Hadoop入门:安装hadoop搭建集群
准备工作
VMware Workstation
CentOS-7 镜像
远程连接工具(xshell、MobaXterm(我现在用的) 等等)
hadoop安装包、 jdk安装包
链接:https://pan.baidu.com/s/13rWvSjP9ukoIOq-Nr6UDfg
提取码:2580
安装虚拟机
选择典型
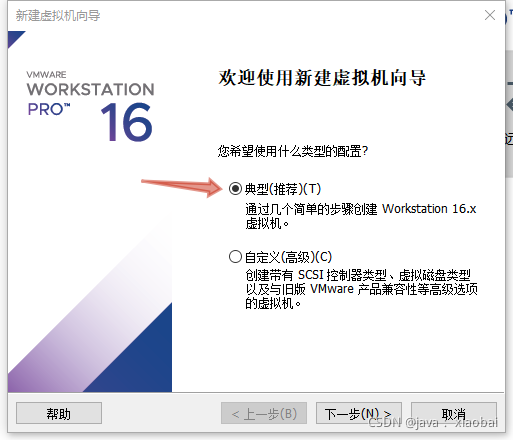
选择稍后安装操作系统
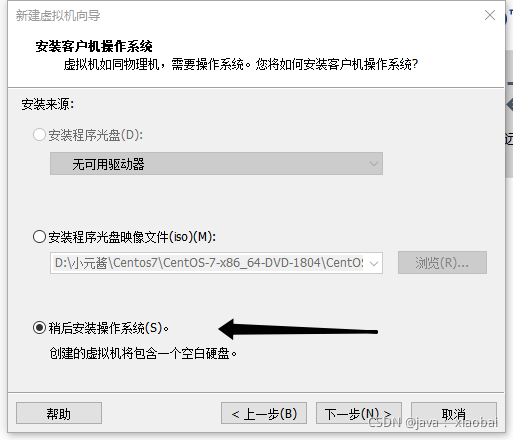
选择Linux 版本CentOS 7 64 位
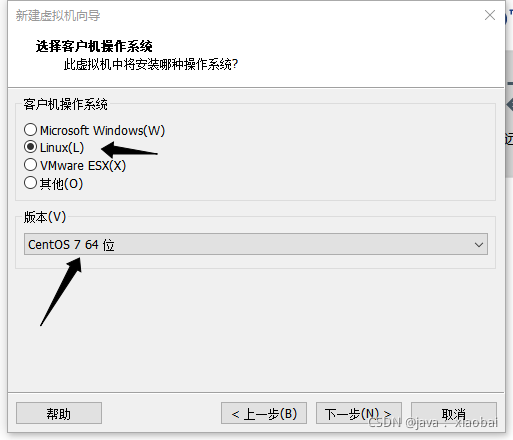
磁盘大小根据自己需求 , 然后选择将磁盘拆分成多个文件
点击完成
编辑虚拟机设置
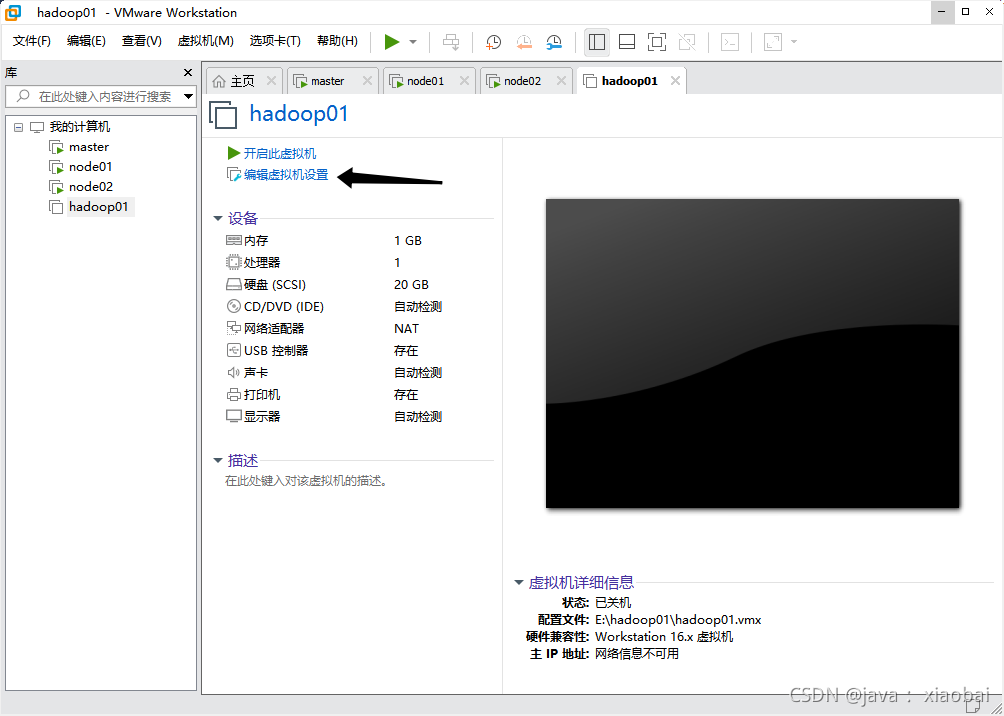
选择CD/DVD(IDE),点击使用ISO映像文件,选择自己centos镜像的位置,并点击确定
开启虚拟机
选择第一个,安装CentOS7
都选择中文
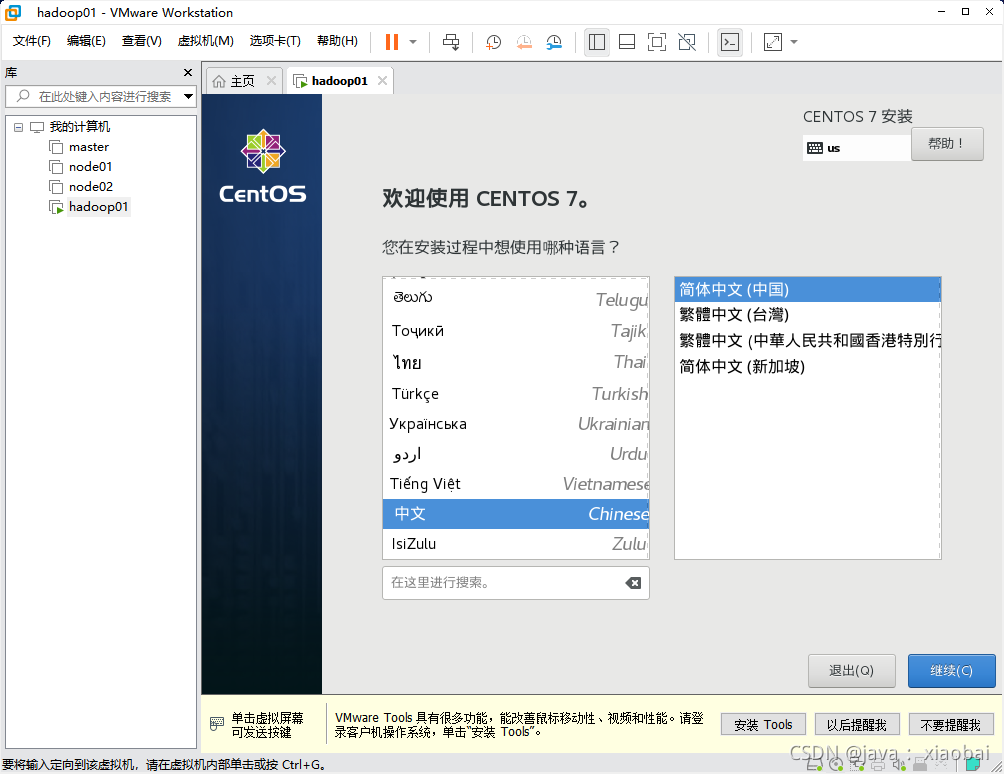
选择安装源,进去后验证一下镜像完整度即可
选择安装位置

点击一下硬盘,点击完成
选择网络和主机名
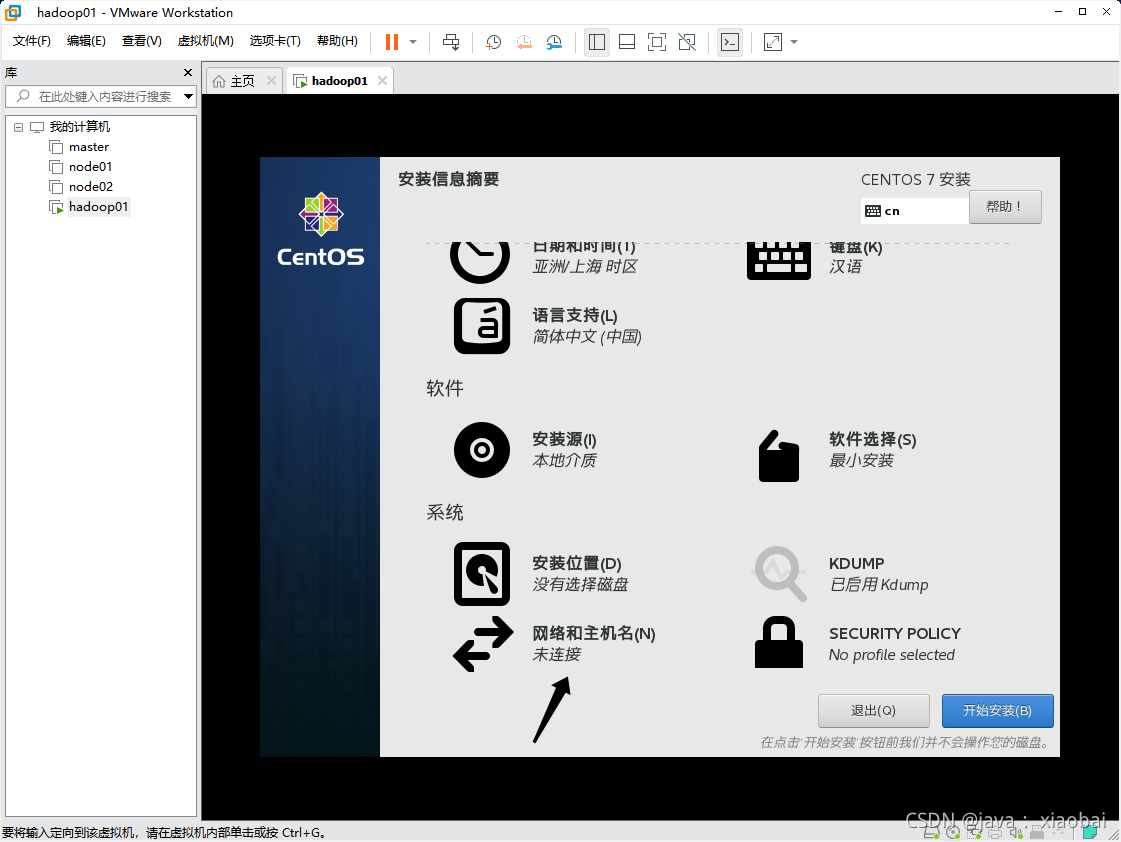
打开以太网,修改主机名并应用
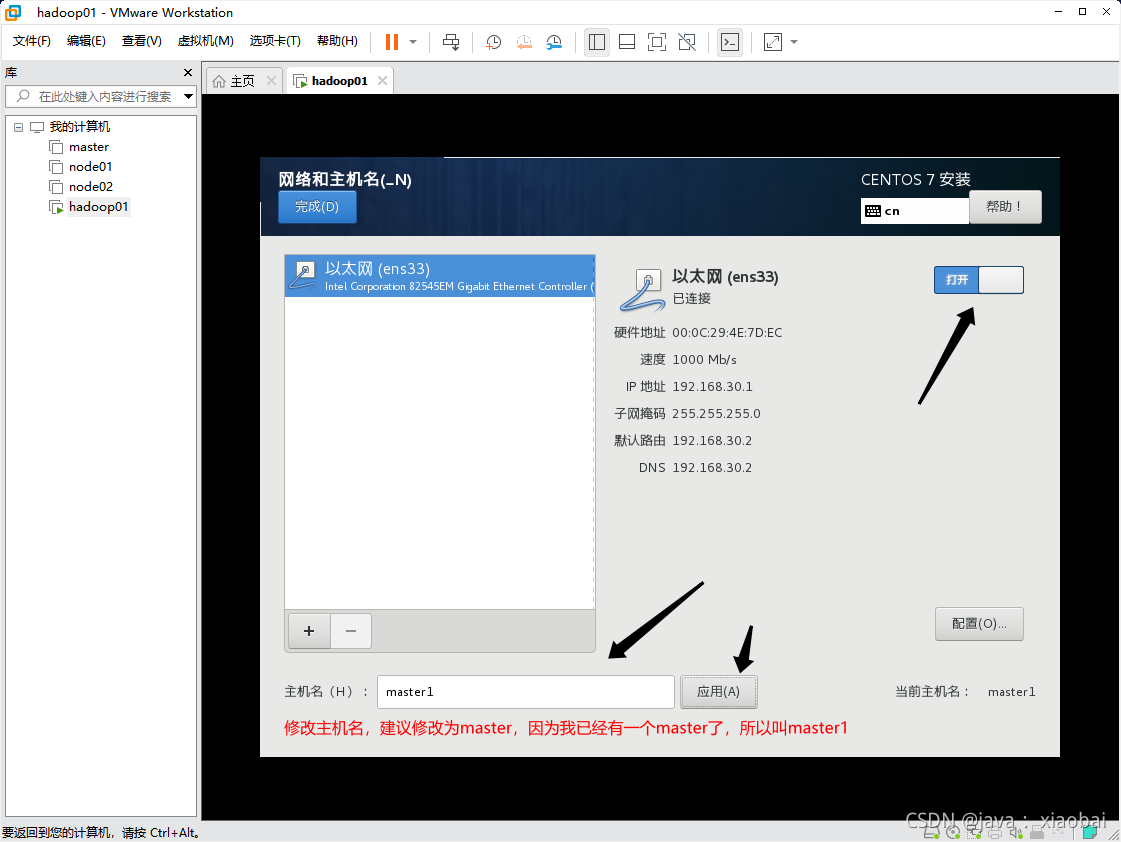
进入配置到ipv4的设置
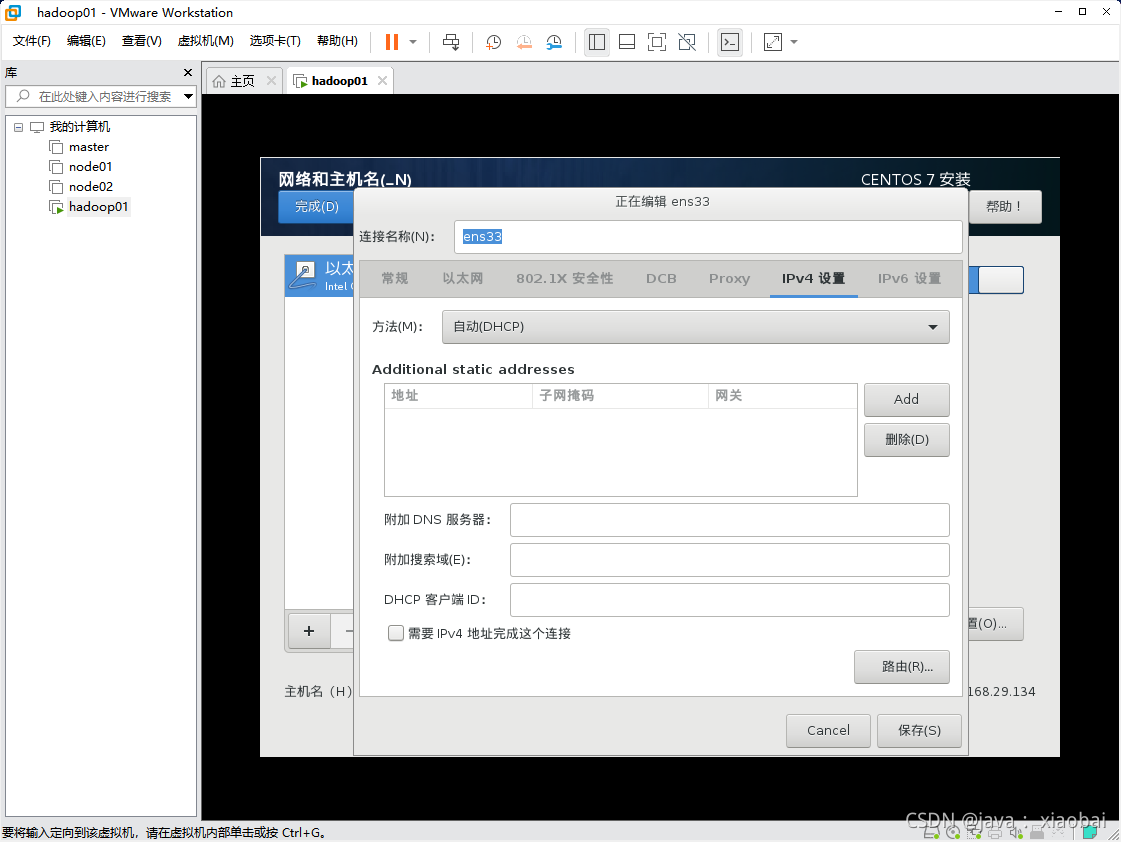
先把方法改为手动,添加一个ip,ip的前三位要跟自己Windows上的ipv4的前三位一样,后面的去0~255之间的数字,我这里就写20了(不要和别人冲突了),子网掩码是固定的,网关和DNS服务器就是在前三位的基础上加了个2 然后保存,点击左上角的完成
Windows查看自己的IP地址 Win+R 输入cmd 然后输入ipconfig 就可以看到了

开始安装
*设置root密码(自己要记住)
创建用户
名字随意,密码要记住,要把此账户设置为管理员
然后等待安装结束,重启虚拟机
开机后登录root
我们的CentOs里面是没有ifconfig这个命令的需要自己下载
//先输入这个命令
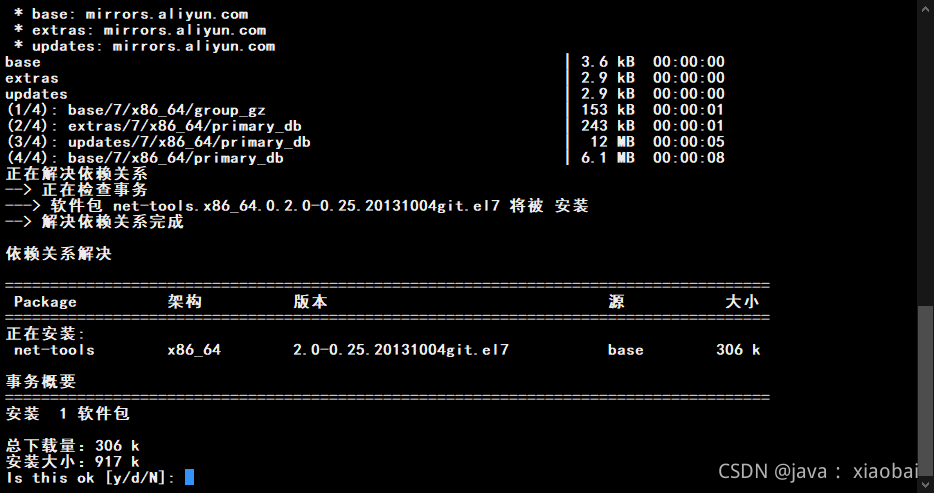
yum search ifconfig
//会出现下面这种情况
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
base: mirrors.neusoft.edu.cn
extras: mirrors.neusoft.edu.cn
updates: mirrors.neusoft.edu.cn
============ 匹配:ifconfig ==============
net-tools.x86_64 : Basic networking tools
//然后安装匹配到的ifconfig,安装这个即可
yum install net-tools.x86_64
使用ifconfig查看自己的IP地址发现上面的IP地址为什么不跟我们设置的ip一样呢?
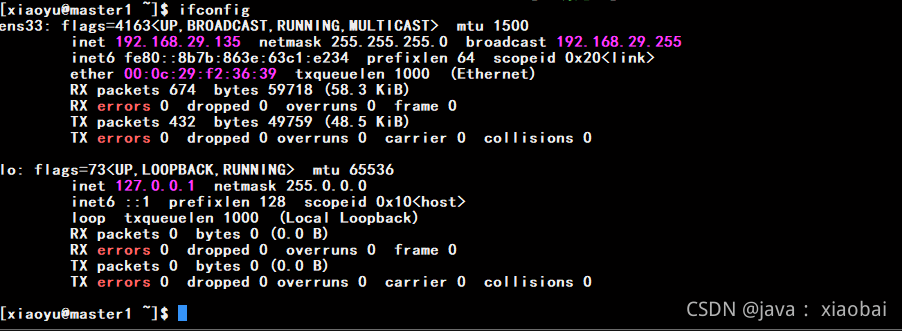
使用vi编辑器编辑网卡的配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
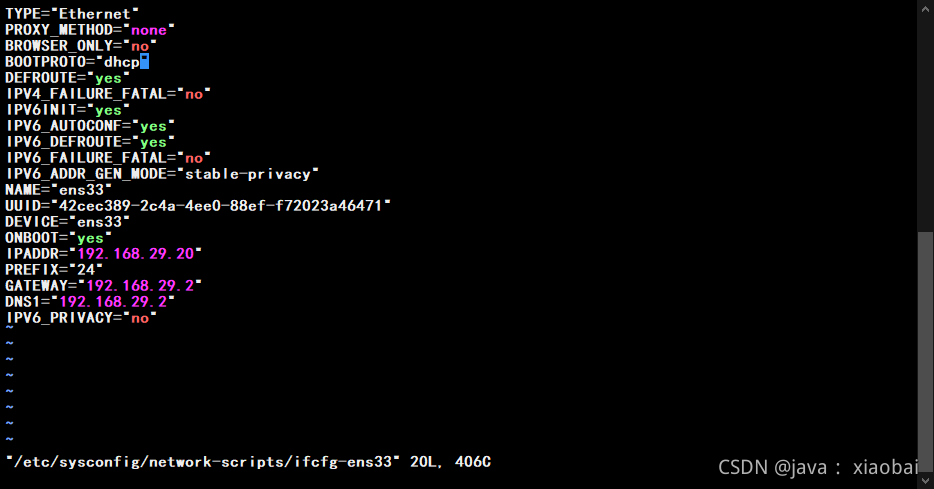
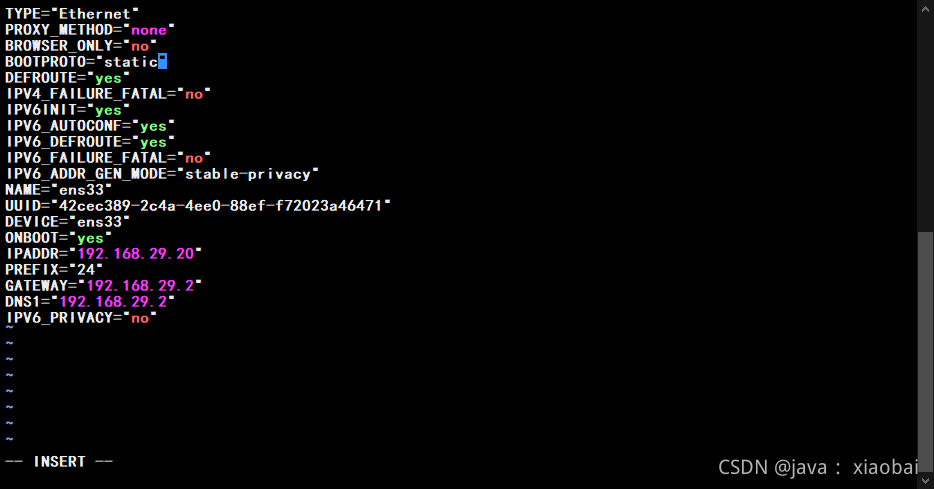
把BOOTPROTO=“dhcp” 中的dhcp改成static
(不懂vi命令的看过来:就用键盘上的上下左右键把光标移动到想要修改的词后面,按i进入插入模式就可以把文字修改了,修改完确认没问题后先按esc键退出插入模式,到命令模式,然后在按shift+;到末行模式输入wq (w就是保存q就是退出,保存并退出的意思))
修改完之后需要重启网卡
service network restart
使用ifconfig查看ip
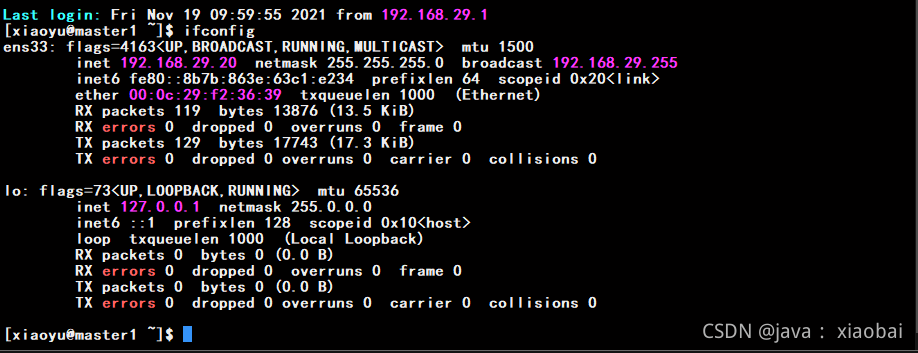
没问题的话,关闭虚拟机,点击工具栏虚拟机选项选择管理然后克隆hadoop1
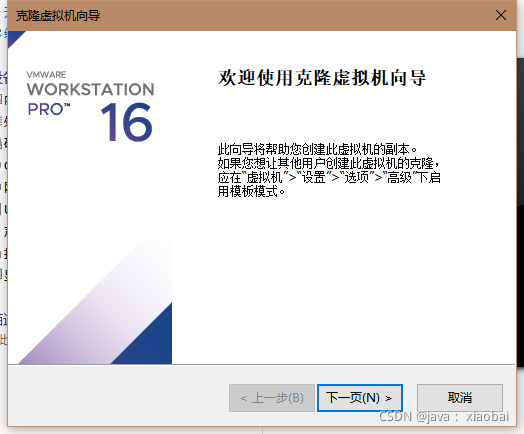
选择虚拟机的当前状态
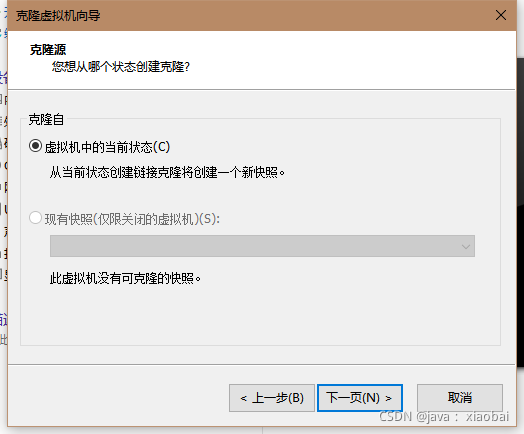
创建完整克隆
修改虚拟机的名字和位置,点击完成
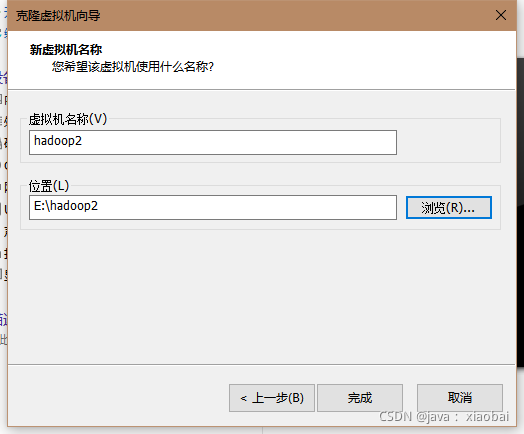
完成后先不要开机,先编辑hadoop2的设置,点击网络适配器选择高级
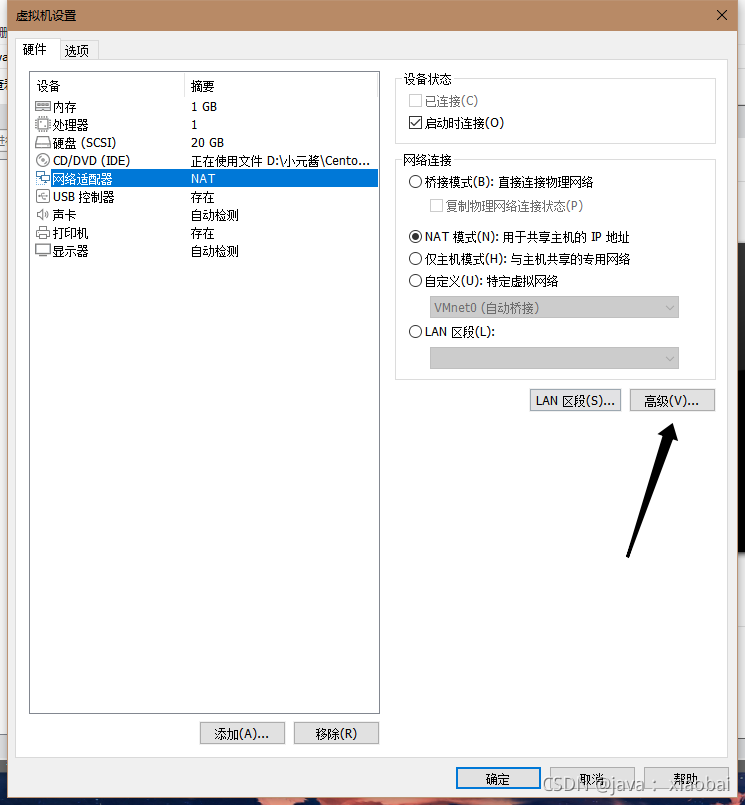
点击生成新的Mac地址(因为是克隆过来的Mac地址一样所以要重新生成一个新的Mac地址)
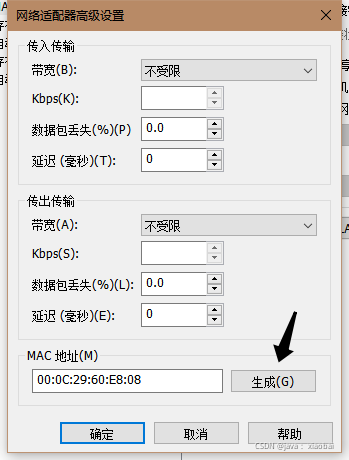
更改完之后启动hadoop2,并查看ip,因为克隆的缘故ip地址也一样需要修改IP地址
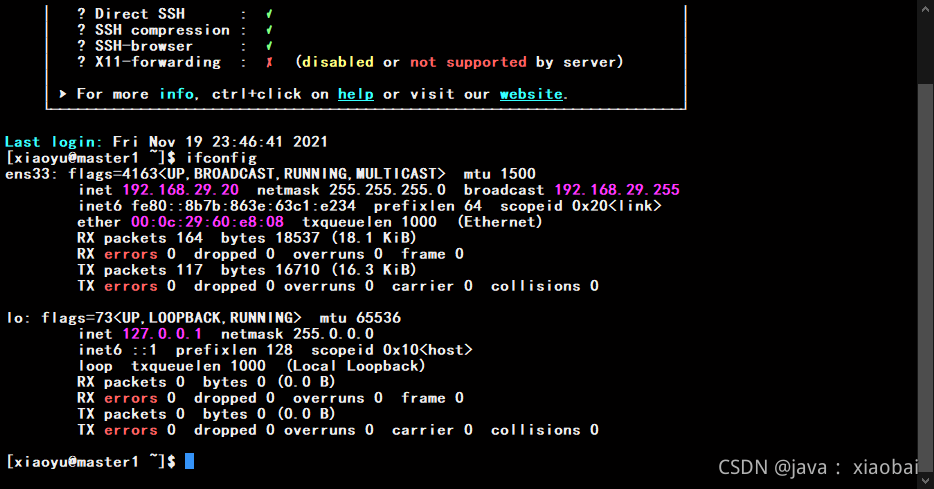
再次进入配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改IP地址并退出然后重启网卡(ip地址尽量要连着,我hadoop1是20,hadoop2我就用21,以此类推)
service network restart
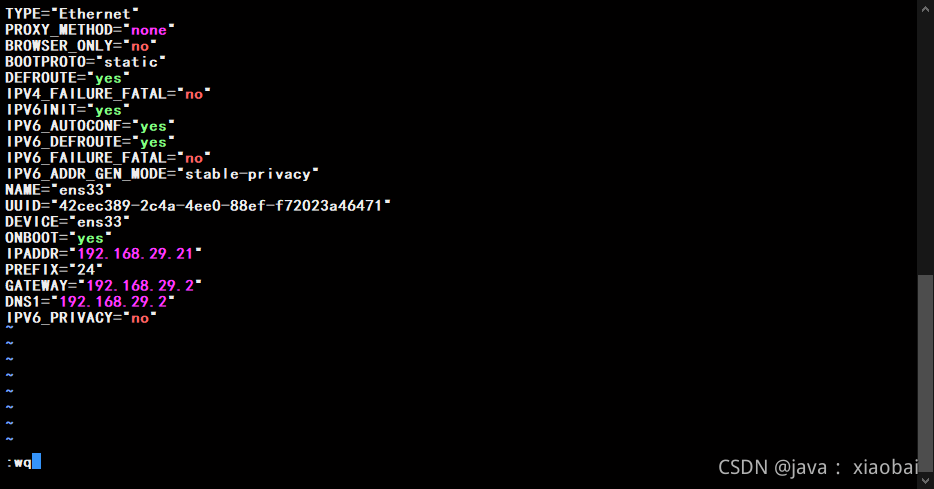
再克隆一台hadoop3 流程和hadoop2一样,弄完之后就开始hadoop集群的搭建了(注意Mac地址一定要重新生成,不要和前两台的Mac地址相同,IP地址也要更改)
修改主机名,修改第二台和第三台分别为server01 和server02,修改后重启虚拟机即可
hostnamectl set-hostname 要修改的主机名
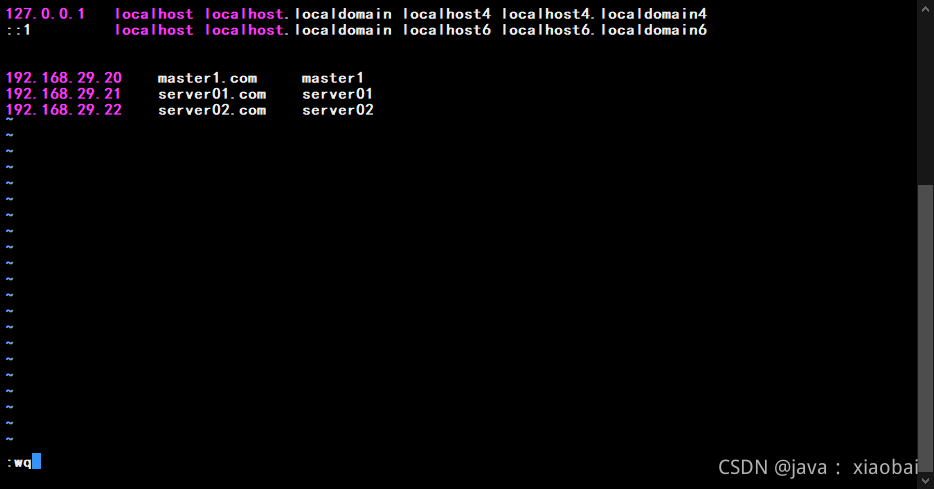
修改hosts的映射,这样做的目的是让三台虚拟机互相认识(三台都要更改)
vi /etc/hosts
添加下面三行
192.168.29.20 master1.com master1
192.168.29.21 server01.com server01
192.168.29.22 server02.com server02
怎么测试他们是否认识呢?通过ping这个命令后面加主机名,如果有响应就没问题了
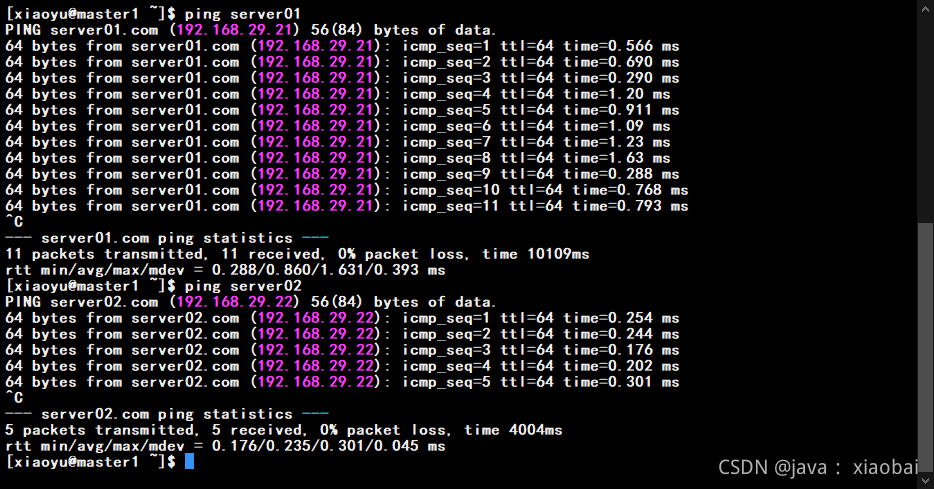
关闭防火墙(三台都关)
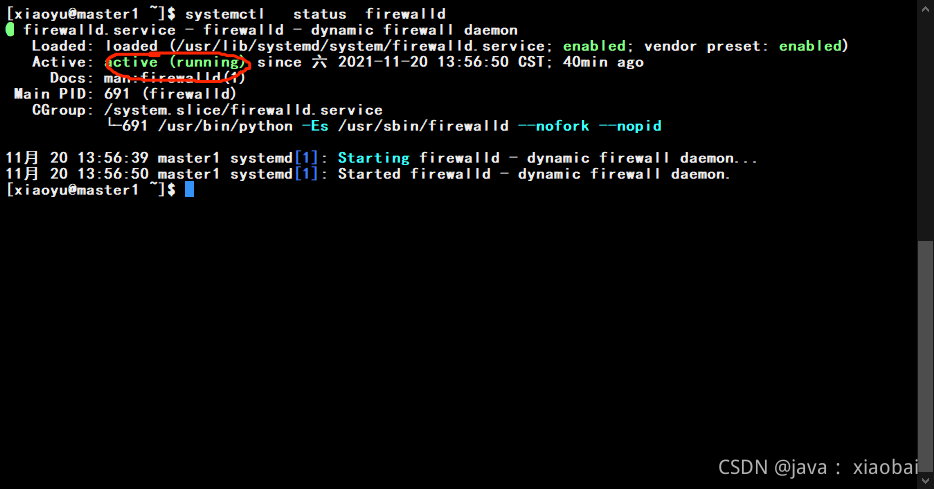
查看防护墙状态
Systemctl status firewalld
active (running说明防火墙在开着的
关闭防火墙
systemctl stop firewalld
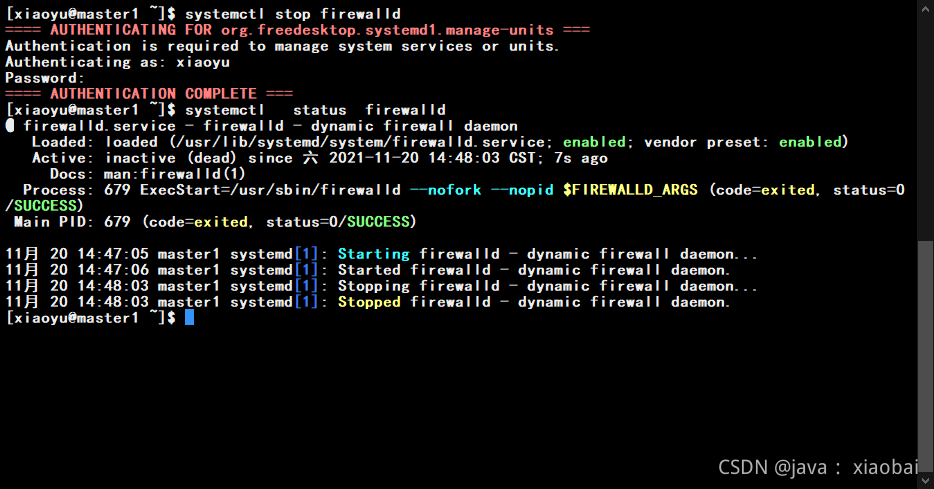
永久关闭防火墙(因为上面的呢那种方法重启后防火墙会继续开启,而永久关闭防火墙是将配置文件改了,建议先关闭防火墙然后在永久关闭)
systemctl disable firewalld.service
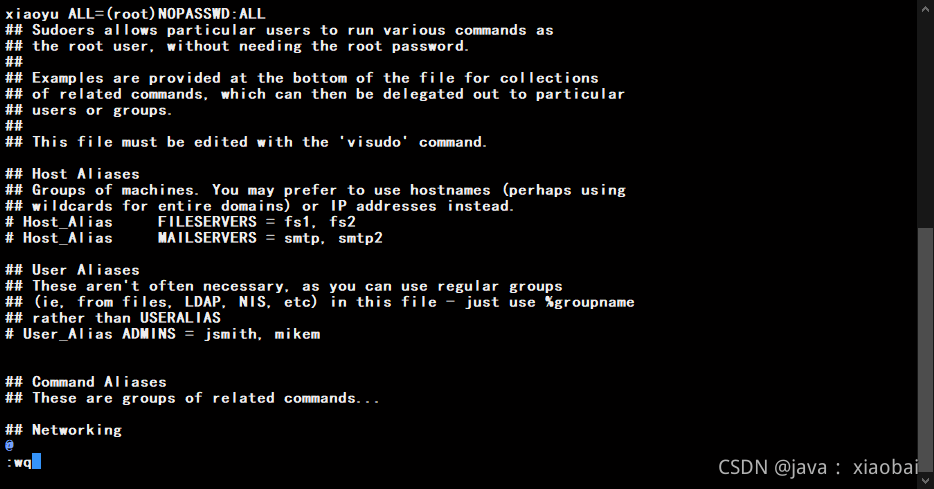
给用户免密码root权限(在Linux上尽量不要用到root,一般都用自己创建的管理员,所以要让管理员也有跟root一样的权限)
sudo vi /etc/sudoers
在第一行添加(xiaoyu是我创建管理员的那个名字,要根据你设置的用户名来)
xiaoyu ALL=(root)NOPASSWD:ALL
安装jdk
用远程连接工具连接虚拟机,用普通用户(就是那个管理员)也可以通过su xiaoyu(这是我的普通用户名,改成你的) 切换

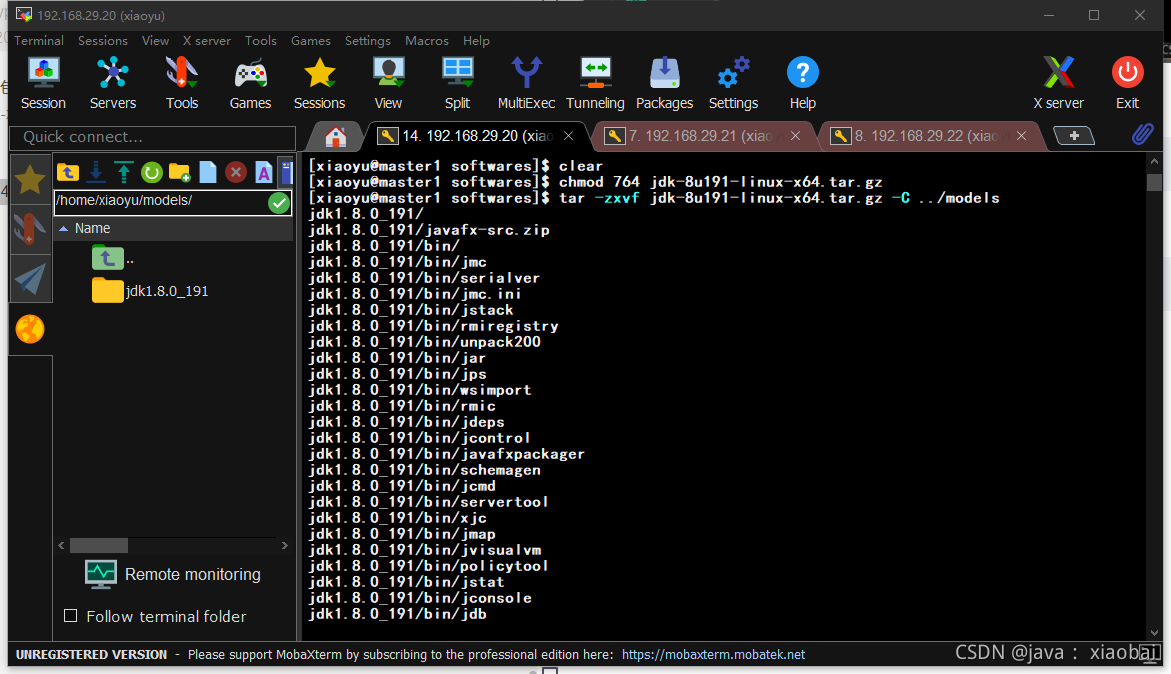
因为这是新建的虚拟机所以现在什么都没有,我们需要新建两个文件夹models(用来放解压后的软件的)、softwares(用来放安装包的)
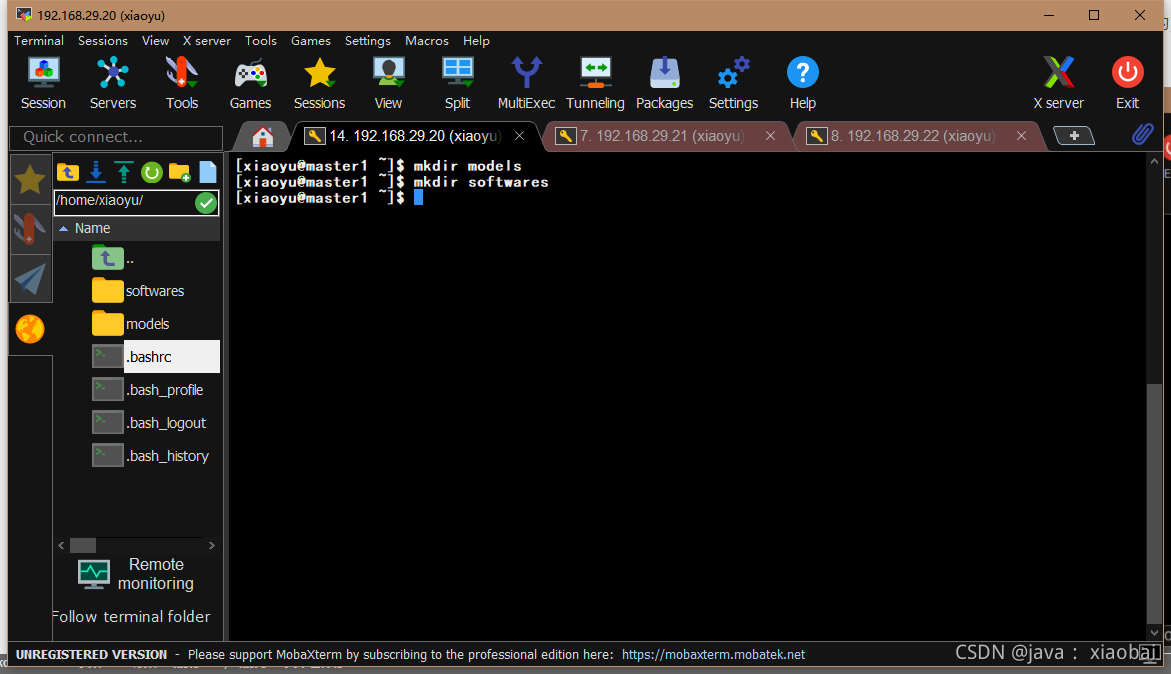
进入softwares中把jdk的安装包拖进来并修改jdk压缩包的可执行权限
chmod 764 jdk-8u191-linux-x64.tar.gz..
然后把jdk解压的models中
tar -zxvf jdk-8u191-linux-x64.tar.gz -C ../models
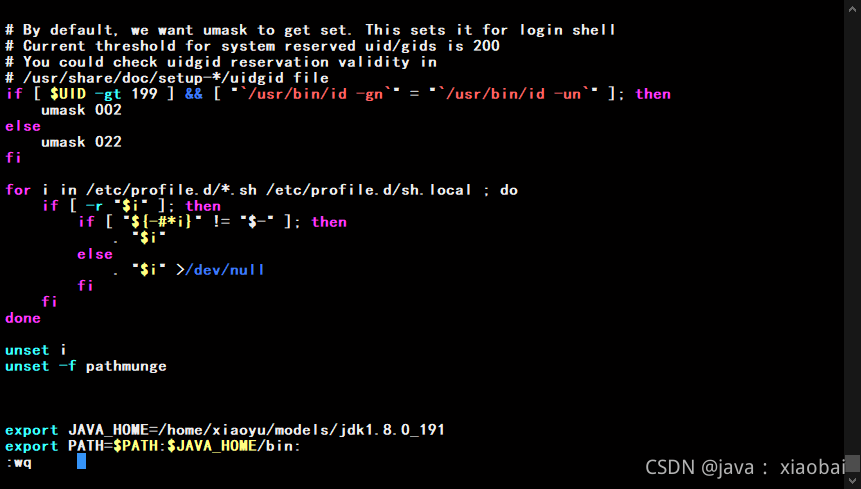
配置jdk的环境变量
sudo vi /etc/profile
在最后两行添加
export JAVA_HOME=/home/xiaoyu/models/jdk1.8.0_191 (是自己jdk的安装目录)
export PATH=$PATH:$JAVA_HOME/bin:
保存后刷新配置文件
source etc/profile
然后输入Java或javac,当出现一长串的东西时就说明jdk安装成功了(另外两台也要安装)
设置SSH免密码登录
用以生成公钥私钥的秘钥对
ssh-keygen -t rsa
然后四次回车
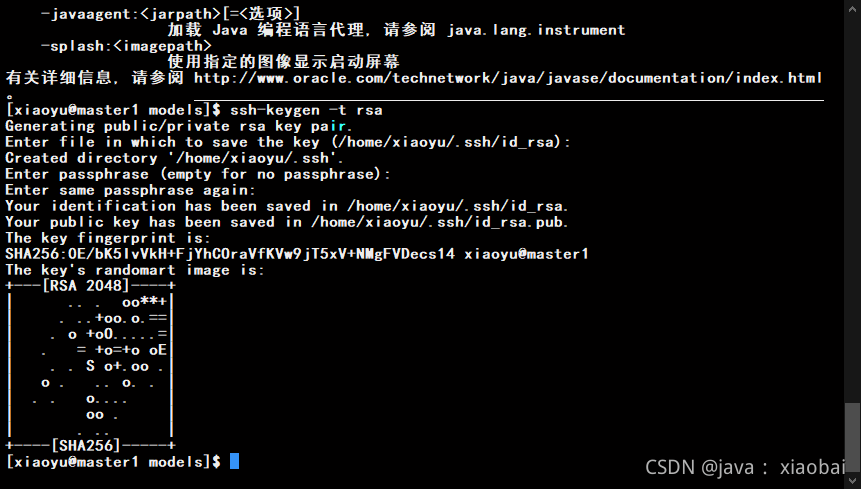
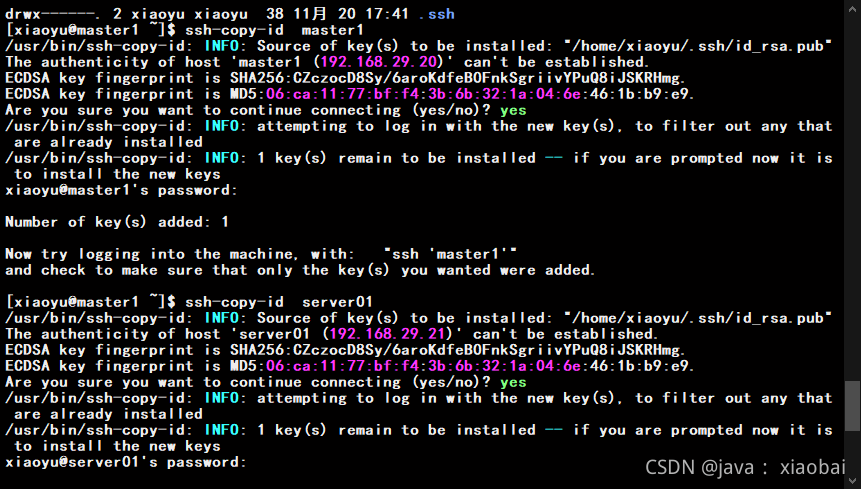
成功后将ssh秘钥发给自己和另外两台虚拟机
ssh-copy-id master1
ssh-copy-id server01
ssh-copy-id server02
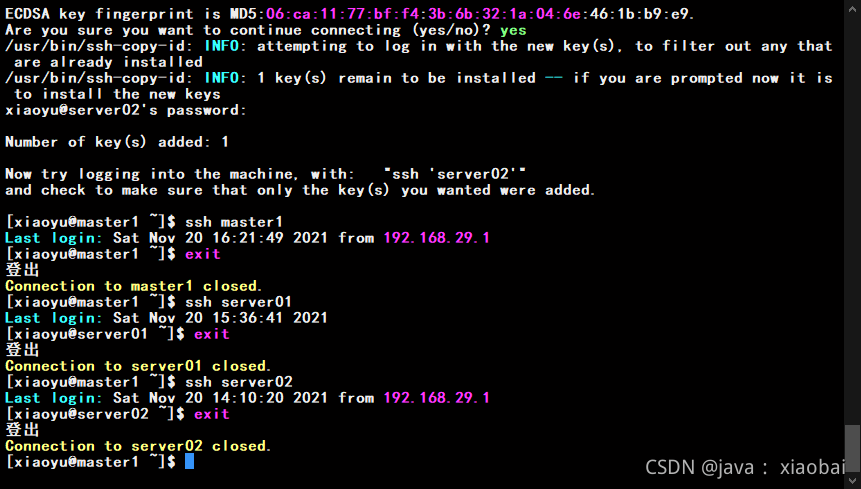
发送完成后用ssh 测试一下
ssh master1
ssh server01
ssh server02
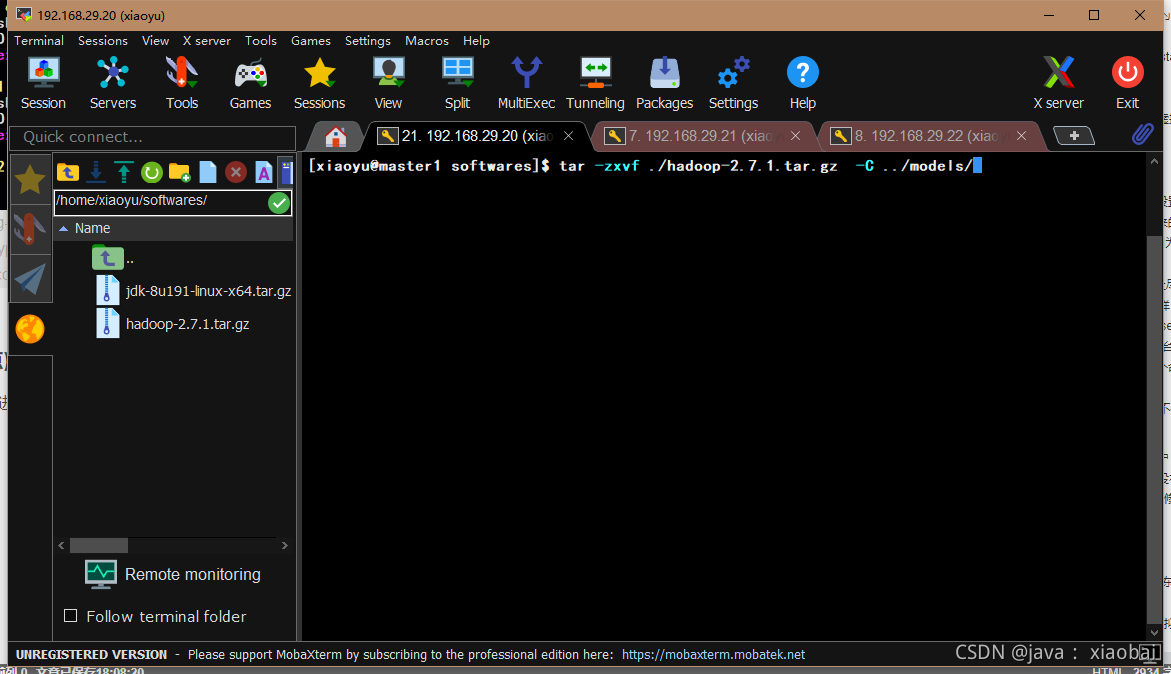
安装hadoop(重点)
老样子先把hadoop安装包拖进softwares中,然后解压到models中
tar -zxvf ./hadoop-2.7.1.tar.gz -C ../ models/
修改环境变量
sudo vi /ect/profile
没有修改之前
export JAVA_HOME=/home/xiaoyu/models/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin:
修改之后(添加了一个HADOOP_HOME,并在PATH后加了hadoop的bin目录和sbin目录)
export JAVA_HOME=/home/xiaoyu/models/jdk1.8.0_191
export HADOOP_HOME=/home/xiaoyu/models/hadoop-2.7.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
修改hadoop的配置文件(小白建议在左边可视化文件夹操作)
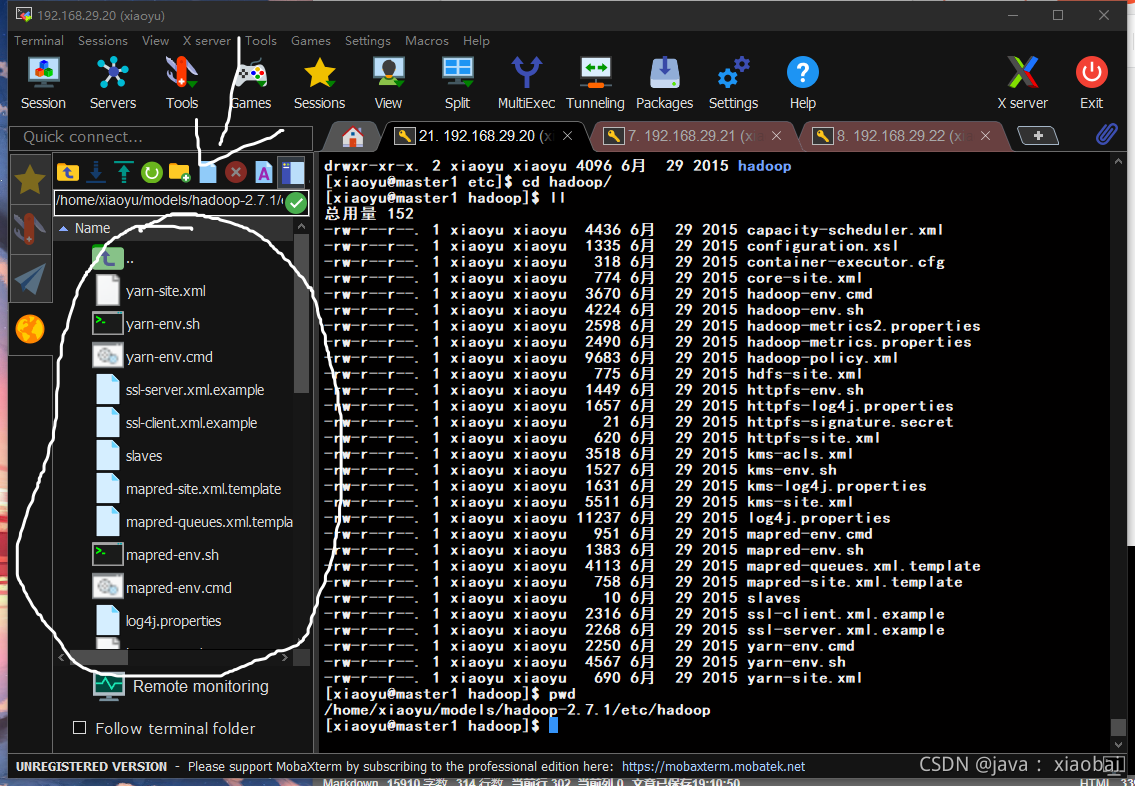
hadoop 的配置文件都在/models/hadoop-2.7.1/etc/hadoop

修改hadoop-env.sh
双击hadoop-env.sh这个文件更改里面jdk的路径
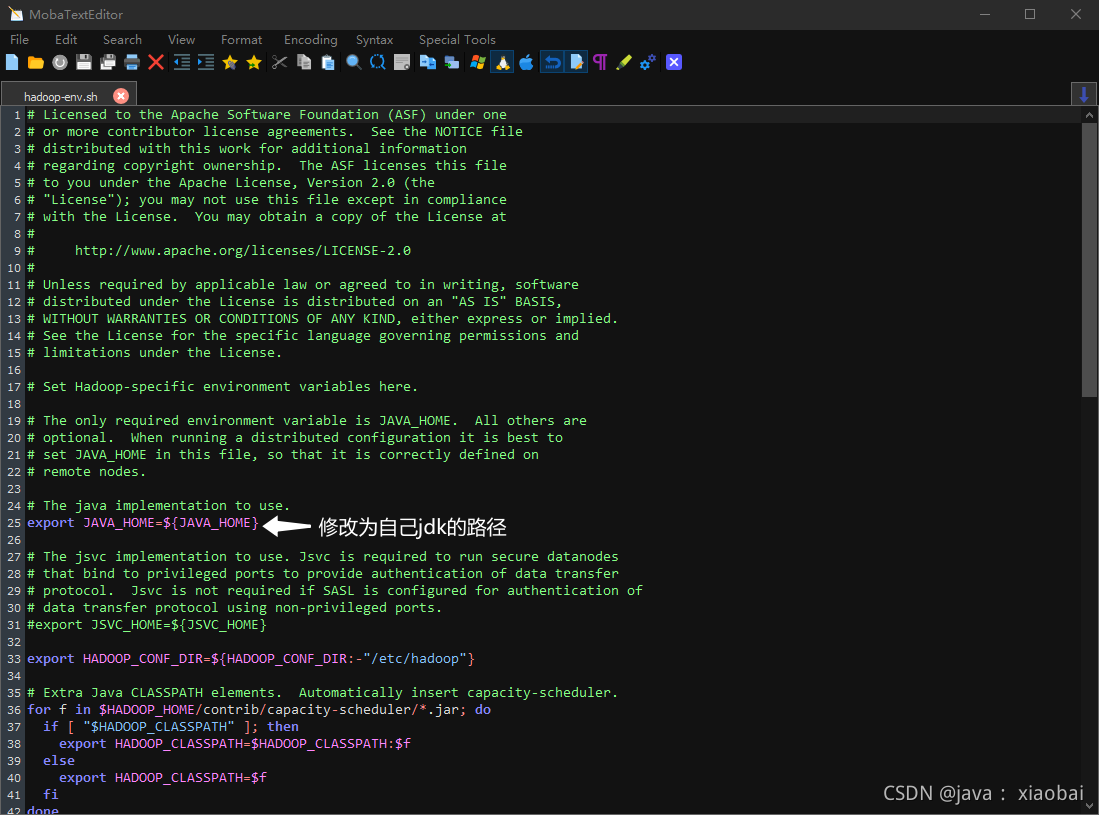
这里教大家一个快速查看自己jdk的路径
echo $JAVA_HOME

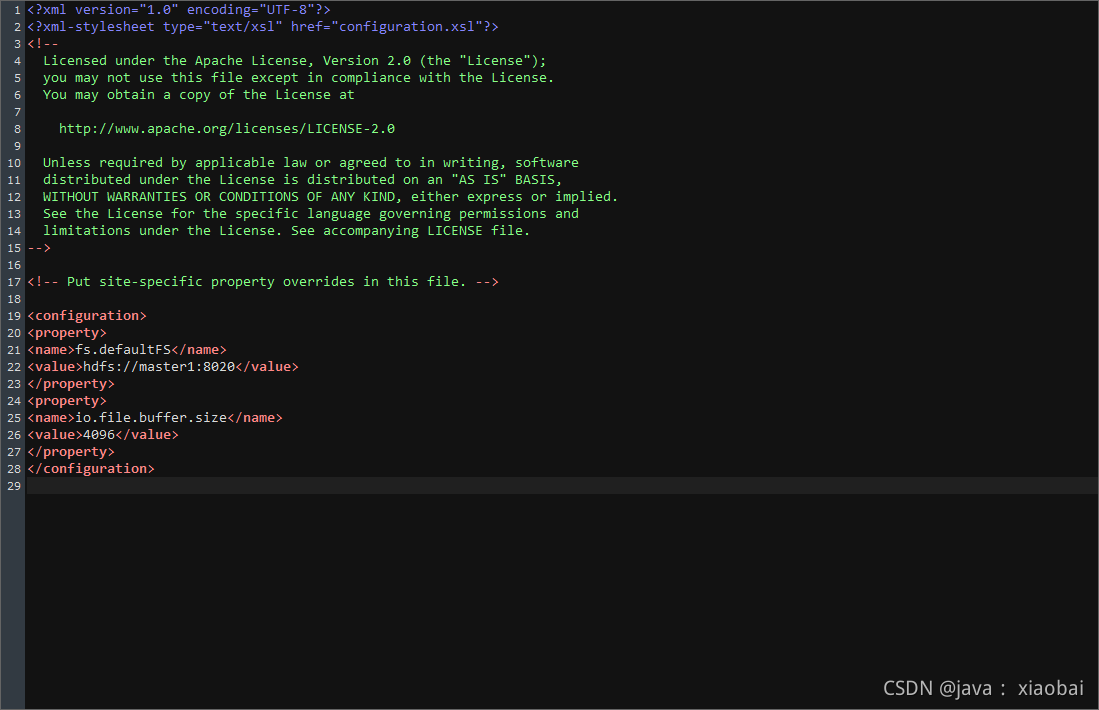
修改 core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
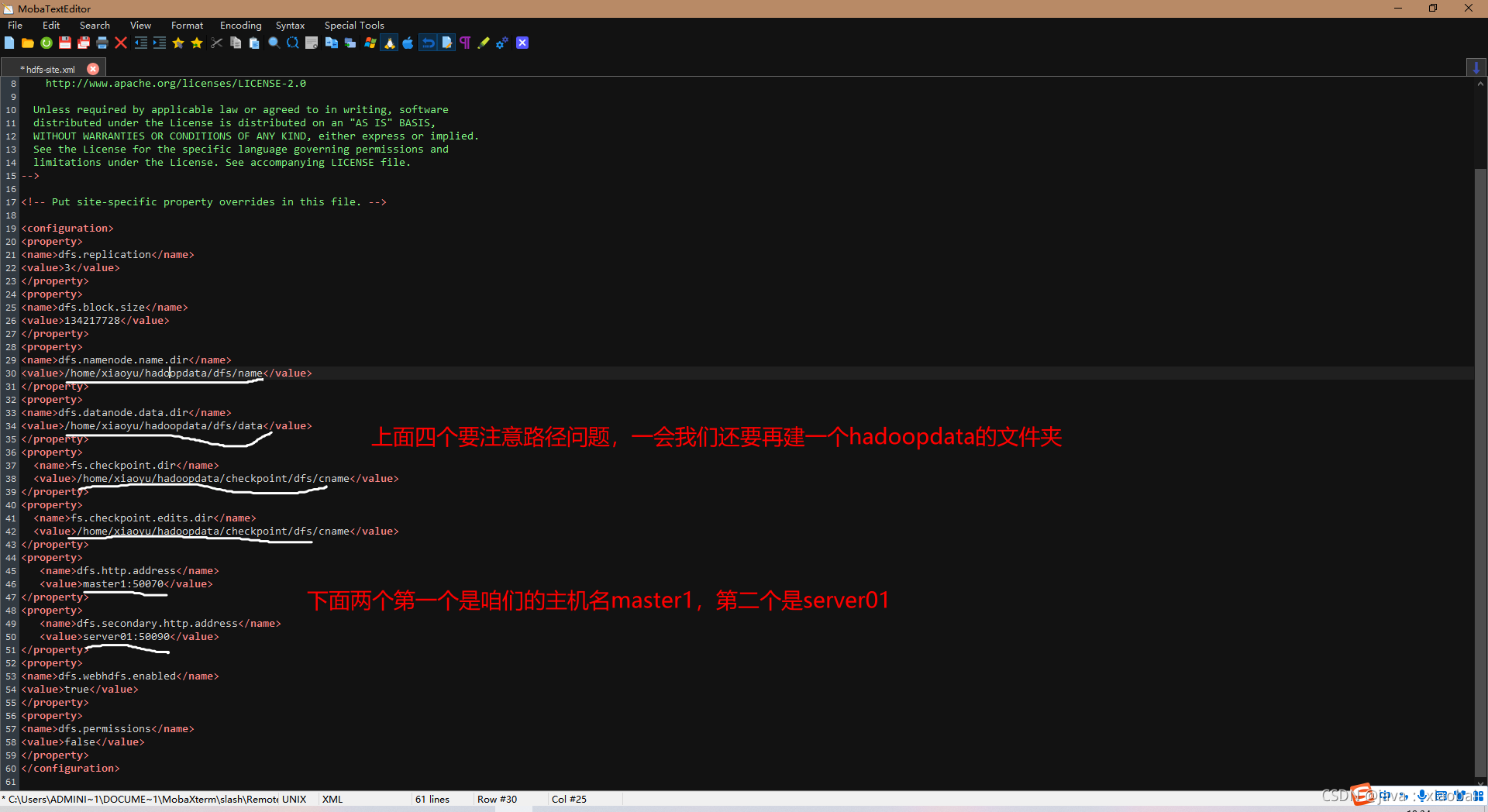
修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/xiaoyu/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/xiaoyu/hadoopdata/dfs/data</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/home/xiaoyu/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/home/xiaoyu/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>server01:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
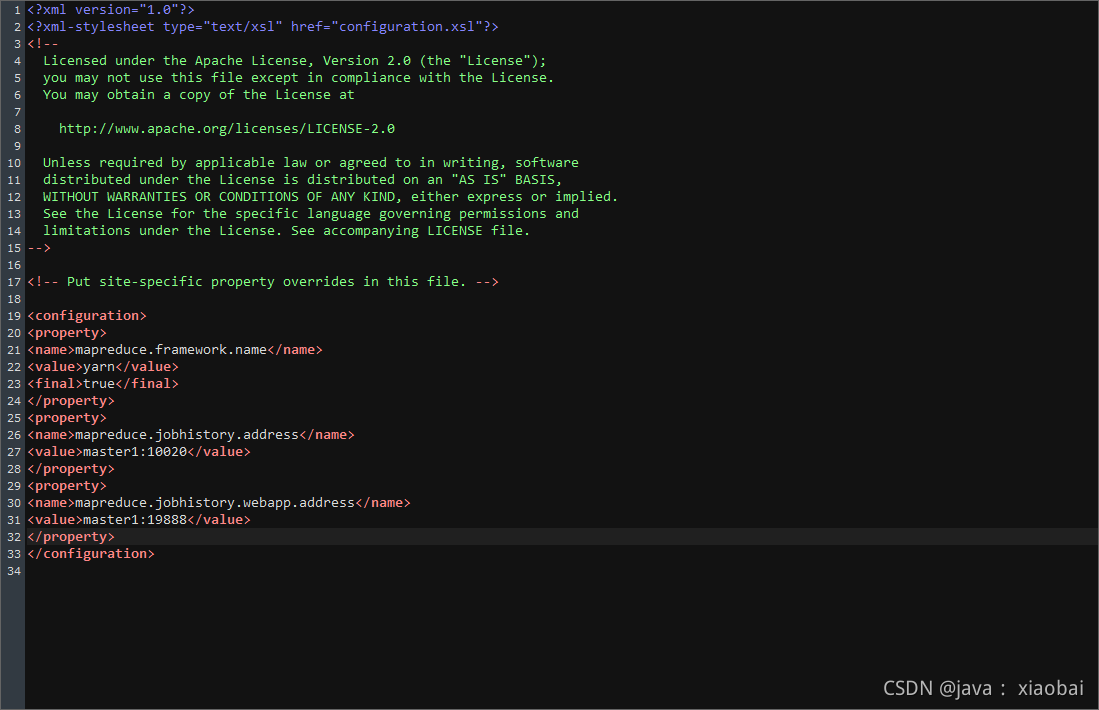
修改mapred-site.xml文件
在配置文件中没有mapred-site.xml这个文件,有mapred-site.xml.template这个文件,把
mapred-site.xml.template的文件重命名为mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1:19888</value>
</property>
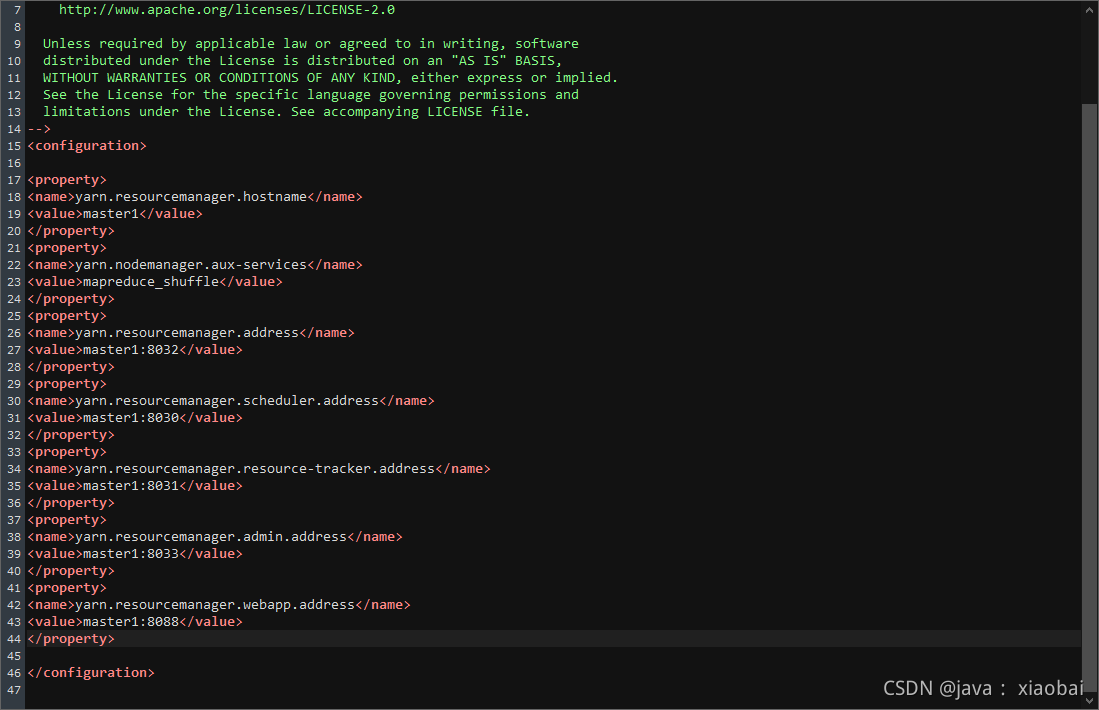
修改yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
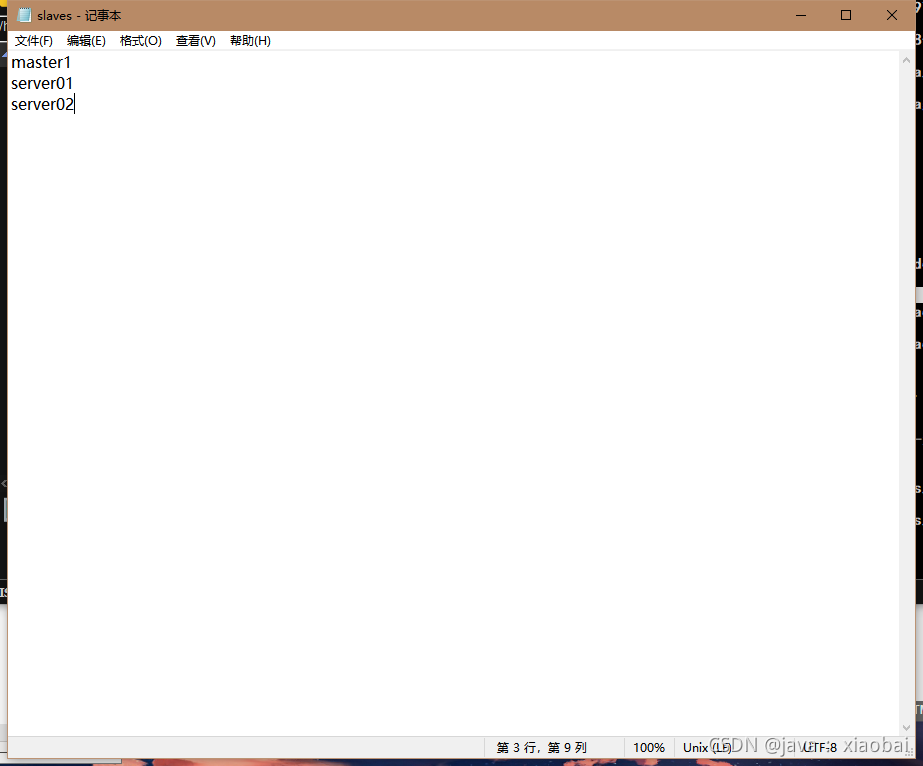
修改slaves文件
master1
server01
server02
创建namenode 元数据保存目录(另外两台也要创建)
在hdfs-site.xml的配置文件中配置了namenode的元数据保存目录,所以我们要创建hadoopdata这个文件夹
将本地的hadoop整个目录复制到另外两台虚拟机
先进入存放hadoop的models文件夹,然后输入以下命令
//scp -r 要发送的文件 用户名@主机名:要发送到的路径
scp -r ./hadoop-2.7.1/ xiaoyu@server01:/home/xiaoyu/models/
scp -r ./hadoop-2.7.1/ xiaoyu@server02:/home/xiaoyu/models/
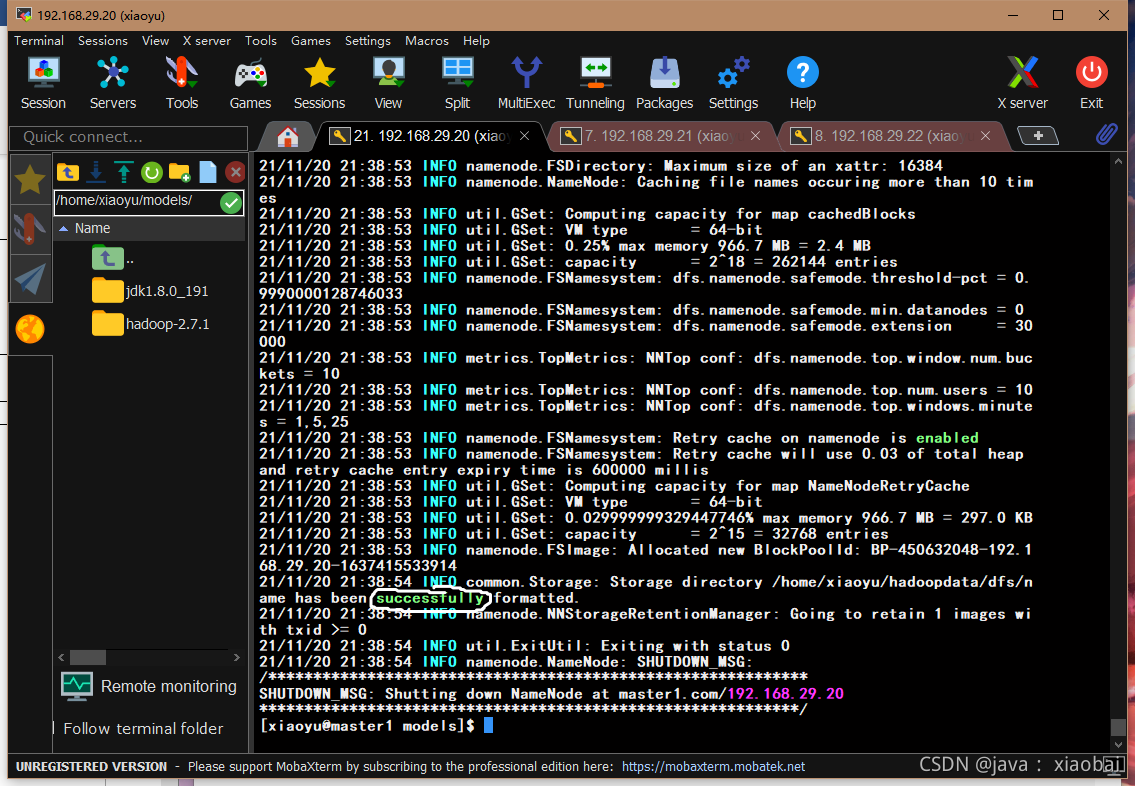
格式化hadoop
hadoop namenode -format
出现successfully就说明成功了
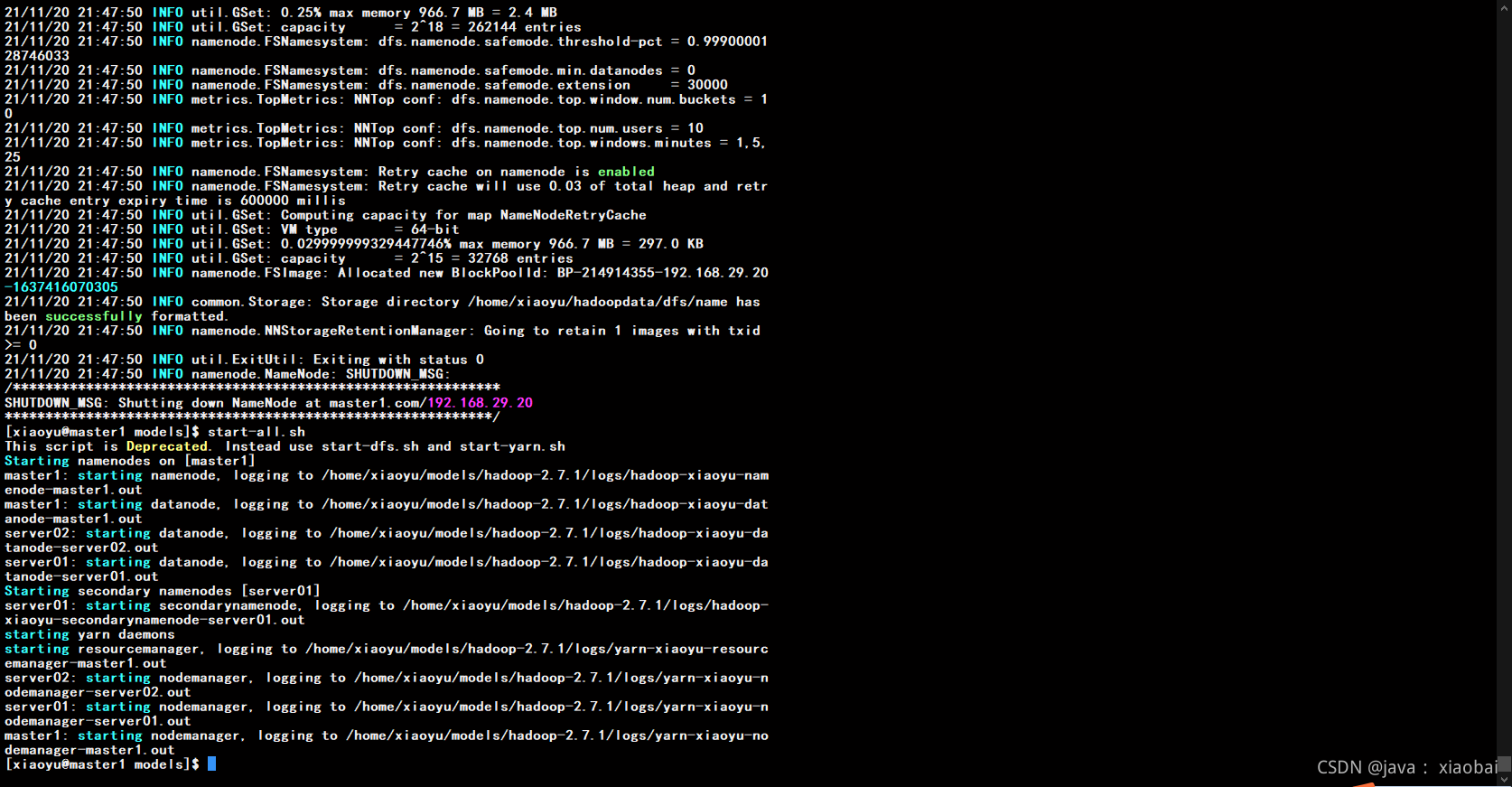
启动hadoop
start-all.sh
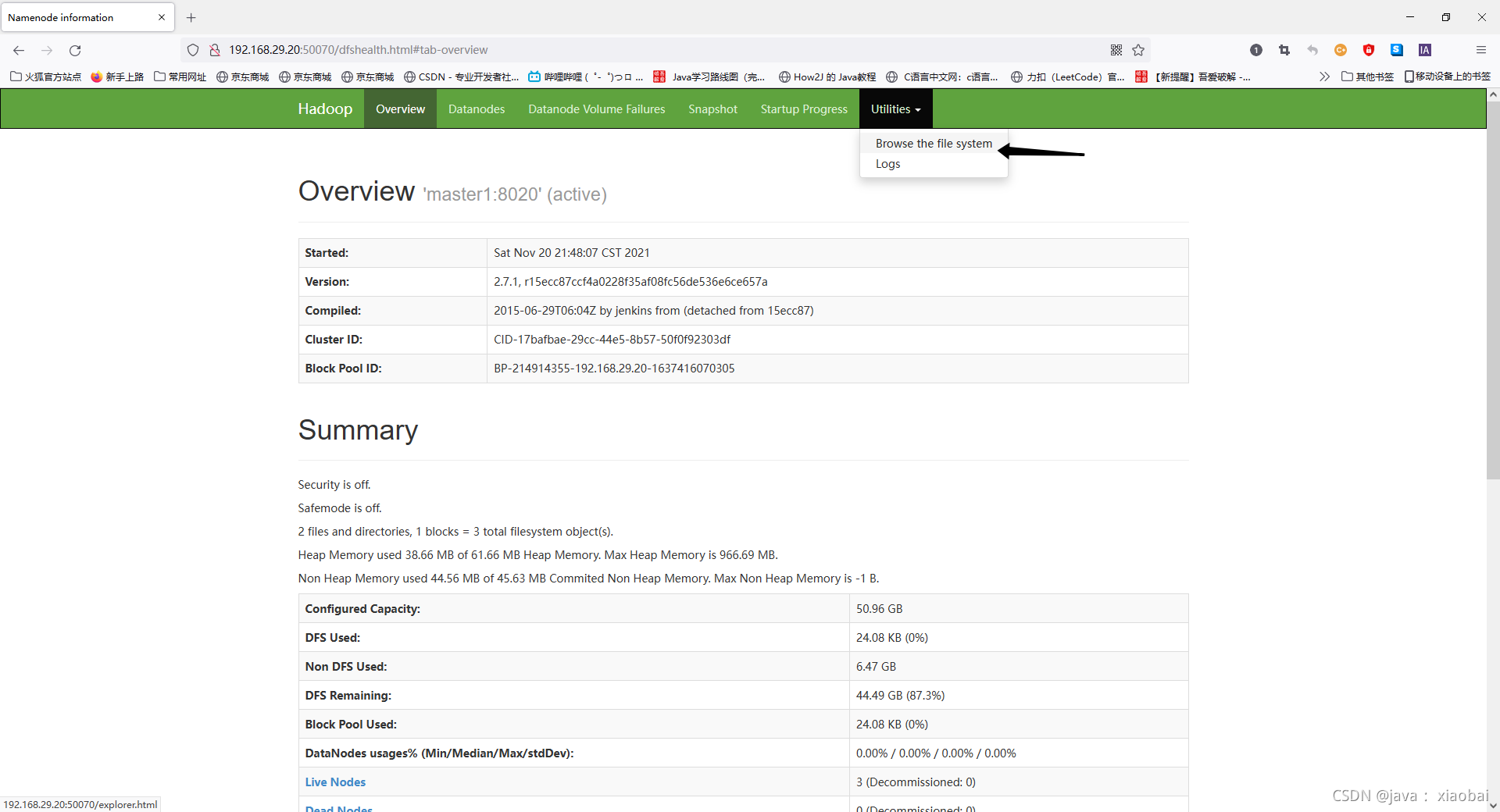
访问hadoop的web端口
http://192.168.29.20:50070
看到以下页面就表示已经成功了

然后再点击页面上的 Live Nodes(活着的节点)
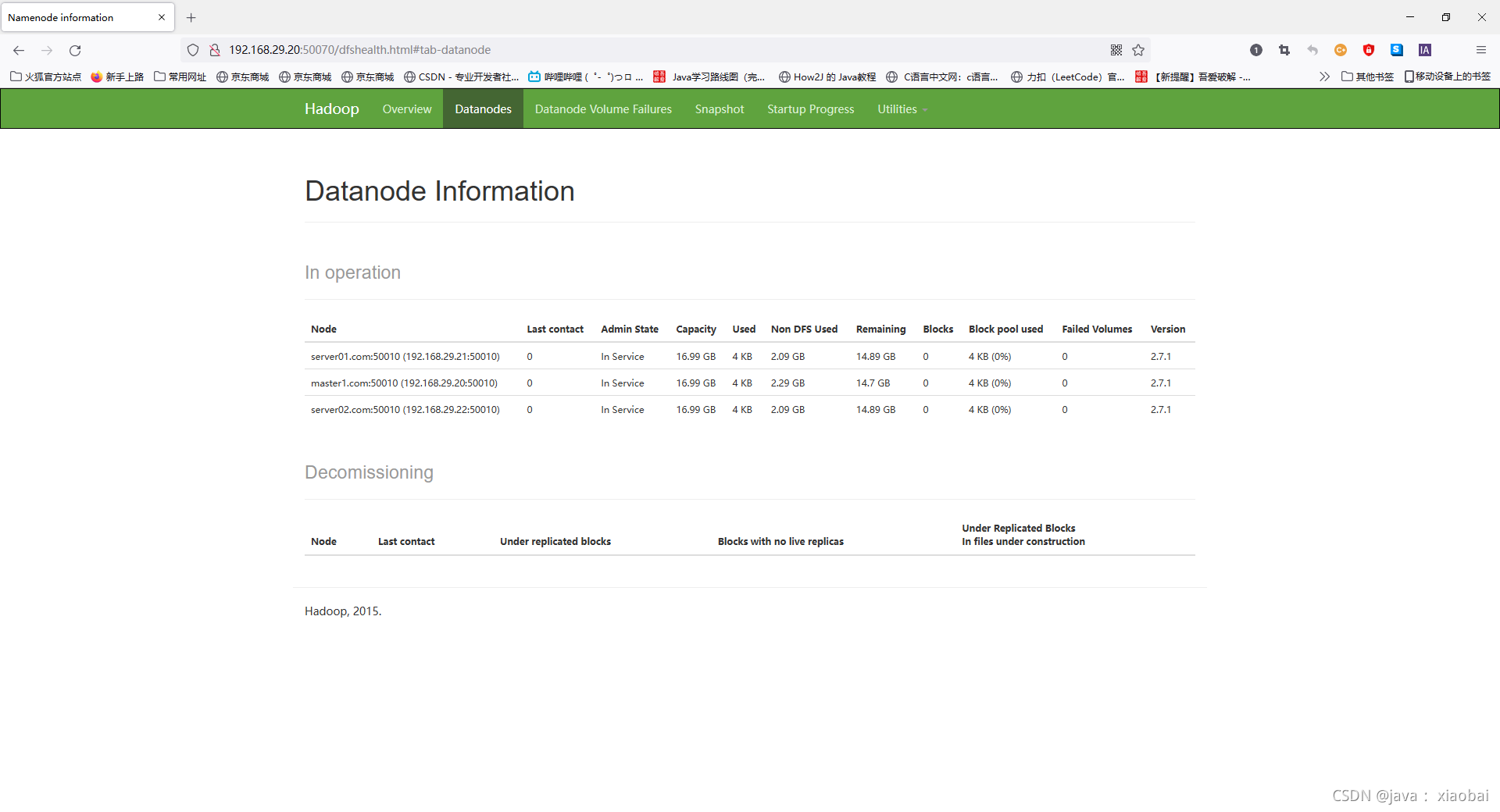
上面显示的就是我们的三个节点
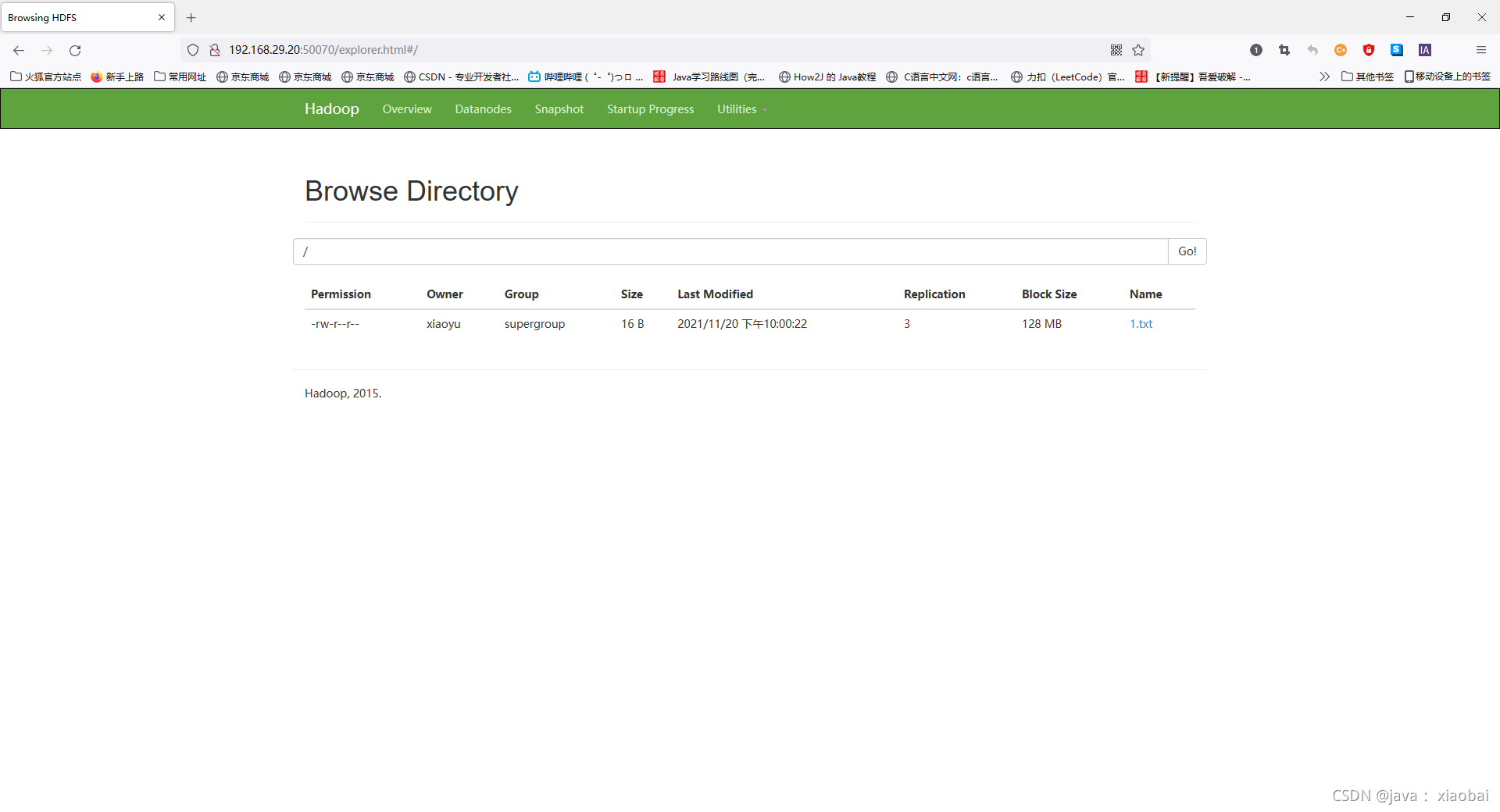
测试hadoop的HDFS是否能用
创建一个1.txt的文件
//把1.txt文件上传到HDFS上
hdfs dfs -put ./1.txt /
看到我们上传的1.txt在上面,成功
最后如果有问题的话可以联系我
QQ:1031248402