前言
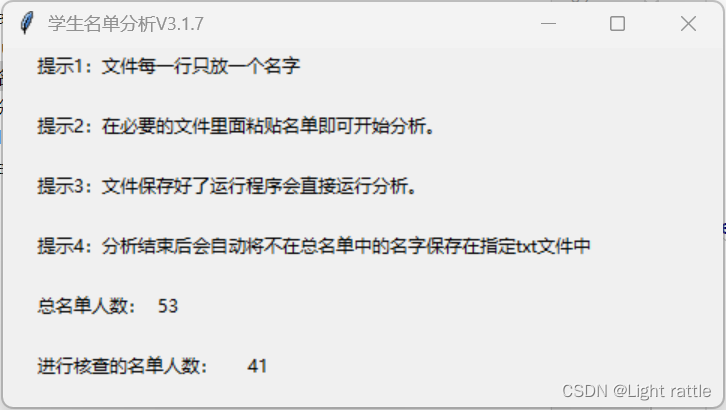
之前在担任学习委员的时候经常需要填在线表格,同时又要检查这个表格哪些人填过了哪些人没填过,由于在线表格内的人名是无序的,一个个核对名单非常麻烦,于是我用当时学习的Python写了一个名单分析程序,效果如下:
一、程序逻辑
(一)输入文件
这个程序是读入外部文件后对外部文件的数据进行分析,所以首先是外部文件的格式。这里我采用Excel的表格形式(因为是腾讯在线表,以表格形式可以直接复制粘贴):
一个总名单Excel文件、一个待判断名单Excel文件即可。
(二)输出文件
第一个操作是在程序中添加消息框直接显示结果;第二个操作是读入外部文件将比较结果存放在外部文件中。由于我将名单比较出来的目的是为了催那些还没填表的人,所以我对结果没有格式要求,所以我就直接使用的.txt文档存放结果(实际上只有消息框也是可达到我的目的,但我为了防止我不小心将结果消息×掉,我就将结果同时保存在.txt文件中)。
(三)比较过程
执行的事件是在N个数据中比对M(M≤N)个数据,并将剩下的N-M个数据记录下来,所以我直接使用遍历法解决问题(两个for循环)。
二、程序代码
(一)引用的库:
import pandas as pd
import tkinter as tk
import tkinter.messagebox as messagebox
(二)分析类:
下面是执行分析的分析类 analyse。
class analyse:
def __init__(self):
self.file1=[]#打开文件1
self.file2=[]#打开文件2
self.thing1=[]
self.thing2=[]
self.anaresult=[]#无重复,作为分析结果;如果有重复,将作为总人数名单分析结果
self.anaresult1=[]#如果有重复,将作为待分析人数名单分析结果
self.int1=1#总名单人数
self.int2=1#待分析人数
def main(self):
self.root=tk.Tk()#GUI界面
self.root.geometry("480x240")
self.root.title("学生名单分析V3.1.7")
self.thing1=pd.read_excel("G:/学习委员相关/名单分析程序/The all students.xlsx",index_col='姓名')
self.thing2=pd.read_excel("G:/学习委员相关/名单分析程序/The judge students.xlsx",index_col='姓名')
label1=tk.Label(self.root,text="提示1:文件每一行只放一个名字").place(x=20,y=1)
label2=tk.Label(self.root,text="提示2:在必要的文件里面粘贴名单即可开始分析。").place(x=20,y=41)
label3=tk.Label(self.root,text="提示3:文件保存好了运行程序会直接运行分析。").place(x=20,y=81)
label4=tk.Label(self.root,text="提示4:分析结束后会自动将不在总名单中的名字保存在指定txt文件中").place(x=20,y=121)
#messagebox.showinfo("注意","内测版本,如需要正常使用查重和遗漏功能,请使用Excel提前进行排序!")
label5=tk.Label(self.root,text="总名单人数:").place(x=20,y=161)
label6=tk.Label(self.root,text="进行核查的名单人数:").place(x=20,y=201)
analyse.judrepeat(self,self.anaresult,self.thing1,self.thing2)#检查重复数据
self.root.mainloop()
def judrepeat(self,anaresult,thing1,thing2):
list1=self.thing1.index
list2=self.thing2.index
list1=list1.sort_values()
list2=list2.sort_values()
for i in range(0,len(self.thing1.index)-1):#总名单检查重复
if list1[i]==list1[i+1]:
self.anaresult.append(list1[i])
self.int1=-1
i=i-1
continue
else:
self.int1=1
continue
#print(self.anaresult)
for j in range(0,len(self.thing2.index)-1):#待分析名单检查重复
if list2[j]==list2[j+1]:
self.anaresult1.append(list2[j])
self.int2=-1
j=j-1
continue
else:
self.int2=1
continue
if self.int1==1 and self.int2==1:
labe17=tk.Label(self.root,text=len(self.thing1.index)).place(x=100,y=161)
label8=tk.Label(self.root,text=len(self.thing2.index)).place(x=160,y=201)
analyse.getdatas(self,self.anaresult,self.thing1,self.thing2)
else:
analyse.infoerror(self,self.anaresult,self.anaresult1)
return
def infoerror(self,anaresult,anaresult1):#报告错误信息
if len(self.anaresult)!= 0:
messagebox.showinfo("错误!","总名单中存在数据重复,重复的数据已存入分析结果,请检查后重试!")
if len(self.anaresult1) != 0:
messagebox.showinfo("错误!","待分析名单中存在数据重复,重复的数据已存入分析结果,请检查后重试!")
f = open("E:/学习委员相关/名单分析程序/分析名单结果.txt","w",encoding='utf-8')
f.write("总名单中重复的数据为:\n")
for item1 in self.anaresult:
f.write(item1)
f.write("\n")
f.write("待分析名单中重复的数据为:\n")
for item2 in self.anaresult1:
f.write(item2)
f.close()
return
def getdatas(self,anaresult,thing1,thing2):#读取并分析数据
anaresult=analyse.nameana(self,self.anaresult,self.thing1,self.thing2)
analyse.show_mas(self,self.anaresult)
return
def nameana(self,anaresult,thing1,thing2):#分析名单
t=0
for i in range(0,len(self.thing1.index)):
for j in range(0,len(self.thing2.index)):
if self.thing2.index[j] == self.thing1.index[i]:
t=1
break
else:
t=-1
continue
if t==-1:
if self.thing2.index[j] in self.anaresult:
continue
else:
self.anaresult.append(self.thing1.index[i])
else:
continue
return self.anaresult
def show_mas(self,anaresult):#显示并保存分析结果
#print(self.anaresult)
if len(self.anaresult)!=0:
messagebox.showinfo("结果",self.anaresult)
f = open("G:/学习委员相关/名单分析程序/分析名单结果.txt","w",encoding='utf-8')
for item in self.anaresult:
f.write(item)
f.close()
else:
messagebox.showinfo("结果","所有人都已经提交,如果还有遗漏,请检查数据是否正确!")
(三)调用:
def yunxin():
ana=analyse()
ana.main()
return
yunxin()
三、两个名单文件数据重复的处理
总名单理论上是不可能重复的(因为在开始使用这个程序之前总名单就已经保存好了),但我也添加了总名单的查重代码,同样的我对待处理名单也有一次查重过程,如果有任意一个名单存在重复(如有小伙伴交在线表的时候交了很多次),这个时候就会返回重复结果而不是未填表的人(因为存在重复时单纯遍历检查会出问题):
def judrepeat(self,anaresult,thing1,thing2):
list1=self.thing1.index
list2=self.thing2.index
list1=list1.sort_values()
list2=list2.sort_values()
for i in range(0,len(self.thing1.index)-1):#总名单检查重复
if list1[i]==list1[i+1]:
self.anaresult.append(list1[i])
self.int1=-1
i=i-1
continue
else:
self.int1=1
continue
#print(self.anaresult)
for j in range(0,len(self.thing2.index)-1):#待分析名单检查重复
if list2[j]==list2[j+1]:
self.anaresult1.append(list2[j])
self.int2=-1
j=j-1
continue
else:
self.int2=1
continue
if self.int1==1 and self.int2==1:
labe17=tk.Label(self.root,text=len(self.thing1.index)).place(x=100,y=161)
label8=tk.Label(self.root,text=len(self.thing2.index)).place(x=160,y=201)
analyse.getdatas(self,self.anaresult,self.thing1,self.thing2)
else:
analyse.infoerror(self,self.anaresult,self.anaresult1)
return
四、结果验收
(一)总名单;

(二)待分析名单:

(三)分析结果
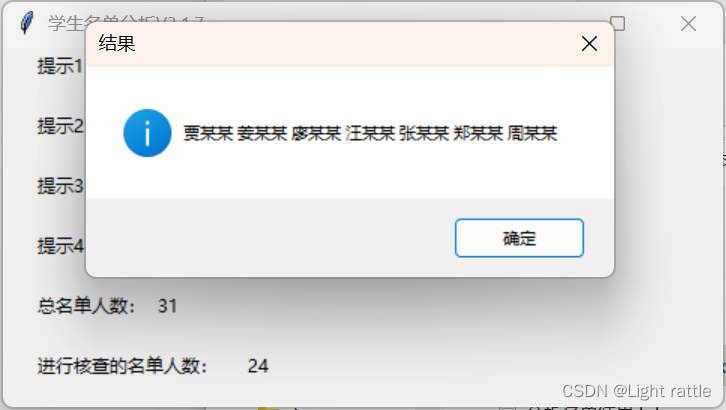
(上面只是姓不同的测试用例,事实上只要不重名就能得出正确结果)