Gym 简明教程【1. Basic Usage v0.26.2版本】
文章目录
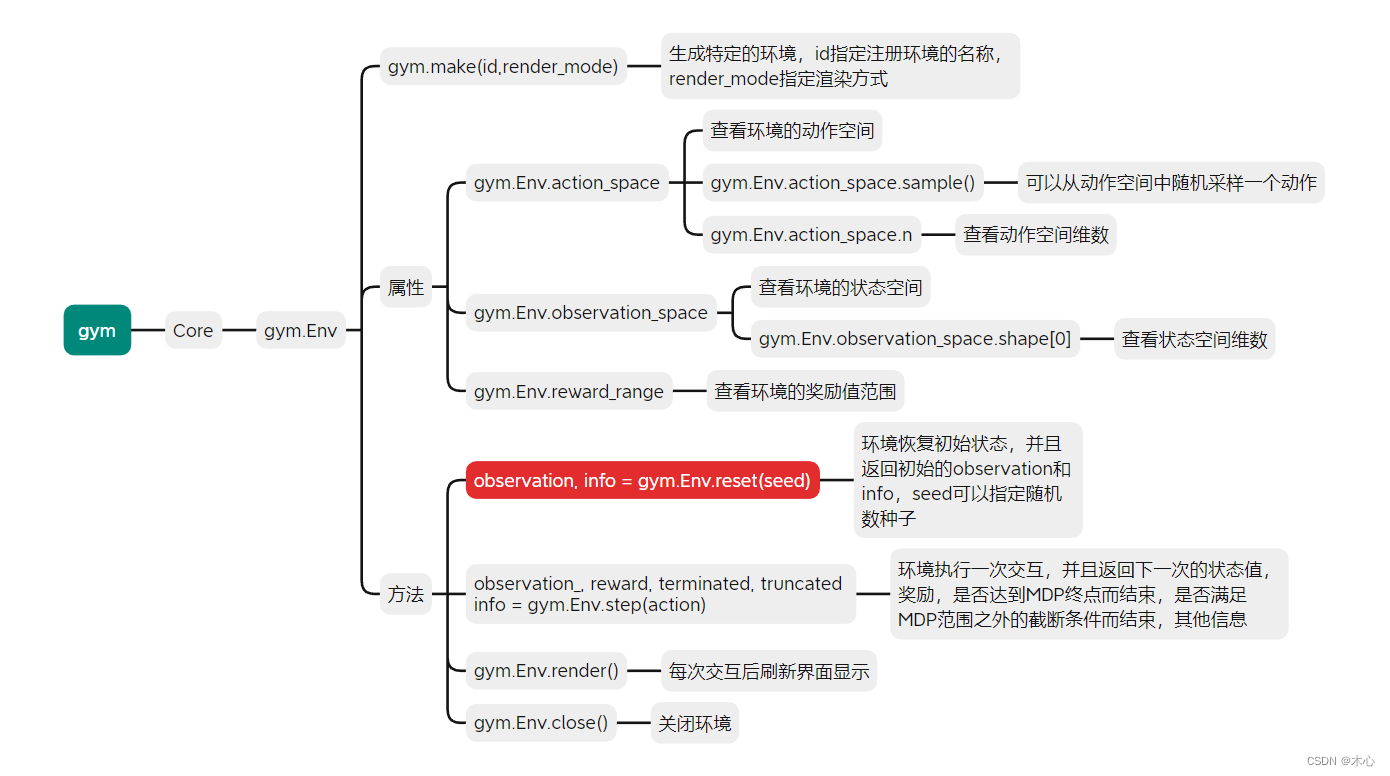
1. 构建gym环境
使用gym.make(id,render_mode)我们可以注册一个环境,然后我们可以查看一下这个环境的一些信息,比如action space或者state space等
常用的信息查看方式
env.action_space
# 查看这个环境中可用的action有多少个,返回Discrete()格式
env.observation_space
# 查看这个环境中observation的特征,返回Box()格式
n_actions=env.action_space.n
# 查看这个环境中可用的action有多少个,返回int
n_features=env.observation_space.shape[0]
# 查看这个环境中observation的特征有多少个,返回int
import gym
if __name__ == "__main__":
env = gym.make(id='CartPole-v1')
print(env.action_space)
print(env.observation_space)
print(env.reward_range)
显示的结果如下
Discrete(2)
Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
(-inf, inf)
可以看出,该环境的动作空间是离散的且只有两个动作,状态包含了一些数据,奖励范围是从正无穷到负无穷。
action_space是一个离散Discrete类型,从 discrete.py 源码可知,范围是一个{0,1,...,n-1}长度为n的非负整数集合,在CartPole-v1例子中,动作空间表示为{0,1}。observation_space是一个Box类型,从 box.py 源码可知,表示一个n维的盒子,所以在上一节打印出来的observation是一个长度为 4 的数组。数组中的每个元素都具有上下界。
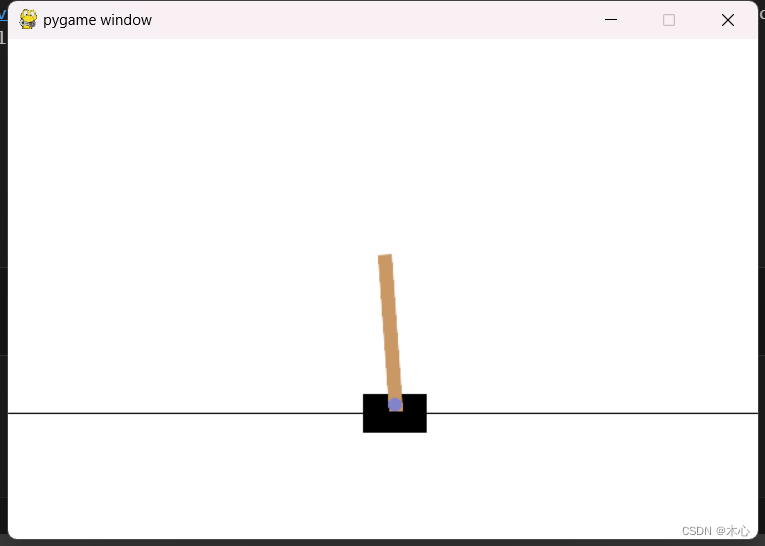
如果在构建的时候指定显示渲染,那么则可以看到有游戏图像出现
import gym
if __name__ == "__main__":
env = gym.make(id='CartPole-v1', render_mode='human')
env.reset()
for _ in range(100):
env.render()
env.close()
图像如下所示
2. gym.Env常用method
常用的method包括
-
gym.Env.reset()恢复初始状态,并且返回初始状态的observation -
gym.Env.render()显示图像,只有先reset了才能进行显示 -
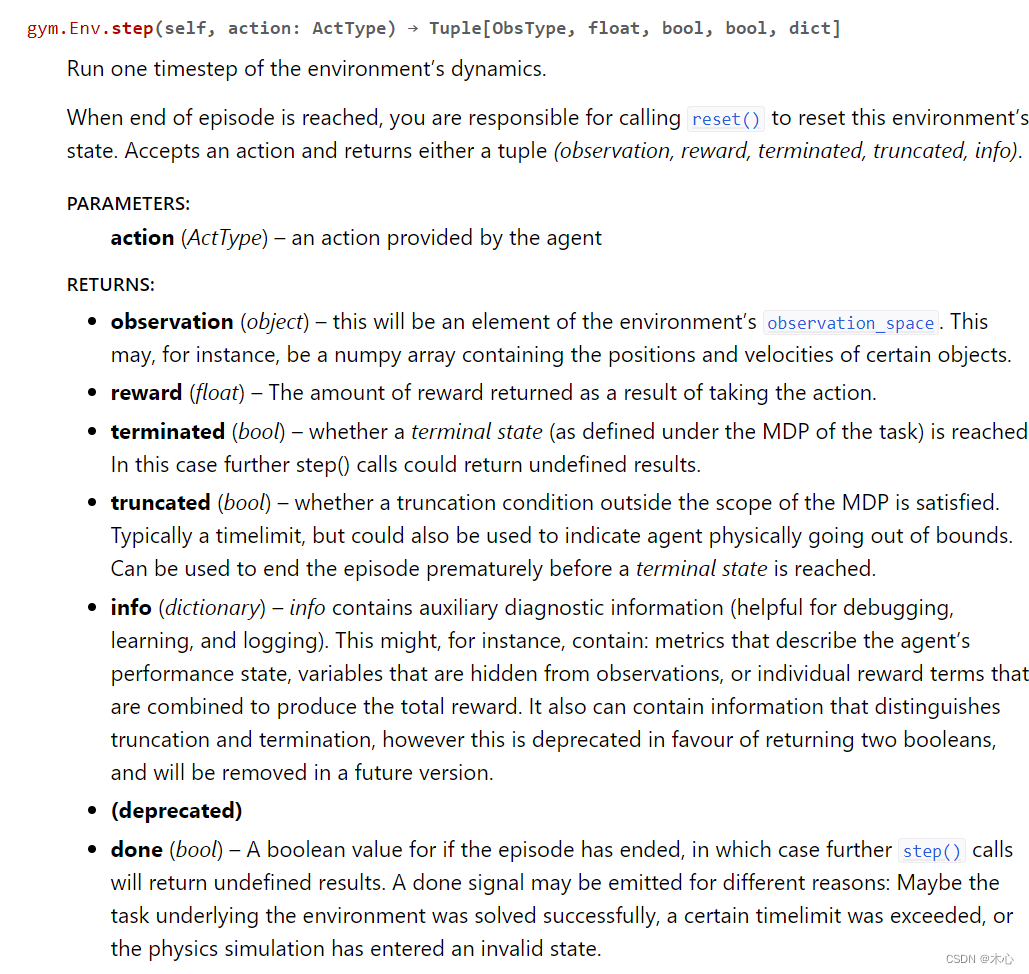
gym.Env.step()执行一部交互,并且返回observation_, reward, termianted, truncated, infoobservation_是下一次观测值reward是执行这一步的奖励terminated是否是因为到达MDP终点而结束truncated是否是因为MDP之外的截断条件而结束info针对调试过程的诊断信息。在标准的智体仿真评估当中不会使用到这个 info。
详细信息如下图所示,详见官网
gym.Env.close()关闭环境
下面介绍常用的强化学习范式
import gym
episodes = 10
timesteps = 100
if __name__ == "__main__":
env = gym.make(id='CartPole-v1',render_mode='human')
for e in range(episodes):
observation, info = env.reset()
done = False
while not done:
env.render()
action = env.action_space.sample()
observation_, reward, terminated, truncated, info = env.step(action)
done = termianted or truncated
agent.learn()
env.close()
3. 关于 gym 0.26.2新版本的更改
最重要的一个更改就是gym.Env.reset()返回的值新增了info这一项,官网上解释说:gym.Env.reset()的返回值有两项,第一项是类似于gym.Env.step()的返回值,是observation,第二项是提示信息info,这一项不常用,可以用__来接收然后丢弃。
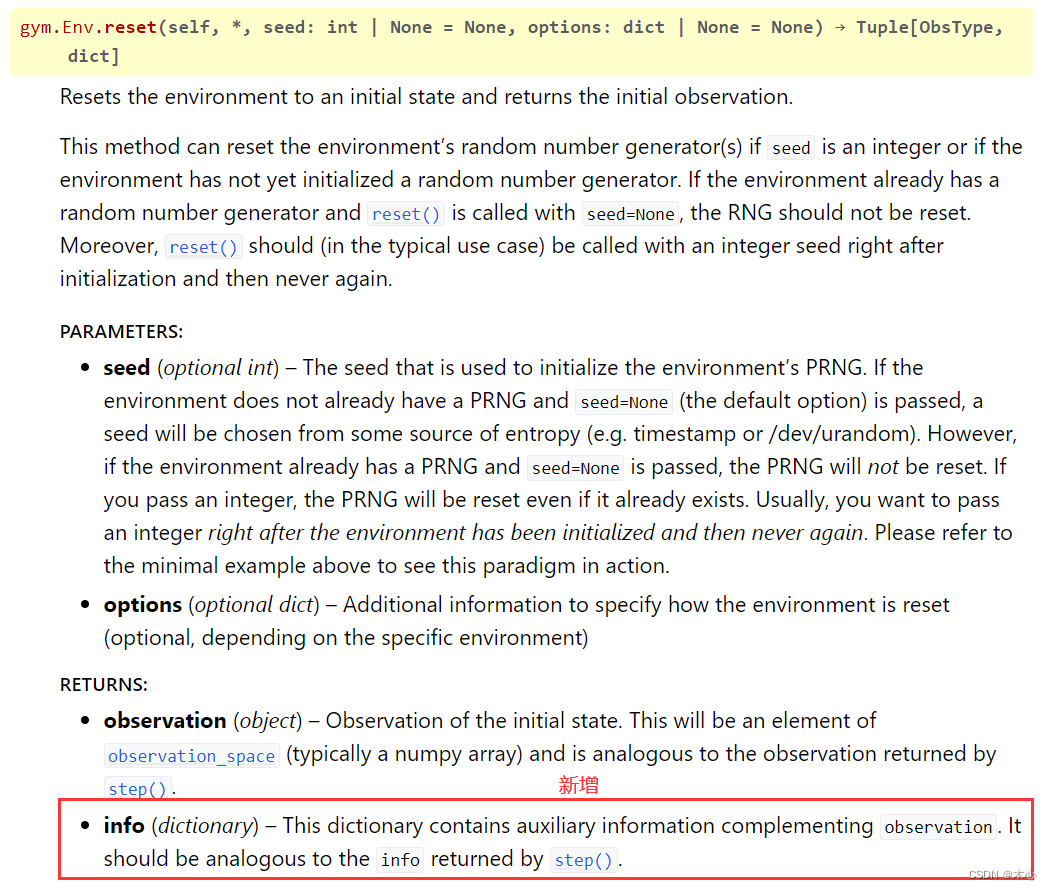
以CartPole-v1环境为例
import gym
if __name__ == "__main__":
env = gym.make(id='CartPole-v1',render_mode='human')
observation, _ = env.reset()
observation_, reward, terminated, truncated, _ = env.step(1)
print(observation)
print(observation_)
print(reward)
print(terminated)
print(truncated)
env.close()
结果如下
[ 0.03654356 0.002174 0.04146604 -0.0444533 ]
[ 0.03658704 0.19667757 0.04057698 -0.32377034]
1.0
False
False
4. Reference
[官网教程](