课外作业七:Spark
- 作业详情
内容
一、阿里云实验《基于EMR离线数据分析》: 基于EMR离线数据分析 - 云起实验室-在线实验-上云实践-阿里云开发者社区-阿里云官方实验平台-阿里云 步骤2.登录集群,启动spark shell。或者在自己的虚机上安装配置Spark-3.1.3伪分布式。 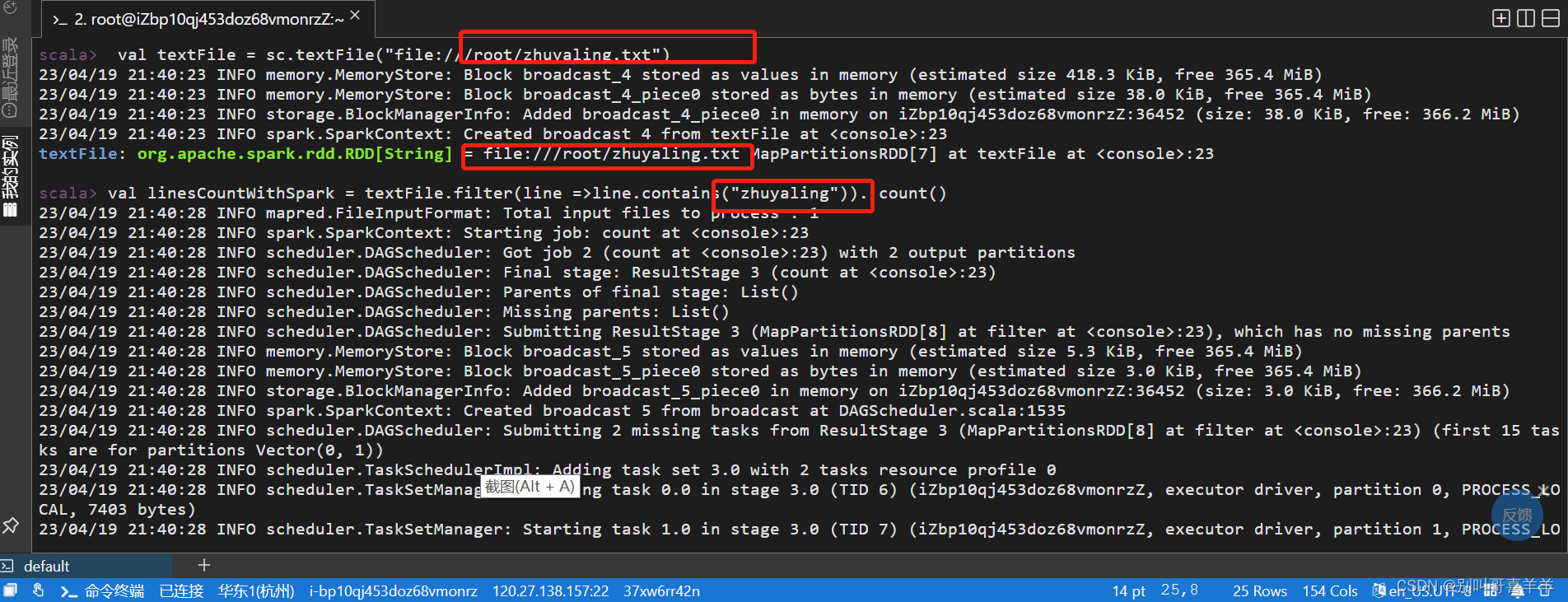
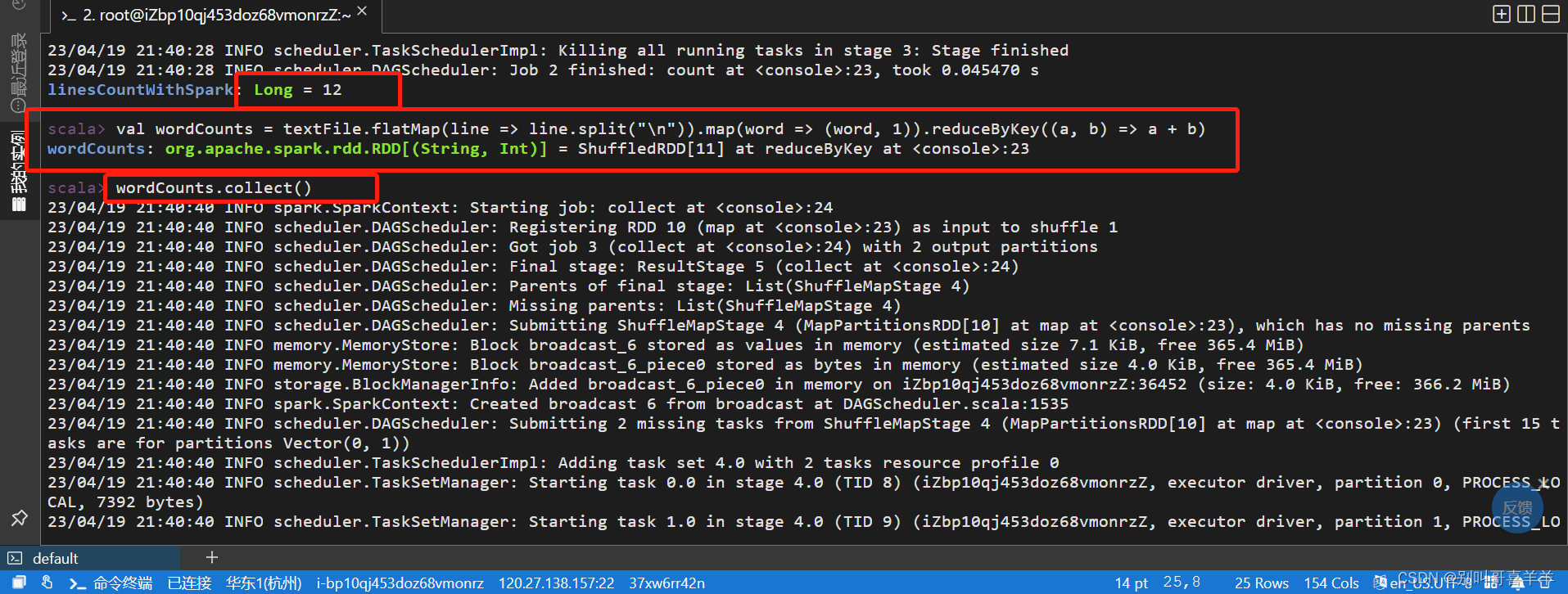
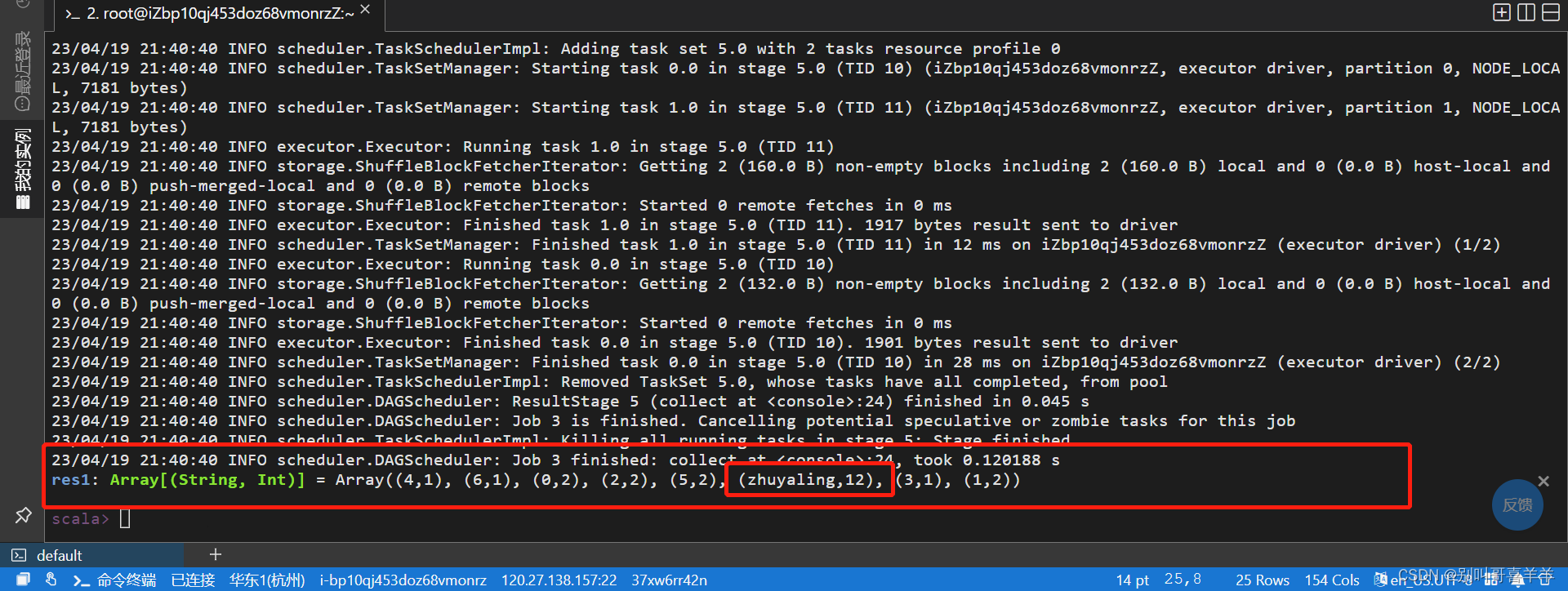 实验要求: 参考教材10.5.2,创建本地文件,文件名为自己姓名.txt,文件内容除了其他文字,加入多个自己姓名字符串。
实验要求: 参考教材10.5.2,创建本地文件,文件名为自己姓名.txt,文件内容除了其他文字,加入多个自己姓名字符串。
统计带有姓名字符串的行数,截图运行结果。 基于自己姓名.txt文件做词频统计,截图运行结果。
二、华为云实验 《Spark统计分析实验》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 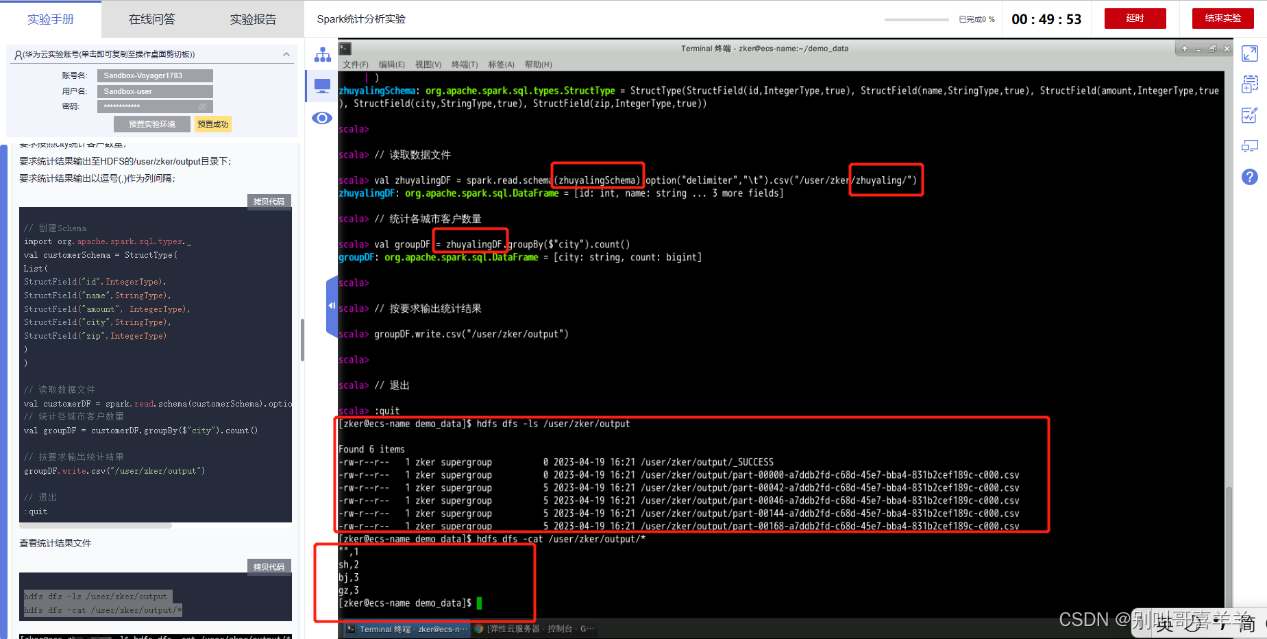 《基于Spark的关联分析KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 统计带有姓名字符串的行数,截图运行结果。
《基于Spark的关联分析KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 统计带有姓名字符串的行数,截图运行结果。 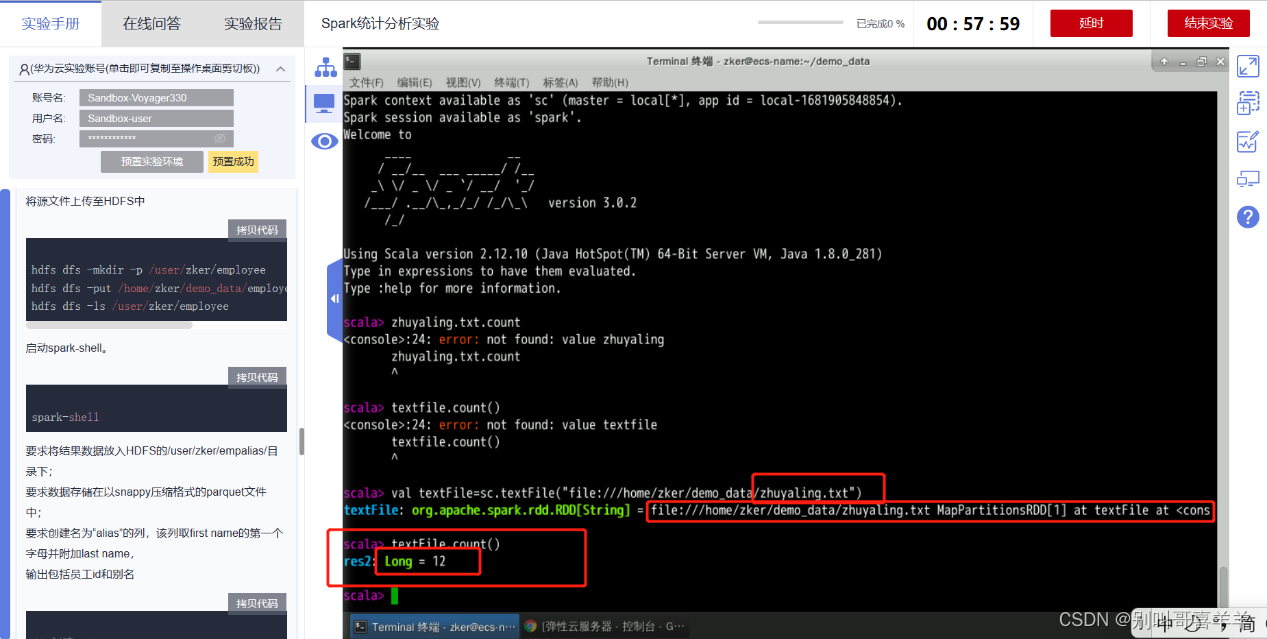 《Spark SQL数据分析实验》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云
《Spark SQL数据分析实验》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 3、 简要回答“课堂考核”内容 1、Spark RDD是什么? Spark RDD是Spark的基本抽象概念,代表弹性分布式数据集。它是一个容错、并行的数据结构,可以在集群中分布式地存储和处理大规模数据集。
3、 简要回答“课堂考核”内容 1、Spark RDD是什么? Spark RDD是Spark的基本抽象概念,代表弹性分布式数据集。它是一个容错、并行的数据结构,可以在集群中分布式地存储和处理大规模数据集。
2、数据导入RDD是哪个?数据从哪里导入? 要将数据导入RDD,可以使用SparkContext的textFile()方法。数据可以从本地文件系统或Hadoop Distributed File System (HDFS)中导入。
3、从HDFS导入数据,程序应该怎么修改? 要从HDFS导入数据,只需要将文件路径改为HDFS中的路径,比如hdfs://namenode:port/path/to/file。
4、创建一个数据表,从表里导入数据,程序应该怎么修改? 要创建一个数据表并从表中导入数据,可以使用Spark SQL的createOrReplaceTempView()方法创建一个临时表。然后使用Spark SQL的select语句从表中选择数据。
5、实验用了哪些转换操作?作用是什么? 实验中使用了多个转换操作,包括map、filter、flatMap、union、distinct、groupByKey、reduceByKey等。这些操作用于对Spark RDD进行数据转换和处理,例如从RDD中选择特定的数据、按键聚合数据等。
6、实验用了哪些行动操作?作用是什么? 实验中使用了多个行动操作,包括count、take、collect、foreach等。这些操作会触发Spark计算引擎对RDD进行计算并返回结果,例如返回RDD中元素数量、返回RDD中的前几个元素等。
四、10.7 习题

1、Spark是基于内存计算的大数据计算平台,试述Spark的主要特点 (1)快速计算:Spark的内存计算技术可以极大地提高数据处理和分析的速度。 (2)多语言支持:Spark支持Java、Scala、Python和R等多种编程语言,方便开发者使用熟悉的语言进行编程。 (3)支持多种数据源:Spark可以读取和处理多种类型的数据源,包括Hadoop Distributed File System(HDFS)、Cassandra、HBase和Amazon S3等。 (4)易于使用:Spark提供了易于使用的高级API,如Spark SQL、DataFrame API和MLlib机器学习库,使得开发者可以更加方便地进行数据分析和机器学习任务。 (5)扩展性:Spark支持在集群中添加更多的节点,以扩展系统的规模,从而处理更大规模的数据集。
2、Spark的出现是为了解决Hadoop MapReduce的不足,试列举Hadoop MapReduce的几个缺陷,并说明Spark具备那些优点。 Hadoop MapReduce的几个缺陷包括: (1)低效性:Hadoop MapReduce主要是基于磁盘的数据读写,因此在处理大数据时会受到磁盘I/O速度的限制,导致效率较低。 (2)不支持迭代式计算:Hadoop MapReduce处理完一次任务后需要将结果存储到磁盘上,然后从磁盘上重新读取数据进行下一次计算,这种方式不适合迭代式计算,例如机器学习中的迭代式算法。 (3)不适合实时计算:Hadoop MapReduce一般是批处理,不太适合实时计算场景,例如金融交易实时监控。 Spark相对于Hadoop MapReduce有以下优点 (1)更高的性能:Spark使用内存计算技术,数据读写速度更快,可以提供比Hadoop MapReduce更高的性能和响应速度。 (2)支持迭代式计算:Spark采用RDD(Resilient Distributed Datasets)模型实现数据分布式处理,支持迭代式计算,从而适用于机器学习等迭代计算场景。 (3)支持实时计算:Spark提供了流式处理引擎Spark Streaming,可以支持实时计算,例如金融交易监控、网络安全攻击监测等场景。 (4)更简洁的API:Spark提供了Scala、Java和Python等多种编程语言的API,而且相对于Hadoop MapReduce,Spark的API更加简洁易用,开发人员可以更快速地开发出复杂的分布式应用程序。 (5)更多的应用场景:除了批处理,Spark还可以用于图计算、SQL处理及机器学习等应用场景,具有更丰富的用途和更广泛的适用范围。
3、美国加州大学伯克利分校提出数据分析的软件栈BDAS认为目前的大数据处理可以分为哪三种类型。 (1)批处理(Batch Processing):将海量数据拆分成小份进行处理,适用于大量数据离线处理。 (2)流处理(Stream Processing):将数据推送进来后实时的处理,适用于实时性要求高的场景。 (3)交互式查询(Interactive Querying):基于用户的查询动态返回结果,适用于用户对数据查询的及时性要求高的场景。 4、Spark已打造出结构一体化,功能多样化的大数据生态系统,试述Spark的生态系统。 Spark Core:Spark的核心组件,提供统一的内存计算引擎,支持数据处理和转换。 Spark SQL:提供结构化数据处理和SQL查询等功能,让开发人员可以使用SQL语句来查询和分析数据。 Spark Streaming:支持实时数据处理,包括流式数据输入、处理和输出等功能,可与Kafka、Flume等消息队列集成。 MLlib:Spark的机器学习库,提供常用的机器学习算法和工具,如分类、聚类、回归、协同过滤等。 GraphX:Spark的图计算框架,支持大规模图数据处理和分析。 SparkR:提供R语言开发者使用Spark的接口和工具。 Tungsten:Spark的内存管理和优化模块,可显著提高Spark性能。 PySpark:提供Python语言开发者使用Spark的接口和工具。 Spark Job Server:为Spark作业提供RESTful API,便于在分布式环境中部署和管理Spark应用程序。 Zeppelin:数据可视化和交互式笔记本工具,可支持多种编程语言,包括Scala、Python、R等。 综上所述,Spark的生态系统涵盖了大数据与机器学习、流处理、图计算等多个领域,提供了非常丰富的组件和工具,让数据分析人员可以更加高效地开发和运行大规模分布式数据应用。
5.从Hadoop+Storm架构转向Spark架构可带来那些好处 更快的处理速度:与Hadoop相比,Spark能在内存中运行任务,从而更快地处理数据。 更容易使用:相比于Storm,Spark提供了更简单、更易用的API,使得开发人员可以更快地编写和运行大规模数据处理任务。 更高的可靠性:Spark的任务可以在不同节点上同时执行,因此即使出现了节点故障,也不会影响整个任务的执行。 更丰富的生态系统:与Hadoop和Storm相比,Spark拥有更丰富的生态系统,支持更多的数据源和工具,使得开发人员可以更加高效地进行数据处理和分析。 更好的实时处理能力:相比于Hadoop和Storm,Spark更适合进行实时数据处理,能够更快地处理流数据并实时生成结果。 综上所述,通过从Hadoop+Storm架构转向Spark架构,可以带来更快、更可靠、更易用、更丰富的数据处理能力,提高了大数据处理的效率和质量。
6、试述Spark on YARN的概念 Spark on YARN是指将Spark应用程序部署到基于YARN的Hadoop集群上运行的方式。在这种模式下,Spark作为YARN应用程序运行,可以与YARN资源管理器配合使用来管理集群资源并进行任务调度。 具体来说,Spark on YARN通常会使用以下组件: 客户端:负责提交Spark作业到YARN集群。 Driver:在YARN集群中启动Spark应用程序的驱动程序,负责协调任务和管理各个执行器。 执行器(Executors):在YARN节点上启动的进程,负责执行Spark任务中的具体计算,并返回结果给驱动程序。 应用程序主管(Application Master):在启动Spark应用程序时,会为该应用程序创建一个应用程序主管,在YARN集群中启动该应用程序并管理执行器。 工作者(Worker):在YARN节点上启动的进程,用于接受任务调度并执行具体的Spark操作。 资源管理器(Resource Manager):YARN的核心组件之一,负责管理集群资源、协调各个应用程序的资源分配及调度。 在Spark on YARN中,Spark作为YARN的一种应用程序运行,可以充分利用YARN资源管理和任务调度的优势,同时也遵循了Hadoop开发和管理的标准流程。使用Spark on YARN可以使得Spark应用程序能够更加高效地利用Hadoop集群的资源,从而提高大数据处理的效率和质量。
7、试述如下Spark的几个概念:RDD,DAG,阶段,分区,窄依赖,宽依赖 RDD(弹性分布式数据集,Resilient Distributed Dataset):是Spark中最基本的抽象,它是一个不可变的分布式集合,可以被并行地处理。RDD代表着将数据划分成很多片段(Partition),每个片段可以被同一台或不同的计算机节点处理。 DAG(有向无环图,Directed Acyclic Graph):在Spark中,每个RDD都会形成一个DAG,代表了一个数据处理的逻辑流程,由若干个RDD和其之间的依赖关系构成,其中每个RDD是一个节点。 阶段(Stage):DAG中的每个RDD都可以划分为若干个阶段,每个阶段包含了一组相互依赖的RDD。 分区(Partition):是指RDD中的数据按照特定的规则分布在不同的节点上,每个节点处理自己负责的数据部分。 窄依赖(Narrow Dependency):指在DAG中,子节点只依赖于父节点的某些分区数据的情况。这种依赖关系允许Spark以并行的方式执行计算任务。 宽依赖(Wide Dependency):指在DAG中,子节点依赖于父节点的全部或大部分数据的情况。这种依赖关系会导致Spark的计算任务需要等待所有父节点全部完成才能开始,并且可能导致数据倾斜或网络瓶颈等问题。
8、Spark对RDD的操作主要分为行动和转换两种类型,两种操作的区别是什么。 Spark对RDD的操作主要分为行动操作和转换操作两种类型。 其中,转换操作(Transformation)是一类“惰性”的操作,即它们仅记录应该如何计算(而没有实际计算),只有当行动操作调用时才会真正执行计算。转换操作可以返回一个新的RDD,但原有的RDD并不会改变。 而行动操作(Action)是一类实际触发计算的操作,该操作将触发整个DAG的计算,并可能在控制台等输出介质上返回结果。行动操作通常会导致Spark作业的执行。 简单来说,转换操作用于定义数据处理流程,而行动操作会开始执行这些操作并返回最终结果。通过这种方式,Spark可以在避免中间数据生成的同时,可以对数据进行高效的处理和计算。