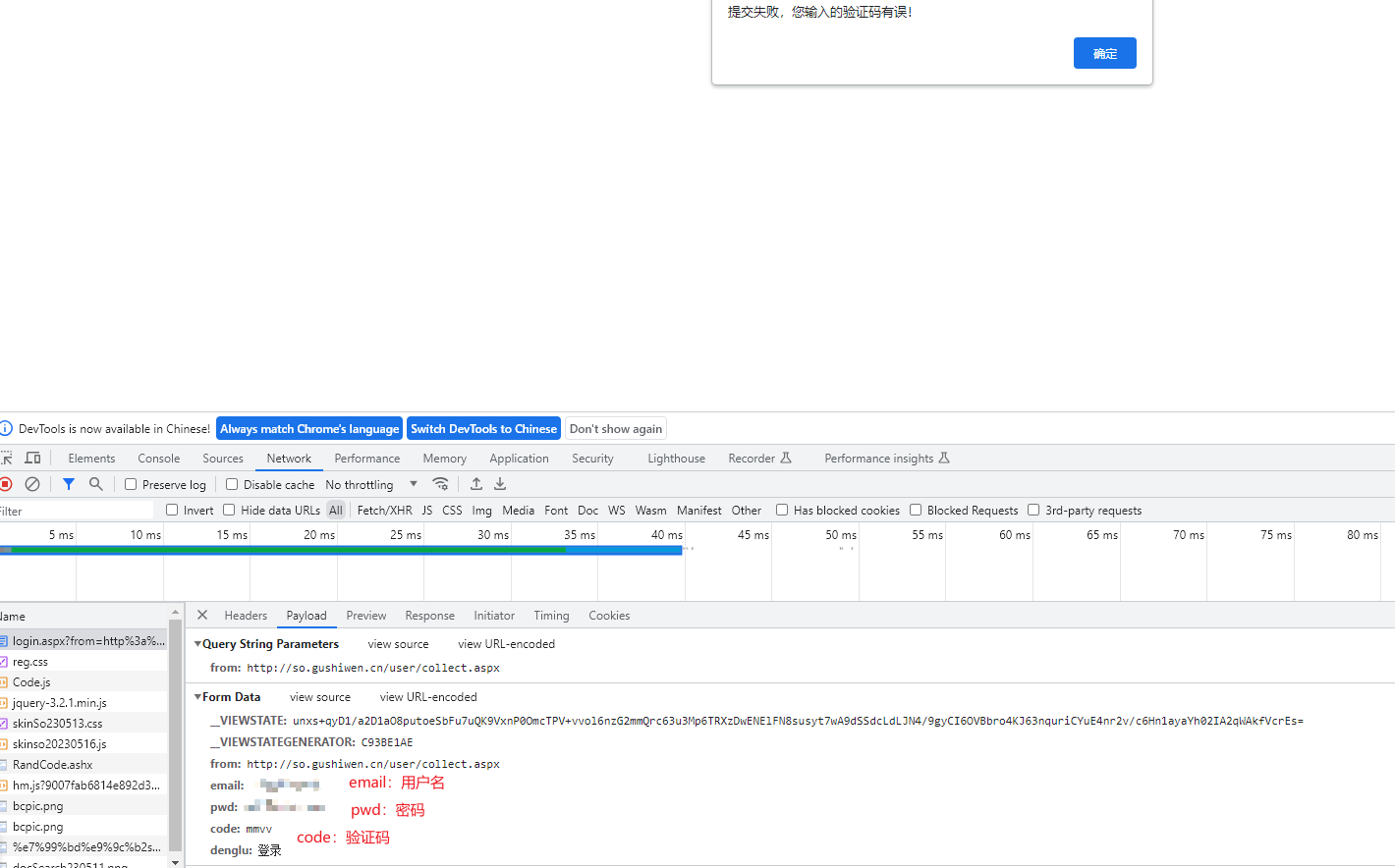
用户名密码和验证码我们都知道,这是登录必备的东西。
除此之外的from和denglu表单字段,看着也像是固定写死的。
但是,__VIEWSTATE 和__VIEWSTATEGENERATOR ,看着像是动态生成的,我们如何获取呢?
(3)获取隐藏域中的数据
我们右键->查看网页源代码,全局搜索,发现__VIEWSTATE 和__VIEWSTATEGENERATOR 是保存在页面隐藏域中的数据,一般情况看不到的数据 都是在页面的源码中,所以我们需要获取页面的源码 然后进行解析就可以获取了。

# 解析页面源码 然后获取_VIEWSTATE __VIEWSTATEGENERATOR
# 我们此处用bs4进行解析
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取_VIEWSTATE的值
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
print('获取__VIEWSTATE:' + viewstate)
# 获取__VIEWSTATEGENERATOR的值
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print('获取__VIEWSTATEGENERATOR:' + viewstategenerator)
(4)获取验证码图片
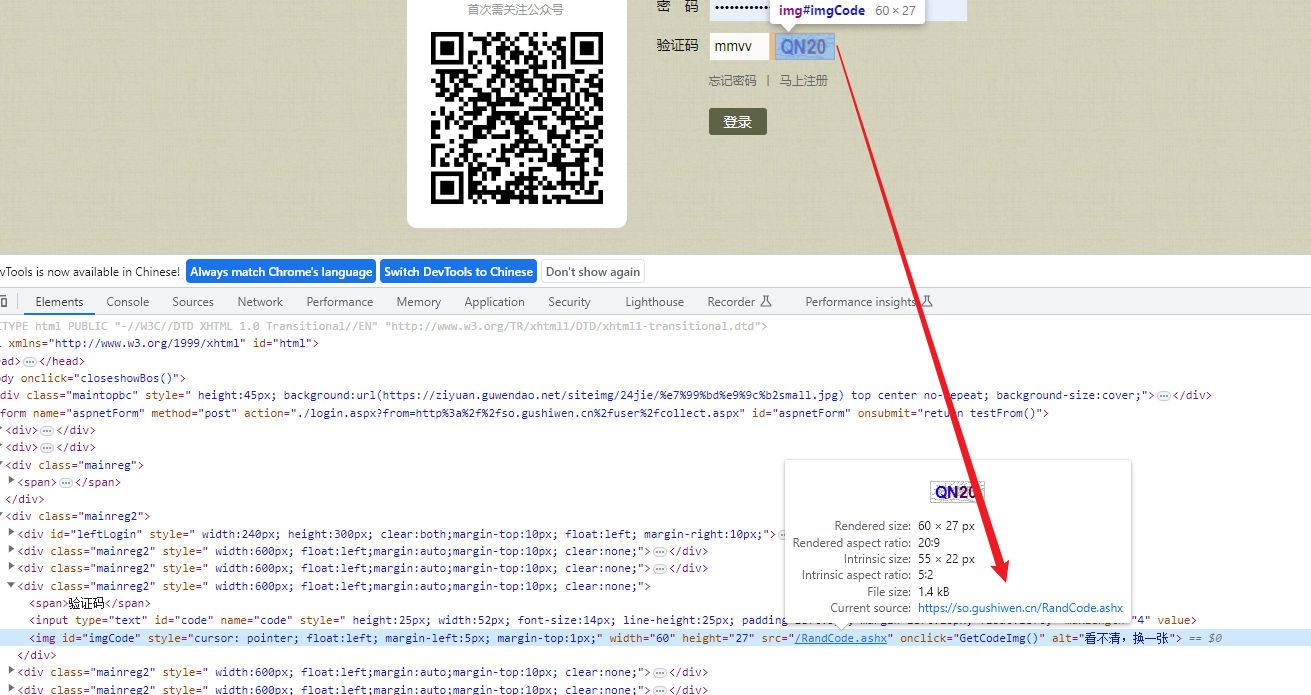
我们发现,该图片的地址就是:https://so.gushiwen.cn/RandCode.ashx,每次刷新都是不同的验证码图片。
此处我们获取验证码图片,不能通过request直接获取,因为要确保每次请求的session是相通的,所以我们需要通过session来获取验证码图片。
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 有坑,需要使用session进行验证码的获取
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# requests里面有一个方法 session() 通过session的返回值 就能使用请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 注意此时要使用二进制数据 因为我们要使用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg','wb')as fp:
fp.write(content_code)
# 获取了验证码的图片之后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码 就可以将这个值给
# code的参数 就可以登陆
code_name = input('请输入你的验证码')
将验证码保存到本地,登录的时候看一下验证码,然后进行输入。
(5)登录操作
获取到所有数据之后,拼装数据,调用登录接口post请求:
# 点击登陆
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '', # 用户名
'pwd': '', # 密码
'code': code_name,
'denglu': '登录',
}
response_post = session.post(url = url, headers = headers, data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding= ' utf-8')as fp:
fp.write(content_post)
(6)获取我的收藏
登录完毕之后,只需要使用同一个session,就可以获取到我的全部信息了。
# 获取我的收藏
collect_url = 'https://so.gushiwen.cn/user/collect.aspx?sort=t'
collect_info = session.get(url = collect_url)
collect_context = collect_info.text
with open('collect.html','w',encoding= ' utf-8')as fp:
fp.write(content_post)
2、实战:使用超级鹰验证码自动识别
(1)超级鹰官网
http://www.chaojiying.com/
价格:http://www.chaojiying.com/price.html
(2)下载
点击【开发文档】:http://www.chaojiying.com/api-14.html
下载完成之后,会有一个实例,只需要使用其API即可实现图像自动识别:
