拿到一个目标检测算法,想用这个算法训练自己的数据集怎么办?这时就要把自己的数据集进行包装,找到一个模板把自己的数据套进去,训练的时候就可以免去一些自定义过程。本文将介绍的模板是
PASVAL VOC2007。
了解PASCAL VOC数据集的格式
1.Annotations
存放xml格式的标签文件,xml文件中存放了标定框的位置、大小、类别等信息,标定是个机械苦力活。
2.ImageSets
Action: 存放人体的动作数据,用不着。
Layout: 存放人体的部位数据,用不着。
Main: 存放目标检测的数据,是一些txt文件,后面我们会生成这些文件,把数据集分成训练集、验证集和测试集。
Segmentation: 存放图像分割的数据,用不着。
3.JPEGImages
存放jpg文件,就是我们的图片数据,训练集和测试集都在里面。
还有两个文件夹:SegmentationClass和SegmentationObject,都是图像分割用到的,这里不进行介绍。
开始制作数据集
制成的数据集长啥样?我们先一睹为快:
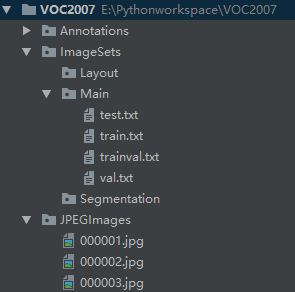
如果已经有VOC数据,可以拷贝一份然后把对应文件夹的数据删除,或者自己按上图建好文件夹(Layout和Segmentation这两个文件夹可以不新建)。
第一步:重命名jpg图片文件
手上有很多数据,可能命名都是杂乱无章的,需要对这些文件重新命名,排好序。
不多说,直接上代码:
# -*- coding:utf8 -*-
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
# 我的图片文件夹路径
self.path = 'E:/Pythonworkspace/datas/tfclight'
def rename(self):
filelist = os.listdir(self.path)
total_num = len(filelist)
i = 1 # 设置第一个文件名
n = 6 # 设置文件名长度,如000001,长度为6
for item in filelist:
# 这里修改的是jpg文件,如果要修改其他类型的文件,请手动将下面两个'.jpg'修改为对应的文件后缀
if item.endswith('.jpg'):
n = 6 - len(str(i))
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), str(0) * n + str(i) + '.jpg')
try:
os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
然后把得到的图片放到JPEGImages文件夹中。如果有新的数据,修改i的值就行了。比如之前的数据集有5000张,最后一张命名为’005000.jpg’,把i改为5001,那么新增数据集的第一张命名为’005001.jpg’,无缝连接。当然path值也不要忘了修改。
第二步:生成xml标签文件
这一步老老实实标定就行了,推荐一个大佬的标定工具:labelImg,在github上面已经有10k星星了。标定时把保存文件夹设为Annotations。
第三步:搞定Main文件夹
现在我们有了jpg文件和xml文件,接下来要把数据分为训练集、验证集和测试集:
import os
import random
trainval_percent = 0.7 # 训练集和验证集 占 数据集 的比例
train_percent = 0.6 # 训练集 占 训练集和验证集 的比例
# 把xml路径修改为自己的Annotations文件夹路径
xmlfilepath = 'E:/Pythonworkspace/VOC2007/Annotations'
# 把保存路径修改为自己的Main文件夹路径
savepath = 'E:/Pythonworkspace/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(savepath + '/trainval.txt', 'w')
ftest = open(savepath + '/test.txt', 'w')
ftrain = open(savepath + '/train.txt', 'w')
fval = open(savepath + '/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
到这里就大功告成了。
一个辅助工具
这是一个修改xml文件的辅助工具,用到这个工具的可能情况有:标定时图片数据不在JPEGImage文件夹中、标定时不小心把class_name写错了(比如我把部分类别为green light标定成了greeen light)、想改变类别名(比如把类别为黄种人、白种人、黑种人的标签全改为人):
# coding=utf-8
import xml.dom.minidom
import os.path
i = 1 # 第一个文件命,如'000001.xml'
xmldir = "E:/Pythonworkspace/VOC2007/Annotations"
imgsdir = "E:/Pythonworkspace/VOC2007/JPEGImages"
for xmlfile in os.listdir(xmldir):
xmlname = os.path.splitext(xmlfile)[0]
for pngfile in os.listdir(imgsdir):
pngname = os.path.splitext(pngfile)[0]
if pngname == xmlname:
# 修改filename结点属性
# 读取xml文件
dom = xml.dom.minidom.parse(os.path.join(xmldir, xmlfile))
root = dom.documentElement
n = 6-len(str(i))
# 获取标签对filename之间的值并赋予新值i
root.getElementsByTagName('filename')[0].firstChild.data = str(0)*n + str(i) + '.jpg' #修改文件名
root.getElementsByTagName('folder')[0].firstChild.data = 'VOC2007' #修改文件夹名
root.getElementsByTagName('path')[0].firstChild.data = '/home/zmh/SSD_double/datasets/VOC2007/JPEGImages/' + str(0)*n + str(i) + '.jpg' #修改图片路径名
if root.getElementsByTagName('name')[0].firstChild.data == 'greeen light': #修改标签名
root.getElementsByTagName('name')[0].firstChild.data = 'green light'
# 将修改后的xml文件保存
# xml文件修改前后的路径
old_xmldir = os.path.join(xmldir, xmlfile)
new_xmldir = os.path.join(xmldir, str(0)*n + str(i) + '.xml')
# 打开并写入
with open(old_xmldir, 'w') as fh:
dom.writexml(fh)
os.rename(old_xmldir, new_xmldir)
i += 1
print('total number is ', i - 1)
参考博客:VOC2007数据集制作
有问题欢迎在评论区留言,本人水平有限,有错误欢迎指正。