链接:https://www.zhihu.com/question/26190832/answer/32387918
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不知道为什么这问题突然火了,更新一个一句话总结:
cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到**加快访问速度**的作用。而 buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以**减少响应次数**(比如从网上下电影,你不能下一点点数据就写一下硬盘,而是积攒一定量的数据以后一整块一起写,不然硬盘都要被你玩坏了)。
=======================
以下观点属于程老大,无节操默写:
1、 Buffer(缓冲区)是系统两端处理 速度平衡(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,起到 流量整形的作用。比如生产者——消费者问题,他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。
2、 Cache(缓存)则是系统两端处理 速度不匹配时的一种 折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
3、假定以后存储器访问变得跟CPU做计算一样快,cache就可以消失,但是buffer依然存在。比如从网络上下载东西,瞬时速率可能会有较大变化,但从长期来看却是稳定的,这样就能通过引入一个buffer使得OS接收数据的速率更稳定,进一步减少对磁盘的伤害。
4、TLB(Translation Lookaside Buffer,翻译后备缓冲器)名字起错了,其实它是一个cache.
俩英文单词,不先看看本义吗?虽然都是抽象单词,但在各个地方都有具象的应用。
Buffer常见的是这个:

(来源: train stop buffer bumper)
对,就是铁道端头那个巨大的弹簧一类的东西。作用是万一车没停住,撞弹簧上减速慢,危险小一些。叫 缓冲。
Cache常见的是这个:
 (来源:
https://upload.wikimedia.org/wikipedia/commons/6/68/Bear_caches.jpg)
(来源:
https://upload.wikimedia.org/wikipedia/commons/6/68/Bear_caches.jpg)
{kind=link}
没错,就是一种保管箱。看到右边那个被锈掉的Food Cache没?这是部署在森林里的存应急物资的保管箱。功能是把你需要用的东西放在更容易拿到的地方。虽然常用准确翻译叫 缓存,但个人以为意思表达的不对,丢了一半的功能。台湾的翻译更好,叫 快取。
相信看完这些应该不用我说区别了?
哎呀还是卖弄一下吧。
简单说,Buffer的核心作用是用来缓冲,缓和冲击。比如你每秒要写100次硬盘,对系统冲击很大,浪费了大量时间在忙着处理开始写和结束写这两件事嘛。用个buffer暂存起来,变成每10秒写一次硬盘,对系统的冲击就很小,写入效率高了,日子过得爽了。极大缓和了冲击。
Cache的核心作用是加快取用的速度。比如你一个很复杂的计算做完了,下次还要用结果,就把结果放手边一个好拿的地方存着,下次不用再算了。加快了数据取用的速度。
所以,如果你注意关心过存储系统的话,你会发现硬盘的读写缓冲/缓存名称是不一样的,叫write-buffer和read-cache。很明显地说出了两者的区别。
当然很多时候宏观上说两者可能是混用的。比如实际上memcached很多人就是拿来读写都用的。不少时候Non-SQL数据库也是。严格来说,CPU里的L2和L3 Cache也都是读写兼用——因为你没法简单地定义CPU用它们的方法是读还是写。硬盘里也是个典型例子,buffer和cache都在一块空间上,到底是buffer还是cache?
不过仔细想一下,你说拿cache做buffer用行不行?当然行,只要能控制cache淘汰逻辑就没有任何问题。那么拿buffer做cache用呢?貌似在很特殊的情况下,能确定访问顺序的时候,也是可以的。简单想一下就明白——buffer根据定义,需要随机存储吗?一般是不需要的。但cache一定要。所以大多数时候用cache代替buffer可以,反之就比较局限。这也是技术上说cache和buffer的关键区别。
——————
补充1:不要误解Buffer就是用来写的,Cache就是用来读的。读可以用Buffer吗?当然可以,比如你想一批一批地处理读取而非有啥处理啥的时候,就可以用读buffer。写当然也可以用cache,比如你的写入有很高的随机性的时候。具体什么场景用Buffer什么场景用Cache要根据场景的具体需要决定。
Cache 是有 source of truth 的,里面的数据如果没有了可以去 source of truth 重新获取,最多就是浪费一下性能而已。Buffer 不一定存在 source of truth,往里面写的东西写不下了或者丢了就永久丢了。
要问Cache和Buffer的区别,首先要问另一个问题:为何会存在Cache和Buffer?
为了提速。
从功能上看,PC挺简单的,就是“输入输出”设备:参数输入进设备(比如鼠标点击),经过计算(CPU),把结果输出到目标设备(比如打印机、显示器、网络)。
我们当然希望PC的速度越快越好,如果说有什么因素在拖慢PC的速度,那也就是在2个过程上起作用:“计算”以及“输入/输出”。
在“计算”上,我们都知道I5肯定比I3快,I9肯定比I5快,这种速度差拼的是纯硬件性能,为了提速,除了花钱购买高端硬件,别无他法。
另一方面,在“输入/输出”(也就是I/O)的过程中拖慢PC的因素,却可以不用花钱就可以解决。这些因素包括I/O过程本身的延迟,以及高速设备与低速设备交互时的等待延迟。Cache和Buffer就是从这2个方向上以软件的方法,以不花钱的方法给PC提速。
举栗说明。
假设某地发生了自然灾害(比如地震),居民缺衣少食,于是派救火车去给若干个居民点送水。
救火车到达第一个居民点,开闸放水,老百姓就拿着盆盆罐罐来接水。
假如说救火车在一个居民点停留100分钟放完了水,然后重新储水花半个小时,再开往下一个居民点。这样一个白天来来来回回的,也就是4-5个居民点。
但我们想想,救火车是何等存在,如果把水龙头完全打开,其强大的水压能轻易冲上10层楼以上, 10分钟就可以把水全部放完。但因为居民是拿盆罐接水,100%打开水龙头那就是给人洗澡了,所以只能打开一小部分(比如10%的流量)。但这样就降低了放水的效率(只有原来的10%了),10分钟变100分钟。
那么,我们是否能改进这个放水的过程,让救火车以最高效率放完水、尽快赶往下一个居民点呢?
方法就是:在居民点建蓄水池。
救火车把水放到蓄水池里,因为是以100%的效率放水,10分钟结束然后走人。居民再从蓄水池里一点一点的接水。
我们分析一下这个例子,就可以知道Cache的含义了。
救火车要给居民送水,居民要从救火车接水,就是说居民和救火车之间有交互,有联系。
但救火车是“高速设备”,居民是“低速设备”,低速的居民跟不上高速的救火车,所以救火车被迫降低了放水速度以适应居民。
为了避免这种情况,在救火车和居民之间多了一层“蓄水池(也就是Cache)”,它一方面以100%的高效和救火车打交道,另一方面以10%的低效和居民打交道,这就解放了救火车,让其以最高的效率运行,而不被低速的居民拖后腿,于是救火车只需要在一个居民点停留10分钟就可以了。
所以说,蓄水池是“活雷锋”,把高效留给别人,把低效留给自己。把10分钟留给救火车,把100分钟留给自己。
从以上例子可以看出,所谓Cache,就是“为了弥补高速设备与低速设备之间交互时的等待延迟”而设立的一个中间层。因为在现实里经常出现高速设备要和低速设备打交道,结果被低速设备拖后腿的情况。
回到PC。CPU速度很快,但CPU执行的指令是从内存取出的,计算的结果也要写回内存,但内存的响应速度跟不上CPU。
CPU跟内存说:你把某某地址的指令发给我。内存听到了,但因为速度慢,迟迟不见指令返回,这段时间,CPU只能无所事事的等待了。这样一来,再快的CPU也发挥不了效率。
怎么办呢?在CPU和内存之间加一块“蓄水池”,也就是Cache(片上缓存),这个Cache速度比内存快,从Cache取指令不需要等待。
当CPU要读内存的指令的时候先读Cache再读内存,但一开始Cache是空着的,只能从内存取,这时候的确是很慢,CPU需要等待。
但从内存取回的不仅仅是CPU所需要的指令,还有其它的、当前不需要的指令,然后把这些指令存在Cache里备用。
CPU再取指令的时候还是先读Cache,看看里面有没有所需指令,如果碰巧有就直接从Cache取,不用等待即可返回(命中),这就解放了CPU,提高了效率。(当然不会是100%命中,因为Cache的容量比内存小)
<img src="https://pic1.zhimg.com/50/v2-e62c6d9272aedc29ee30c6f36ebb780a_hd.jpg" data-caption="" data-size="normal" data-rawwidth="398" data-rawheight="396" class="content_image" width="398">
CPU的Cache,可以有好几层,而且还分数据Cache和指令Cache。
也许你会问,既然Cache的响应速度快,CPU不需要等待,那为啥还要用“慢速”的内存条呢?直接用Cache不就得了?这是因为在具体制造上有困难,大Cache不但成本无法接受,而且容量大了延迟也会上升。
磁盘缓存也是Cache。刚才说内存是慢速设备,所以需要片上缓存,但这个“慢”是相对于CPU而言的,相对于机械硬盘HDD,内存的速度可快多了。
对于磁盘的读写操作,在很久以前,读写过程需要CPU参与,后来出现了“DMA/直接内存访问"就不再需要CPU了,但即使如此,高负荷、长时间的磁盘读写也非常的耗时,因为磁盘是机械旋转部件,其读写速度相比CPU和内存条的二进制电压变化速度,那就是蒸汽机和火箭速度的差别。
为了加快数据的读写速度,在磁盘和内存之间也插入一层Cache(Windows在内存里划分出一块区域作为Cache,硬盘也有板载Cache。)
写入数据的时候先写入到Cache里;因为Cache很快,所以数据很快就写入。
比方说,1G的数据,如果直接写入硬盘需要10秒,但写入Cache(也就是系统内存)只需要1秒。
这样一来用户就有了系统速度很快的“幻觉”。但这只是障眼法,数据暂存在Cache里并没有被真正写入磁盘,等系统空闲的时候再慢慢写入。
同理,在读数据的时候,除了所需的数据,还有一堆目前不需要的数据也都被读出来放到内存的Cache里。下次再读的时候,如果恰巧Cache里有所需的数据就可直接读入(命中),这就避免了从慢速的HDD读数据的尴尬。用户的体验同样也是速度很快。(同样不会100%命中,因为RAM的容量远小于硬盘容量)
<img src="https://pic1.zhimg.com/50/v2-ca8cadd1052a5d261c02c02c2792bdf6_hd.jpg" data-caption="" data-size="normal" data-rawwidth="543" data-rawheight="209" class="origin_image zh-lightbox-thumb" width="543" data-original="https://pic1.zhimg.com/v2-ca8cadd1052a5d261c02c02c2792bdf6_r.jpg">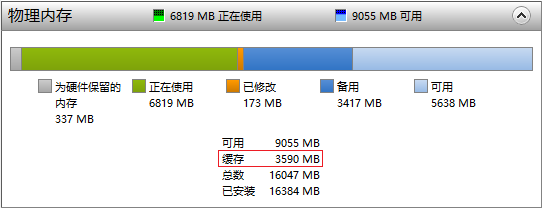
PC有16G的内存,磁盘Cahce占用了3.59G,这是动态的,会自动调整大小
<img src="https://pic1.zhimg.com/50/v2-9a784b47e3c5f3ad405f627df6889a9c_hd.jpg" data-caption="" data-size="normal" data-rawwidth="291" data-rawheight="63" class="content_image" width="291">
硬盘也内置了Cache。某品牌硬盘的广告强调了大缓存的优势
以上举了3个栗子:蓄水池、CPU的Cache、磁盘的Cache
Cache是为了解决什么问题?高速与低速设备通信时,因为低速设备响应缓慢的原因,造成高速设备的性能优势无法发挥,所以需要Cache给高速设备降低延迟,加快速度!
那么buffer呢? 是从另一个方向降低延迟,与上面的原因不同,该延迟来自于IO过程本身。
请允许我再次举起栗子。
比如说吐鲁番的葡萄熟了,要用大卡车装葡萄运出去卖。
但问题是,卡车距离葡萄园很远,于是就需要在葡萄园和卡车之间往返多次才能把卡车装满。往返所需要的时间就是I/O延迟,比如往返各15分钟,总共半小时。
果园的姑娘采摘葡萄,难道是摘一串葡萄,就花15分钟跑到卡车旁边放进去么?如果是这样,100串葡萄就需要往返100次,所需要的时间就是100X15X2分钟,那是何其漫长!
所以聪明的做法就是暂时把100串葡萄放入一个箩筐,再以箩筐为单位倒入卡车,一箩筐(100串)葡萄的往返延迟是半小时。
由此可见,“箩筐”把输入参数暂时集中放在一起,不是“一条一条”,而是“一股脑”地提供给下家处理。这就大大降低了I/O的次数,也就降低了I/O延迟,提高了速度。
这个箩筐,就是Buffer。
I/O次数过多,除了会造成很大的延迟之外,也会有其它的问题。
以BT为例,BT下载需要长时间的挂机,电脑就有可能24小时连轴转,但BT下载的数据是碎片化的,体现在硬盘写入上也是碎片化的,因为硬盘是机械寻址器件,寻址/写入的过程会带来机械运动,长时间的小碎片写入会造成硬盘长时间高负荷的机械运动,造成硬盘过早老化损坏,当年有大量的硬盘因为BT下载而损坏。
于是新出的BT软件在内存里开辟了Buffer,数据暂时写入Buffer,攒到一定的大小(比如512M)再一次性写入硬盘,这种“化零为整”的写入方式因为大大减小了寻址/写入次数,所以就降低了硬盘的负荷。
这就是:为了完成最终目标:把数据写入硬盘空间,需要暂时写入Buffer的空间。
再以编程为例,假设要实现一个功能:接受用户键入的字符串,并赋值给一个字符串变量
其过程如下:
1:在内存中开辟一个”键盘缓冲区“接受用户键入的字符串
2:把缓冲区中的字符串copy到程序中定义的字符串变量指向的内存空间(也就是赋值过程)
也就是说,为了完成最终目标:把字符串放入字符串变量指向的空间,需要暂时把字符串放入“键盘缓冲区”的空间。
buffer:缓冲
将数据缓冲下来,解决速度慢和快的交接问题;速度快的需要通过缓冲区将数据一点一点传给速度慢的区域。例如:从内存中将数据往硬盘中写入,并不是直接写入,而是缓冲到一定大小之后刷入硬盘中。
A buffer is something that has yet to be "written" to disk.
cache:缓存
实现数据的重复使用,速度慢的设备需要通过缓存将经常要用到的数据缓存起来,缓存下来的数据可以提供高速的传输速度给速度快的设备。例如:将硬盘中的数据读取出来放在内存的缓存区中,这样以后再次访问同一个资源,速度会快很多。
A cache is something that has been "read" from the disk and stored for later use.
总结:
buffer是用于存放将要输出到disk(块设备)的数据,而cache是存放从disk上读出的数据。二者都是为提高IO性能而设计的。
首先谢谢你的邀请。
是这样的,其实Cache和Buffer,物理上讲都是RAM。逻辑上讲,你把Cache叫成Buffer,或者把Buffer叫成Cache,都没有错。
不过Buffer多用于编程方面,Cache多用于非编程方面的叫法。比如为某程序分配一段Buffer,而一般没有说为某程序分配一段Cache的,但是你可以说这个程序有Cache,或者说Cache是泛指,Buffer是特指。见仁见智。而对于磁盘阵列来讲,Buffer=Cache。
另外,从本质上讲,Buffer是“缓冲”,而Cache是“缓存”,即Buffer中的数据是一定要在短时间内被处理的,而Cache则可以作为一个数据的长期的容器而其中的数据不一定非要被立刻处理。看了前面一整页感觉只有
和 回答比较模糊的说到了我认为的关键点,大部分回答说的基本上都是一些表面上的区别。回答举生活中例子的,基本上都只是举了个例子并没有给出一个如何精确区分buffer和cache的标准。高票答案说cache是用来处理速度不匹配而buffer是用来处理速度平衡的,恕我直言完全没看明白这两者的区别是什么。
回答说buffer是写的,cache是读的,我感觉从实践角度上来说已经比较接近事实了,更准确的说法似乎应该是buffer有读buffer和写buffer,但是cache基本上只用来读,不太会有专门的写cache(经@Sigma网友提醒,这里有些让人误解,数据写回的时候当然也是经过cache的,我是想说很少回出现一个cache是专门为了写操作而设计的,一般都是以读为主)。
出现这种区别的最核心的因素在于:buffer的概念是buffer里存的都是有价值的数据,而cache的逻辑有点类似一人得道鸡犬升天。
具体解释一下,无论是读buffer还是写buffer,buffer里的所有数据都是你将来确定要用到的,不会有你没有请求的数据在buffer中。而cache的策略就不一样了,你读一次数据,它会把你这次请求的数据身边的一堆数据一起放在cache中,无论你是否会需要到这些数据。这就是为什么有些答案中提到buffer一般是用队列实现,而cache一般要支持随机访问,并且有命中率的概念的核心原因。
参考
的说法:Buffer是临时性的,是两个同时输出/输入交换数据的的一个缓存口,首先它是临时性的,用完可以扔掉,如 所说,是用来抵消掉两者之间的突然性波动。或者减少过于断续短小的输入导致输出频繁响应,影响输出响应。 Cache偏近是永久性的,更像将输入的数据保存下来,输出如果需要的数据已经存在,就不需要直接再一次拉输入,而是直接拉已经保存下来的,尤其完成一次输入时要耗时极长时。
2、一般来说cache越大,性能越好,超过一定程度,导致命中率太低之后才会越大性能越低。buffer来说,空间越大性能影响不大,够用就行。
3、cache过小,或者没有cache,不影响程序逻辑(高并发cache过小或者丢失导致系统忙死除外)。buffer过小有时候会影响程序逻辑,如导致网络丢包。
4、cache可以做到应用透明,编写应用的可以不用管是否有cache,可以在应用做好之后再上cache。当然开发者显式使用cache也行。buffer需要编写应用的人设计,是程序的一部分。
Cache和Buffer都既可以用硬件实现,也可以用软件实现。它们都作为数据发送源和接收端的中间数据存储。它们都是为了提高数据访问效率(但Buffer除此之外还有其它功能)。故Cache和Buffer的功能是有一定交叉的。
广义上来讲,Cache可以当Buffer用,但Buffer不能当Cache用。但一般还是会明显区别开2者。
之前有很多答案提到,Cache是为了缓和“高速和低速设备/端的速度差异”。对,确实是这样的。但其实Buffer也有这样的功能和作用。还有说Buffer是用作临时存储,Cache不是的,但其实Cache也是用于临时存储。
不同的是,Cache的唯一作用就是减少访问低速端数据的次数、降低数据访问时延。这是Cache的根本作用,也是Cache区别于Buffer的地方所在。Cache里的数据,我们希望能够多次访问到,因为多次访问到Cache里的数据就不用从低速的数据源端访问从而节省时间。所以Cache会有命中率,越高越好。所以,Cache很多由硬件来实现,CPU、TLB、GPU、DSP、Disk等的Cache都是速度很快存储器(与数据收、发2端最慢的设备相比),同时也导致Cache比较贵,容易小。所以Cache会有替换策略/算法。
但Buffer则完全不同。Cache很多是硬件实现,软件实现的也有,比如web服务器缓存、浏览器缓存,而Buffer绝大多数都是由软件来实现的,较少由硬件来实现,比如我们平常所说的磁盘缓存一般指的是硬件Buffer而非Cache。
所以,即使Cache和Buffer都可以用来缓冲“高低速设备之间速度差异”,如果Cache里的数据第一次读入后再也用不到了,那毫无疑问Cache做了无用功、是失败的,仅仅作为了一个临时存储器,相当于Buffer;但对于Buffer而言,哪怕Buffer里的数据只需要用一次也是成功的,因为Buffer的本意就不是通过命中率来减少访问低速端数据的次数从而降低时延,而是通过批量操作来提高数据访问效率。
当然,除此之外,Buffer还可以作为通信双方无法或不方便直接通信时的中转层等。
如果咬文嚼字的话,一般有这么区分:
1. 读的叫Cache,写的叫buffer
2. 不同请求共用的叫cache,作用域主要是本请求的叫buffer
比如OS处理网络数据的速度远超过网卡接收数据,因此需要一个Buffer,等存满了一次性交给OS。
又比如从数据库获取数据很慢,所以对于不经常修改的数据,就一次性取出,放入Cache,将来就不去数据库取了
linux的buffer与cache,见文章:
如文中我有理解错误的地方也请各位及时指出,如转载请注明出处。
(本文所有截图来自《深入理解linux内核-第三版》 DANIEL P.BOVET & MARCO
CESATE著 陈莉君 张琼声 张宏伟 译 中国电力出版社)
提前需了解的内容, VFS, inode,address_space,radix_tree之前关联 :(可参考之前的一个回答https://www.zhihu.com/question/52639327/answer/134434918)
先说总结:
1. Linux2.4.10之前的内核中,分两种disk cache, 分别为buffer cache和page cache,区别见文章最后两个截图(至于具体里面放什么结构的数据,我也不知道,还没看过2.4内核的块设备和VFS这部分内容)。
2. 大约2.4.10后的内核,buffer cache已经不存在了(或者说换了一种数据存放的方法) 而这种页面的叫法也变了,叫做 buffer page, 而buffer page放在什么地主呢? 它放在page cache中。
听着很绕口, 或者可以这样讲: 2.4.10之后的内核的disk cache 只有 page cache, 而page cache中有些页面被叫做buffer page的,是因为这些页面(buffer page)都有与其相关的buffer_head 描述符,也正是这样页面被free 统计为 buffer 占用。如果没有buffer_head与该页相关,则被free统计为 cache占用。 Buffer page 与 buffer_head(下图中右边方框里的 缓冲区首部 )的关联如下 截图1:
<img src="https://pic2.zhimg.com/50/v2-4cbec5e9539e6dd78193a7214e168b8b_hd.jpg" data-size="normal" data-rawwidth="554" data-rawheight="279" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic2.zhimg.com/v2-4cbec5e9539e6dd78193a7214e168b8b_r.jpg">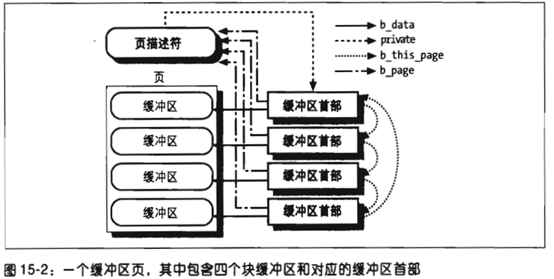 (截图 1, 书611页)
(截图 1, 书611页)
缓冲区首部(buffer_head)的结构(include/linux/fs.h):
struct buffer_head {
/* First cache line: */
struct buffer_head *b_next; /* Hash queue list*/
unsigned long b_blocknr; /* block number */
unsigned short b_size; /* block size */
unsigned short b_list; /* List that this buffer appears */
kdev_t b_dev; /* device (B_FREE = free) */
atomic_t b_count; /* users using this block */
kdev_t b_rdev; /* Real device */
……
char * b_data; /* pointer to data block (512byte) */
struct page *b_page; /* the page this bh is mapped to */
void (*b_end_io)(struct buffer_head *bh, intuptodate); /* I/O completion */
void *b_private; /* reserved for b_end_io */
unsigned long b_rsector; /* Real buffer location on disk */
wait_queue_head_t b_wait;
struct inode * b_inode;
struct list_head b_inode_buffers; /* doubly
linked list of inode dirty buffers */
};
注意结构中下面的三个字段:
- kdev_t b_dev:表示包含该块的块设备,通常是一个磁盘或分区
- unsigned long b_blocknr;存放逻辑块号,表示块在磁盘或分区上的逻辑块号
- struct page *b_page; 指向包含该块的页描述符
buffer_head 结构中以上三个字段把页中的内容和磁盘上的块直接关联起来。
下面来说说,buffer page里面放的是什么。
首先我们应该了解何时,内核会分配buffer page:
<img src="https://pic4.zhimg.com/50/v2-a519950740989c94d9b5e2e2f538dc6a_hd.jpg" data-size="normal" data-rawwidth="554" data-rawheight="94" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic4.zhimg.com/v2-a519950740989c94d9b5e2e2f538dc6a_r.jpg"> (截图2, 书609页)<img src="https://pic3.zhimg.com/50/v2-2ec35fcdfcb0831f09bb6e0f12d7dbed_hd.jpg" data-size="normal" data-rawwidth="612" data-rawheight="343" class="origin_image zh-lightbox-thumb" width="612" data-original="https://pic3.zhimg.com/v2-2ec35fcdfcb0831f09bb6e0f12d7dbed_r.jpg">
(截图2, 书609页)<img src="https://pic3.zhimg.com/50/v2-2ec35fcdfcb0831f09bb6e0f12d7dbed_hd.jpg" data-size="normal" data-rawwidth="612" data-rawheight="343" class="origin_image zh-lightbox-thumb" width="612" data-original="https://pic3.zhimg.com/v2-2ec35fcdfcb0831f09bb6e0f12d7dbed_r.jpg">
 (截图3,书610页)
(截图3,书610页)
对于截图3中说的第一种情况,这里举个例子,如下面图中,如果该页属于同一个文件,且文件所在的文件系统的 block size 为1k, 页面中的4个block如果在磁盘上都不连续,那么这个页面就成为buffer page,且有与页中4个block相关的buffer_head结构:
<img src="https://pic2.zhimg.com/50/v2-142a68961a3497709a44a39a6c617f89_hd.jpg" data-size="normal" data-rawwidth="423" data-rawheight="342" class="origin_image zh-lightbox-thumb" width="423" data-original="https://pic2.zhimg.com/v2-142a68961a3497709a44a39a6c617f89_r.jpg">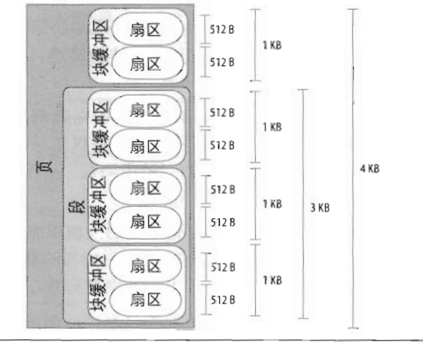 (截图4,书560页)
(截图4,书560页)
 (截图5,书610页)
(截图5,书610页)
对于截图3中所说的第二种情况:
<img src="https://pic1.zhimg.com/50/v2-4eb05423ccc752725b2553e834488607_hd.jpg" data-size="normal" data-rawwidth="538" data-rawheight="290" class="origin_image zh-lightbox-thumb" width="538" data-original="https://pic1.zhimg.com/v2-4eb05423ccc752725b2553e834488607_r.jpg"> (截图6,书610页)
(截图6,书610页)
由些可见,从磁盘读出来的文件在file system上的inode(ext3_inode ?)信息是放在buffer page里的,但是,这种page的所有者(如果一个cache页面是某文件的内容,那么我们说这个文件是此页面的所有都,或者属主)是哪个文件呢?往下看截图7的第二段:
<img src="https://pic1.zhimg.com/50/v2-a2f47616f0a7fff780ce30e0c6674a78_hd.jpg" data-size="normal" data-rawwidth="554" data-rawheight="255" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic1.zhimg.com/v2-a2f47616f0a7fff780ce30e0c6674a78_r.jpg"> (截图7-书599页)
(截图7-书599页)
Buffer Page的所有者(即属主)是这个文件系统所在设备的总设备文件(如,所有 /dev/sdb1,/dev/sdb2, 的buffer page的所有者都是 /dev/sdb这主个设备文件,因为对于磁盘设备驱动程序来说,处理各分区读写是无差别的,而且对分区的读写最后是要合并后并给主设备的,所以分区并不会提高读写性能,但分区可以保持数据隔离,一个分区文件系统崩毁不会影响到其他分区的文件)。
最后,直接访问一个设备文件会发生什么呢?架个虚拟机,启动一段时间后,待free输出cache和buffer部分稳定后,再执行下面内容:
#free 记录输出中buffer和cache的大小
#cat /proc/slabinfo |grep buffer_head 记录buffer_head的分配和使用数量
#cat /dev/sdb1 >/dev/null 这条命令执行完成后,再执行free 和cat /proc/slabinfo 查看输出 并和前面做对比。
最后帖一个linux 统计buffer的相关函数内容(原文件链接:https://github.com/liuyangc3/note-book/blob/master/kernel/Cache%20and%20Buffer.md):
buffer:
从 free 命令的代码里(项目地址 http://procps.sourceforge.net)
可以得知命令的数值实际上是 从 /proc/meminfo 来的,而 meminfo 的数值是从系统调用 sysinfo 来的。
具体详情 http://blog.csdn.net/lux_veritas/article/details/19231993
文章里提到了一个函数 si_meminfo mm/page_alloc.c
void si_meminfo(struct sysinfo *val)
{
val->totalram = totalram_pages;
val->sharedram = 0;
val->freeram = global_page_state(NR_FREE_PAGES);
val->bufferram = nr_blockdev_pages();
val->totalhigh = totalhigh_pages;
val->freehigh = nr_free_highpages();
val->mem_unit = PAGE_SIZE;
}
可以看到 bufferram 的值是函数 nr_blockdev_pages() 得到的 fs/block_dev.c
long nr_blockdev_pages(void)
{
struct block_device *bdev;
long ret = 0;
spin_lock(&bdev_lock);
list_for_each_entry(bdev,&all_bdevs, bd_list)
{
ret+= bdev->bd_inode->i_mapping->nrpages;
}
spin_unlock(&bdev_lock);
return ret;
}
可以看到这个函数其实就是,遍历了所有的块设备,然后把这些设备 bd_inode 上的 pages 数目加起来。这些 page 由内核通过一颗 radix tree 来维护,而 nrpages 记录了tree pages 的数量。buffer 统计的是所有block device 对应的inode的 address_space的 page的数量。
如何增加 buffers ?
cat /dev/sda1 > /dev/null
所以可以确定的是直接访问 block 设备产生的 page cache是保存到 block device的 bd_inode 里面的。
另:关于linux 2.4.10之前内核对buffer和cache 的描述:
<img src="https://pic2.zhimg.com/50/v2-96ba2b2596202feeaa34efd01a8d8bb8_hd.jpg" data-size="normal" data-rawwidth="554" data-rawheight="312" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic2.zhimg.com/v2-96ba2b2596202feeaa34efd01a8d8bb8_r.jpg"> (截图8—书607页)
(截图8—书607页)
英文版:
<img src="https://pic4.zhimg.com/50/v2-967aae8304770127ef99f283a3c46f31_hd.jpg" data-caption="" data-size="normal" data-rawwidth="554" data-rawheight="281" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic4.zhimg.com/v2-967aae8304770127ef99f283a3c46f31_r.jpg">
cache 是缓存/快取,有“命中”这个概念。buffer 是缓冲,缓冲不是缓存。提问前提不成立。
TLB is about speeding up address translation for Virtual memory so that page-table needn’t to be accessed for every address.
CPU Cache is about speeding up main memory access latency so that RAM isn’t accessed always by CPU.
那人体打比方的话,
buffer是胃,主要功能是让数据能慢慢的写,而不影响其他工作。同时还能让还未写又更改的数据快速改变(反刍,笑);
cache是记忆T细胞,主要功能是提高同一个数据多次使用时的效率;
Buffer绝不应该理解成为缓存,而应该是缓冲。目的是临时存放,马上会被消费掉。
Cache的目的则是加快读取速度,并且通常cache是可复制的,可重复使用的,除非过期或者失效,则不需要消亡。
形象点来说:
Buffer是一个月光族的银行卡余额
Cache是你把钥匙从背包深处掏出来,放到了口袋里;有时候你还会复制一把钥匙放口袋里面
银行卡余额用一点少一点,并且有时候你需要攒几个月工资一起花;而怎么用钥匙,钥匙都不会少,除非锁换了buffer 和 cache 这两个词现在经常混用,如果硬要区分的话,
Buffer is something that has yet to be "written" to disk.
Cache is something that has been "read" from the disk and stored for later use.
简单说,buffer 存放要输入到块设备的数据,cache 存放从块设备上读取的数据。
我的理解,
- Cache和Buffer的数据都是临时的
- Cache中的数据是可以丢弃的(要么数据不重要,要么数据有持久化副本)
- Buffer中的数据是没有持久化的数据
- Cache的目的是加速
- Buffer的目的是配速,以配合上下游两个处理速度不一样的模块,使系统平稳工作
我一直理解的buffer是那种囤囤囤抽水的管子,今天才知道不对,但这个理解微妙地凑上了边。
池水可以有多类型的输入,但是总要被集合成一个固定的形式输出,这就是buffer。因此说buffer是缓存是不对的,缓存是池子,而buffer是以固定形式囤囤囤的管子。
a data buffer (or just buffer) is a region of a physical memory storage used to temporarily store data while it is being moved from one place to another.
a cache /ˈkæʃ/ KASH,[1] is a hardware or software component that stores data so future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation, or the duplicate of data stored elsewhere.
Cache有private属性,Buffer有public属性。
在一个系统中,直接把Cache层暴力删除,往往系统还能正常工作,但是如果暴力删除Buffer层,往往系统会崩溃。
另外,Cache是为了缓存计算结果,减少冗余计算。Buffer有点批处理的味道,它把东西缓存下来,然后一次性提交。