1、GlusterFS简述
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源并不直接与本地节点相连,而是分布于计算网络中的一个或者多个节点的计算机上。目前意义上的分布式文件系统大多都是由多个节点计算机构成,结构上是典型的客户机/服务器模式。流行的模式是当客户机需要存储数据时,服务器指引其将数据分散的存储到多个存储节点上,以提供更快的速度,更大的容量及更好的冗余特性。GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。
术语:
Brick:GFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识,如‘SERVER:EXPORT‘
Client:挂载了GFS卷的设备
Extended Attributes:xattr是一个文件系统的特性,其支持用户或程序关联文件/目录和元数据。
FUSE:Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码。通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接。
Geo-Replication
GFID:GFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,其用于模拟inode
Namespace:每个Gluster卷都导出单个ns作为POSIX的挂载点
Node:一个拥有若干brick的设备
RDMA:远程直接内存访问,支持不通过双方的OS进行直接内存访问。
RRDNS:round robin DNS是一种通过DNS轮转返回不同的设备以进行负载均衡的方法
Self-heal:用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。
Split-brain:脑裂
Translator:
Volfile:glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname
Volume:一组bricks的逻辑集合
a、无元数据设计
元数据是用来描述一个文件或给定区块在分布式文件系统中所在的位置,简而言之就是某个文件或某个区块存储的位置。传统分布式文件系统大都会设置元数据服务器或者功能相近的管理服务器,主要作用就是用来管理文件与数据区块之间的存储位置关系。相较其他分布式文件系统而言,GlusterFS并没有集中或者分布式的元数据的概念,取而代之的是弹性哈希算法。集群中的任何服务器和客户端都可以利用哈希算法、路径及文件名进行计算,就可以对数据进行定位,并执行读写访问操作。
这种设计带来的好处是极大的提高了扩展性,同时也提高了系统的性能和可靠性;另一显著的特点是如果给定确定的文件名,查找文件位置会非常快。但是如果要列出文件或者目录,性能会大幅下降,因为列出文件或者目录时,需要查询所在节点并对各节点中的信息进行聚合。此时有元数据服务的分布式文件系统的查询效率反而会提高许多。
b、服务器间的部署
在之前的版本中服务器间的关系是对等的,也就是说每个节点服务器都掌握了集群的配置信息,这样做的好处是每个节点度拥有节点的配置信息,高度自治,所有信息都可以在本地查询。每个节点的信息更新都会向其他节点通告,保证节点间信息的一致性。但如果集群规模较大,节点众多时,信息同步的效率就会下降,节点信息的非一致性概率就会大大提高。因此GlusterFS未来的版本有向集中式管理变化的趋势。
2、访问流程
Glusterfs基于内核的fuse模块,fuse模块除了创建fuse文件系统外,还提供了一个字符设备(/dev/fuse),通过这个字符设备,Glusterfs可以读取请求,并发送响应,并且可以发送notify消息。
下面是在Glusterfs下的一个读/写请求的完整流程:

过程说明:
蓝实线表示一个请求通过系统调用到VFS,然后经由Fuse封装为一个req并发送到等待队列,然后唤醒在该等待队列上阻塞的Glusterfs读进程,读取请求
绿虚线表示Glusterfsd进程读取请求后,处理请求的过程
红虚线表示Glusterfs处理完请求后,封装响应消息并将消息发送到/dev/fuse下,并唤醒相应的请求进程(请求进程在将请求发送后,一直阻塞,直到该请求收到响应并处理完成)。
请求进程被唤醒后,将Glusterfs封装的响应信息返回给用户。
为方便说明问题,下图是一个读请求走到Fuse的完整流程:
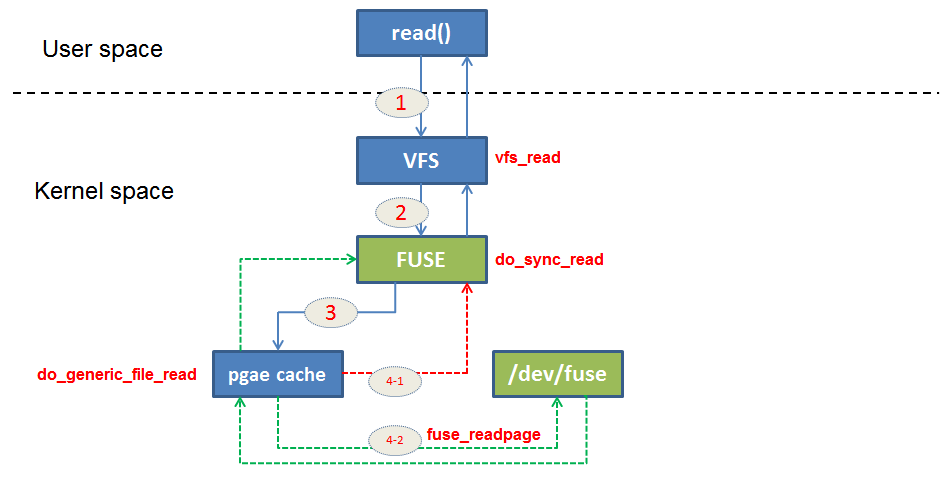
下面是上面这些步骤的说明:
①read系统调用,陷入到内核
②vfs通过fd及当前进程维护的打开的文件表找到fd对应的file,然后调用该file被赋值的read函数进行读操作
③因为该file是基于fuse文件系统创建的,因此调用fuse的read函数do_sync_read
④-1.最终调用do_generic_file_read基于读操作的偏移量及该文件的缓存树查找该对应的缓存页,该缓存页存在且是最新的,直接从该缓存中读数据给用户
④-2.如果该缓存页不存在,则申请一个页作为缓存。并调用readpage去读数据。fuse的readpage会封装一个请求到字符设备的等待队列中。收到glusterfs的响应后会将响应写到缓存中并返回
常用卷类型
分布(distributed)
复制(replicate)
条带(striped)
基本卷:
(1) distribute volume:分布式卷
(2) stripe volume:条带卷
(3) replica volume:复制卷
复合卷:
(4) distribute stripe volume:分布式条带卷
(5) distribute replica volume:分布式复制卷
(6) stripe replica volume:条带复制卷
(7) distribute stripe replicavolume:分布式条带复制卷
3、实验环境及规划:
| 操作系统 | IP地址 | 主机名 | 硬盘数量(3块) | 角色 |
| CentOS7.2 | 192.168.0.51 | node01 | sdb:10G sdc:10G sdd:10G | 存储节点 |
| CentOS7.2 | 192.168.0.52 | node02 | sdb:10G sdc:10G sdd:10G | 存储节点 |
| CentOS7.2 | 192.168.0.53 | node03 | sdb:10G sdc:10G sdd:10G | 存储节点 |
| CentOS7.2 | 192.168.0.54 | node04 | sdb:10G sdc:10G sdd:10G | 存储节点 |
| CentOS7.2 | 192.168.0.55 | node05 | sdb:10G sdc:10G sdd:10G | 存储节点 |
| CentOS7.2 | 192.168.0.56 | node06 | sdb:10G sdc:10G sdd:10G | 存储节点 |
| CentOS7.2 | 192.168.0.57 | node07 | sda:100G | 客户端 |
3.1 关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
3.2 关闭selinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
3.3 同步时间
yum install chrony -y
systemctl enable chronyd.service
systemctl start chronyd.service
3.4 主机名解析
192.168.0.51 node01
192.168.0.52 node02
192.168.0.53 node03
192.168.0.54 node04
192.168.0.55 node05
192.168.0.56 node06
192.168.0.57 node07
3.5 安装epel源
yum install http://mirrors.163.com/centos/7/extras/x86_64/Packages/epel-release-7-9.noarch.rpm -y
配置yum源
vim /etc/yum.repos.d/gluster.repo
[gluster]
name=gluster
baseurl=https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-3.8/
gpgcheck=0
enabled=1
3.6 安装gluster主服务及辅助包
yum install -y glusterfs-server samba rpcbind
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl start rpcbind
systemctl enable rpcbind
systemctl status rpcbind
以上操作3.1~3.6操作在node01---node06上同时操作,并确保生效
4、gluster基本操作
4.1 常用命令
gluster help
volume info [all|<VOLNAME>] - list information of all volumes
volume create <NEW-VOLNAME> [stripe <COUNT>] [replica <COUNT> [arbiter <COUNT>]] [disperse [<COUNT>]] [disperse-data <COUNT>] [redundancy <COUNT>] [transport <tcp|rdma|tcp,rdma>] <NEW-BRICK>?<vg_name>... [force] - create a new volume of specified type with mentioned bricks
volume delete <VOLNAME> - delete volume specified by <VOLNAME>
volume start <VOLNAME> [force] - start volume specified by <VOLNAME>
volume stop <VOLNAME> [force] - stop volume specified by <VOLNAME>
volume tier <VOLNAME> status
volume tier <VOLNAME> start [force]
volume tier <VOLNAME> attach [<replica COUNT>] <NEW-BRICK>...
volume tier <VOLNAME> detach <start|stop|status|commit|[force]>
- Tier translator specific operations.
volume attach-tier <VOLNAME> [<replica COUNT>] <NEW-BRICK>... - NOTE: this is old syntax, will be depreciated in next release. Please use gluster volume tier <vol> attach [<replica COUNT>] <NEW-BRICK>...
volume detach-tier <VOLNAME> <start|stop|status|commit|force> - NOTE: this is old syntax, will be depreciated in next release. Please use gluster volume tier <vol> detach {start|stop|commit} [force]
volume add-brick <VOLNAME> [<stripe|replica> <COUNT> [arbiter <COUNT>]] <NEW-BRICK> ... [force] - add brick to volume <VOLNAME>
volume remove-brick <VOLNAME> [replica <COUNT>] <BRICK> ... <start|stop|status|commit|force> - remove brick from volume <VOLNAME>
volume rebalance <VOLNAME> {{fix-layout start} | {start [force]|stop|status}} - rebalance operations
volume replace-brick <VOLNAME> <SOURCE-BRICK> <NEW-BRICK> {commit force} - replace-brick operations
volume set <VOLNAME> <KEY> <VALUE> - set options for volume <VOLNAME>
volume help - display help for the volume command
volume log <VOLNAME> rotate [BRICK] - rotate the log file for corresponding volume/brick
volume log rotate <VOLNAME> [BRICK] - rotate the log file for corresponding volume/brick NOTE: This is an old syntax, will be deprecated from next release.
volume sync <HOSTNAME> [all|<VOLNAME>] - sync the volume information from a peer
volume reset <VOLNAME> [option] [force] - reset all the reconfigured options
volume profile <VOLNAME> {start|info [peek|incremental [peek]|cumulative|clear]|stop} [nfs] - volume profile operations
volume quota <VOLNAME> {enable|disable|list [<path> ...]| list-objects [<path> ...] | remove <path>| remove-objects <path> | default-soft-limit <percent>} |
volume quota <VOLNAME> {limit-usage <path> <size> [<percent>]} |
volume quota <VOLNAME> {limit-objects <path> <number> [<percent>]} |
volume quota <VOLNAME> {alert-time|soft-timeout|hard-timeout} {<time>} - quota translator specific operations
volume inode-quota <VOLNAME> enable - quota translator specific operations
volume top <VOLNAME> {open|read|write|opendir|readdir|clear} [nfs|brick <brick>] [list-cnt <value>] |
volume top <VOLNAME> {read-perf|write-perf} [bs <size> count <count>] [brick <brick>] [list-cnt <value>] - volume top operations
volume status [all | <VOLNAME> [nfs|shd|<BRICK>|quotad]] [detail|clients|mem|inode|fd|callpool|tasks] - display status of all or specified volume(s)/brick
volume heal <VOLNAME> [enable | disable | full |statistics [heal-count [replica <HOSTNAME:BRICKNAME>]] |info [healed | heal-failed | split-brain] |split-brain {bigger-file <FILE> | latest-mtime <FILE> |source-brick <HOSTNAME:BRICKNAME> [<FILE>]} |granular-entry-heal {enable | disable}] - self-heal commands on volume specified by <VOLNAME>
volume statedump <VOLNAME> [nfs|quotad] [all|mem|iobuf|callpool|priv|fd|inode|history]... - perform statedump on bricks
volume list - list all volumes in cluster
volume clear-locks <VOLNAME> <path> kind {blocked|granted|all}{inode [range]|entry [basename]|posix [range]} - Clear locks held on path
volume barrier <VOLNAME> {enable|disable} - Barrier/unbarrier file operations on a volume
volume get <VOLNAME> <key|all> - Get the value of the all options or given option for volume <VOLNAME>
volume bitrot <VOLNAME> {enable|disable} |
volume bitrot <volname> scrub-throttle {lazy|normal|aggressive} |
volume bitrot <volname> scrub-frequency {hourly|daily|weekly|biweekly|monthly} |
volume bitrot <volname> scrub {pause|resume|status} - Bitrot translator specific operation. For more information about bitrot command type 'man gluster'
peer probe { <HOSTNAME> | <IP-address> } - probe peer specified by <HOSTNAME>
peer detach { <HOSTNAME> | <IP-address> } [force] - detach peer specified by <HOSTNAME>
peer status - list status of peers
peer help - Help command for peer
pool list - list all the nodes in the pool (including localhost)
quit - quit
help - display command options
exit - exit
snapshot help - display help for snapshot commands
snapshot create <snapname> <volname> [no-timestamp] [description <description>] [force] - Snapshot Create.
snapshot clone <clonename> <snapname> - Snapshot Clone.
snapshot restore <snapname> - Snapshot Restore.
snapshot status [(snapname | volume <volname>)] - Snapshot Status.
snapshot info [(snapname | volume <volname>)] - Snapshot Info.
snapshot list [volname] - Snapshot List.
snapshot config [volname] ([snap-max-hard-limit <count>] [snap-max-soft-limit <percent>]) | ([auto-delete <enable|disable>])| ([activate-on-create <enable|disable>]) - Snapshot Config.
snapshot delete (all | snapname | volume <volname>) - Snapshot Delete.
snapshot activate <snapname> [force] - Activate snapshot volume.
snapshot deactivate <snapname> - Deactivate snapshot volume.
global help - list global commands
nfs-ganesha {enable| disable} - Enable/disable NFS-Ganesha support
4.2 添加存储节点到gluster池(任意一个存储节点上操作都行,这里在node01上,从node02开始,node01默认自己会添加)
命令:peer probe { <HOSTNAME> | <IP-address> } - probe peer specified by <HOSTNAME>
[root@node01 ~]# gluster peer probe node02 peer probe: success. [root@node01 ~]# gluster peer probe node03 peer probe: success. [root@node01 ~]# gluster peer probe node04 peer probe: success. [root@node01 ~]# gluster peer probe node05 peer probe: success. [root@node01 ~]# gluster peer probe node06 peer probe: success. [root@node01 ~]# gluster peer status Number of Peers: 5 Hostname: node02 Uuid: a6052b2f-7724-428b-a030-3372663c8896 State: Peer in Cluster (Connected) Hostname: node03 Uuid: df99aea5-24aa-4176-8b45-ecea75bbb34a State: Peer in Cluster (Connected) Hostname: node04 Uuid: 6baedfed-7132-421d-8227-b79b76339688 State: Peer in Cluster (Connected) Hostname: node05 Uuid: e6027a77-1b9a-4d58-bb7e-e3eb13c8b3d8 State: Peer in Cluster (Connected) Hostname: node06 Uuid: 85f56ce4-0a47-4934-bbe9-a5ebaabf3bc9 State: Peer in Cluster (Connected) [root@node01 ~]#