前言:
在使用yolov5之前,尝试过到百度飞桨平台(小白不建议)、AutoDL平台(这个比较友好,经济实惠)训练模型。但还是没有本地训练模型来的舒服。因此远程了一台学校电脑来搭建自己的检测模型。配置嘛!勉强过的去。毕竟训练的模型也不是很大。本来想着也想搞一些nb轰轰的模型,但想想还是算了,一是经济(云平台,只想白嫖),二是时间(准备那些数据集就非常浪费时间,自己昨天制作的那150关于猫的label就标了三四个小时,还标错了,导致训练时全部返工,真的烦),三是学校电脑配置还是不咋行,训练完估计模型精度也就那样子。想想嘛!还是根据喜好训练一个模型吧!
使用yolov5进行本地部署的原因:
推荐使用YOLOv5训练检测模型有以下几个原因:
1. 高性能:YOLOv5在检测任务上具有出色的性能。相比于之前的版本,YOLOv5采用了更深的网络结构和更多的特征层,可以提供更准确的检测结果,并且在速度上也有所提升。
2. 简单易用:YOLOv5提供了一个简单的训练和测试框架,使得用户可以轻松地进行模型的训练和评估。用户只需要准备好训练数据,并进行简单的配置,就可以开始训练模型。
3. 多平台支持:YOLOv5支持多种平台,包括CPU、GPU和TPU等。这使得用户可以根据自己的需求选择合适的硬件平台来进行训练和推理。
4. 开源社区支持:YOLOv5是一个开源项目,有一个庞大的开源社区支持。这意味着用户可以从社区中获取到丰富的资源、教程和解决方案,以帮助他们更好地使用和优化YOLOv5模型。
综上所述,YOLOv5是一个性能优秀、简单易用、多平台支持且有开源社区支持的检测模型,因此推荐使用它进行训练和应用。
数据预处理:
xml文件转txt文件
在使用yolov5训练模型之前,需要将label目录下的xml文件转为txt文件。


转换代码如下
import os
import xml.etree.ElementTree as ET
import os
import xml.etree.ElementTree as ET
def convert_xml_to_yolov5_label(xml_file, txt_file):
tree = ET.parse(xml_file)
root = tree.getroot()
with open(txt_file, 'w') as f:
for obj in root.findall('outputs/object/item'):
class_name = obj.find('name').text
bbox = obj.find('bndbox')
x_min = float(bbox.find('xmin').text)
y_min = float(bbox.find('ymin').text)
x_max = float(bbox.find('xmax').text)
y_max = float(bbox.find('ymax').text)
width = x_max - x_min
height = y_max - y_min
x_center = x_min + width / 2
y_center = y_min + height / 2
# 将坐标归一化到0-1之间
width /= float(root.find('size/width').text)
height /= float(root.find('size/height').text)
x_center /= float(root.find('size/width').text)
y_center /= float(root.find('size/height').text)
f.write(f"{class_name} {x_center} {y_center} {width} {height}\n")
def batch_convert_xml_to_yolov5_label(xml_folder, txt_folder):
if not os.path.exists(txt_folder):
os.makedirs(txt_folder)
for file in os.listdir(xml_folder):
if file.endswith('.xml'):
xml_file = os.path.join(xml_folder, file)
txt_file = os.path.join(txt_folder, file.replace('.xml', '.txt'))
convert_xml_to_yolov5_label(xml_file, txt_file)
# 示例用法
xml_folder = r'C:\Users\1\Desktop\images\labelsxml'
txt_folder = r'C:\Users\1\Desktop\images\labels'
batch_convert_xml_to_yolov5_label(xml_folder, txt_folder)
划分训练集和验证集
因为数据集比较少,所以验证集部分直接使用训练集来做验证。
数据目录结构如下:
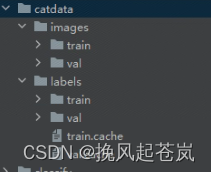
编写data目录yaml文件(索引文件,加载数据的访问路径以及检测类别)
# 数据集根路径
path: C:\Users\1\Desktop\catmaoxunlian\catdata
#训练集
train: images/train
#验证集
val: images/val
nc: 1
# Classes
names: ['cat']示例编辑如下

编写models目录下的yum文件

模型训练
找到yolov5目录下的train.py,加载数据集yaml文件和models云文件,以及预训练模型,
详细教程请找我的另一篇博客(懒得再写一遍)基于yolov5的NEU-NET产品缺陷目标检测_map50_挽风起苍岚的博客-CSDN博客

基本上检测出来了,不过精度不是很高,精度不高的原因,主要时数据集太少(猫的类别很多),训练次数不是很够。

模型推理
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/LNwODJXcvt4' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream测试图片如下:

模型推理后的结果
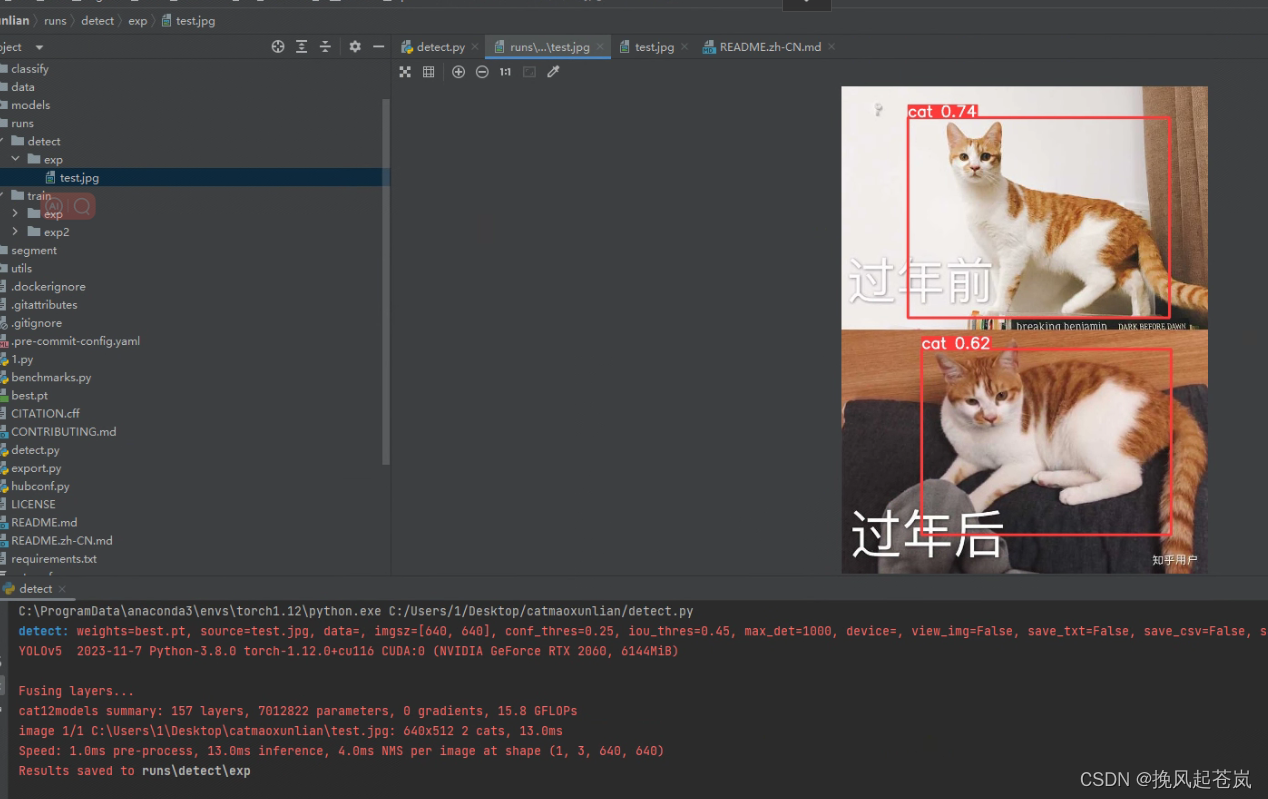
额,模型精度有待加强,不过先这样吧!勉勉强强,哈哈。。。
后续内容
训练一个猫12分类的模型;
部署到云平台,开放一个接口调用模型API;
然后结合猫目标检测模型制作一个C#小程序。
增加一个GPT功能等等吧!
....