序言
最近在做行人属性识别相关的任务,本文用于记录训练过程,供以后复习查阅。
目前网上可用的行人属性识别仓库还是比较多的,比如前段时间百度开源的PP-Human属性识别、PULC 人体属性识别,以及京东的JDAI-CV/fast-reid都是比较优秀的工作,但是这里不打算用以上的项目,追述到源头,发现百度和京东的行人属性识别都是基于Rethinking_of_PAR该项目进行,所以我直接研究此项目即可,本文也将基于这个项目进行训练,以及后续的修改模型和训练自己的数据集。
行人属性识别数据集最新指标 :https://paperswithcode.com/task/pedestrian-attribute-recognition/
其他相关项目:
- https://github.com/chufengt/ALM-pedestrian-attribute
- https://github.com/hyk1996/Person-Attribute-Recognition-MarketDuke
- https://github.com/xh-liu/HydraPlus-Net
一、数据集准备
训练基于PA100k数据集,PA-100K数据集是迄今为止用于行人属性识别的最大数据集,其中包含从室外监控摄像头收集的总共100000张行人图像,每张图像都有26个常用属性。根据官方设置,整个数据集随机分为80000个训练图像、10000个验证图像和10000个测试图像。
这里我将数据集打包放在我的百度云盘中供需要下载,链接: https://pan.baidu.com/s/1WLWCZujhENVAL0Iz0BXnQQ 密码: iulh,下载下来后解压得到图片和.mat标签文件,将release_data文件夹重命名为data,先放置一边。
clone训练仓库下来:
git clone https://github.com/valencebond/Rethinking_of_PAR.git
cd Rethinking_of_PAR
这个仓库提供了很多行人属性数据集的训练方式,各个数据集训练的精度指标如下:
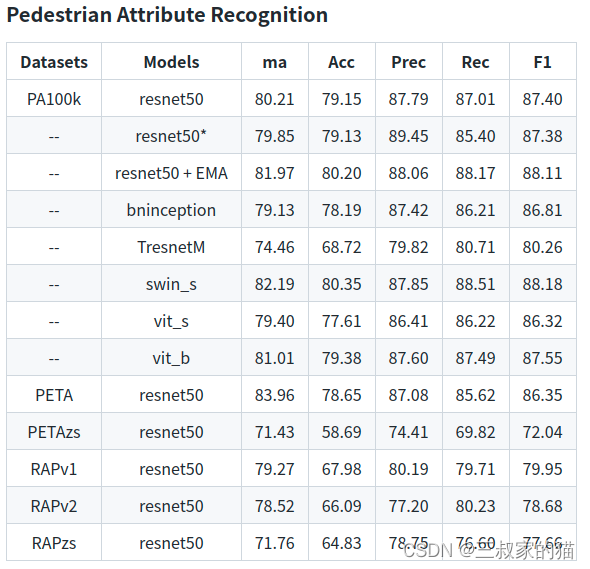
这里我只针对PA100k进行训练,其他数据集准备方式大同小异,因为作者没有提供预训练好的模型(谷歌云盘失效了),所以如果你想测试的话,需要自己先跑一遍训练,训练时间并没有很长。
因为该项目读取的是.pkl格式的标注文件,所以需要解析上面下载的.mat,并保存为.pkl文件,幸运的是作者也把准备的脚本提供了,在dataset/pedes_attr/preprocess/format_pa100k.py中,在使用format_pa100k.py脚本文件之前,需要先阅读一下dataset/pedes_attr/annotation.md,该文件的大致内容简单来说就是,需要将数据集的各个属性按照如下标准从头到脚排序一下,统一的属性顺序为:
- head region
- upper region
- lower region
- foot region
- accessory/bag
- age
- gender
- others
对于pa100k,26个属性排序后的新顺序为:
num_in_group = [2, 6, 6, 1, 4, 7]
‘Hat’,‘Glasses’, [7,8] 2
‘ShortSleeve’,‘LongSleeve’,‘UpperStride’,‘UpperLogo’,‘UpperPlaid’,‘UpperSplice’, [13,14,15,16,17,18] 6
‘LowerStripe’,‘LowerPattern’,‘LongCoat’,‘Trousers’,‘Shorts’,‘Skirt&Dress’, [19,20,21,22,23,24] 6
‘boots’ [25] 1
‘HandBag’,‘ShoulderBag’,‘Backpack’,‘HoldObjectsInFront’, [9,10,11,12] 4
‘AgeOver60’,‘Age18-60’,‘AgeLess18’, [1,2,3] 3
‘Female’ [0] 1
‘Front’,‘Side’,‘Back’, [4,5,6] 3
permutation = [7,8,13,14,15,16,17,18,19,20,21,22,23,24,25,9,10,11,12,1,2,3,0,4,5,6]
所以再去阅读format_pa100k.py文件就清晰多了,根据刚才下载的数据集路径,修改相关配置,然后运行后得到dataset_all.pkl文件,需要注意的是,如果没有将数据集存放在./data/PA100k下的话,而是存放外部文件夹的话,加载数据集时会报错,需要修改此处tools/function.py:
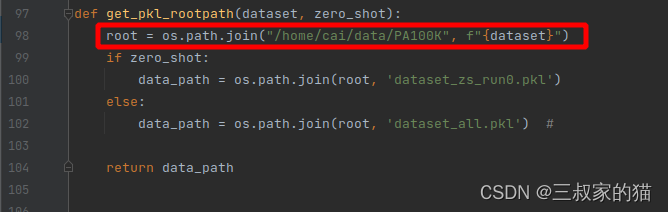
改成你的数据集路径,不然默认加载./data里的,看着修改就好了。
二、开始训练
修改configs/pedes_baseline/pa100k.yaml配置文件中的相关配置,批次大小、长宽、backbone等,修改完直接在终端中运行:
python train.py --cfg ./configs/pedes_baseline/pa100k.yaml
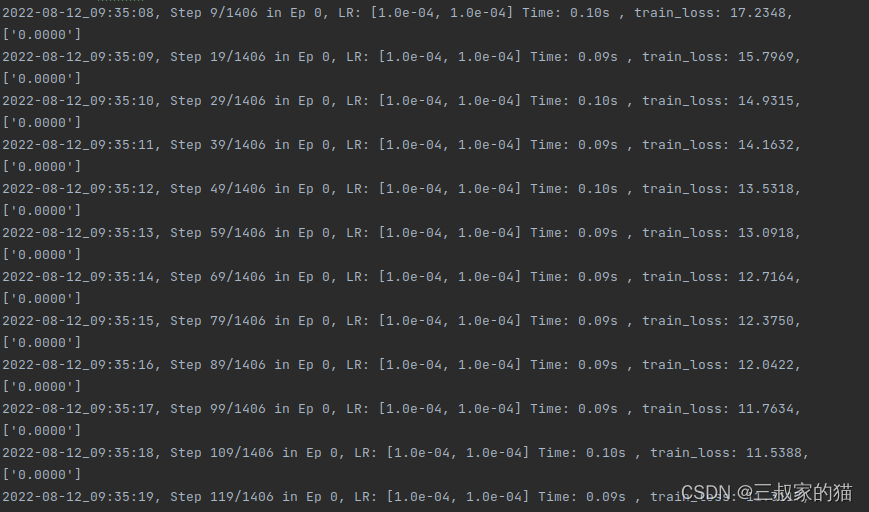
出现如下界面,即训练开始:
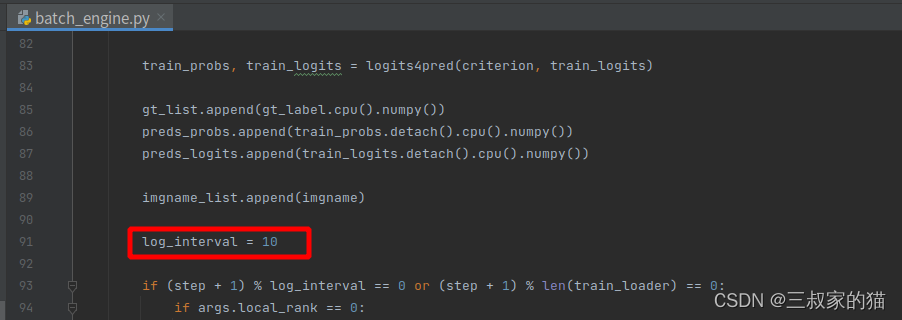
如果觉得打印的间隔太长,可以修改文件中的打印间隔:
训练结束后模型保存在exp_result文件夹中的pa100k/img_model,只有一个模型,因为该模型的名字在训练时由时间戳确定,所以后面以更优精度保存下来的模型都会覆盖该模型,如果想修改模型保存的名字,可以修改该行代码:

保存下来的模型名字带有最优的epoch和最优精度信息,看起来更加简单明了一点。
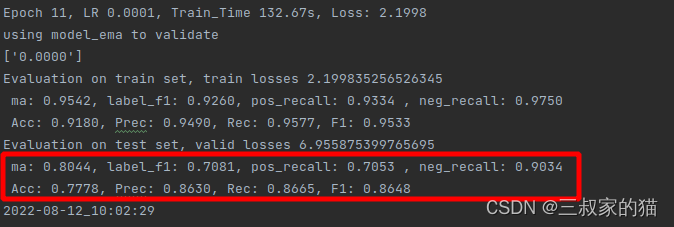
训练得到的最优精度为:
三、模型测试
因为作者没有提供单独测试某张图片的代码,所以我基于infer.py文件进行修改,得到demo.py文件,用于测试单张或者文件夹内多张图片功能:
import argparse
import json
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import pickle
from dataset.augmentation import get_transform
from dataset.multi_label.coco import COCO14
from metrics.pedestrian_metrics import get_pedestrian_metrics
from models.model_factory import build_backbone, build_classifier
import numpy as np
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
from PIL import Image
from configs import cfg, update_config
from dataset.pedes_attr.pedes import PedesAttr
from metrics.ml_metrics import get_map_metrics, get_multilabel_metrics
from models.base_block import FeatClassifier
# from models.model_factory import model_dict, classifier_dict
from tools.function import get_model_log_path, get_reload_weight
from tools.utils import set_seed, str2bool, time_str
from models.backbone import swin_transformer, resnet, bninception,repvgg
set_seed(605)
clas_name = ['Hat','Glasses','ShortSleeve','LongSleeve','UpperStride','UpperLogo','UpperPlaid','UpperSplice','LowerStripe','LowerPattern','LongCoat','Trousers','Shorts','Skirt&Dress','boots','HandBag','ShoulderBag','Backpack',,'HoldObjectsInFront','AgeOver60','Age18-60','AgeLess18','Female','Front','Side','Back']
def main(cfg, args):
exp_dir = os.path.join('exp_result', cfg.DATASET.NAME)
model_dir, log_dir = get_model_log_path(exp_dir, cfg.NAME)
train_tsfm, valid_tsfm = get_transform(cfg)
print(valid_tsfm)
backbone, c_output = build_backbone(cfg.BACKBONE.TYPE, cfg.BACKBONE.MULTISCALE)
classifier = build_classifier(cfg.CLASSIFIER.NAME)(
nattr=26,
c_in=c_output,
bn=cfg.CLASSIFIER.BN,
pool=cfg.CLASSIFIER.POOLING,
scale =cfg.CLASSIFIER.SCALE
)
model = FeatClassifier(backbone, classifier)
if torch.cuda.is_available():
model = torch.nn.DataParallel(model).cuda()
model = get_reload_weight(model_dir, model, pth='best_11_0.8044.pth') # 修改此处的模型名字
model.eval()
with torch.no_grad():
for name in os.listdir(args.test_img):
print(name)
img = Image.open(os.path.join(args.test_img,name))
img = valid_tsfm(img).cuda()
img = img.view(1, *img.size())
valid_logits, attns = model(img)
valid_probs = torch.sigmoid(valid_logits[0]).cpu().numpy()
valid_probs = valid_probs[0]>0.5
res = []
for i,val in enumerate(valid_probs):
if val:
res.append(clas_name[i])
if i ==14 and val==False:
res.append("male")
print(res)
print()
def argument_parser():
parser = argparse.ArgumentParser(description="attribute recognition",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"--test_img", help="test images", type=str,
default="./test_imgs",
)
parser.add_argument(
"--cfg", help="decide which cfg to use", type=str,
)
parser.add_argument("--debug", type=str2bool, default="true")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = argument_parser()
update_config(cfg, args)
main(cfg, args)
运行命令:python demo.py --cfg ./configs/pedes_baseline/pa100k.yaml --test_img ./test_imgs,得到类似如下结果:

我这里的结果是将列表里的英文翻译成中文显示处理,至此训练结束,下一篇将写如何修改添加新的网络进行训练。