目录
建模的整个过程中最耗时的部分是特征工程(含变量分析),其次可能是调参,所以今天来通过代码实战介绍调参的相关方法:网格搜索、贝叶斯调参。
一、交叉验证
工作中最常用的训练集测试集划分方法主要是随机比例分割和(分层)交叉验证,随机比例分割可以按照7-3、8-2的比例划分训练集、测试集,但是这样的数据划分存在一定随机性,不如使用交叉验证来的严谨。
1、导包、设定初始参数
# 导包
import re
import os
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
import matplotlib.pyplot as plt
import gc
from sklearn import metrics
from sklearn.model_selection import cross_val_predict,cross_validate
# 设定xgb参数
params={
'objective':'binary:logistic'
,'eval_metric':'auc'
,'n_estimators':500
,'eta':0.03
,'max_depth':3
,'min_child_weight':100
,'scale_pos_weight':1
,'gamma':5
,'reg_alpha':10
,'reg_lambda':10
,'subsample':0.7
,'colsample_bytree':0.7
,'seed':123
}2、初始化模型对象、5折交叉验证,交叉验证函数cross_validate可以设定多个目标(此处使用AUC)、而cross_val_score只能设置一个
xgb = XGBClassifier(**params)
scoring=['roc_auc']
scores=cross_validate(xgb,df[col_list],df.y,cv=5,scoring=scoring,return_train_score=True )
scores 
3、Xgb、lgb的原生接口可用自带的cv函数
xgb.cv(params,df,num_boost_round=10,nfold=5,stratified=True,metrics='auc' ,as_pandas=True) 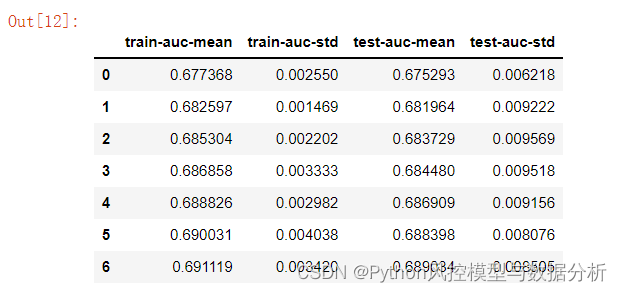
二、网格搜索
通过遍历全部的参数组合,寻找测试集效果最优的参数组
1、设定调参参数及范围,使用网格搜索
from sklearn.model_selection import GridSearchCV
train=df_train.head(60000)
test=df_train.tail(10000)
param_value_dics={
'n_estimators':range(100,900,500),
'eta':np.arange(0.02,0.2,0.1),
'max_depth':range(3,5,1),
# 'num_leaves':range(10,30,10),
# 'min_child_weight':range(300,1500,500),
}
xgb_model=XGBClassifier(**params)
clf=GridSearchCV(xgb_model,param_value_dics,scoring='roc_auc',n_jobs=-1,cv=5,return_train_score=True)
clf.fit(df[col_list], df.y)2、返回最优参数
clf.best_params_![]()
3、返回最优参数的模型
clf.best_estimator_
4、返回最优参数下的测试集评估指标(此处设定的AUC)
clf.best_score_![]()
网格搜索在设定的参数范围中全局遍历寻找最优参数、即全局最优解,但是这样的计算量下程序运行简直是龟速,而且它网格搜索的目标是测试集效果最优、在这种目标下调参训练仍然存在过拟合的风险;针对这些问题,有了贝叶斯优化调参。
三、贝叶斯优化
贝叶斯调参需要自定义目标函数,可根据实际情况灵活选择,而且运行速度快、在运行的同时就能展示每次当下参数的模型结果,确实是很好用的方法
1、导包
from bayes_opt import BayesianOptimization
import warnings
warnings.filterwarnings("ignore")
from sklearn import metrics
from sklearn.model_selection import cross_val_predict,cross_validate
from xgboost import XGBClassifier
2、自定义调参目标,此处使用cv下测试集的AUC均值为调参目标
def xgb_cv(n_estimators,max_depth,eta,subsample,colsample_bytree):
params={
'objective':'binary:logistic',
'eval_metric':'auc',
'n_estimators':10,
'eta':0.03,
'max_depth':3,
'min_child_weight':100,
'scale_pos_weight':1,
'gamma':5,
'reg_alpha':10,
'reg_lambda':10,
'subsample':0.7,
'colsample_bytree':0.7,
'seed':123,
}
params.update({'n_estimators':int(n_estimators),'max_depth':int(max_depth),'eta':eta,'sub sample':subsample,'colsample_bytree':colsample_bytree})
model=XGBClassifier(**params)
cv_result=cross_validate(model,df_train.head(10000)[col_list],df_train.head(10000).y, cv=5,scoring='roc_auc',return_train_score=True)
return cv_result.get('test_score').mean()3、设定调参范围,注意数值范围的固定格式:(left,right),贝叶斯调参会在该范围内随机选取实数点,对于n_estimators、max_depth等参数,随即出来的结果一样是浮点数、所以在模型部分要将这些参数转化为整型:int(n_estimators)
param_value_dics={
'n_estimators':(100, 500),
'max_depth':(3, 6),
'eta':(0.02,0.2),
'subsample':(0.6, 1.0),
'colsample_bytree':(0.6, 1.0)
}4、 建立贝叶斯调参对象,迭代20次
lgb_bo = BayesianOptimization(
xgb_cv,
param_value_dics
)
lgb_bo.maximize(init_points=1,n_iter=20) #init_points-调参基准点,n_iter-迭代次数
5、查看最优参数结果
lgb_bo.max
6、查看全部调参结果
lgb_bo.res
7、将全部调参结果转化为DataFrame,便于观察和展示
result=pd.DataFrame([res.get('params') for res in lgb_bo.res])
result['target']=[res.get('target') for res in lgb_bo.res]
result[['max_depth','n_estimators']]=result[['max_depth','n_estimators']].astype('int')
result
8、在当前调参的结果下,可以再次细化设定或修改参数范围、进一步调参
lgb_bo.set_bounds({'n_estimators':(400, 450)})
lgb_bo.maximize(init_points=1,n_iter=20)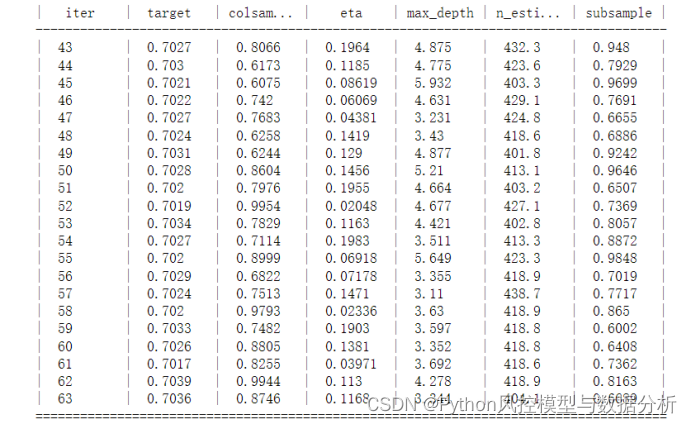
更多知识及代码分享,关注公众号Python风控模型与数据分析