1. 何为管线
管线命令和Linux学习18里面的连续执行指令少许不同。他是只有在前面指令执行正确的时候,才会执行管线命令。
即这个管线命令“ | ”仅能处理经由前面一个指令传来的正确信息,也就是 standard output 的信息,对于 stdandard error 并没有直接处理的能力。
管线命令的执行流程可以使用下面简图表示:

在每个管线后面接的第一个数据必定是“指令”,而且这个指令必须要能够接受 standard input 的数据才行,这样的指令才可以是为“管线命令”。如 less, more, head, tail 等都是可以接受 standard input 的管线命令啦。至于例如 ls, cp, mv 等就不是管线命令。因为 ls, cp, mv 并不会接受来自 stdin 的数据。 也就是说,管线命令主要有两个比较需要注意的地方:
管线命令仅会处理 standard output,对于 standard error output 会予以忽略
管线命令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。
举一个实操的例子:
我们用 ls /etc 来查阅 /etc/ 下面有多少文件,但由于 /etc 下面的文件太多,并且命令执行完自动会跳转到最后一行去,我们得通过 less 指令的协助。
指令:ls -al /etc | less

通过鼠标滚轮进行阅览,再通过输入q进行退出。
2. 摘取命令:cut, grep
之前在对环境变量PATH进行修改与添加的时候,有时候我只想取其中一段进行操作,当时就不知道怎么做,在图形化界面中还好说用鼠标辅助,有些命令行界面就直接蒙了。
这个章节就写一下摘取命令。
摘取命令通常是针对“一行一行”来分析的, 并不是整篇讯息分析。
2.1 cut
一般用法:cut -option parameter
cut -d ‘分隔字符’ -f fields------->一般用于特定分隔字符
cut -c 字符区间--------->一般用于排列整齐的讯息
选项与参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段讯息分区成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
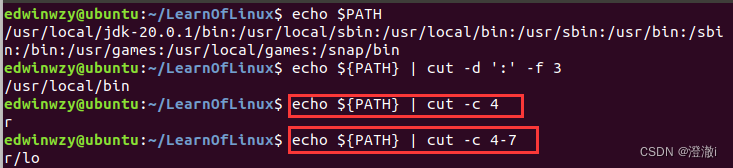
例1:摘取PATH的第3个路径
先通过echo查看PATH的值,我们可以得知我们要取的第三个路径是/usr/local/bin

管线命令cut进行摘取

这里cut先-d接分割字符:,这个分隔字符是根据实际情况来决定的,我这里PATH的分隔符是:。再用-f来决定取第几段。
例2:取PATH的第四个字符,取PATH的4-7个字符
2.2 grep
cut 是将一行讯息当中,取出某部分我们想要的,而 grep 则是分析一行讯息, 若当中有我们所需要的信息,就将该行拿出来。
一般用法:grep [-acinv] [--color=auto] '搜寻字串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 ‘搜寻字串’ 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 ‘搜寻字串’ 内容的那一行
–color=auto :可以将找到的关键字部分加上颜色的显示
grep是一个非常强大的指令,结合上正则表达式有奇效。正则表达式后面再写博客记录。
对grep的用法,举几个例子应该就能懂了。
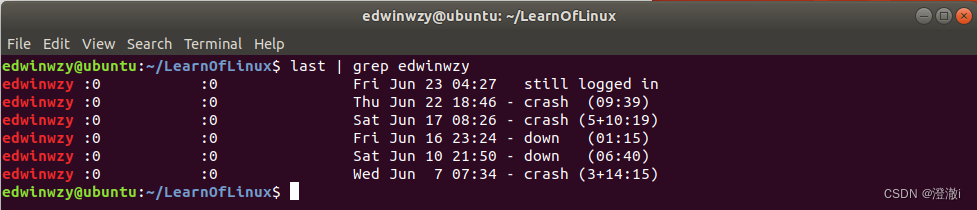
例1:将 last 当中,有出现 edwinwzy 的那一行就取出来;
指令:last | grep edwinwzy
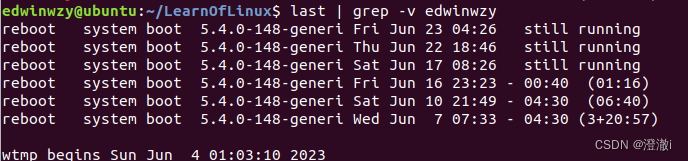
例2:与例1相反,只要没有 edwinwzy的就取出
指令: last | grep -v edwinwzy
例3:在 last 的输出讯息中,只要有 edwinwzy就取出,并且仅取第一栏满足条件的
last | grep edwinwzy |cut -d ' ' -f 1

3. 排序命令sort,wc,uniq
3.1 sort
以查看/etc/passwd为例
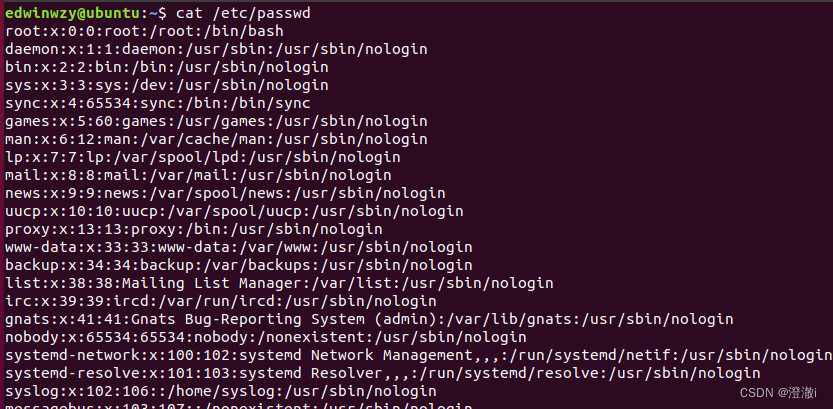
指令:cat /etc/passwd
对应的输出是乱序的,如果我们想让其顺序输出,那就得通过sort指令
sort一般用法:sort [-fbMnrtuk] [file or stdin]
选项与参数:
-f :忽略大小写的差异,例如 A 与 a 视为编码相同;
-b :忽略最前面的空白字符部分;
-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;
-n :使用“纯数字”进行排序(默认是以文字体态来排序的);
-r :反向排序;
-u :就是 uniq ,相同的数据中,仅出现一行代表;
-t :分隔符号,默认是用 [tab] 键来分隔;
-k :以那个区间 (field) 来进行排序的意思
针对上面的乱序输出的passwd进行排序
指令:cat /etc/passwd | sort
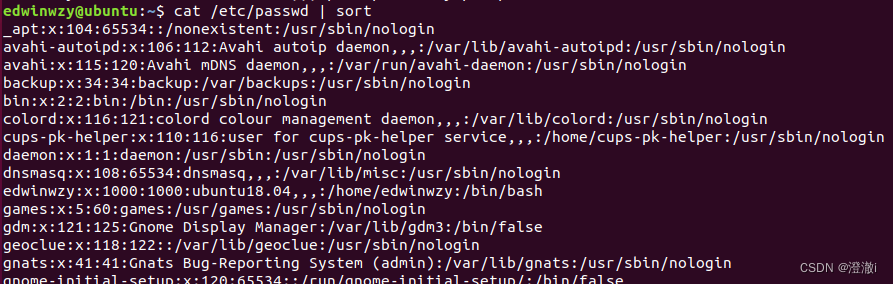 单独只用sort只是对第一栏进行排序,如果我想让其以第三栏进行排序,那么就需用到sort的一些备选参数。
单独只用sort只是对第一栏进行排序,如果我想让其以第三栏进行排序,那么就需用到sort的一些备选参数。
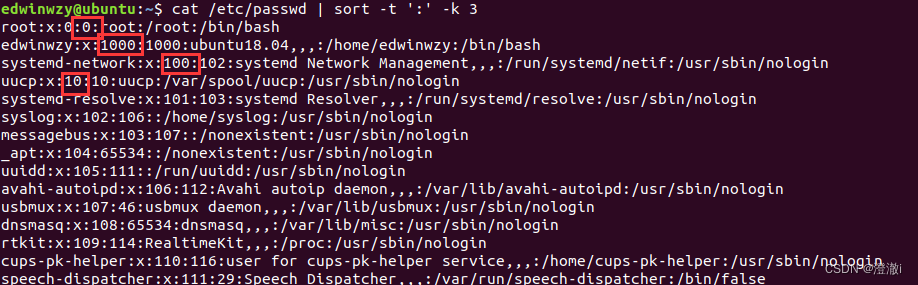
指令:cat /etc/passwd | sort -t ':' -k 3
但是这个排序似乎并不对,这是因为它是以文字体态排序,而非我们看到的数字,如果要以数字排序,那后面还要加上-n
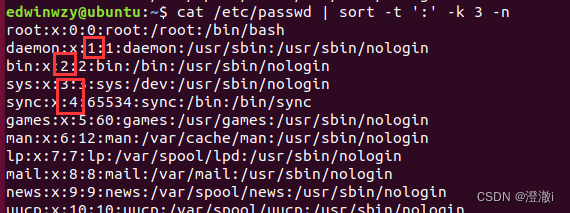
指令:cat /etc/passwd | sort -t ':' -k 3- n
3.2 uniq
uniq是unique的缩写,所以这个指令的含义就是重复情况只显示一个的意思。
使用last指令可以列出账号,但是会有很多重复的名称,用unique就会简洁很多。
一般用法:uniq [-ic]
选项与参数:
-i :忽略大小写字符的不同;
-c :进行计数
指令:last | cut -d ' ' -f1 | sort | uniq

对于上面情况,如果我想让其显示每个人的登录次数,只需要在uniq后加上选项-c
指令:last | cut -d ' ' -f1 | sort | uniq -c

3.3 wc
wc即wordcount的缩写,用来统计一个文件里面有多少字符或者说输出的内容里面有多少字符。
一般用法: wc [-lwm]
选项与参数:
-l :仅列出行;
-w :仅列出多少字(英文单字);
-m :多少字符;
wc不带参数默认列出的三个字符是“行、字数、字符数”,分别对应选项-l,-w,-m
总结
这个管线相关的命令还是非常重要的,这篇博客写指令相对于下一节来说,实际运用频率上大很多,还是得好好练习一下。