作者:Luca Wintergerst, David Hope, Bahubali Shetti

当今的快速软件开发过程需要不断扩展且复杂的基础设施和应用程序组件,并且运营和开发团队的工作不断增长且涉及多个方面。 可观察性有助于管理和分析遥测数据,是确保应用程序和基础设施性能和可靠性的关键。 特别是,日志是开发人员启用的主要默认信号,为调试、性能分析、安全性和合规性管理提供了大量详细信息。 那么如何定义策略来充分利用日志呢?
在这篇博文中,我们将探讨:
- 日志记录之旅,回顾日志的收集、处理和丰富、分析和合理化
- 管理日志中的结构化数据和非结构化数据之间的区别
- 跟踪是否应该取代日志
- 通过了解如何减少转换时间、集中式与分散式日志存储以及如何以及何时减少存储内容,提高日志的运营效率
通过更深入地了解这些主题,你将能够更好地有效管理日志并确保应用程序和基础设施的可靠性、性能和安全性。
记录日志之旅
日志记录过程涉及三个基本步骤:
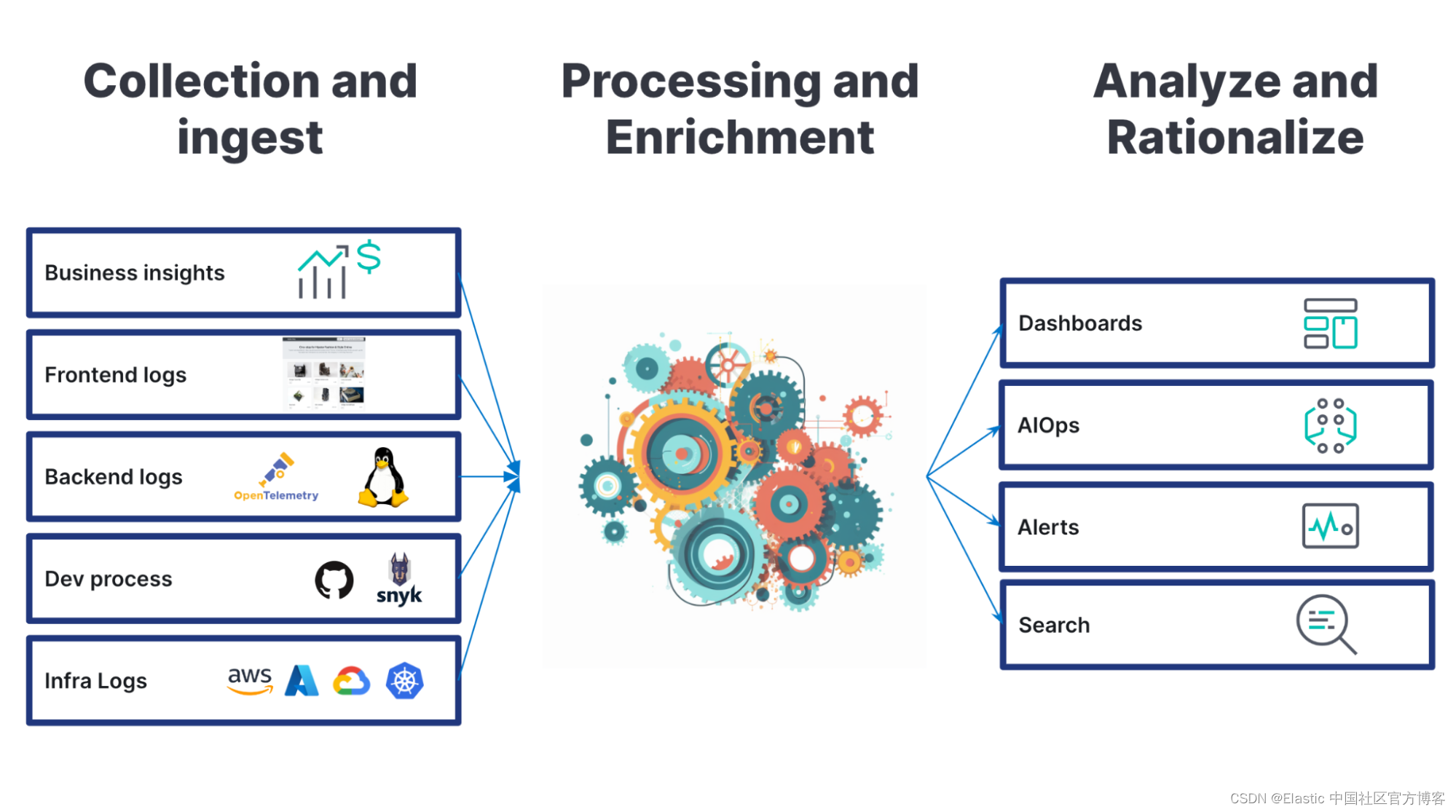
让我们介绍如何收集和摄取日志、什么是正确的解析和处理以及如何分析和合理化日志。 此外,我们还将讨论如何通过应用程序性能监控 (APM)、指标和安全事件来增强这一旅程。
日志采集
日志记录之旅的第一步是将你拥有的所有日志收集到一个中心位置。 这涉及识别你的所有应用程序和系统并收集它们的日志。
日志收集的一个关键方面是在所有应用程序和基础设施中实现最大程度的标准化。 拥有共同的语义模式非常重要。 Elastic 向 OpenTelemetry (OTel) 贡献了 Elastic Common Schema (ECS),帮助加速采用基于 OTel 的可观察性和安全性。 这将转向一种更规范的方式来定义和摄取日志(包括指标和跟踪)。
日志收集的另一个重要方面是确保你以较低的成本拥有足够的摄取容量。 进行此评估时,你可能需要谨慎对待对高基数数据收取倍数费用的解决方案。 一些可观测性解决方案将为此收取高昂费用,这就是为什么在此步骤中了解扩展能力和成本至关重要的原因。
处理和丰富日志
收集日志后,你可以开始处理日志文件并将它们放入通用架构中。 这有助于标准化你的日志,并更轻松地聚合最重要的信息。 标准化模式还可以更轻松地跨源进行数据关联。 在将日志数据处理为标准化模式时,你需要考虑:
- 大多数可观察性工具都具有开箱即用的集成,可将数据转换为特定的已知模式。 如果没有可用的开箱即用集成,则可以使用正则表达式或类似方法来解析信息。
- 管理日志处理通常是在某种摄取管道中完成的。 你可以使用涉及 Kafka、Azure Service Bus 或 Pulsar 的流数据管道的可扩展且复杂的架构,甚至可以使用 Logstash 或 Kafka Streams 等处理框架。 没有对错之分,但我们的建议是要小心,不要在这里增加太多的复杂性。 存在这样的危险:如果你在此处添加流数据处理步骤,你最终可能会得到一个为期数月的项目和大量需要维护的代码。
Elastic 提供了多种摄取(即 AWS Kensis Data Firehose)和处理(解析非结构化日志、丰富日志,甚至对其进行正确分类)的方法。
摄取数据后,可能需要提取和丰富该数据,并且可能还需要根据日志文件中的数据创建指标。 做这件事有很多种方法:
- 一些可观察性仪表板功能可以执行运行时转换,以动态地从未解析的源中提取字段。 这通常称为读取时模式。 这在处理可能不以标准化格式记录数据的遗留系统或自定义应用程序时非常有用。 然而,运行时解析可能非常耗时且占用资源,特别是对于大量数据。
- 另一方面,写入时模式提供了更好的性能和对数据的更多控制。 schema 是预先定义的,数据是在编写时构建和验证的。 这允许更快地处理和分析数据,这有利于丰富。
日志分析
搜索、模式匹配和仪表板
合乎逻辑且传统的下一步是构建仪表板并设置警报以帮助你实时监控日志。 仪表板提供日志的可视化表示,使识别模式(patterns)和异常变得更加容易。 警报可以在发生特定事件时通知你,以便你快速采取行动。 利用全文搜索的强大功能,可以轻松地从日志创建指标。 例如,你可以搜索术语 “error”,搜索功能将找到所有源中的所有匹配条目。 然后可以显示结果或发出警报。 此外,你还将在仪表板时搜索日志并查找模式。
然后,机器学习可用于分析日志并识别通过手动分析可能不可见的模式。 机器学习可用于检测日志中的异常情况,例如异常流量或错误。 此外,日志分类功能等功能可以自动跟踪正在索引的日志数据类型并检测该模式的任何变化,这些功能可能很有用。 这可用于检测新的应用程序行为或你可能错过的其他有趣事件。
机器学习 —— 发现潜伏在日志文件中的未知事物
建议组织使用各种机器学习算法和技术,以帮助你更有可能有效地发现日志文件中的未知事物。
应采用无监督机器学习算法,例如聚类(x 均值、BIRCH)、时间序列分解、贝叶斯推理和相关性分析,对实时数据进行异常检测,并根据严重性进行速率控制警报。
通过自动识别影响者,用户可以获得有价值的背景信息以进行自动根本原因分析 (root cause analysis - RCA)。 日志模式分析对非结构化日志进行分类,而日志速率分析和变化点检测有助于识别日志数据峰值的根本原因。 这些方法相结合提供了一种强大的方法来发现日志文件中隐藏的见解和问题。

除了帮助 RCA 之外,发现未知的未知因素并改进故障排除组织还应该寻找预测功能来帮助他们预测未来需求并校准业务目标。
增强旅程
最后,在收集日志时,你可能还想收集指标或 APM 数据。 指标可以让你深入了解系统的性能,例如 CPU 使用率、内存使用率和网络流量,而 APM 可以帮助你识别应用程序的问题,例如响应时间慢或错误。 虽然不是必需的,但特别是指标数据与日志数据密切相关,并且设置起来也非常容易。 如果你已经从系统中收集日志,那么额外收集指标通常不会花费超过几分钟的时间。 作为运营人员,你不仅要始终跟踪部署的安全性,还要跟踪部署的人员和内容,因此通过 APM 和指标添加和使用安全事件有助于完善情况。
结构化日志对比非结构化日志?
日志记录过程中的一个普遍挑战是管理非结构化和结构化日志,特别是在摄取期间进行解析。
使用已知模式管理日志
幸运的是,一些工具为流行的源提供了广泛的内置集成,例如 Apache、Nginx、Docker 和 Kubernetes 等。 这些集成可以轻松地从不同来源收集日志,而无需花费时间构建自定义解析规则或仪表板。 这节省了时间和精力,并使团队能够专注于分析日志,而不是解析或可视化它们。
如果你没有来自流行来源的日志(例如自定义日志),你可能需要定义自己的解析规则。 许多可观测性日志记录工具将为你提供这种功能。
因此,结构化日志通常比非结构化日志更好,因为它们提供更多价值并且更易于使用。 结构化日志具有预定义的格式和字段,使提取信息和执行分析变得更加容易。
非结构化日志怎么样?
可观察性工具中的全文搜索功能可以帮助减少对非结构化日志潜在限制的担忧。 全文搜索是一个强大的工具,可以通过对日志进行索引来从非结构化日志中提取有意义的信息。 全文搜索允许用户搜索日志中的特定关键字或短语,即使日志未经过解析。
默认情况下对日志进行索引的主要优点之一是它有助于以有效的方式搜索日志。 如果事先已建立索引,即使是大量数据也可以快速搜索,以便找到你正在查找的特定信息。 这可以在分析日志时节省时间和精力,并可以帮助你更快地识别问题。 通过将所有内容都编入索引并可搜索,你无需编写正则表达式、学习复杂的查询语言或等待很长时间才能完成搜索。
你应该将日志移至跟踪中吗?
日志长期以来一直是应用程序监控和调试的基石。 然而,虽然日志是任何监控策略不可或缺的一部分,但它们并不是唯一可用的选择。
例如,跟踪是对日志的宝贵补充,可以提供对特定事务或请求路径的更深入的了解。 事实上,如果实施正确,跟踪可以作为应用程序(相对于基础设施)的附加检测手段对日志记录进行补充,特别是在云原生环境中。 跟踪可以提供更多上下文信息,尤其擅长跟踪环境中的依赖关系。 与日志数据相比,任何连锁反应在跟踪数据中都更容易看到,因为跨服务端到端地跟踪单个交互。
尽管跟踪可以提供多种优势,但考虑使用跟踪的局限性也很重要。 实现跟踪仅适用于你拥有的应用程序,并且你不会获得基础设施的跟踪,因为它仍然仅限于应用程序。 并非所有开发人员都完全同意使用跟踪来替代日志记录。 许多开发人员仍然默认将日志记录作为检测的主要手段,这使得很难完全采用跟踪作为监控策略。
因此,采用组合的日志记录和跟踪策略非常重要,其中跟踪可以覆盖较新的检测应用程序,而日志记录将支持你不拥有其源代码的遗留应用程序和系统,并了解你不拥有其源代码的系统的状态。
提高日志运行效率
管理日志时,主要有以下三个方面会降低运行效率:
- 需要花大量时间转换日志
- 管理日志信息的存储和检索
- 何时删除或从日志中删除哪些内容
我们将在下面讨论管理这些问题的策略。
减少转换数据所花费的时间
由于大量日志具有不同的模式集,甚至是非结构化日志,组织可能会花费更多的时间在不必要的数据转换上,而不是理解问题、分析根本原因或优化操作。
通过根据通用模式构建数据,运营团队将能够专注于识别、解决和预防问题,同时缩短平均解决时间 (MTTR)。 运营还可以通过没有重复数据并且不必处理数据进行标准化来降低成本。
业界正在通过 OpenTelemetry Semantic Convention 项目实现这种标准化,该项目试图为日志、指标、跟踪和安全事件实现通用模式。 由于 Elastic Common Schema (ECS) 最近对 OpenTelemetry 的贡献,日志尤其强大,这有助于加强通用模式之旅。
一个简单的说明性示例是当客户端的 IP 地址从监视或管理有关客户端的遥测数据的多个源发送时。
src:10.42.42.42
client_ip:10.42.42.42
apache2.access.remote_ip: 10.42.42.42
context.user.ip:10.42.42.42
src_ip:10.42.42.42以多种方式表示 IP 地址会给分析潜在问题甚至识别问题带来复杂性。
通过通用模式,所有传入数据都采用标准化格式。 以上面的示例为例,每个源都会以相同的方式识别客户端的 IP 地址。
source.ip:10.42.42.42这有助于减少花费时间转换数据的需要。
集中式 vs 去中心化日志存储
在管理日志数据时,数据局部性是一个重要的考虑因素。 传入和传出大量日志数据的成本可能非常高,尤其是在与云提供商打交道时。
如果没有区域冗余要求,你的组织可能没有令人信服的理由将所有日志数据发送到中央位置。 你的日志记录解决方案应该提供一种方法,允许你的组织将其日志数据保存在生成日志数据的本地数据中心。 这种方法有助于降低与通过网络传输大量数据相关的入口和出口成本。
跨集群(或跨部署)搜索功能使用户能够同时跨多个日志记录集群进行搜索。 这有助于减少需要通过网络传输的数据量。
如果你的组织需要在发生灾难时保持业务连续性,那么跨集群复制是你可能需要考虑的另一个有用功能。 通过跨集群复制,即使在其中一个数据中心发生故障的情况下,组织也可以通过自动将数据复制到第二个目的地来确保其数据可用。 通常,此方法仅用于最关键的数据,同时利用上述数据局部性来处理最大的数据源。
另一个值得考虑的相关主题是供应商锁定。 一些日志记录解决方案会在获取数据后锁定数据,如果组织想要更换供应商,则很难或不可能提取数据。
并非每个供应商都是如此,组织应该检查以确保他们可以随时完全访问所有原始数据。 这种灵活性对于希望能够更换供应商而不被锁定到专有日志记录解决方案的组织来说至关重要。
处理大量日志数据 - 记录所有内容、丢弃所有内容或减少使用量?
处理大量日志数据可能是一项具有挑战性的任务,特别是当系统和应用程序生成的数据量持续增长时。 此外,合规性要求可能会强制记录某些数据,并且在某些情况下,所有系统的日志记录可能不受你的控制。 减少数据量似乎不切实际,但有一些优化可以提供帮助:
1)收集所有内容,但制定日志删除策略。 组织可能想要评估收集哪些数据以及何时收集。如果你发现需要该数据进行故障排除或分析,则在源头丢弃数据可能会导致以后出现问题。 评估何时删除数据。 如果可能,设置自动删除旧数据的策略,以帮助减少手动删除日志的需要以及意外删除仍需要的日志的风险。
一个好的做法是尽早丢弃 DEBUG 日志甚至 INFO 日志,并尽快删除开发和暂存(staging)环境日志。 根据你使用的产品,你可以灵活地设置每个日志源的保留期限。 例如,你可以将暂存日志保留 7 天,将开发日志保留一天,将生产日志保留一年。 你甚至可以更进一步,按应用程序或其他属性拆分它。
2)进一步的优化是聚合相同日志行的短窗口,这对于 TCP 安全事件日志记录尤其有用。 只需聚合相同的日志行并生成计数,再加上开始和结束时间戳即可。 这可以很容易地以提供足够保真度的方式展开,并节省大量存储空间。 可以使用预处理工具来执行此操作。
3)对于你控制的应用程序和代码,你可能会考虑将一些日志移至跟踪中,这将有助于减少日志量。 但痕迹仍然会构成额外的数据。
将其整合在一起
在这篇文章中,我们提供了日志记录过程的视图以及本文中需要考虑的几个挑战。 在介绍日志记录过程时,涉及三个基本步骤 —— 收集和摄取、解析和处理以及分析和合理化——我们强调了以下几点:
- 重要的是要确保在日志收集阶段基础设施中没有盲点,并专注于在源头制作结构化日志。
- 提取数据和丰富日志可以通过读取模式或写入模式方法来实现,机器学习可用于分析日志并识别通过手动分析可能不可见的模式。
- 组织还应该收集指标或 APM 数据来增强他们的日志记录之旅。
我们讨论了几个关键挑战:
- 结构化日志更容易使用并提供更多价值,但非结构化日志可以通过全文搜索功能进行管理。
- 跟踪可以提供对特定 transaction 和依赖关系的更深入的了解,有可能取代日志记录作为主要的检测手段,但由于限制和开发人员的采用,组合的日志记录和跟踪策略非常重要。
- 组织可以通过专注于减少转换数据所花费的时间、在集中式或分散式日志存储之间进行选择以及通过实施日志删除策略和聚合相同日志行的短窗口来处理大量日志数据来帮助提高日志的运营效率。
原文:Effective log management in software development and operations | Elastic Blog