最近,端到端的目标检测器因其出色的性能而受到研究界的广泛关注。然而,DETR通常依赖于在ImageNet上进行Backbone网络的监督预训练,这限制了DETR的实际应用和Backbone网络的设计,影响了模型的潜在泛化能力。
《DEYOv3: DETR with YOLO for Real-time Object Detection》提出了一种新的训练方法,称为分阶段训练。具体来说,在第一阶段,使用一对多预训练的YOLO检测器来初始化端到端检测器。在第二阶段,Backbone网络和编码器与DETR样式的模型保持一致,但只有检测器需要从头开始训练。由于这种训练方法,目标检测器不需要额外的数据集(ImageNet)来训练Backbone网络,使得Backbone网络的设计更加灵活,并大幅降低了检测器的训练成本,有助于目标检测器的实际应用。同时,与DETR样式的模型相比,分阶段训练方法可以实现比传统的DETR样式模型训练方法更高的准确性。代码据说会在Github开源。

1. 简介
目标检测是计算机视觉中的一个基本任务,旨在从图像或视频中准确地定位和识别多个不同类别的目标。目标检测是许多计算机视觉应用的基础,包括智能驾驶、视频监控、人脸识别、物体跟踪等。近年来,特别是基于卷积神经网络(CNN)的深度学习方法在目标检测任务中取得了显著进展,并成为主流技术手段。实时目标检测是目标检测中的一个重要主题,旨在实时场景中快速准确地检测和识别图像或视频中的目标。
与传统的目标检测方法相比,实时目标检测需要更快的处理速度和实时或接近实时地检测目标的能力。现有的实时检测器通常采用基于CNN的架构,这提供了准确性和速度之间的良好平衡。其中,实时检测器的代表之一是YOLO。经过多年的发展,YOLO已经发展成为一系列性能良好的快速模型。
传统的检测器通常需要使用NMS进行后处理。NMS的有效性可能受到选择的IoU阈值的影响,这可能导致检测结果出现显著变化。在拥挤的场景中,它可能成为经典检测器的性能瓶颈,并为实时检测引入推断延迟。DETR提出了一种创新的基于Transformer的目标检测器,它利用了Transformer编码器-解码器框架,消除了NMS的手动组件,而是利用匈牙利损失来预测一对一的目标集,实现端到端优化。
尽管近年来有许多工作来改进DETR,但高计算成本的问题仍然没有解决,限制了其实际应用和优势的利用。这意味着,尽管目标检测过程被简化了,但DETR模型的高计算成本使得实现实时目标检测具有挑战性。RT-DETR重新评估了DETR,在DETR编码器中减少了不必要的计算冗余,并提出了首个端到端目标检测器RT-DETR,充分利用了端到端检测管道的优势。
然而,DETR通常依赖于在ImageNet上对Backbone网络进行监督预训练,以及对Transformer编码器和解码器进行随机初始化。如果想使用新的Backbone网络,需要从ImageNet中选择预训练的Backbone网络。或者,在设计Backbone网络后,必须在训练DETR之前在ImageNet上进行预训练。这限制了Backbone网络的设计,并显著增加了训练成本。
此外,模型的性能和有效性严重依赖于用于预训练的数据集。如果当前任务的数据集与ImageNet差异显著,微调DETR可能无法充分适应特定任务,导致性能下降,限制了DETR的鲁棒性和泛化能力。为增强DETR模型的实用性,作者提出了一种称为分阶段训练的新训练方法。具体而言,在训练的第一阶段,作者使用YOLO进行一对多匹配的预训练。在训练的第二阶段,作者利用YOLO的Backbone网络和Neck初始化实时端到端检测器的Backbone网络和编码器,而解码器则是随机初始化的,用于微调一对一匹配。作者的训练不需要额外的数据集;只需要一个目标检测数据集来完成两个训练阶段。此外,由于第一阶段多尺度层的高质量一对多匹配预训练,与DETR训练方法相比,作者的方法在不影响推断时间的情况下实现了更高的准确性。
此外,作者提出了一种基于分阶段训练方法的全新实时目标检测模型DEYOv3。DEYOv3消除了对NMS的需求,确保检测器的推断速度保持不受影响且稳定。DEYOv3-N在COCO val2017上实现了41.1%的AP,并在NVIDIA Tesla T4 GPU上运行270 FPS,而DEYOv3-L实现了51.3%的AP和102 FPS。在没有使用额外训练数据的情况下,DEYOv3在速度和准确性方面均优于同等规模的实时检测器,成为实时目标检测的新SOTA。
本论文的主要贡献可以总结如下:
- 作者提出了一种新颖的训练方法,称为分阶段训练,适用于DETR模型。与传统的DETR训练方法相比,它消除了对额外数据集的预训练需求,并使模型能够实现更高的准确性。
- 利用分阶段训练,作者开发了DEYOv3,这是最先进的实时目标检测器。
- 作者进行了一系列消融实验,对DEYOv3进行了全面分析,并讨论了它作为未来大规模目标检测模型可行设计方法的潜力。
2. 分阶段训练
由于DETR在直接预测一对一目标集合时采用了匈牙利匹配,以及DETR解码器的复杂度与序列长度之间的二次关系,DETR实现的Query数量比传统检测器低了几个数量级。作者认为,这种情况导致了DETR在训练时的监督信号相对较少,使得从头开始训练变得具有挑战性,并因此高度依赖于ImageNet的Backbone网络预训练。此外,ImageNet预训练的多尺度层次并未针对目标检测任务进行有效的预训练。
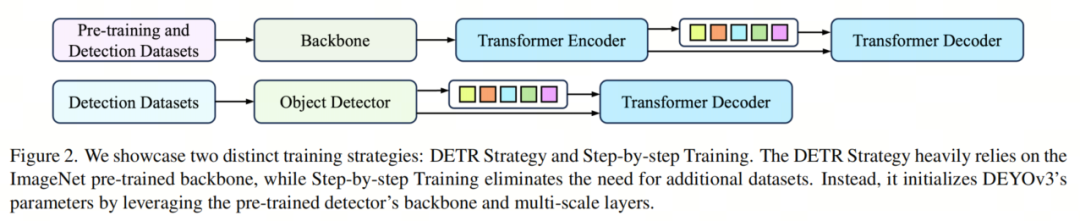
图2. 我们展示了两种不同的训练策略:DETR策略和逐步训练。DETR策略在很大程度上依赖于ImageNet预训练的骨干网络,而逐步训练则消除了对额外数据集的需求。相反,它通过利用预训练检测器的骨干网络和多尺度层来初始化DEYOv3的参
为了解决这些问题,作者将DETR的训练过程分为两个阶段。通过广泛的工程测试,计算机视觉社区已经全面验证了YOLO的通用性和实用性。这些评估包括在各种实际情况下测试和评估YOLO,以评估其在不同数据集、目标类别和环境条件下的性能。基于这些广泛的工程测试,作者相信,即使在不使用额外数据集的情况下,YOLO仍然可以在处理复杂场景、多目标检测和实时应用方面表现良好,同时具有出色的泛化性能和实用性。
毫无疑问,从头开始训练YOLO是其训练策略的最佳选择。因此,在训练的第一阶段,作者首先训练一个强大的YOLO目标检测模型,为DEYOv3模型的Backbone网络和多尺度层次提供高质量的预训练。由于一对多匹配和YOLO提供数千个Query的能力,大量的监督信号使网络能够学习丰富的特征表示,从而为训练的第二阶段提供更好的初始特征表达能力。
由于第一阶段为DEYOv3模型的Backbone网络和Neck提供了高质量的预训练,所以在训练的第二阶段,只需从头开始训练解码器,进一步加快了模型的收敛速度。此外,与在ImageNet上预训练的多尺度层次相比,第一阶段中预训练的Neck可以提供更高质量的特征。与DETR的传统训练方法相比,作者的训练策略使作者的模型表现更好。
3. DEYOv3
3.1 模型概述
基于Ultralytics的未发布的yolov8-rtdetr,作者构建了DEYOv3模型。由于YOLO和DETR共享相同的Backbone网络和Neck结构,因此可以轻松地以一种轻量级的方式呈现用于实时目标检测的DEYO范例。
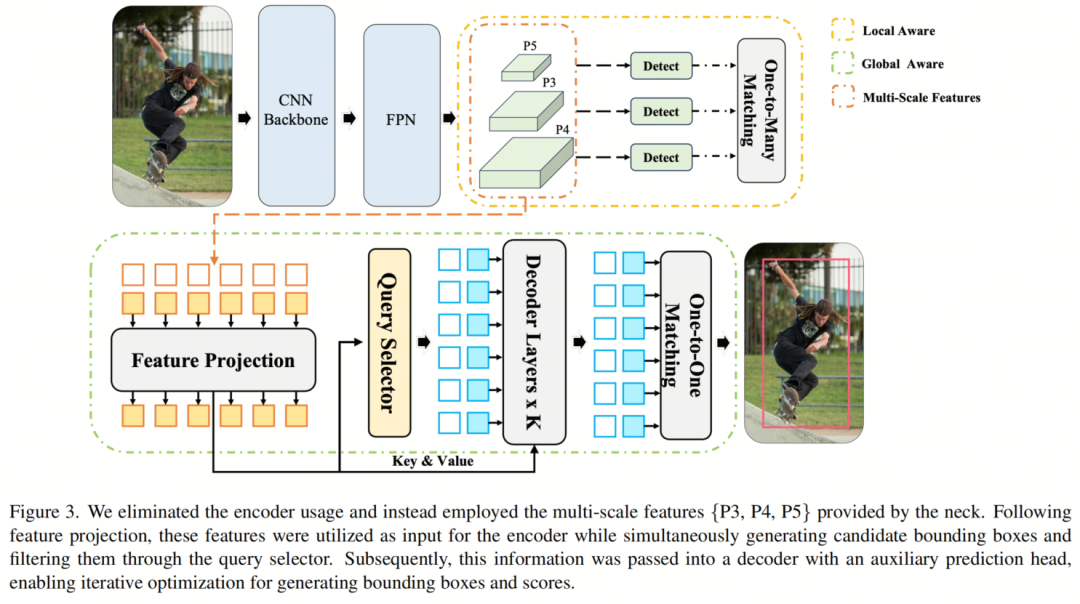
图3展示了DEYOv3的总体结构。DEYOv3使用YOLOv8作为模型的一对多分支。YOLOv8是Ultralytics引入的YOLOv5的改进版本,包括一个Backbone网络,由FPN和PAN组成的Neck结构,以及在三个尺度上输出预测结果的头部。
DEYOv3的一对一分支采用了类似于 DINO的解码器 ,不同于以前的DEYO模型,它不像DETR那样使用Transformer作为编码器。相反,它使用 简单的Neck结构和特征投影方法对多尺度特征进行编码。特征投影的结构很简单,由一个简单的1x1卷积组成。这个设计使DEYOv3在编码阶段更加轻量级,提高了模型的运行效率。
此外,DEYOv3的解码器采用静态Query和动态初始化方法来生成Anchor边界框。此外,DEYOv3引入了额外的CDN(对比去噪训练)分支。
3.2 一对多分支
DEYOv3采用YOLOv8作为模型的一对多分支,以适应作者的分阶段训练方法。YOLOv8建立在之前YOLO版本的成功基础上,引入了新的功能和改进,以提高性能和灵活性。YOLOv8的 三个多尺度层为一对一分支提供了多达8400个Query ,这些Query可以用于生成Proposals边界框,并用作解码器的Key和Value。
与DETR不同,YOLO受益于一对多训练方法,这使得这些Query在第一阶段训练期间可以更彻底地受到监督。因此,强大的Neck经过训练,为解码器提供多尺度信息,使模型能够实现更好的性能。
3.3 高效编码器
DEYOv3的编码器与DETR不同,它不使用Transformer作为编码器。相反,DEYOv3在第一阶段利用YOLO的预训练Neck来对多尺度特征进行编码,然后将其馈送到特征投影中,以将它们与隐藏维度对齐。
在广义上,整个Neck和特征投影 可以被视为DEYOv3的编码器。这种实现与作者的分阶段训练方法非常吻合。由于在第一阶段高效预训练期间获得的丰富特征,这些特征可以为第二阶段的编码器提供高质量的Key、Value和Proposals边界框信息。因此,编码器在保持性能的同时实现了卓越的速度。作者可以如下描述这个过程:
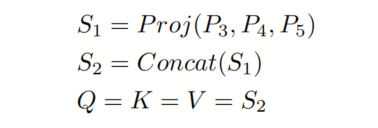
3.4 一对一分支
DEYOv3的解码器采用与DETR类似的架构,利用Transformer中的自注意力来捕获不同Query之间的关系,从而建立分数差异以抑制冗余的边界框。在解码器的每个Level中,逐渐改进Query,从而形成一对一的目标集合。这个设计极大地简化了DEYOv3中的目标检测过程,并且不再依赖NMS。
此外,由于第一阶段训练提供的高质量初始化,即使在一对一分支中仅监督了数百个Query,模型也可以迅速收敛并实现更好的性能。
