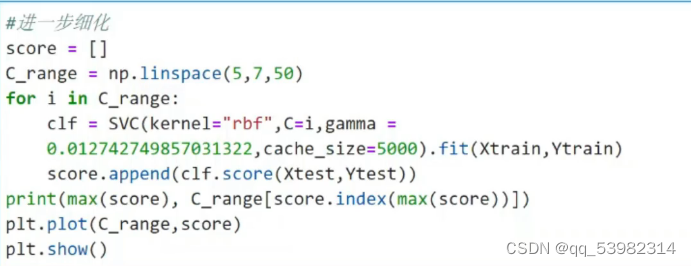
一、支持向量机SVM

主要是寻找决策边界。

第二层:

类:
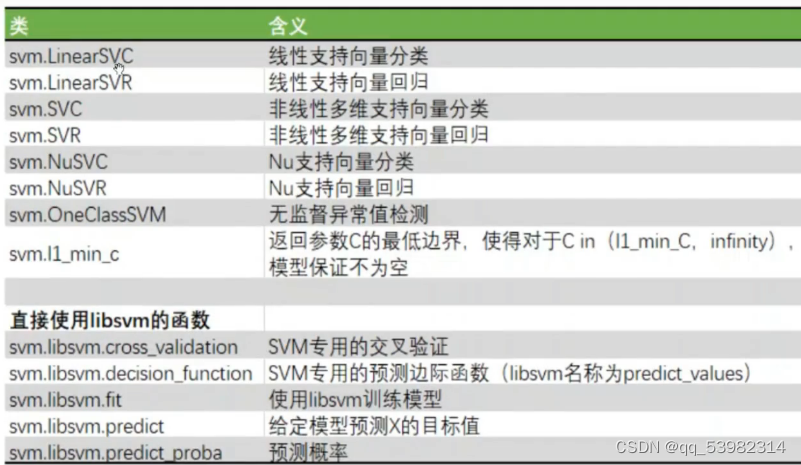
1. sklearn.svm.SVC
例如,svm将两类分开。即二维平面的一条线: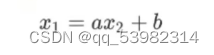 将平面分开,分出的点y成为-1,+1这两类。即公式:
将平面分开,分出的点y成为-1,+1这两类。即公式:
即如图所示: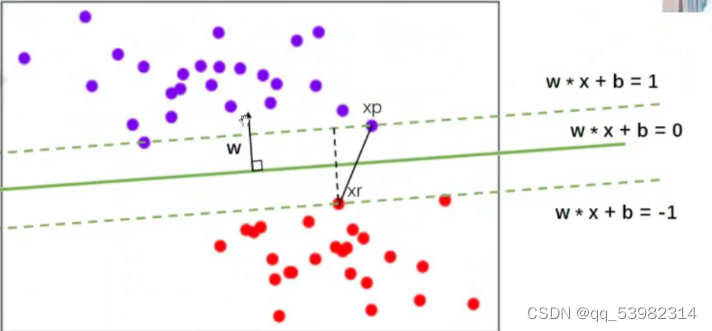
这里的w,x均为向量。
1.1 代码
- 数据集代码:
from sklearn.datasets import make_blobs as mb
from sklearn.svm import SVC as svc
import matplotlib.pyplot as pt
import numpy as np
x,y=mb(n_samples=100,centers=2,random_state=0,cluster_std=0.5)
pt.scatter(x[:,0],x[:,1],c=y,s=100,cmap="rainbow")
数据集图像: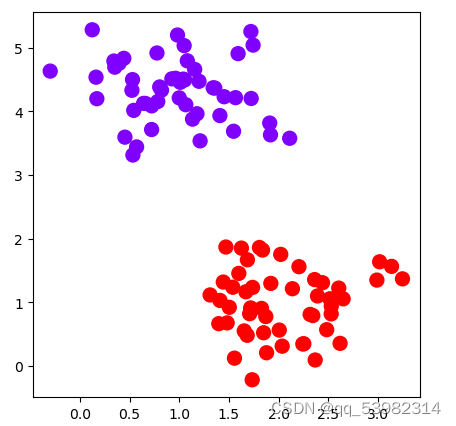
- 绘制网格代码:
ax = pt.gca() # 获取当前的坐标轴对象
xlim=ax.get_xlim()
ylim=ax.get_ylim()
print(xlim)
//绘制网格
axisx=np.linspace(xlim[0],xlim[1],30)//从左到右取30个值来绘制网格
axisy=np.linspace(ylim[0],ylim[1],30)
axisy,axisx=np.meshgrid(axisy,axisx)//特征向量转化成坐标矩阵,即x,y堆叠成30,30的坐标矩阵
xy=np.vstack([axisx.ravel(),axisy.ravel()]).T//将两个矩阵展平为一维数组,并在一起就是900组坐标。
print(xy.shape)//900,2
- svc代码:
cf=svc(kernel="linear").fit(x,y)
p=cf.decision_function(xy).reshape(axisx.shape)//将900个点变为30,30
print(p)//数值的绝对值可以表示距离的远近
ax.contour(axisx,axisy,p,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
结果: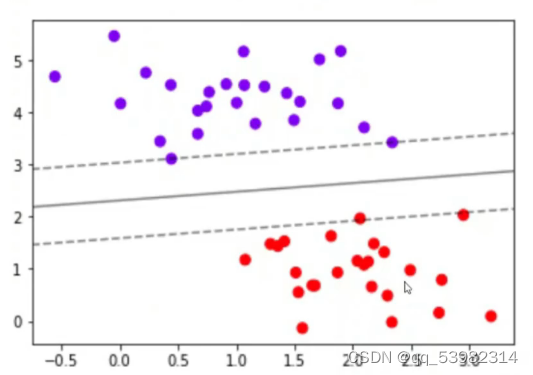
2.核函数

3.软间隔

这个时候,我们的决策边界就不是单纯地寻求最大边际了,因为对于软间隔地数据来说,边际越大被分错的样本也就会越多,因此我们需要找出一个"最大边际”与”被分错的样本数量”之间的平衡。参数C用于权衡“训练样本的正确分类“与”决策函数的边际最大化“两个不可同时完成的目标,希望找出一个平衡点来让模型的效果最佳。
代码: