目录
一,验证二叉搜索树
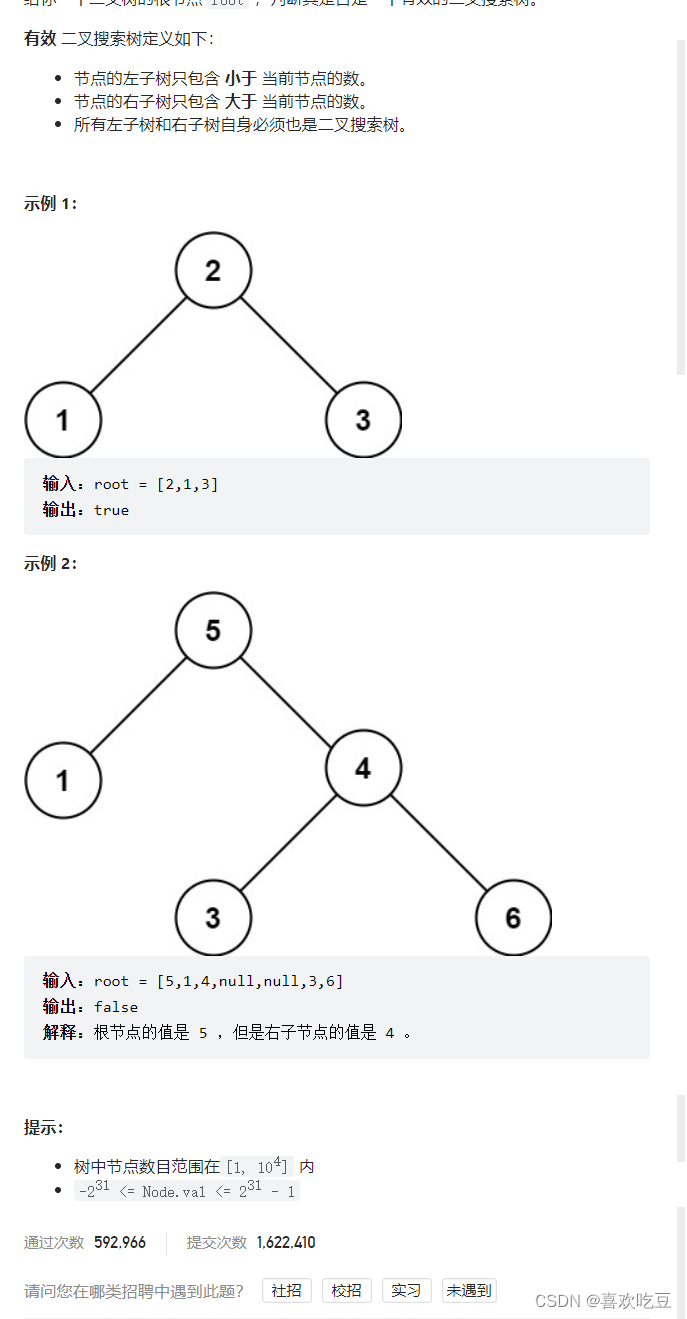
1,递归
思路和算法
要解决这道题首先我们要了解二叉搜索树有什么性质可以给我们利用,由题目给出的信息我们可以知道:如果该二叉树的左子树不为空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;它的左右子树也为二叉搜索树。
这启示我们设计一个递归函数 helper(root, lower, upper) 来递归判断,函数表示考虑以 root 为根的子树,判断子树中所有节点的值是否都在 (l,r) 的范围内(注意是开区间)。如果 root 节点的值 val 不在 (l,r) 的范围内说明不满足条件直接返回,否则我们要继续递归调用检查它的左右子树是否满足,如果都满足才说明这是一棵二叉搜索树。
那么根据二叉搜索树的性质,在递归调用左子树时,我们需要把上界 upper 改为 root.val,即调用 helper(root.left, lower, root.val),因为左子树里所有节点的值均小于它的根节点的值。同理递归调用右子树时,我们需要把下界 lower 改为 root.val,即调用 helper(root.right, root.val, upper)。
函数递归调用的入口为 helper(root, -inf, +inf), inf 表示一个无穷大的值。
class Solution {
public:
bool helper(TreeNode* root, long long lower, long long upper) {
if (root == nullptr) {
return true;
}
if (root -> val <= lower || root -> val >= upper) {
return false;
}
return helper(root -> left, lower, root -> val) && helper(root -> right, root -> val, upper);
}
bool isValidBST(TreeNode* root) {
return helper(root, LONG_MIN, LONG_MAX);
}
};
复杂度分析
时间复杂度:O(n),其中 n 为二叉树的节点个数。在递归调用的时候二叉树的每个节点最多被访问一次,因此时间复杂度为 O(n)。
空间复杂度:O(n),其中 n 为二叉树的节点个数。递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度,即二叉树的高度。最坏情况下二叉树为一条链,树的高度为 n ,递归最深达到 n 层,故最坏情况下空间复杂度为 O(n) 。
2,中序遍历
思路和算法
基于方法一中提及的性质,我们可以进一步知道二叉搜索树「中序遍历」得到的值构成的序列一定是升序的,这启示我们在中序遍历的时候实时检查当前节点的值是否大于前一个中序遍历到的节点的值即可。如果均大于说明这个序列是升序的,整棵树是二叉搜索树,否则不是,下面的代码我们使用栈来模拟中序遍历的过程。
可能有读者不知道中序遍历是什么,我们这里简单提及。中序遍历是二叉树的一种遍历方式,它先遍历左子树,再遍历根节点,最后遍历右子树。而我们二叉搜索树保证了左子树的节点的值均小于根节点的值,根节点的值均小于右子树的值,因此中序遍历以后得到的序列一定是升序序列。
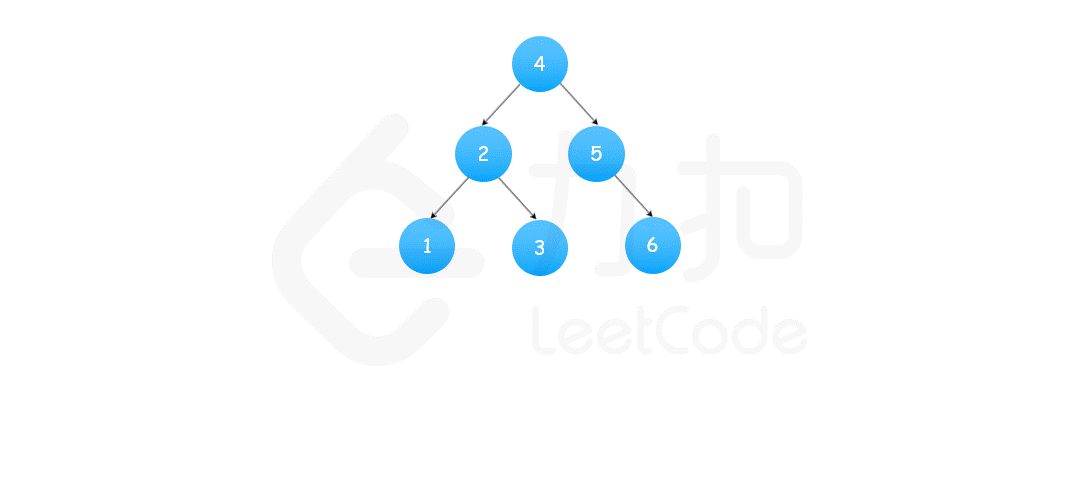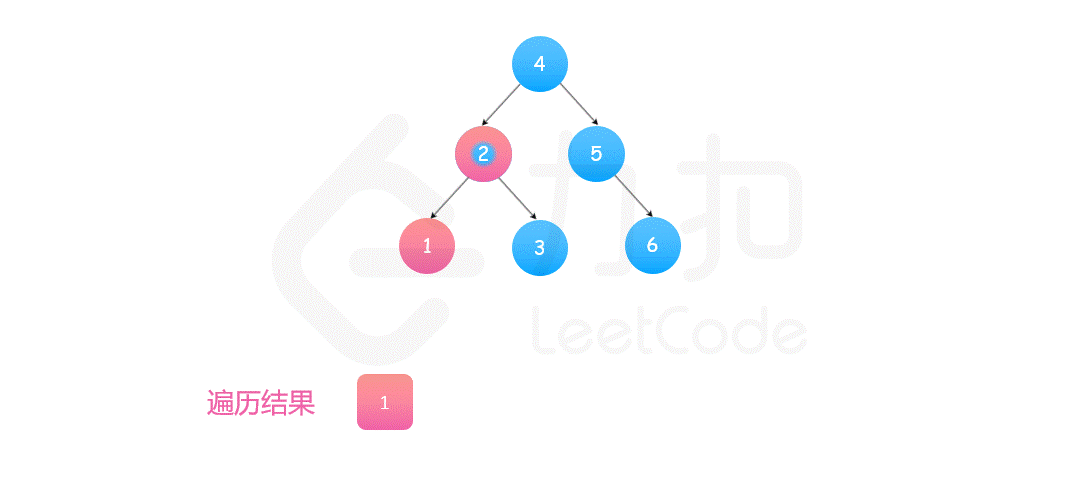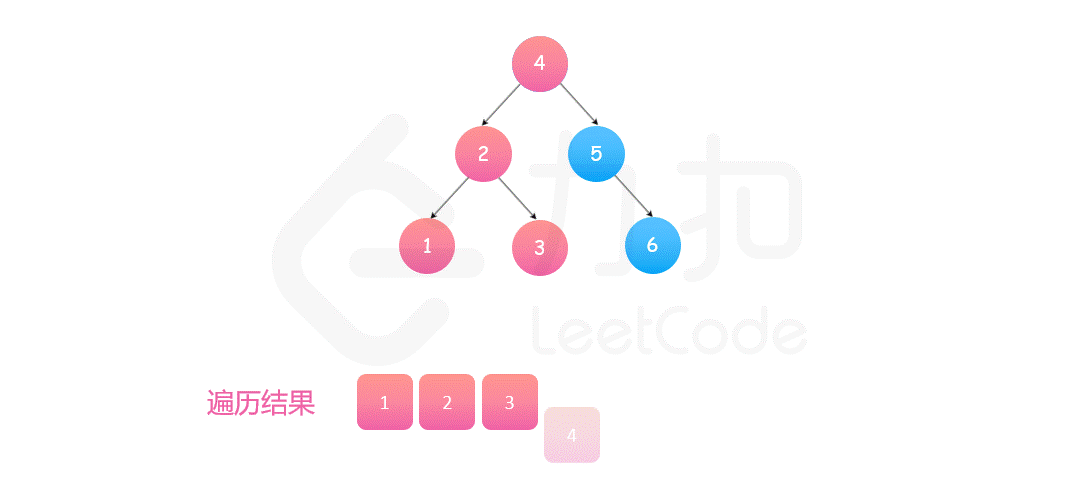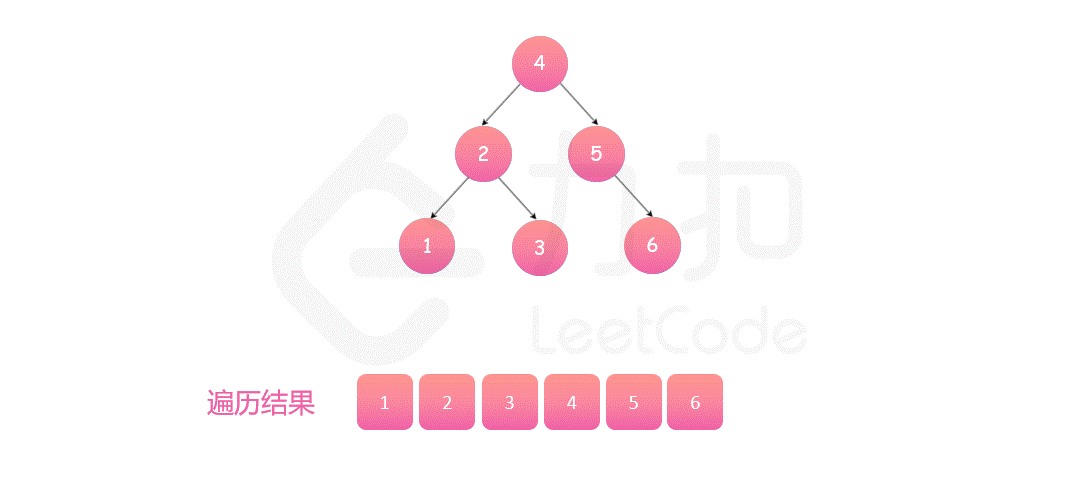
class Solution {
public:
bool isValidBST(TreeNode* root) {
stack<TreeNode*> stack;
long long inorder = (long long)INT_MIN - 1;
while (!stack.empty() || root != nullptr) {
while (root != nullptr) {
stack.push(root);
root = root -> left;
}
root = stack.top();
stack.pop();
// 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树
if (root -> val <= inorder) {
return false;
}
inorder = root -> val;
root = root -> right;
}
return true;
}
};
复杂度分析
时间复杂度:O(n),其中 n 为二叉树的节点个数。二叉树的每个节点最多被访问一次,因此时间复杂度为 O(n)。
空间复杂度:O(n),其中 n 为二叉树的节点个数。栈最多存储 n 个节点,因此需要额外的 O(n) 的空间。
二,两数之和 IV - 输入二叉搜索树
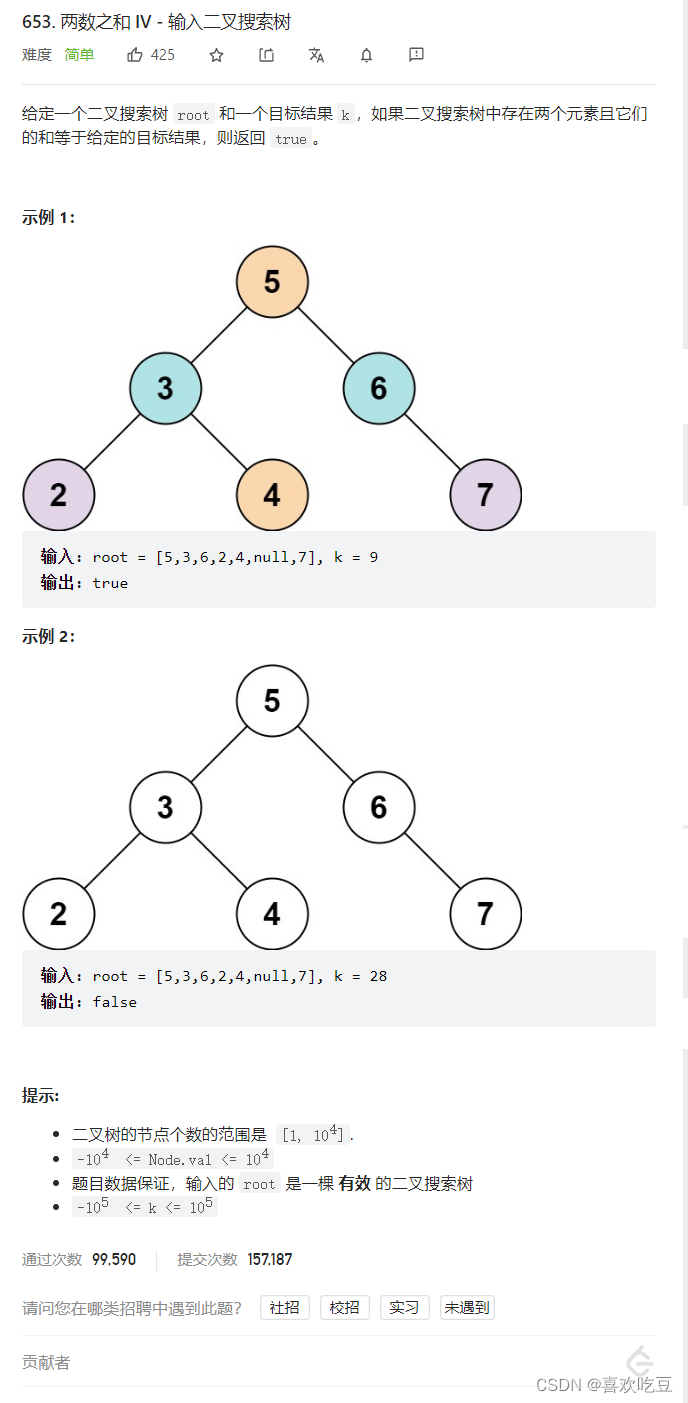
看题解:
三,二叉搜索树的最近公共祖先

1,两次遍历
思路与算法
注意到题目中给出的是一棵「二叉搜索树」,因此我们可以快速地找出树中的某个节点以及从根节点到该节点的路径,例如我们需要找到节点 p:
我们从根节点开始遍历;
如果当前节点就是 p,那么成功地找到了节点;
如果当前节点的值大于 p 的值,说明 p 应该在当前节点的左子树,因此将当前节点移动到它的左子节点;
如果当前节点的值小于 p 的值,说明 p 应该在当前节点的右子树,因此将当前节点移动到它的右子节点。
对于节点 q 同理。在寻找节点的过程中,我们可以顺便记录经过的节点,这样就得到了从根节点到被寻找节点的路径。
当我们分别得到了从根节点到 p 和 q 的路径之后,我们就可以很方便地找到它们的最近公共祖先了。显然,p 和 q 的最近公共祖先就是从根节点到它们路径上的「分岔点」,也就是最后一个相同的节点。因此,如果我们设从根节点到 p 的路径为数组 path_p,从根节点到 q 的路径为数组 path_q,那么只要找出最大的编号 i,其满足
path_p[i]=path_q[i]
那么对应的节点就是「分岔点」,即 p 和 q 的最近公共祖先就是 path_p[i](或 path_q[i])。
class Solution {
public:
vector<TreeNode*> getPath(TreeNode* root, TreeNode* target) {
vector<TreeNode*> path;
TreeNode* node = root;
while (node != target) {
path.push_back(node);
if (target->val < node->val) {
node = node->left;
}
else {
node = node->right;
}
}
path.push_back(node);
return path;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
vector<TreeNode*> path_p = getPath(root, p);
vector<TreeNode*> path_q = getPath(root, q);
TreeNode* ancestor;
for (int i = 0; i < path_p.size() && i < path_q.size(); ++i) {
if (path_p[i] == path_q[i]) {
ancestor = path_p[i];
}
else {
break;
}
}
return ancestor;
}
};
复杂度分析
时间复杂度:O(n),其中 nn 是给定的二叉搜索树中的节点个数。上述代码需要的时间与节点 p 和 q 在树中的深度线性相关,而在最坏的情况下,树呈现链式结构,p 和 q 一个是树的唯一叶子结点,一个是该叶子结点的父节点,此时时间复杂度为 Θ(n)。
空间复杂度:O(n),我们需要存储根节点到 p 和 q 的路径。和上面的分析方法相同,在最坏的情况下,路径的长度为 Θ(n),因此需要Θ(n) 的空间。
2,一次遍历
思路与算法
在方法一中,我们对从根节点开始,通过遍历找出到达节点 p 和 q 的路径,一共需要两次遍历。我们也可以考虑将这两个节点放在一起遍历。
整体的遍历过程与方法一中的类似:
我们从根节点开始遍历;
如果当前节点的值大于 p 和 q 的值,说明 p 和 q 应该在当前节点的左子树,因此将当前节点移动到它的左子节点;
如果当前节点的值小于 p 和 q 的值,说明 p 和 q 应该在当前节点的右子树,因此将当前节点移动到它的右子节点;
如果当前节点的值不满足上述两条要求,那么说明当前节点就是「分岔点」。此时,p 和 q 要么在当前节点的不同的子树中,要么其中一个就是当前节点。
可以发现,如果我们将这两个节点放在一起遍历,我们就省去了存储路径需要的空间。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
TreeNode* ancestor = root;
while (true) {
if (p->val < ancestor->val && q->val < ancestor->val) {
ancestor = ancestor->left;
}
else if (p->val > ancestor->val && q->val > ancestor->val) {
ancestor = ancestor->right;
}
else {
break;
}
}
return ancestor;
}
};
复杂度分析
-
时间复杂度:O(n),其中 n 是给定的二叉搜索树中的节点个数。分析思路与方法一相同。
-
空间复杂度:O(1)。