
论文地址:Language Models are Few-Shot Learners
往期相关文章:
本文的标题之所以取名技术报告而不是论文,是因为长达63页的GPT-3的这篇文章它不是一个发表的论文,而是一份报告,文中也没有针对模型的结构和整个训练过程的细节介绍,基本上都是在讨论,因此本博客也只挑一些个人觉得值得关注的点介绍一下。
Abstract

回顾一下GPT-1和GPT-2,GPT-1中主要用到了改变输入样式的方式让模型学会执行不同任务,GPT-2作者通篇在强调零样本学习,放弃用在输入中加入特殊符号区分不同任务的做法,改用纯自然语言输入的方式执行不同的任务,而在GPT-3中,作者又不再强调零样本的事了,也认为依靠大量的标注数据进行任务相关的微调不是个好主意,因为作者提到,人类对于新的任务的学习,往往只需要少量的样本就能学到新知识,估计作者认为也不能一个样本都不给,因此,作者想到了一个few-shot的方法,牛掰!当然也提到了one-shot的方法,这个后面会说。摘要中作者主要说明了他们开发出一个包含1750亿个参数的GPT-3,比之前非稀疏的模型大10倍,为啥是非稀疏的,因为稀疏模型的权重存在很多0,会导致模型虚大,所以 没有对比意义。其次,作者发现GPT-3生成的新闻文本连人类都难以分辨真假是不是人写的。
1. Instruct

接下来,作者提到了目前对于语言模型训练的范式,就是在一个任务无关的数据集上预训练,再在特定任务数据集上做微调,但是这种范式存在很大的问题,就是这样训练模型仍然需要大量的标注数据去做微调,具体地,作者列出了3个问题:


总结来说,主要是3个方面的问题:
- 标注数据集的依赖,即模型的训练需要大量的标注数据,这是十分困难的;
- 在微调模型表现的好不见得是因为预训练模型泛化能力强,有可能是因为预训练使用的大批量数据涵盖了微调数据的信息,如果微调的数据在预训练中没有相应的分布,那么模型的表现可能就变差了。
- 人类在学习某个新的任务时,往往不需要有大量的例子进行辅助,比如让你认识猫,那么其实给你几只猫的样子,后期不管什么颜色什么品种的猫,你都大概率能区分出它是只猫。而GPT-3就想类比人类学习的过程,认为模型也不需要大量的任务相关的例子来学习,这就是few-shot。


为了解决上述的问题,作者也提出了他们的思路,这一段中作者提到了一个比较新的名词,叫元学习(meta-learning),还提到了“in-context learning”,这是上下文学习的意思。对于元学习,其实也没那么高深,说白了就是将大量的不同任务的样本同时送给模型做预训练,和GPT2中的多任务学习形似,而在做in-context learning的时候,根据示例样本的多少,区分zero-shot、one-shot和few-shot,所以这个in-context learning过程有没有在做梯度更新?是没有的。作者对于元学习和in-context learning在本页的尾部做了解释:

作者说了,之前提到的零样本学习不是真的从零样本的情况下学习,为了避免这种歧义,所以用了元学习来代替预训练过程,用in-context leaning代表前向传播过程(注意,可以认为是推理,因为不涉及到梯度的更新)。而且根据在推理过程所依赖示例样本的多少划分零样本、单样本和少样本。说实话,有点绕,如果不深入分析作者的意思的话,困扰更大。作者还附上了一幅图来说明这个过程:
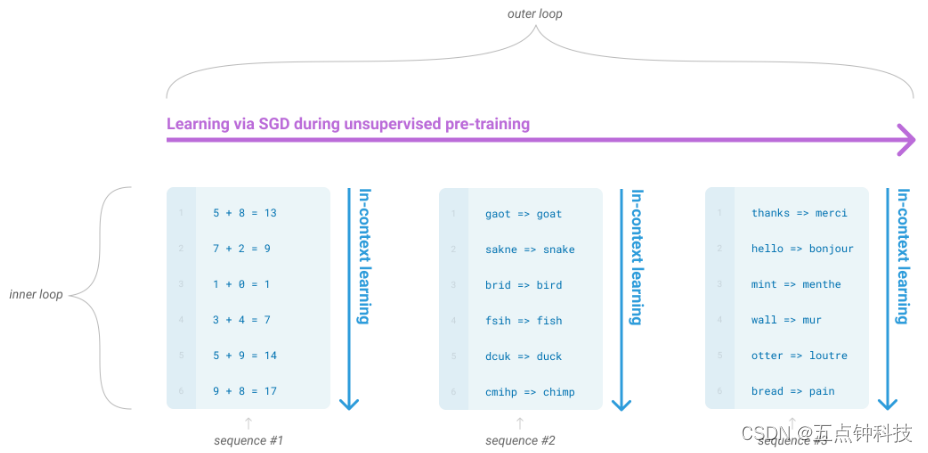
outer loop部分是无监督预训练过程,底下蓝色部分就是in-context learning。单从图上来看,整个outer loop部分是无监督预训练,在这个过程中,分别包含了不同的in-context learning阶段,可是按照文中的意思,预训练过程是不可能不做梯度更新的,而in-context learning又是不做梯度更新的,所以上图可能表示的有些问题,所以我认为,这个图并不是在讲GPT-3是怎么训练的,而是告诉我们有这么个组成阶段,具体的就是,有个无监督预训练阶段,而in-context learning只发生在前向传播阶段,作者想告诉我们,在预训练阶段,只要数据量足够大,那么就很有可能包括了in-context learning过程中的任务相关的示例样本。大家看看就好,挺奇怪的反正是。当然,由于GPT-3未开源,所以这些只是猜测。

这段话作者想说明随着模型参数量的不断增大,模型的性能也的确在不断改善,总结就是模型的参数量对模型的性能确实有直接的影响。


作者对不同shot做的实验对比图,从图上来看,few-shot貌似是最好的,注意图上三条实线取的是n次实验的平均值。也就是说,随着给的示例样本的增多,模型的性能大体也越来越好。但值得注意的是,给的示例样本并非用来给模型进行微调训练的,而是在不更新梯度的条件下让模型能够根据示例样本执行相关的任务,这的确有点像人类执行新任务的过程。
 作者也提到了说GPT-3在自然语言推断方面的任务仍然有很大的改进空间,他们也会继续在少样本学习方面加大改进研究的力度。
作者也提到了说GPT-3在自然语言推断方面的任务仍然有很大的改进空间,他们也会继续在少样本学习方面加大改进研究的力度。

这几段话主要概括了接下来作者要在文中讨论的内容。包括数据集、模型尺寸、不同训练方式、模型的局限、社会影响等方面,没啥可说的。
2. Approach


接下来作者又介绍了一遍什么是微调、少样本学习、单样本学习、零样本学习,以及他们是怎么做的。这里值得一提的是,作者在少样本学习中介绍了他们实验的示例样本范围是10到100个,也提到了少样本学习的一个主要缺点是它仍然比目前最好的有微调过程的模型表现的差。而零样本学习是最接近人类学习新任务的情形。下面是一张示例图,分别对微调、零样本、单样本、少样本学习剧了不同的例子:

从上图可以清楚的明白4个不同过程究竟是怎么一回事:微调就是在预训练模型的基础上用一定量的带标签的样本进行增量训练(有梯度更新);零样本就是只有提示词,没有示例样本;单样本就是有提示词,也有一个示例;少样本就是提示词加上少量的示例。示例就是为了让模型推理的时候也给个例子让模型看,使模型能够知道你要让它干嘛。比如上图的提示词“translate English to French:”,提示词下面就是示例样本和待预测样本,“=>”左端序列指的是原始文本(English),右边是目标文本(French),最后一条不存在目标文本的序列就是需要模型做预测的待预测的样本。
接下来,作者列举了他们在文章中所设计的不同大小的模型的参数情况:

这个大家看图就一目了然了,其中,GPT-3 Small的参数和Bert-base类似,GPT-3 Medium和Bert-Large差不多。GPT-3 XL的参数量和GPT-2的相当,但是其向量维度会比GPT-2宽一些,层数比GPT-2深一些,GPT-2是48层的。至于这些参数为什么这么设定,我想应该是作者们的玄学思维发挥了作用。。。比较好奇的是,随着GPT层数的增加,其向量维度增加的程度并不高,而且随着batchsize的增加,学习率也往小了调,我感觉这有点和我们的认识反着来。通常层数增加的倍数要和向量维度增加的倍数相当,因为层数增加了,就要有更多的向量维度去记住更多的信息,当batchsize增大,学习率应该也有所增大才是,因为在那么一大批量的样本上,应该先要有个大的学习率快速的接近最优空间,总之这块挺玄学的。
2.1 Model and Architectures

到了大家最关心的模型结构问题,很可惜,最重要的地方篇幅却很少。开头作者就说,GPT-3和GPT-2在模型结构上没有本质区别,唯一不同的就是GPT-3在注意力机制这块GPT-3采用了一种叫做Sparse Transformer的网络结构,抱歉,这个模型我还没仔细研究过,暂且不做讨论。所有的8个模型作者均采用了2048个token的输入限制,也就是说GPT-3支持最多2048个token。文中作者还简要提了一下工程上的问题,把模型的深度和宽度分布在多台机器上并行,这样可以减少计算复杂度。
2.2 Training Dataset
当要的到GPT-3这么大的模型时,就不得不考虑大数据了。作者在这一节里介绍了他们的主要数据来源是基于Common Crawl来采样的。

在GPT-2那篇文章中,作者有提到说这个数据集质量低,所以他们没有采用,而是采取了其它方式构建了新的数据集,但在GPT-3中,为了训练如此大的模型,作者不得不采用该数据集了。为了提高数据集的质量,作者采取了3个步骤来提高数据集的平均质量:(1)下载并筛选了与一系列高质量参考语料库相似的Common Crawl版本,简单来讲,就是拿一个质量高的参考语料,经过对比来筛选出common crawl中的高质量语料,对比的方法我看网上有人说用的二分类,就是把common crawl数据集中质量低的当成负样本,其它质量高的数据集当成正样本,训练一个二分类模型,然后再用二分类模型去筛选common crawl,这是一种方法,反正无所谓了,只要能够较好的完成这项工作,用什么方式去筛选都行,属于数据特征工程的任务;(2)在文档层面进行了模糊去重,防止冗余并保持验证集的完整性,以此作为准确衡量过拟合的依据,我想这么大批量的去重,十有八九就是用到哈希的方法,类似于LSH;(3)向训练混合中添加了已知的高质量参考语料库,以增加Common Crawl的多样性和丰富性,比如GPT-2、Bert之类的所用到的语料。

从上表中可以看到,虽然common crawl基数很大,但是它的采样率不及下面几个数据集的采样率,这可能是因为作者仍然认为common crawl数据集的质量较低,所以应当降低其采样比例。

作者提到对在大量互联网数据上预训练的语言模型,特别是具有记住大量内容能力的大模型,存在一个主要的方法论问题,即预训练过程中可能会无意中看到测试集或开发集,从而对下游任务产生潜在的污染。其实就是模型的“作弊”问题,这容易导致模型性能虚高。虽然作者做了一些去重,但是由于过滤器设计上的一些缺陷,导致了去重不彻底,也就是GPT-3的数据集中,仍然存在着许多训练样本和测试样本重叠的情况,对于这一问题,重新训练是不可能的,因为成本太高了,所以作者想把它放在后续研究中来解决。
2.3 Training Process
这一小节稍微介绍了一下训练过程(细节无),没有太多值得关注的。
 这段话主要了解一下作者他们用的是v100分布式训练的,其它的没啥,可以看下附录B里的内容:
这段话主要了解一下作者他们用的是v100分布式训练的,其它的没啥,可以看下附录B里的内容:

从附录B可以提炼出以下几点:
- Adam优化器的参数是β1=0.9,β2=0.95,
=10^-8;
- 学习率在前260亿个tokens之前,以余弦衰减策略将学习率从初始值衰减到其10%,之后就保持不变,并在3.75亿个tokens之前采用线性学习率预热策略;
- 根据模型大小,在训练的前4-12亿个tokens期间,逐步将batchsize线性地从一个小值(32k个tokens)增加到全值;
- 训练阶段的数据采样是不放回抽取;
- 所有模型以0.1比例进行权重衰减;
- 输入长度限制在2048个tokens,当一篇文档的总token数小于2048时,用其它文档补齐,总之每条输入序列保证是2048个tokens。如果一条序列是由多个文档组成的,那么文档与文档之间用一个特殊的结束符来区分;
2.4 Evaluation
本节就是关于实验评估的一些介绍,不同的是,作者采用的是上下文学习的方式,由于这里不涉及微调,所以对GPT-3的评估就是直接用预训练好的模型拿不同数量的示例样本进行评估了。
写到这里,其实关于GPT-3比较重要的部分都介绍完了,后面的一堆内容就是关于各种实验任务的介绍,以及一堆附录,感兴趣的小伙伴根据自己的需求挑着看就行。
总结
总结一下,GPT-1中,作者提出了无监督预训练结合任务相关的微调训练范式,将输入结构改成和任务相关的样子进行微调,这也是后续Bert、T5等模型的训练方式;GPT-2中,作者将任务相关的输入全用自然语言来描述,而不再使用特殊符号区分不同任务,这也是后来指示学习的范式,并提出了零样本在语言模型训练上的应用;GPT-3一改前面模型的训练范式,直接用大规模语料进行模型的训练,而不需要使用特定任务的微调,并在少样本示例上验证了大规模数据训练以及大参数量模型性能的提升,这也是现如今各大语言模型所采用的的基本方式。总结一句话:牛逼!