目录
1、前言
古彝文指的是在云南、贵州、四川等地的彝族人之间流通使用的原生态彝文。彝族有着古老灿烂的文化,彝族人用彝文记录了他们修养生息的完整过程,是中华传统文化的重要组成部分。

古彝文的起源距今至少数千年,是世界上最古老的文字之一。古彝文的外形与其他古文字中可能存在某些相似关联:
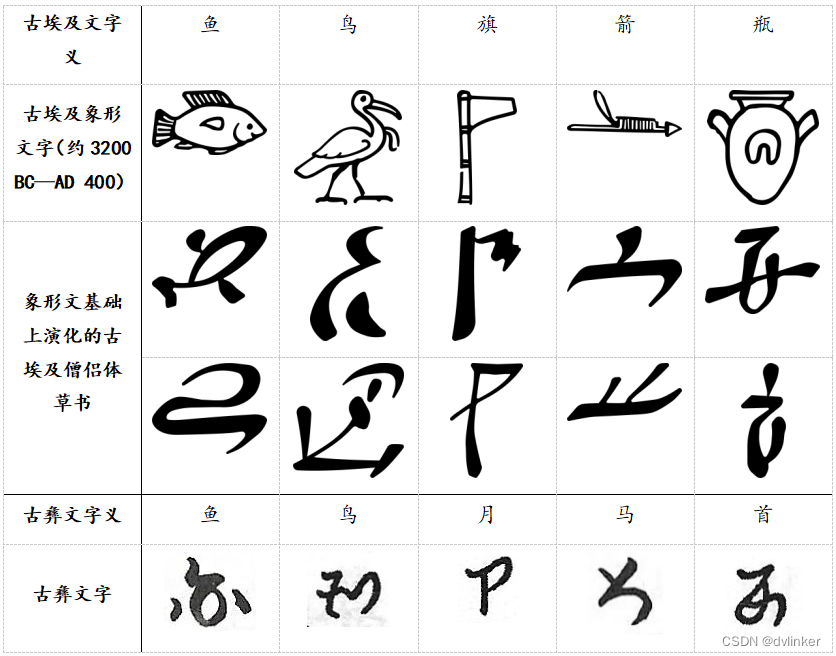
但不同区域的彝族人,他们在造字与使用方法有着很大的差异。据《滇川黔桂彝文字集》显示,这种文字多达87046字;在国家图书馆珍藏中,由这些文字书写的古彝文典籍共有592册(件)。
这些古彝文典籍的内容涉及范围非常广泛,包含天文、地理、政治、经济、军事、医学、算术、地形、地貌、生物、农牧等多个领域,其中蕴含着大量的生产与生活的技能智慧,是彝族人民开发利用所在地自然资源的经验总结和科学的结晶,可见其蕴含着巨大的文化价值和实用价值。
在当代,彝文依然拥有广泛的受用人群。四川省曾在1980年发布规范彝文共819字,截止2012年,滇川黔桂发布的通用彝文有5598字。这两种彝文常用于仪式、节庆、旅游景点等场合——彰显彝族非物质文化遗产的传承;同时也用于民族地区相关政策与宣传文件的翻译,以及文学创作。值得一提的是彝文的使用同样受到了国家层面上的重视,中央民族语文翻译局设有彝语文室,负责每年全国、省两会文件的翻译和同声传译等。
2、对古彝文古籍的保护迫在眉睫

彝文古籍文献的载体形式是多样化的,有纸质书籍、文书档案、碑刻、竹简、金属载体,以及一些口耳相传的口述史料,其中以手抄的形式为主。这些文献代代相传,由于战火与自然风蚀的洗礼,很多文献遭到破坏和流失,存在缺失、污渍、笔墨污染、模糊、印章噪声干扰,目前, 从各地收藏单位收集到彝文古籍文献来看,纸质文件存在泛黄变脆,甚至出现残边、虫蛀等损毁问题; 一些碑刻、木刻的古彝文也由于长期的侵蚀,字迹出现了模糊, 腐蚀等情况。
这些给古彝文古籍的保存、流通与使用产生了很大的阻碍,这使得抢救与保护现有的彝文古籍文献迫在眉睫,其中数字化技术是重要手段之一,也是现如今梳理和保护古彝文最有希望的路线。通过现代化的数字技术,将珍贵的古彝文文本文献转换为电子文件,更加便于其保存与传承。
作为世界上最古老的文字之一,古彝文是中华文明地图上神秘而耀眼的印记。合合信息联合上海大学、华南理工大学团队针对现有的西南彝志、云贵一带古彝文字符开展统一编码,并于近期发布了业内首个古彝文基础编码数据库(简称“数据库”)。
据悉,数据库包含上千个古彜文基础编码,通过API数据接口等形式,该数据库有望帮助高校研究人员、文化工作者、兴趣爱好者等人群快速找到古彝文在字典中的读音、汉语释义、用法,如同“大字典”一般,帮助人们降低古彝文书籍、文献阅读的门槛,以数字化手段助力传统文化保护、创新之路。
研究古彝文字集,有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护,同时通过建立古彝文数据库,填补当前国内外研究的空白。合合信息与华南理工大学共同成立文档图像分析识别与理解联合实验室,联合上海大学社会学院,共同解决数据库建设中的学术性、技术性难点。
3、古彝文识别的难点问题
目前, 从各地收藏单位收集到彝文古籍文献来看,纸质文件存在泛黄变脆,甚至出现残边、虫蛀等损毁问题; 一些碑刻、木刻的古彝文也由于长期的侵蚀,字迹出现了模糊, 腐蚀等情况,这对古彝文典籍修复、文本检测、文字识别带来极大困难。此外,当前对于古彝文识别技术的研究寥寥无几,这进一步加深了古彝文识别的难度。目前,古彝文识别的挑战性主要集中于以下几个方面,合合信息针对这些难点问题开创性地提出了对应的解决办法。
(1)缺乏完善的手写古彝文数据集
数据集通常是训练神经网络最为关键的因素之一,数据集的质量直接决定了模型的效果。当前对古彝文的研究多集中在文献整理上,而尚未有完善的古彝文手写数据集,并且在传承过程中通晓古彝文文字的人越来越少,导致数据集标注工作量大而人手少,数据集样本严重不足,这是古彝文识别最为关键的挑战之一。
合合信息研究人员通过与古彝文传承人建立良好的关系,获取大量典籍,弥补了古彝文识别项目训练样本不足的情况。
(2)版式多样性

古彝文典籍排版风格具有多样性,字符间距、行距等有较大差异,且存在加字、替字、整句倒置等现象,这种情况对文字定位与识别造成了诸多干扰。
合合信息依托其在智能文字识别领域的领先技术,包括图像复杂版式识别、图像扭曲矫正等优秀成果,为古彝文识别奠定了技术基础。
(3)图像质量较差

多数古彝文典籍都因历史保护的原因,出现了或多或少的缺失或污迹,严重影响了数据集的质量,增加了文字识别的难度。
合合信息依托智能文字识别技术,通过利用图像增强技术可以显著提高图像质量,进而提高古彝文文字识别的精度和效率。
(4)字符集庞大
古彝文拥有庞大的字符集,在上文中,我们已经提到仅仅是 2004 年出版的《滇川黔桂彝文字集》就包含 87000 多个字。对如此庞大的字符集进行分类是一项十分艰巨的任务。
合合信息在2021年、2022年的世界人工智能大会上,合合信息展现了智能文字识别技术在甲骨文、西周钟鼎文(金文)中的应用,获得了包括央视、人民日报、新华社等上百家主流媒体的关注。合合信息利用在甲骨文、金文等古文中的研究经验,文字间的识别有相通之处,为古彝文识别打下了坚实基础。
(5)字形变化较多

古彝文字体、字形的变化较多,没有统一的手写规范,且不同地区书写规则不同,存在大量的变形字和异体字,例如,如下图所示,表示“种类”的古彝文就有四种不同的写法,并且存在大量字形相似,甚至在视觉上没有太大差别的字,在意义上毫无联系,这为古彝文的识别增加了难度。
针对这一问题,上海大学的古彝文研究人员提出了四字节编码方案,用于描述每个变体和形近字符之间的细微差别,根据这种编码方案能够更好的建立深度学习数据集。合合信息根据四字节编码系统标注异体字、变体字、误用字和混用字,并由此精确建立彝文古籍电子数据库。
4、古彝文文字识别的关键技术
虽然古彝文的识别研究尚处于起步阶段,但合合信息依托其在文字识别领域的多年技术沉淀,融合了AI技术,拥有强大的智能图像处理、基于深度学习的复杂场景文字识别、自然语言处理(NLP)等关键技术积累,在图像的复杂版式识别、结构化智能理解层面做了大量的研究,并取得优秀的应用效果,为古彝文识别提供技术支持。合合信息的智能文字识别技术可对图像质量进行增强,提升文字识别的效率与准确性。
此外,合合信息引入了先进的AI技术,为彝文古籍建立了统一的电子数据库,对于增强古彝文研究的连续性、降低繁琐的检索工作起到了很大的作用。
4.1、智能高清滤镜技术
合合信息旗下扫描全能王推出了基于智能扫描引擎AI-Scan的智能高清滤镜技术,该智能高清滤镜技术使用深度学习模型来识别和理解图像的内容。通过深度学习模型,应用可以感知到图像中的光照、阴影、颜色和倾斜角度等特征,可自动检测图像中存在的问题并判定图像的优化方式,实现模糊、阴影、手指、屏幕纹等干扰因素一键全处理,使用者无需思考拍摄角度、光源、背景等的影响。例如,对于手指的遮挡,它可以进行去手指处理;对于过暗或过亮的图像,它可以调整图像的亮度和对比度;对于倾斜的文档,它可以自动进行倾斜矫正等。

这个智能高清滤镜技术,可以较大地提高对古彝文等古籍文献识别的清晰度与准确性。
4.2、图像矫正
由于相机拍摄(扫描)的角度和镜头畸变的问题,会产生文档图像的变形和扭曲。比如对目标文档的拍摄视角一般做不到与目标文档的垂直,拍摄出来的图像不可避免地会产生文变形和扭曲,效果如下:
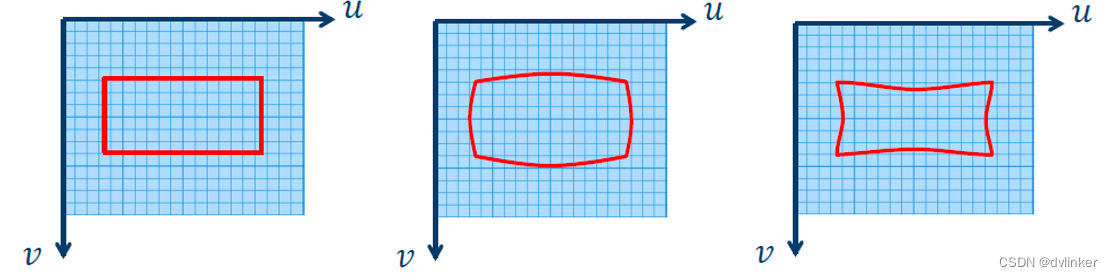
对于传统扭曲变形的校正方式,通过对选择的区域进行特征提取,以分类回归的方式得到最后的文本区域。但对于古文古籍这类很复杂的文本场景时,图像受遮挡、模糊等因素的影响,加上文本在纵横比、比例、方向呈现的方式不同,传统算法的稳定性变差。
合合信息采用基于偏移场的学习方法大大改善了上述缺陷。偏移场是一种具有中间监督的堆叠U-Net网络,用于直接预测从扭曲图像到校正图像的正向映射。通过扭曲未失真的图像创建高质量的图像合成数据集,而数据驱动和学习的方法可以极大地涵盖各种真实世界条件,提高了模型泛化能力,达到商用级别。在提供大规模训练数据的前提下,它可以处理各种文档类型——包括古彝文等古籍文档;且可以作为一种有效的方法部署在现实世界中应用。
4.3、图像增强
因为古籍文献往往存在斑点、阴影、破旧、模糊不清等影响文字提取和识别的问题,此时需要借助图像增强技术进行预处理。
从 2017 年开始,生成对抗网络在图像阴影去除方向的应用陆续被人提出并不断完善,以达到图像阴影去除效果进一步的提升。GAN网络由生成器网络与判别器网络两部分共同构成。
其核心思想是通过两个子网各自的最优变化,达到全局的最优效果。生成器网络的核心作用是通过一系列的网络结构生成可以骗过判别器网络的数据,判别器网络的核心作用是通过网络设计可以不被生成器网络生成的数据所骗过。生成器网络与判别器网络二者互相制约,共同成长,形成表现良好的网络结构。有时,网络内部还借助空洞卷积、注意力机制、特征融合、编码器等方法的一个或多个特性进行优化。
通过上述两个网络的博弈,使得去阴影的效果更接近于真实的无阴影文档,大大提高了文档的可读性。
4.4、版面还原
对文档版面的处理,可以说是一个复杂且高度专业的任务。不仅需要对各种元素进行精准定位,还要准确解析这些元素的内容及它们之间的关系。合合信息通过融合自研技术和前沿理论,创建了一套完整的版面处理流程,成功实现了精准的版面还原。
(1)元素检测和识别
首先,利用Layout-engine这样的版面分析框架,进行文档的初步元素检测和识别。它利用类似卷积神经网络(CNN)和Faster R-CNN的深度学习模型,定位并识别文档中的元素,如文本、图表、图片等,处理的范围包括段落检测、表格检测、页眉页脚识别等。
(2)元素聚合
在准确检测到元素后,我们需要对这些元素进行合理的聚合。例如,将相同段落的文字聚合在一起,形成完整的段落;将表格的行列单元聚合,生成完整的表格。在这个过程中,扫描全能王运用了类似图神经网络(GNN)的方法,构建一个图形模型来描述元素之间的关系,从而实现对元素的有效聚合。
(3)版面识别
在元素聚合完成后,需要识别这些元素的内容。识别文本、识别表格中的信息、解析条形码和二维码的数据等。这一步,扫描全能王使用了一种类似Transformer网络模型的结构,它能有效处理长距离依赖问题,同时具有并行计算的优势,对大规模文档处理任务有着显著的效益。
5、合合信息识别技术赋能古彝文数字化
作为行业领先的人工智能及大数据科技企业,合合信息致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。17年来深耕智能文字识别+商业大数据领域,在C端推出了多款深受全球用户喜爱的效率产品,例如:名片全能王、扫描全能王、启信宝等。
近三年来,合合信息智能文字识别技术先后在ICDAR、ICPR等人工智能国际竞赛中斩获多项冠军,学术成果在CVPR、AAAI、ACL等顶会上发表,并在多个业务领域取得了举世瞩目的应用成果。
在2021年、2022年的世界人工智能大会上,合合信息展现了智能文字识别技术在甲骨文、西周钟鼎文(金文)中的应用,获得了包括央视、人民日报、新华社等上百家主流媒体的关注。

合合信息凭借着在甲骨文、金文识别中的深入研究和技术积累,以及后续的持续创新,必将在古彝文数字化进程中取得令人瞩目的成绩!