| 序号 | 内容 |
|---|---|
| 1 | 【Python】Pandas 简介,数据结构 Series、DataFrame 介绍,CSV 文件处理,JSON 文件处理 |
| 2 | 【Python】Pandas 数据清洗操作,常用函数总结 |
1. Pandas 简介
Pandas 是 Python 语言的一个扩展程序库,用于数据分析,其提供了高性能、易于使用的数据结构和数据分析工具。Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
2. Pandas 数据结构
Pandas 的主要数据结构是
- Series(一维数据)
- DataFrame(二维数据)
1. Series(一维数据)
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)。index:数据索引标签,如果不指定,默认从 0 开始。dtype:数据类型,默认会自己判断。name:设置名称。copy:拷贝数据,默认为 False。
程序代码的例子参考:Pandas 数据结构 - Series。
2. DataFrame(二维数据)
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
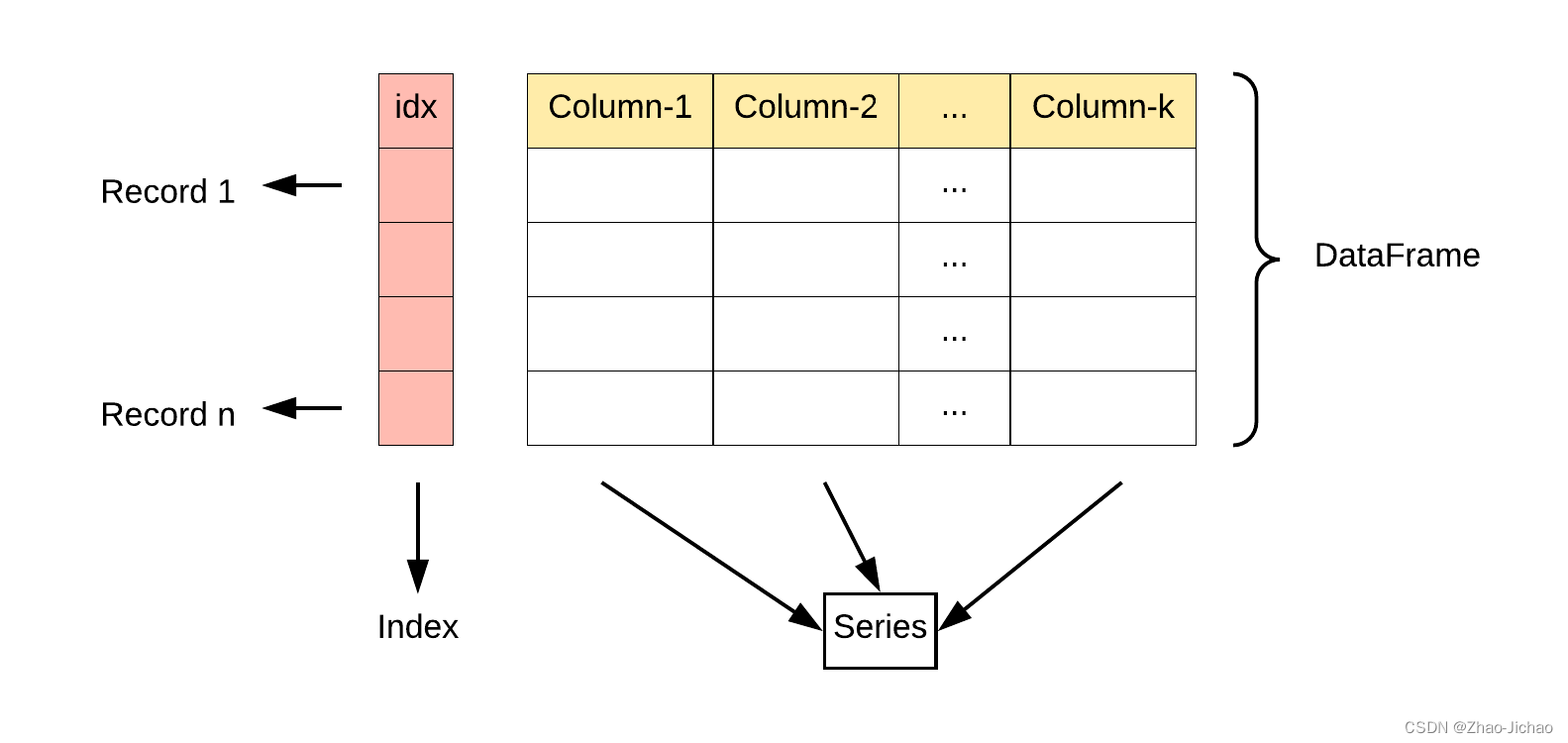
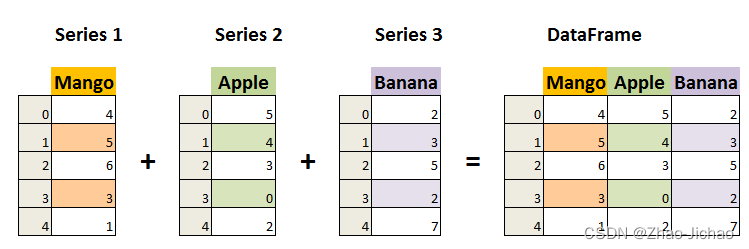
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)。index:索引值,或者可以称为行标签。columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。dtype:数据类型。copy:拷贝数据,默认为 False。
没有对应的部分数据为 NaN。
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1。
程序代码的例子参考:Pandas 数据结构 - DataFrame。
3. 处理 CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
to_csv() 方法将 DataFrame 存储为 csv 文件。
import pandas as pd
df = pd.read_csv('nba.csv')
df.to_csv('site.csv')
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
info() 方法返回表格的一些基本信息:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
4. 处理 JSON 文件
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
下面是名字为 sites.json 文件的数据内容:
[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
import pandas as pd
df = pd.read_json('sites.json')
print(df.to_string())
JSON 对象与 Python 字典具有相同的格式,所以我们也可以直接将 Python 字典转化为 DataFrame 数据。
从 URL 中读取 JSON 数据:
import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df)
json_normalize() 方法可以将内嵌的数据完整的解析出来。