前言
人工智能在古彝文古籍保护方面具有巨大的潜力和意义。通过数字化、自动化和智能化的手段,可以更好地保护和传承古彝文的文化遗产,促进彝族文化的传承和发展。
文章目录
一、古彝文是什么?
1.1古彝文的背景
古彝文是中国彝族人民使用的一种古老文字系统,彝族是中国的一个少数民族,主要分布在云南、四川、贵州等地。古彝文起源于公元前13世纪左右,是彝族人民长期积累和发展的产物,具有悠久的历史和独特的文化内涵。
古彝文的使用范围广泛,包括文献、神话、诗歌、歌谣、家谱等各个方面。彝族人民利用古彝文记录了丰富的历史、文化、宗教和社会信息。古彝文不仅是彝族人民的重要交流工具,也是他们传承文化、宣扬思想、表达情感的重要媒介。
然而,由于历史的变迁和社会的变化,古彝文的使用逐渐减少,目前,古彝文面临着保护和传承的挑战,相关机构和学者正致力于研究和保护古彝文,以确保其珍贵的文化遗产不会失落。
1.2古彝文古籍保护背景
目前,包括Google在内,全球许多技术厂商都在使用AI、OCR等数字化技术来保护古籍。国内如龙泉寺还发明了名为“佛原生”的AI技术,利用基于深度学习的单字识别引擎成功地将《六十华严》的大藏经版本进行电子化。

这些项目和技术的出现,为古籍保护和数字化提供了新的可能性。促进人工智能领域与古彝文保护领域的合作与共享,吸引更多的人工智能专家和学者参与到古彝文的保护工作中。通过跨学科和跨领域的合作,可以充分发挥人工智能在古彝文保护方面的作用,提高保护效果。
然而,数字化技术在古籍保护方面仍面临一些挑战。古籍的复杂性、纸质的脆弱性以及文字的特殊性都需要我们持续努力去解决。同时,还需要加强对数字化古籍的存储、备份和安全性的考虑,以确保这些宝贵的文化遗产得到长期的保护和传承。
二、古彝文识别的重难点
2.1古彝文原籍难以获取
首先,彝族祭司布摩通常不愿意出售祖传书籍。对他们来说,出售书籍被认为是一种耻辱,因为这些书籍承载着祖先的智慧和文化传承。他们更倾向于将这些书籍传承给合适的继承人,而不是出售给外部的研究者。
其次,有些彝族祭司在去世时会要求将自己的经书与自己一同火化。这意味着这些书籍可能会被毁灭,使得获取古彝文原籍更加困难。
此外,古彝文研究者需要在当地长期驻扎,并与彝族社区建立良好的关系。这需要时间和耐心,以获得当地人的信任和支持。只有与古彝文传承人建立起密切的关系,才有可能获得他们的授权和许可,进而获取古彝文原籍。
拿到古籍后,页面如有残缺、粘滞,需要小心翼翼地分开,然后分页粘贴至更大幅的纸张上,以便翻检查阅,一些因年代久远出现脆化的纸片还需重新拼接,像这样:

2.2古彝文翻译过程繁琐
1、古彝文翻译过程繁琐的原因主要有以下几点:
- 1.古彝文的保护和研究较为困难:古彝文是一种古老的文字系统,目前尚未被数字化,也没有预留的Unicode编码区段。在翻译过程中,需要彝文缮写员手工抄写彝文字,并将国际编码与彝文字对应起来。
- 彝语母语者的参与:如果翻译家的母语不是彝语,他们需要在彝语母语者的帮助下进行音译。这种合作过程可能需要时间和精力,增加了翻译的困难度。
- 3.多次翻译过程:首先,翻译家需要逐字用汉语进行直译,将古彝文的文字转化为汉语的文字。然后,他们需要用流畅的汉语进行意译,将古彝文的意思转化为汉语的表达方式。这种多次转换增加了翻译的复杂性和耗时性。

这种四行体彝汉文对译的方式,既保留了古籍原貌,又使得翻译内容易于理解。虽然这种方式在数字化方面存在一些困难,但它为保护古籍和传承彝族文化做出了重要的贡献。
过去的古籍翻译通常到这一步就结束了,速度较快的翻译者可能只需一两年就能出版一本译著,而较慢的可能需要数年时间。具体情况取决于原稿的长度。
如果能够有效建立起古彝文的数据库和翻译系统,高效识别古彝文字将成为可能。
三、合合信息智能文字识别技术
在过去的十几年中,合合信息以智能文字识别技术为核心,在图像的复杂版式识别、结构化智能理解层面做了大量的研究,学术成果在CVPR、AAAI、ACL等顶会上发表,并取得优秀的应用效果,这为古彝文研究提供了技术支持。
智能文字识别技术是合合信息核心技术之一,主要由智能图像处理、基于深度学习的复杂场景文字识别,自然语言处理(NLP)三大核心模块组成。其中,智能图像处理技术可对曲面、阴影、摩尔纹等文档图像进行精准的矫正处理,为接下来的文字信息提取、识别创造了良好的条件;复杂场景文字识别技术可适应多语言、多版式、多样式等复杂场景,以进行文字提取,并结合领先的NLP技术,对识别出的结果进行语义理解。
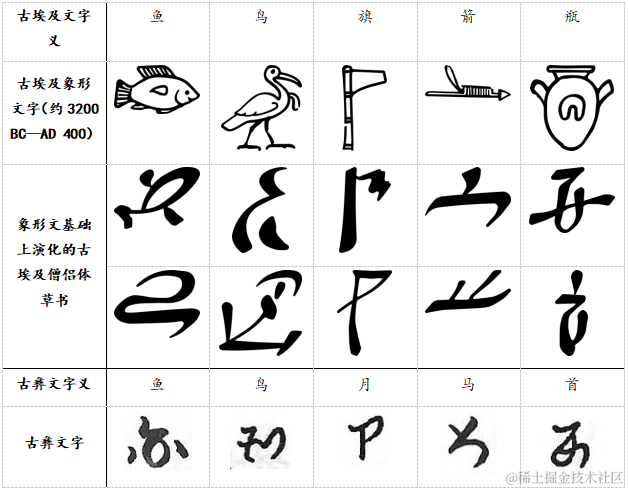
作为世界上最古老的文字之一,古彝文是中华文明地图上神秘而耀眼的印记。合合信息联合上海大学、华南理工大学团队针对现有的西南彝志、云贵一带古彝文字符开展统一编码,并于近期发布了业内首个古彝文基础编码数据库(简称“数据库”)。
据悉,数据库包含上千个古彜文基础编码,通过API数据接口等形式,该数据库有望帮助高校研究人员、文化工作者、兴趣爱好者等人群快速找到古彝文在字典中的读音、汉语释义、用法,如同“大字典”一般,帮助人们降低古彝文书籍、文献阅读的门槛,以数字化手段助力传统文化保护、创新之路。
研究古彝文字集,有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护,同时通过建立古彝文数据库,填补当前国内外研究的空白。合合信息与华南理工大学共同成立文档图像分析识别与理解联合实验室,联合上海大学社会学院,共同解决数据库建设中的学术性、技术性难点。
此外,合合信息旗下扫描全能王还推出“智能高清滤镜”。该功能基于AI技术及智能扫描引擎,可自动检测图像中存在的问题并判定图像的优化方式,实现模糊、阴影、手指、屏幕纹等干扰因素一键全处理。使用者无需思考拍摄角度、光源、背景,只要点击单拍、多拍、扫描等任意拍摄按钮,便可得到一张如原稿打印般清晰、平整的图片。

左图为原图,右图为智能高清滤镜功能识别后的彝文古籍
这些努力为古彝文的研究和传承开辟了新的道路。未来,随着技术的不断进步,我们有望实现更高效、准确的古彝文识别和翻译,为古彝文的保护和传承做出更大的贡献。
四、古彝文识别的意义
古彝文识别的意义在于保护和传承文化遗产、促进语言和文化研究、保护和推广文化多样性,以及提供学习和教育资源。通过数字化技术的应用,我们可以更好地理解和传承彝族文化,促进文化的多元发展和交流。
近两年世界人工智能大会期间,合合信息展示的甲骨文识别、西周钟鼎文识别项目更是成为了场上的“人气黑马”,其背后涉及到的技术点“弯曲矫正”“复杂场景文字识别”等技术已被应用于以扫描全能王为代表的产品中,优化图像处理效果,提升文字识别精度,去满足更多群体更多元的需求。

比如“手写擦除”功能,原理就是用智能文字识别技术将待处理图像划分为手写“擦除区域”和印刷题干等“非擦除区域”,对噪点、阴影、背景杂乱等复杂场景进行处理,同时运用切边矫正、图像增强等滤镜技术,去擦除试卷、作业上的手写笔记,并且为用户呈现清晰美观的卷面图像,在家长、学生中很受欢迎。
五、总结
合合信息前期在甲骨文、金文中所作的研究,让古彝文识别成为一件“水到渠成”的事情。
此次合合信息与上海大学联合开启的“贵州古彝文图像识别及数字化校对项目”校企合作,将填补当前国内外研究的空白,也将成为合合信息智能文字识别技术赋能小语种保护及古文化传承的重要里程碑事件。
未来,合合信息还将重点关注自然语言处理领域,不断精进AI“读懂”古文的能力,去实现更多理解层面的事情,以此更好地促进学术研究效率提升,并通过降低古文理解门槛,在文旅、文创领域触达更广泛的社会群体,让传统文化焕发新的生机。
