文章目录
pandas快速入门
学习目标
- 能够知道 DataFrame 和 Series 数据结构
- 能够加载 csv 和 tsv 数据集
- 能够区分 DataFrame 的行列标签和行列位置编号
- 能够获取 DataFrame 指定行列的数据
1. DataFrame 和 Series 简介
pandas是用于数据分析的开源Python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能。
pandas最基本的两种数据结构:
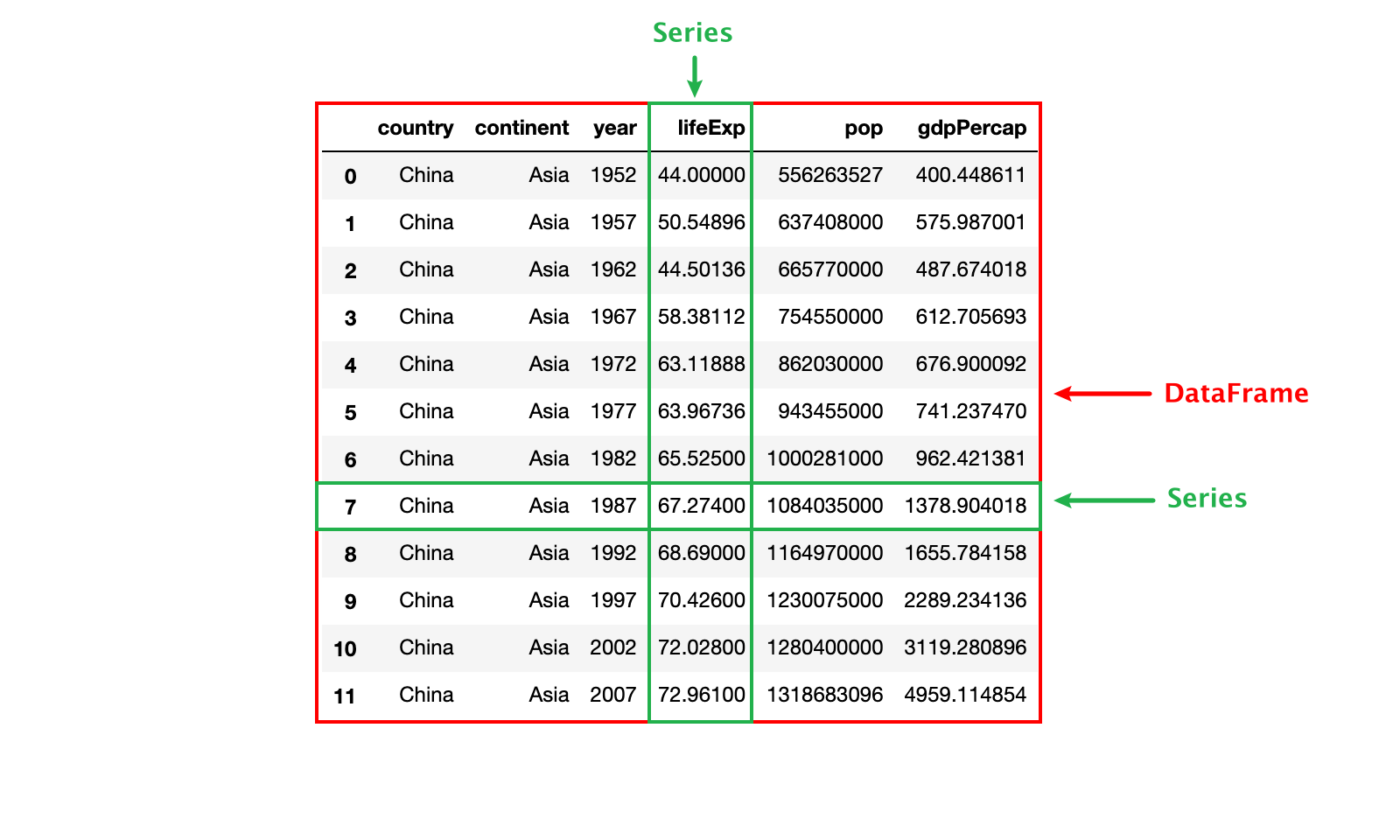
1)DataFrame
- 用来处理结构化数据(SQL数据表,Excel表格)
- 可以简单理解为一张数据表(带有行标签和列标签)
2)Series
- 用来处理单列数据,也可以以把DataFrame看作由Series对象组成的字典或集合
- 可以简单理解为数据表的一行或一列
2. 加载数据集(csv和tsv)
2.1 csv和tsv文件格式简介
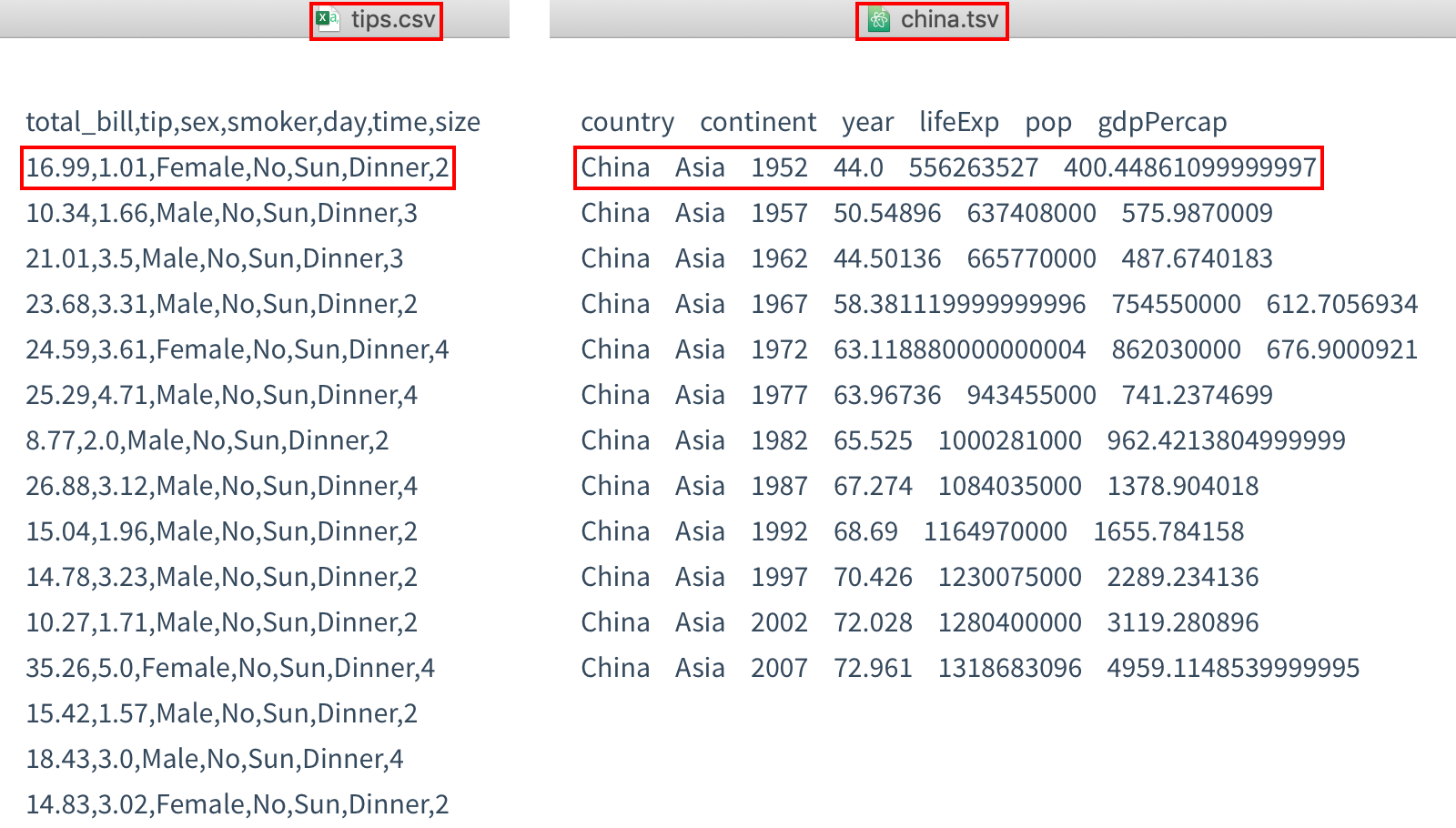
csv 和 tsv 文件都是存储一个二维表数据的文件类型。
注意:其中csv文件每一列的列元素之间以逗号进行分割,tsv文件每一行的列元素之间以\t进行分割。
2.2 加载数据集(tsv和csv)
1)首先打开jupyter notebook,进入自己准备编写代码目录下方,创建01-pandas快速入门.ipynb文件:
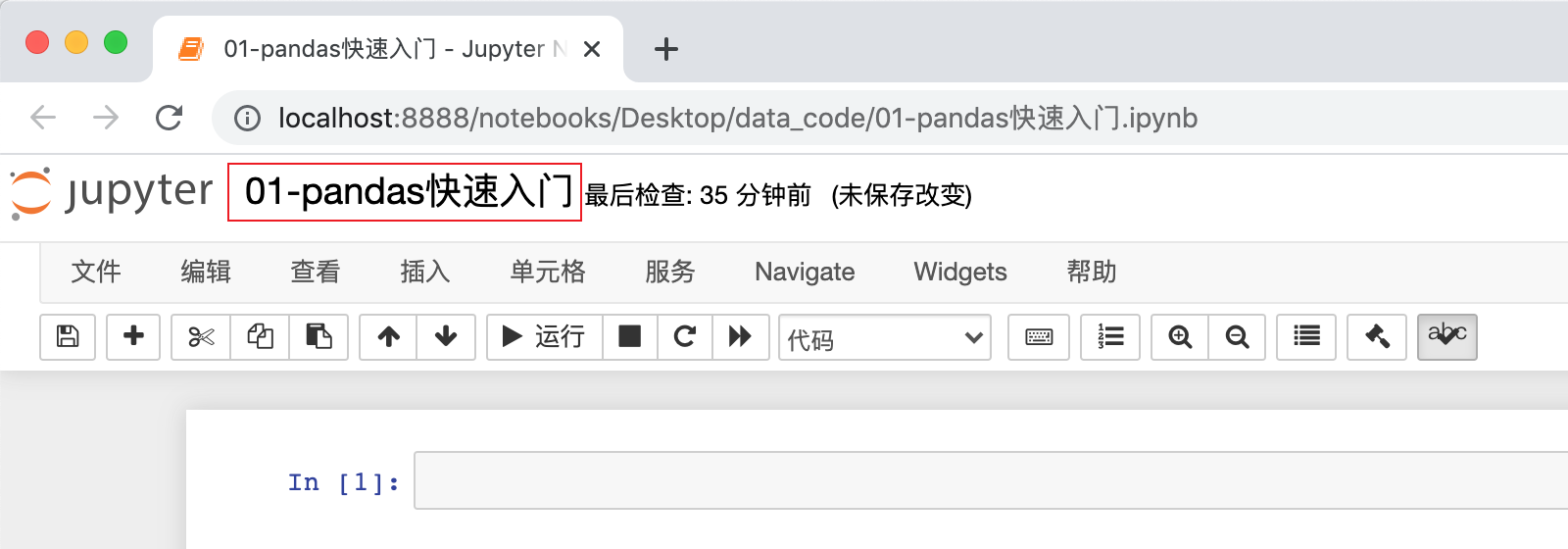
注意:提前将提供的 data 数据集目录放置到 01-pandas快速入门.ipynb 同级目录下,后续课程会加载 data 目录下的数据集。
2)导入 pandas 包
注意:pandas 并不是 Python 标准库,所以先导入pandas
# 在 ipynb 文件中导入 pandas
import pandas as pd
3)加载 csv 文件数据集
tips = pd.read_csv('./data/tips.csv')
tips
4)加载 tsv 文件数据集
# sep参数指定tsv文件的列元素分隔符为\t,默认sep参数是,
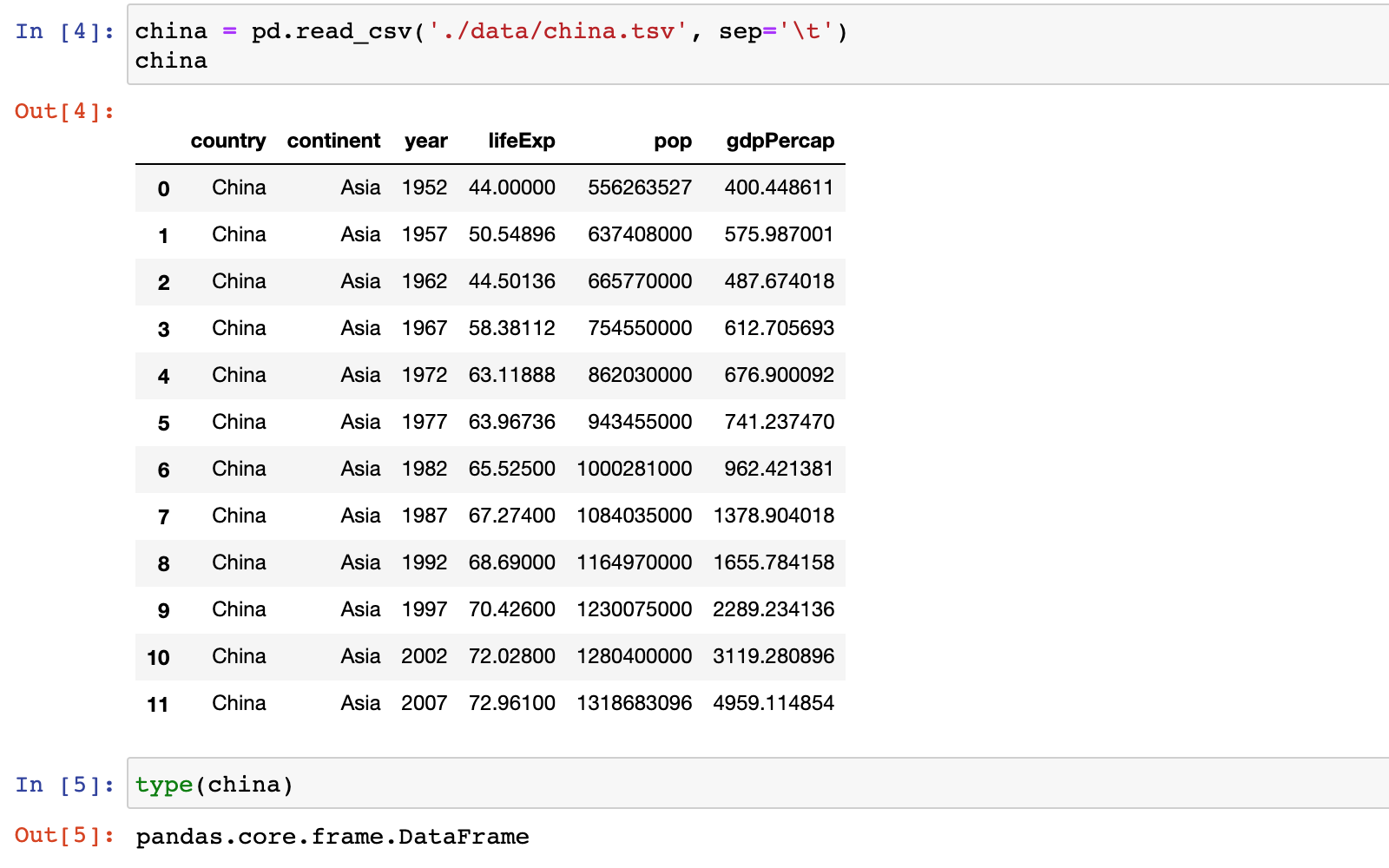
china = pd.read_csv('./data/china.tsv', sep='\t')
china