一、简介
强化学习算法主要可以分为两类:第一类是model free方法,能够免于对环境建模,直接通过和环境交互来学习到一个价值函数或者策略函数;第二类是model based 方法,需要通过和环境交互来对环境进行建模,然后再利用这个模型做出动作规划或者策略选择。相对来说,两种方法互有优劣,model free算法由于其简单实现和高渐进性能表现(asymptotic performance),在众多实验场景和游戏环境上已经取得了很大的成果,但是由于model free类方法是采样效率(sample efficiency)极低,导致需要大量和环境的交互。相对来说,model based算法对环境进行建模,拟合环境的动力学模型(dynamics model),采样效率较高。
这个对环境的建模的模型model,其实是显式的包含对于环境或者任务的知识(knowledge)的一个表征模型,一般来说两类包含的比较多:分别是转移模型(transition model)或者动力模型(dynamics model):St+1=Fs(St,At) ,以及奖励模型(reward model):Rt+1=F(St,At) 。一旦这个模型建模出来,就可以正常的融入和环境的交互以及策略的学习中,具体如下图所示:

图1 模型融入环境交互和策略学习示意图
在ICML2020的一篇tutorial[1]中,用这张图来对比model free和model based方法的区别:
具体来说,基于模型的强化学习方法,在内部可以分为两个阶段,怎么学和怎么用。如果模型已知,也就是如何用,总体上有两种方法:第一种policy based method,额外学出一个policy model去找到当前最好的action。第二种model predictive control(MPC),不去找一个依赖于当前状态的策略,每次需要决定action的时候,基于dynamics model 去逐步预测模拟和选择。(无论是哪种方法,都是靠model根据当前的state和action去预测下一步转移的state,这也是我们学这个model去代替真实交互的初衷,关键是拿到了预测的state之后如何去control)。

图2 model free和model based方法的区别
二、方法分类
假设已经拿到了初步训练好的world dynamics model,我们就可以根据model进行交互来对policy进行训练。根据训练方法的不同,model based RL主要可以分为四种方法:
- Dyna-style methods
- Analytical gradient
- Planning
- Model-based value expansion
Dyna类的方法的特点是可以将Model free的方法和world model结合,world model可以提供大量的模拟数据给model free的算法进行对policy的学习,属于一种显式的策略训练方法;Analytical类的方法的特点是利用了模型产生数据的可微性(differentiability),直接对trajectory的return进行优化来对策略进行训练;Planning类的方法是不显式的对策略进行训练,而是基于world model用简单的规划方法得到一系列动作,能够快速的迁移到相似的任务场景上;Model-based value expansion类的方法的特点是通过对动作价值或者状态价值更好的估计来减小world model和真实环境中的误差,能够控制模型的使用来平衡偏差和方差。
接下来我们从Dyna-style methods开始介绍。
三、Dyna-style Methods
当我们拿到一个初步训练好的模型(暂且不去关注如何训练出来的)后,需要思考如何使用这个world model去帮助我们训练智能体的策略。一个很自然的想法是,使用world model在各个状态基于预测想象,来得到智能体与环境的交互数据,尽管由于模型和真实环境有一定偏差,但是这个交互数据依然有相当的可信度能够用来充当强化学习算法的训练数据。这个强化学习算法,完全可以是model free算法,也就是说dyna-style类的算法相当于是用模型生成想象的数据,用于无模型强化学习算法,能够解决model free算法的sample efficiency低的问题。
这类算法的思想其实在1990年就被Sutton提出[2],这种思想已经被广泛应用到各种model free算法中,比如代表性的MBPO就是融合的SAC算法,能够高效的产生和利用experience,提高sample efficiency,提升渐进性能。如下图,model free对应着direct RL和acting的小圈,这个loop里面直接使用真实的轨迹和数据进行优化,model based增加了model learning和planning的大圈,这意味着算法需要通过experience data来训练一个环境的模型,然后利用习得的环境模型模拟环境,根据动作状态给出预测的想象虚拟return,从而进行对策略的学习。这种方式能很好的补充model free方法中策略训练所需要的数据,减少与真实环境的交互和成本,提高sample efficiency。
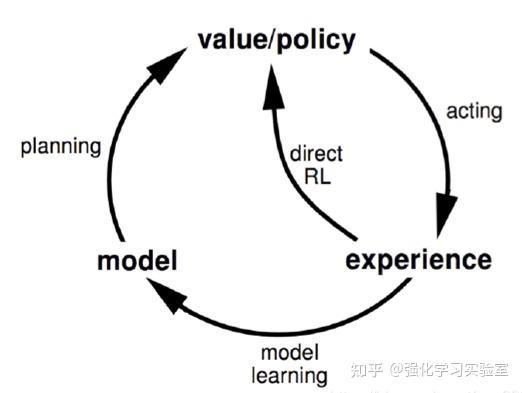
图3 Dyna类算法和direct RL关系示意图
MBPO(Model Based Policy Optimization)
这篇工作由Sergey Levine等发表在NeurIPS19[3],主要考虑了学习到的world dynamics model不准确,对于真实环境的拟合有比较大的复合误差(compound error)的情况下,该如何针对不准确的model进行策略的学习。
这篇文章是基于SLBO进行改进的,在SLBO中,作者为MBRL的monotonic improvement提供了理论分析和论证,本文在SLBO的基础上,针对环境模型和采样可能存在的bias,提出了branched rollout,根据对模型error的估计和,通过控制模型rollout的长度来有限度的使用环境model,最大化的利用学到的环境model,但同时能有效bound住由模型不准确带来的策略误差。
首先介绍一下monotonic improvement,

n[Π]为policy Π 在真实环境中的返回return, n[Π] -hat是policy Π 在学习到的环境模型中的返回return,bias C 有两个因素有关,一个是由于环境模型和真实环境之间的误差(Modeling Error) ,可以表示为两个model的TV distance,即 ;另一个是由于策略自身导致的偏移(Policy Shift) ,主要由于采集数据时的策略和当前采用的策略的不匹配导致,同样可以被TV distance所衡量,即 。单调性的含义是指,我们在环境模型的基础上对策略的表现(即return)进行提高和优化,在减去bias的范围内,也能够提高策略在真实环境的return。
之前的算法(ME-TRPO,MB-MPO等)都关注从初始状态分布就开始rollout,不太关注在task horizon前何时截断,也就是rollout length,该工作为了解决这个问题,设定一个重要的系数model rollout length ,来控制何时截断。那么上式的限制条件变为:
我们的目标就是减小右边的第二项,找到能够让该项最小化的 ,就能够最小化策略在环境模型和真实模型下的bias。但是根据上式进行计算,发现只有 时bound最小,对应着完全不使用环境模型,也就是完全使用真实模型进行交互,这是符合直觉的,但也是不合理的,毕竟我们的目的就是为了减少与真实环境交互的次数,提高sample efficiency。

图4 model error 与 policy error的关系图
本文进行了实验,研究了model error 和policy error 之间的关系如上图,总体上可以得出两个比较明显的结论:1.随着当前策略和数据收集策略的差异性变大,即 越大, 也会越大,之间呈正相关;2.随着原策略收集数据变多,即train size变大,两种error的相关性降低了。因此我们用policy error来代替model error,能得到一个非常有意思的形式:
当环境模型与真实环境之间的误差 相比于策略自身导致的差异性偏移 足够小时,让bias最小的 ,即 ,来控制环境模型的使用。
实验部分,本文对比了model free方法的代表:SAC[4]和PPO[5],以及model based方法中的代表:STEVE[6],PETS[7]和SLBO[8]。实验环境为六个MuJoCo连续控制环境。结果可以看出:MBPO算法超越了所有model based的baseline,也能达到接近与model free方法的渐进表现。
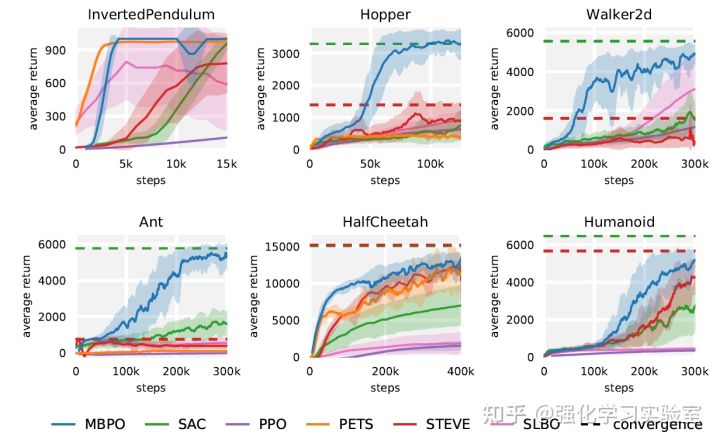
图5 MBPO在MuJoCo环境下的实验对比结果
最后我们来总结一下这个算法:

图6 MBPO算法伪代码框架
MBPO算法在单调性保证的基础上,研究了模型偏差和策略差异的关系,通过计算出最优截断长度rollout length ,来控制环境模型的使用(Model Usage),利用short length rollouts规避掉task horizon的影响,获得大量有效model samples来帮助策略训练。
但是有点奇怪的是,作者实验发现single-step model rollouts的效果是最好的。
AMPO(Adaptation Augmented Model-based Policy Optimization)
这篇工作[9]是基于MBPO改进的,发表在NeurIPS21'上。主要考虑的是从有限数据中学习到的环境模型离真实环境还是有一定偏差,从而使环境模型训练流程的state-action input distribution和环境模型generate的distribution有一定mismatch,这种mismatch会让学到的环境模型给出inaccurate的预测,更重要的是这种error随着多步的rollout会进一步叠加和扩大,从而极大的降低性能。
目前来说针对环境模型的model error带来的distribution mismatch,有较多工作来解决:主要可以分为两类:第一类是从环境模型的训练学习(Model Learning)本身提升,比如不同的网络架构或者损失函数来缓解overfitting或者提升multi step prediction来让环境模型与真实环境更加相似;第二类是从环境模型的使用(Model Usage)着手,根据环境模型离真实分布的偏离程度,来控制对环境模型的使用程度。基于此,本文往前推了一步,在MBPO算法上引入了一个模型适应(Model Adaptation)的流程,也就是AMPO(Adaptation Augmented Model-based Policy Optimization),通过最小化真实数据和想象数据之前的integral probability metric(IPM),能够鼓励环境模型去学习真实数据和想象数据的不变特征。
首先介绍一下IPM,Integral Probability Metric,是一类针对同空间的两个不同分布的距离衡量方式。给定在同空间 上的两个概率分布 和 ,那么 -IPM可以定义为下面的形式:
回顾一下MBPO中expected return的形式:
为policy 在真实环境( )中的返回return, 是policy 在学习到的环境模型( )中的返回return,
其中,。。。。该式表明,对于每个状态的两个state visit distribution之间的差异(discrepancy),是被预测该状态的环境模型error和两个state-action的occupancy measures所upper bound住。直觉上来讲,这意味着当state-action的distribution和环境模型的conditional dynamics distributions很接近时,输出的状态分布也会比较相近。
这个式子拆开来看,第二项是策略 和策略 所induce的state visit distribution之间的divergence,第三项是分布 和 (注意两者的policy和dynamics model均有不同)之间的integral probability metric,用来衡量model learning 和model usage之间的distribution mismatch;第四项直接衡量在真实数据上的模型estimation error。
一般来说,为了简便,不用第一项对model进行优化,而是用第一项对策略进行优化,使用第四项对model进行优化,这也是Dyna-style方法的通用方式。RL是鼓励agent进行探索,所以作者认为不应该再对第二项,也就是状态分布差异进行限制,否则会影响对未知状态的探索。所以,问题的真正关键现在变为minimize第三项,也就是occupancy measure divergence,目的是希望学到的dynamics model预测的state-action更接近与训练的数据。基于此,作者认为利用该项优化policy是不必要的,理由是会减少efficiency,如果model足够准了,只需要使用第一项来优化policy(但这个理由目前还是有点疑惑,感觉有些想不通,大家如果有想法或者见解,欢迎在评论区一起讨论)。
上面的理论分析完毕之后,作者开始在利用第三项来优化model上做文章。首先作者避免在data level去缓解分布不匹配的问题,而是想显式的在feature level去解决,具体想法是使用unsupervised domain adaptation,也就是训练一个learner,能从labeled data泛化到不同分布的unlabeled data。比较常用的思路就是找到invariant feature representation也就是不变量表征,本文基于这个思路,提出了将model adaptation引入到MBPO框架上,从而鼓励dynamics model去学真实数据和虚拟想象数据之间共有不变的feature。
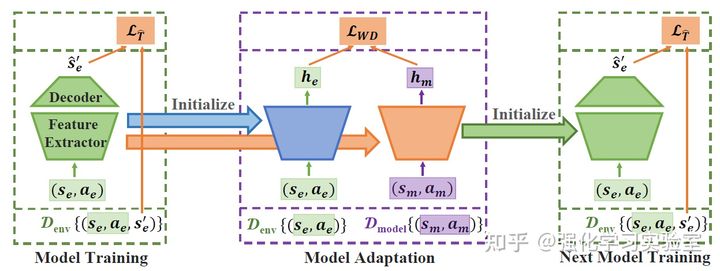
图7 AMPO算法框架示意图
MBPO的知识请回顾上面部分,接下来直接看融入unsupervised model adaptation的部分。以一个dynamics model为例(ensemble很容易推广),本文定义了前几层layers是feature extractor ,后面的layers是decoder ,参数分别是 和 ,因此可以把环境模型写成这样的形式: , 。为了将feature encoder和decoder分开,本文在feature encoder的output上增加一项model adaptation的loss,主要用来调整 将真实数据和虚拟想象数据映射到相似的特征空间上。具体来说,本文选择采用asymmetric feature mapping strategy,为真实数据和虚拟想象数据分别训练单独的feature extractor,如图所示,每当一次迭代的model adaptation结束,会用虚拟数据的weight 参数对下一步迭代的环境模型的feature extractor进行初始化,通过这种交替优化model training和model adaptation,可以帮助feature extractor提取出的feature表征能包含足够多的有用信息来帮助decoder来预测真实数据,同时能泛化到虚拟想象数据。
本文选择Wasserstein-1距离作为IPM的距离度量,使用了一个critic网络 来学习feature表征到距离的映射,通过最大化真实数据和虚拟数据的距离差值来优化,即 ,同时为了让参数化后的critic网络 满足1-Lipschitz约束,加上了一项gradient penalty loss来辅助预测,即 ,因此整体的优化目标函数形式如下:
小结一下,在每一轮迭代中,都会对model adaptation进行优化,具体优化方式是轮替训练critic和feature extractor,前者是让critic学到估计Wasserstein-1距离,后者是让环境模型的feature extractor提取的更有泛化性的表征。
实验部分,本文对比了SAC(model free方法的baseline),以及model based方法中的代表:MBPO,PETS和SLBO。实验环境为六个MuJoCo连续控制环境。结果可以看出:AMPO是most sample efficient,学的也比其它baseline都快,相比与SAC能达到接近model free的渐进性能表现,相比于MBPO(注意rollout length相对短,不受task horizon的干扰)更优,证明了model adaptation的效果,进一步说明在short rollouts导致的distribution mismatch问题上,依然能很好的提升。

图8 AMPO在MuJoCo上的实验对比表现
总结:整体来说,本文可以认为是在MBPO上面的一个改进工作,通过引入model adaptation来correct MBRL中potential distribution bias,提出unsupervised model adaptation来找到真实数据和虚拟想象数据中的不变量表征,鼓励学到两种数据中更加一致的特征,产生虚拟数据时能预测的更准确,缓解model bias,从而提升了性能表现。
参考文献
[1] Model-Based Methods in Reinforcement Learning, ICML 2020 Tutorial. https://sites.google.com/view/mbrl-tutorial
[2] Sutton R S. Dyna, an integrated architecture for learning, planning, and reacting[J]. ACM Sigart Bulletin, 1991, 2(4): 160-163.
[3] Janner M, Fu J, Zhang M, et al. When to trust your model: Model-based policy optimization[J]. arXiv preprint arXiv:1906.08253, 2019.
[4] Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//International conference on machine learning. PMLR, 2018: 1861-1870.
[5] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[6] Buckman J, Hafner D, Tucker G, et al. Sample-efficient reinforcement learning with stochastic ensemble value expansion[J]. arXiv preprint arXiv:1807.01675, 2018.
[7] Chua K, Calandra R, McAllister R, et al. Deep reinforcement learning in a handful of trials using probabilistic dynamics models[J]. arXiv preprint arXiv:1805.12114, 2018.
[8] Luo Y, Xu H, Li Y, et al. Algorithmic framework for model-based deep reinforcement learning with theoretical guarantees[J]. arXiv preprint arXiv:1807.03858, 2018.