1.1 laion数据集
laion2B-en数据集,是laion5B的一个子集,更具体的说它是laion-5B中的英文数据集,laion-5B是从网页数据common crawel中筛选出来的图像文本对,包含5.85B的图像文本对,其中文本为英文的数据量为2.32B,这就是laion-2B-en数据集。
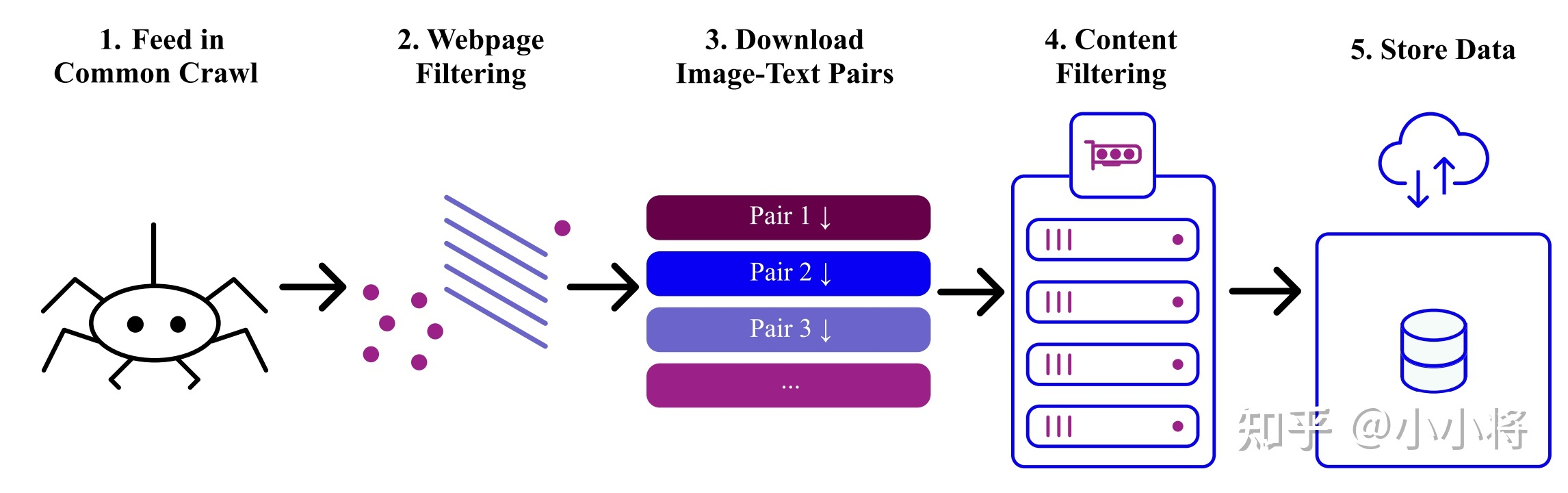
图片的width和height均在256以上的样本量为1324M,在512以上的是488M,在1024以上为76M,文本平均长度为67.

1.2 WUkong数据集
包括1亿对图文对

2.模型训练
扫描二维码关注公众号,回复:
16891841 查看本文章

2.1 runwayml 1.5
在laion-2B-en数据集上评分为5以上训练的,先用256x256,再用512x512,用了32台8卡A100 40G,bs=32x8x2x2=2048。训练了150000小时,大约25天。
2.2 stability 2.0
在laion-2B-en数据集上评分为4.5以上训练的,
2.3 stability 2.1
sd 2.1在sd 2.0基础上放开了一些nsfw过滤掉的数据,
2.2 mosicML sd 2
使用laion-5B的一个子集,其中包括带有纯英文标题且审美得分为4.5+的样本,第一阶段使用分辨率大于256x256的0.79B样本,第二阶段使用大于512x512的0.3B样本,128台A100,第一个阶段耗时1.6天,55万次迭代,第二阶段耗时4.9天,85万次迭代。
2.3 pai-diffusion
用Wukong数据集中的2千万中文图文数据对进行了约20天的预训练。
2.4 chineseclip
laion-5B中的zh文本大概1.1亿,悟空的7千万,加一下自有数据,总量大概2亿。