声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
| Bidirectional Variational Inference for Non-Autoregressive Text-to-Speech |
本文是ICLR 2021的文章,目前看到的文章版本为匿名,主要研究使用BVAE构建non-autoregressive TTS,使推理速度比现有的自回归和非自回归速度都快许多(比tacotron2增加27倍),文章链接
https://openreview.net/pdf?id=o3iritJHLfO
1 研究背景
现有的自回归系统的缺点是推理无法并行,因此时间开销与帧数呈线性关系,而且缺乏对齐鲁棒性。目前非自回归系统则需要teacher模型来引导duration训练或者需要teacher模型来引导特征学习,而且一些flow基础的模型较大,而本文提出的非自回归模型不需要teacher模型,同时更加灵活。实验结果显示,BVAE-TTS的推理速度是tacotron2的27倍,是Glow-TTS的两倍,但合成的音频质量好于Glow-TTS。
2 详细设计
先看一下BVAE(bidirectional inference variational autoencoder)的结构为图1所示,主要分为bottom-up和Top-down两个路径。使用该结构的BVAE-TTS为图2所示,其中(a)为训练流程,其中duration predictor模块训练是使用attention的对齐结果,bvae block分为downsample和upsample,downsample是的结果作为attention的Q来计算对齐,upsample则是把语言特征转成声学特征。在推理阶段(c)则只使用duration predictor,而不再使用attention。


3 实验
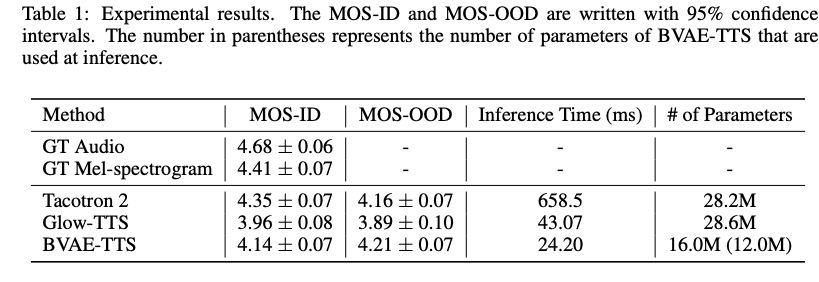
本文实验主要对比自回归模型tacotron2和非自回归模型Glow-TTS,结果table显示了各系统的对比指标。首先,BVAE-TTS在in-domain测试MOS好于glow-tts但比tacotron2差,在out of domain 测试MOS优于这个系统。推理速度则是tactron2的27倍,glow-TTS的2倍,参数量的话只有这两个模型的一半。图3展示结果距离声学特征的两个bvae block学习声学特征好,接近text的则学习语言特征。图4展示本文使用的其它一些算法验证。


4 总结
本文使用BVAE提出的非自回归模型不需要teacher模型,同时更加灵活。实验结果显示,BVAE-TTS的推理速度是tacotron2的27倍,是Glow-TTS的两倍,但合成的音频质量好于Glow-TTS。