YOLO v2
@(目标检测)
YOLO通过整合备选框选择和特征检测两个部分,成功的实现了end-to-end的训练,降低了复杂度并且减少了计算量,达到了实时的效果。但是仍然拥有缺陷:
定位误差,YOLO采用的网络结构中含有全连接层,使得输入图片分辨率固定,对物体尺寸不敏感,大量的位置信息被丢失掉。并且在最后一层中,每个grid里面只预测两个obj,一个类,这让YOLO网络天然对存在大量obj的图片难以准确检测。
如何解决这个问题,就是YOLOv2的工作。下面将一一列举YOLOv2的改进。
Batch Normalization
batch normalization的应用已经得到了很多经典网络的肯定,现在基本上成为标配。YOLOv1中并没有引入,所以在YOLOv2中加入网络,使得网络的收敛更快更稳定。至于batch normalization为何有效,这里简单提一下。神经网络的每一层输出,由于网络权重,都会导致数据的分布发生变化。这会对学习造成困难,因此每一层加上BN,使得每一层的输出和上一层的输出的分布保持一致。详情参见Batch Normalization
High Resolution Classifier
YOLO的训练分成两部分,第一部分是用ImageNet通过分类任务训练特征提取器,第二部分是用CoCo,VOC通过检测任务来对网络做fine-tuning。在v2中,第一部分里使用448×448而不是224×224的图片训练网络,高分辨率的样本进行训练会使得网络的检测效果更好,这一点显而易见。(更多的特征信息可以被学习)
Convolutional With Anchor Box
YOLOv1中最被诟病的region层被改变了,首先看一下两种结构对比。
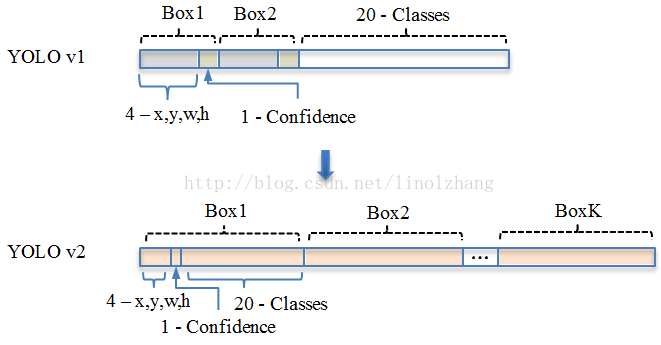
(特别提示,YOLOv1和v2中x,y,w,h的含义不一样,v1中是坐标,而v2中是偏差,详情见Anchor box)
可以发现,YOLOv1中每一个grid可以预测的obj的数量为B(B=2)个,并且在预测的时候每个grid实际上只输出一个BB(bounding box),而YOLOv2上升到了K(K=5)个,并且BB们会独立预测所属类,一个grid里面可以对多个不同类的物体做预测。比如这样的图片。

更多的预测框意味着检测结果的Precsion下降,而Recall 上升,但是根据论文结果,Precsion从69.5%下降到69.2%,Recall由81%提升到了88%。所以这一方法是行之有效,并且精度方面仍然存在改进空间(然后YOLOv3就这么做了)。
作者观察到,大物体通常占据了图像的中间位置,所以将图片的尺寸从448×448变为了416×416,这样做是为了让网络里所有卷积层产生的特征图,尺寸都为奇数,从而使得在预测物体位置的时候只需要中间位置的一个grid,而不是四个grid。
Anchor Box
anchor box是在RCNN系列中被使用的,使用这个结构的原因是为了在一个grid里面能够预测多个不同类别的目标。而且,一般地,同一种对象,他们的框子基本属于同一种比例,比如人的检测框往往是瘦长的,而车辆的检测框要么是宽扁的,要么是方形的。所以为了获得更加精确的检测框,我们可以先精选出不同种类物体的典型检测框,然后在这个基础上进行修改。在YOLOv2中,我们精选出来的检测框数量为K(K=5)个,这个K值是YOLO的作者试出来的,下面将会介绍。所以对于每一个grid,其特征向量的长度为(5+C)×K,即
关于Anchor box的资料找了好久啊,才在RCNN里面的支持材料里面找到。
这个东西叫做Bounding Box Regression。首先我们看看直接预测
有什么不好的地方呢?

还记得YOLO是怎么算loss的嘛。如果你有一个预测框,而图像中有多个GT框,那么你是跟哪个GT框算loss呢?答案是在IoU超过0.5的情况下,跟IoU最大的那个。现在来看上面这个图,我们会觉得这个模型预测飞机基本可以了,但是在模型看来,它预测出来的框和GT框的IoU没有达到0.5,直接预测失败,给了模型一个大的loss回去迭代了,极端点就是本来快收敛了,又搞这么几下,迭代回去了。那么如果我们能再调整一下这个预测框的长宽大小和比例的话,使得这个框子更加接近GT框,我们就不需要对模型进行大的调整,这样精度更高收敛速度更快。Bounding Box Regression就是来调整这个框子的位置,使其更加准确的。

我们的目的就是,给定
,寻找一种映射
,使得
,达到
。
那么这个映射应该是个什么样子呢?什么样的映射可以使得一个size的框变成另一个size的框?
最容易想到的就是平移加变换。平移框子中心坐标
,放缩框子尺寸
。所以RCNN给出了公式如下。
我们来分析一下为什么公式这么定义。
首先这个
是什么?
P不是上面说的那个四个坐标,而是RCNN的Pool5 feature(特征向量),
表示参数化的函数,而
表示对其参数化后得到的变换。
先说(1)(2)两个公式,也许有人会问为什么要加上 ,直接回归偏移不好吗?不好的地方在这。CNN具有尺寸不变性,也就是说一个物体,无论是大还是小,从它身上提取出来的特征应该始终不变。如果直接回归偏移,那么对于一个大物体,它的特征设为 ,那么 ,假设已经完全精确。现在把这个物体缩小,CNN从中提取的特征是不变的,仍然为 ,那么对于这个小物体的预测框坐标x的回归,偏移仍然是 ,这显然是不对的。所以要乘上 ,使其等比例放缩偏差。

再说(3)(4)两个公式,为什么用 函数,有人说这是为了保持放缩系数始终大于0。我个人看法不是这样,不然为什么不用平方呢?论文里面说的很清楚,这是为了把变换拉入log-space中。所以在这里使用了指数。为什么呢?翔宇大大说得好,log函数的特点是在定义域位于(0, 1)之间,值域很敏感,定义域在 时,越大越不敏感。在目标检测中对于大目标,如果你的预测框大一点或者小一点,IoU不会降得太多,而对于小目标,框子大小就变得非常重要了。可以想象一个特别小的物体,只有一个像素大小,那么框子稍微偏一点,或者大一点,IoU就会降低至接近于0。
所以最后的我们回归的变换公式就是:
(公式9翻回去就是4)
我们的真实值是 ,预测值是 ,线性回归嘛, ,这里的 就是我们要学习的参数,那loss函数就是
好,那现在问题就是真实值从哪儿来?当然是从GT框和预测框计算得来。预测框从哪儿来?(⊙o⊙)哦,预测框就是我们先精选出来的那些anchor boxes。模型学的就是微调,所以这就是为什么我们需要精选的Anchor box。说完收工。
Dimension Clusters
Anchor box那一段解释了为什么要有精选的anchor box,这段维度聚类就来解释怎么精选anchor box。
在RCNN中,anchor box被定义了9种,长宽比例是1:1, 1:2, 2:1,尺寸是128, 256, 512。这几个超参数怎么来的?可能是作者拍脑袋决定的。但是如果这几个框子的尺寸是从数据集中来的,是不是更具有代表性呢?所以YOLOv2采用了K-means聚类的方式来决定box的尺寸。K-means聚类的原理详细见这里。
在YOLOv2中,距离函数被定义为
为什么呢?因为传统的K-means聚类方法使用的是欧氏距离函数,也就意味着较大的boxes会比较小的boxes产生更多的error,聚类结果可能会偏离。所以作者采用的评判标准是IoU得分,这样的话,error就和box的尺度无关了。
那为什么K=5呢?这个超参数是作者试出来。

Direct location prediction
这里讲得还是跟anchor box有关。作者发现在训练的时候模型不稳定,特别是在早期的时候,YOLOv2在训练的时候学习率设置得十分鬼畜,前十步,前一百步都单独用了一个学习率学习。据论文的意思是这样可以快速找到极小值区域进行收敛。但是我自己用线性下降法设置学习率,其实收敛的也蛮好的~
扯远了,总之作者经过分析,发现不稳定现象出现的原因是因为预测这个box的
的偏移上了,也就是上文提到的公式
(6)(7)(公式(6)(7)翻过来就是公式(1)(2),利用预测的偏移来调整框子中心x,y)。为什么呢?因为你会发现这个偏移没有限制。YOLO是将图片划分成grid,每个grid在预测框子的x,y的时候,这个x,y就应该落在这个grid里面。但是上面这几个公式并没有限制住偏移,这个偏移可以把x,y带歪,就跟联想5g不投华为一样,歪得很。所以模型随机初始化后,需要花很长一段时间才能稳定预测敏感的物体位置。那么正确做法就是把偏差限制到计算后框子的中心坐标始终在它对应的grid里面。因此YOLOv2使用logistic函数进行约束(gt值也被拉入了0-1之间了)。
logistic:
现在的计算公式,设置当前grid的左上角,距离整个图像的左上角的边距为 ,当前grid的anchor box的长和宽为 ,那么预测的box的(x,y,w,h)为:
这里面的 函数没有给出具体的值,但可以猜测一下主要是在做归一化。然后有一个小疑问的地方就是,我觉得 的公式中, 函数前面应该乘上grid的长。

两项改进anchor box的方法,使得mAP上升了5%。
Fine-Grained Features
补充
1.Precsion和Recall